Cursor 官宣Long-Running 智能体!
Long-Running Agents 的真正革命性,在于重新划分人类与 AI 的责任边界传统模式Long-Running 模式人类:持续监督、频繁纠正人类:定义目标、审核计划、验收结果AI:执行原子操作AI:端到端交付完整功能协作成本:高(注意力碎片化)协作成本:低(异步、批量处理)🚀开发者体验跃迁:你可以在周五下班前启动一个 48 小时的重构任务,周一早上直接 Review 一个包含完整测试
从“副驾驶”到“自动驾驶”:
曾几何时,AI 编码助手像一位需要你手把手指导的实习生——你写提示词,它回几行代码,你再纠正,它再改。这个循环往复的过程,被称为“提示工程马拉松”。而 Cursor 最新推出的 Long-Running Agents(长运行智能体) 正在终结这一时代:它让 AI 从“副驾驶”升级为可独立完成复杂项目的“自动驾驶系统”。
前几天cursor正式发布Long-Running 智能体!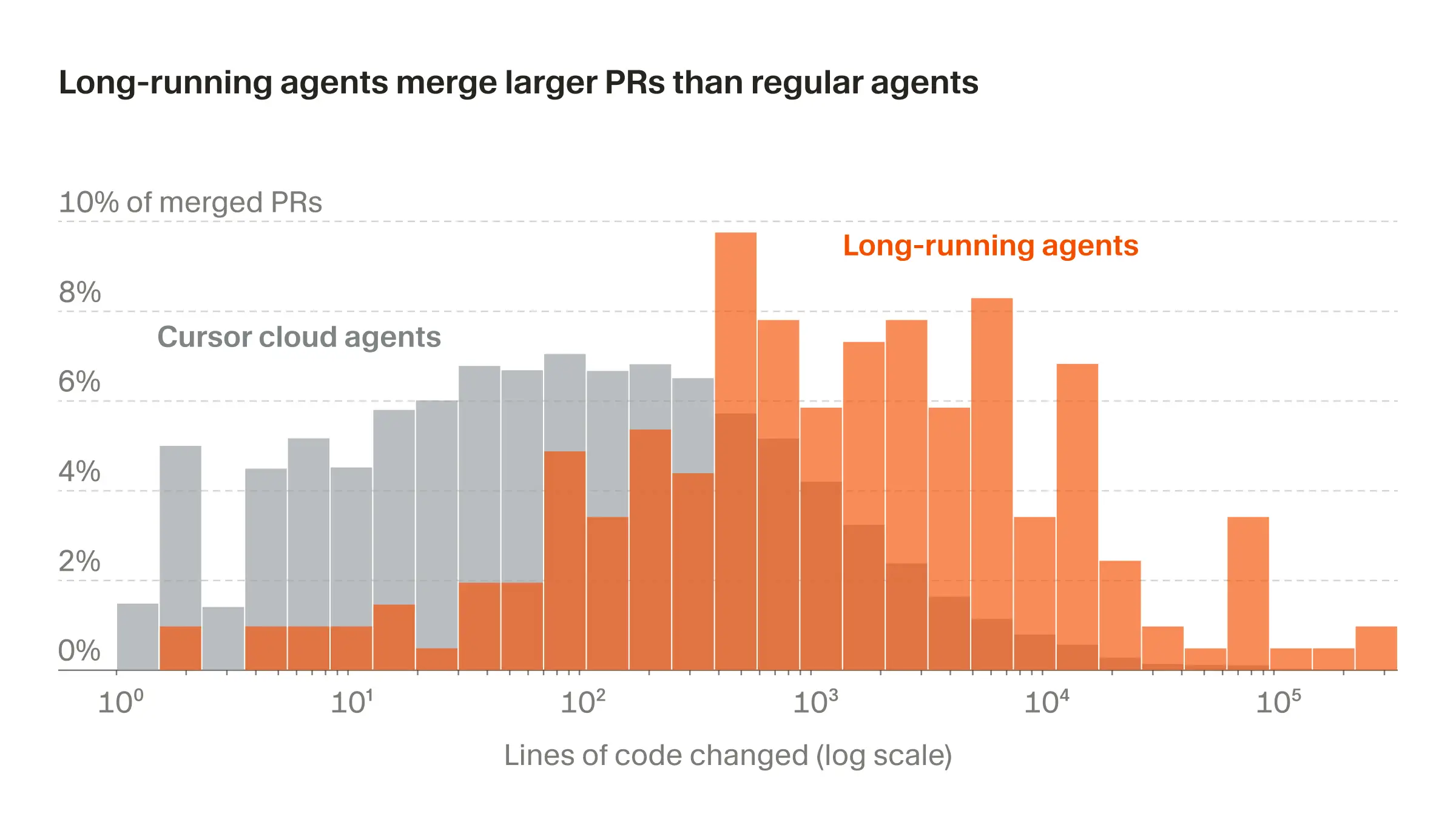
一、范式跃迁:当 AI 学会“先想再做”
传统 AI 编码工具的致命短板,在于缺乏长期记忆与任务连贯性。就像让一个人蒙着眼睛拼千片拼图——每拼一块都要你重新描述整体图案,稍有偏差整幅图就歪了。
Long-Running Agents 的核心突破在于引入 “规划先行”机制 :
- 第一步:智能体先输出完整执行计划(拆解任务、识别依赖、预估风险)
- 第二步:开发者审核并批准计划(关键决策点保留人类控制权)
- 第三步:智能体自主执行,期间多代理交叉验证工作成果
💡 类比:这好比装修房子。传统 AI 是“你说一句它动一下”的工人;Long-Running Agent 则是先给你看 3D 设计图、材料清单、工期表,你点头后它自己协调水电工、泥瓦匠、油漆工,几天后直接交房。
cursor团队亲自下场测试用cursor从零开始构建一个网络浏览器。这些智能体持续运行了近一周时间,在超过1000个文件中编写了逾100万行代码。
尽管代码库规模庞大,新的智能体仍能理解其内容并取得实质性进展。数百个工作单元并行运行,共同向同一分支提交代码,且极少产生冲突。

二、架构哲学:用“组合”破解复杂性
Cursor 没有采用传统分布式系统的复杂协调机制,而是借鉴了 Unix 哲学——“做一件事,并把它做好”:
| 角色 | 职责 | 类比 |
|---|---|---|
| Planner(规划者) | 持续扫描代码库,拆解大目标为原子任务,可递归生成子规划者 | 项目经理:制定路线图,分配任务卡 |
| Worker(执行者) | 专注完成单一任务,不关心全局,完成后直接提交变更 | 专项工程师:只管把手头模块做到极致 |
| Judge(裁判) | 每轮迭代后评估进度,决定是否继续 | 质检员:验收阶段性成果 |
这种角色分离设计意外地解决了大规模协作的瓶颈 [[1]]:
- ✅ 避免单智能体“隧道视野”(tunnel vision)导致的路径依赖
- ✅ 数百个 Worker 可并发提交到同一分支,冲突率极低
- ✅ 移除早期设计的“整合者”角色后,系统反而更健壮(少即是多)
🌟 设计启示:复杂问题的最优解,往往不是增加协调层,而是通过职责隔离降低耦合度——这与 Go 语言“组合优于继承”的哲学异曲同工。
三、实证数据:从“玩具项目”到“生产级交付”
在研究预览阶段,Long-Running Agents 已完成多个令人瞠目的工程实践 [[2]]:
| 项目 | 规模 | 耗时 | 人类干预 |
|---|---|---|---|
| 全功能聊天平台 | 151k 行代码 PR | 52 小时 | 仅批准初始计划 |
| 视频渲染引擎优化 | Rust 重写 + 自定义内核 | 未披露 | 零干预,性能提升 25 倍 |
| Solid → React 迁移 | +266K/-193K 行变更 | 3 周 | 通过 CI 检查 |
| 从零构建网页浏览器 | 100 万行代码 / 1000 个文件 | 近 1 周 | 持续自主运行 |
关键指标突破 :
- 🔸 产出的 PR 体积显著大于传统智能体(平均 10 倍以上)
- 🔸 合并率与传统智能体持平(证明质量未因规模牺牲)
- 🔸 90% 以上任务无需中途干预(开发者可关闭电脑去度假)
四、为何它能“不跑偏”?三大工程巧思
前沿大模型在长周期任务中常犯三类错误:遗忘目标、提前终止、过度简化。Cursor 通过三项设计规避:
1️⃣ 模型角色化分工
- GPT-5.2 担任 Planner(擅长长期规划与指令遵循)
- 专用编码模型担任 Worker(专注实现细节)
- 拒绝“万能模型”幻想:不同角色用最适合的模型 [[1]]
2️⃣ 轻量级状态管理
- 每轮迭代后重置上下文,避免错误累积
- 通过代码库本身作为“外部记忆”(而非依赖脆弱的对话历史)
- Judge 代理在周期边界做质量闸门
3️⃣ 提示工程即架构
- 80% 的行为差异源于提示词设计而非模型能力 [[1]]
- 通过精心设计的系统提示,抑制智能体的“偷懒倾向”(如 Opus 4.5 喜欢提前交卷)
- 强制要求边缘用例覆盖与测试生成
五、重新定义“人机协作”边界
Long-Running Agents 的真正革命性,在于重新划分人类与 AI 的责任边界:
| 传统模式 | Long-Running 模式 |
|---|---|
| 人类:持续监督、频繁纠正 | 人类:定义目标、审核计划、验收结果 |
| AI:执行原子操作 | AI:端到端交付完整功能 |
| 协作成本:高(注意力碎片化) | 协作成本:低(异步、批量处理) |
🚀 开发者体验跃迁:你可以在周五下班前启动一个 48 小时的重构任务,周一早上直接 Review 一个包含完整测试、文档、性能优化的 PR——这曾是科幻场景,如今正在发生。
六、冷静看待:它不是银弹
尽管前景激动人心,Long-Running Agents 仍有明确边界 :
- ❌ 不适合需求频繁变更的探索性开发(计划易失效)
- ❌ 无法替代架构决策(仍需人类定义“做什么”)
- ❌ 对初始提示质量高度敏感(垃圾进=垃圾出放大版)
但它的价值已足够清晰:将开发者从“提示词调教师”解放为“产品架构师”,让人类专注高价值决策,机器处理规模化执行。
结语:通往“自驾驶代码库”的第一步
Long-Running Agents 不是终点,而是 Cursor 通往 “自驾驶代码库”(Self-Driving Codebase) 愿景的关键里程碑 [[2]]。当 AI 能自主维护、演进、优化整个代码库时,软件开发将从“手工业”迈入“自动化工业”时代。
而这一切的起点,不过是让 AI 学会了一件事:先想清楚,再动手做——这或许也是所有优秀工程师的共同特质。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献67条内容
已为社区贡献67条内容

所有评论(0)