大模型私有化部署:小白程序员必看,收藏这份决策指南!
本文从管理和决策视角探讨大模型私有化部署的必要性,将私有化比作从“租房”到“自建房”的转变,强调其核心在于获得对数据、模型和环境的完全控制权。文章分析了私有化的六大核心驱动力,包括数据安全、合规性、定制化、性能、成本可控性和技术自主性,并提供了一个简单的决策问卷帮助读者判断是否需要私有化。此外,还介绍了私有化部署的两种主要形态(本地部署和私有云部署),以及典型适用场景和实施前的需求分析框架。最后,
本文从管理和决策视角探讨大模型私有化部署的必要性,将私有化比作从“租房”到“自建房”的转变,强调其核心在于获得对数据、模型和环境的完全控制权。文章分析了私有化的六大核心驱动力,包括数据安全、合规性、定制化、性能、成本可控性和技术自主性,并提供了一个简单的决策问卷帮助读者判断是否需要私有化。此外,还介绍了私有化部署的两种主要形态(本地部署和私有云部署),以及典型适用场景和实施前的需求分析框架。最后,文章强调在技术选型前应先想清楚决策问题,将私有化视为组织智能化升级的关键拼图。
—— 给还在犹豫“要不要私有化”的你
一、为什么大家都在谈“大模型私有化”?

过去两年,大模型已经从“新玩具”变成了许多组织的“新基础设施”:写材料、写代码、做分析、陪练决策……但在真正把大模型用进业务之前,几乎所有管理者都会遇到同一个问题——到底要不要做私有化部署?
一边是公共云 API,用起来简单、版本永远最新;另一边是“把模型搬回家”,听起来安全、长期更可控,但又意味着预算、团队和长期维护。
这篇文章不讨论具体的技术选型(不聊哪家 GPU、哪种容器、哪款框架),而是从管理和决策的视角,帮你梳理:
•什么是“大模型私有化部署”,它本质在变什么?
•私有化到底解决了哪些问题,适合谁?
•你应该如何系统性地分析需求,并做出“要不要私有化”的决策?
二、私有化部署的核心概念:从“租房”到“自建房”
1. 定义:从“服务消费”到“资产持有”
简单来说,大模型私有化部署,是把你对大模型的使用方式,从“按次消费服务”(公共云 API),转变为“自己持有一整套能力”(模型、推理服务、数据与集成),本质上是一种从“租房”到“自建房”的迁移。
可以用一个很直观的比喻来理解:
•“租房”(公共云 API):你用的是别人家的房子(算力与平台),优点是开箱即用、随时可退;缺点是隐私有限、规则由房东说了算,涨价与关门都不在你掌控之中。
•“自建房”(私有化部署):你在自己控制的地盘上搭了一套完整的房子(模型服务与数据平台),从此户型怎么改、墙上装什么、谁能进门,都是你说了算。
所以,私有化部署的真正目标,不只是“把模型放到本地”,而是为了获得对数据、模型、运行环境和集成方式的完全控制权。
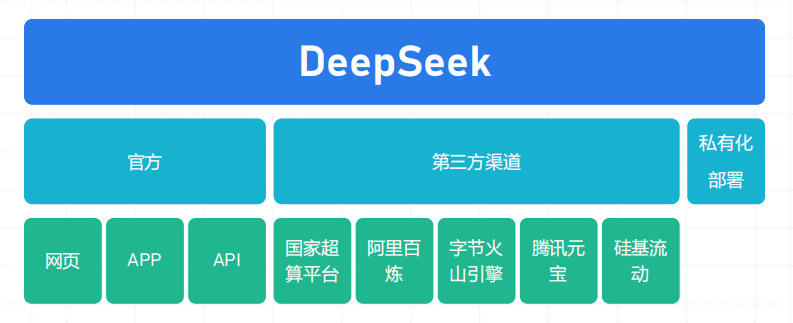
2. 两种主要形态:本地部署 vs 私有云部署
在实际项目中,“私有化部署”通常有两种主要形态,它们的差别不是“用不用云”,而是:谁拥有环境的最终控制权,以及数据到底在哪里流转。
1.本地部署(On-Premise)
指在企业自有的数据中心、机房或边缘节点上落地大模型服务。硬件、网络、物理安全都在自己手里,属于控制力最强的一种形态。
它适合那些对数据主权有极致要求的组织,例如某些政府、军工、金融核心业务系统等——要求“数据一比特都不能出网”。
2.私有云部署(Private Cloud)
指在云服务商为你划定的隔离环境中部署大模型(例如专属 VPC / 专有云等)。底层依然运行在云上,但你的网络与资源与公有云用户严格逻辑隔离,数据可以只在你的私有网络里流转。
它在安全性和便利性之间提供了一个折中方案:既保留了云的弹性伸缩与托管能力,又能做到数据不直接暴露在公共互联网中。
三、为什么要私有化:六大核心驱动力
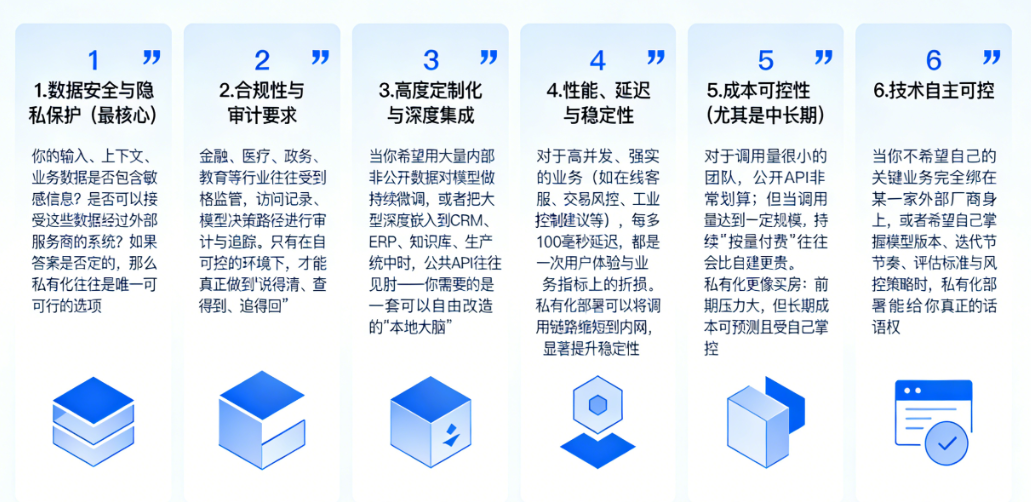
并不是所有团队都需要私有化,但对于一部分组织来说,不做私有化,就意味着很难真正释放大模型的价值。文档中可以提炼出六个常见的驱动力:
3.数据安全与隐私保护(最核心的一条)
你的输入、上下文、业务数据是否包含敏感信息?是否可以接受这些数据经过外部服务商的系统?如果答案是否定的,那么私有化往往是唯一可行的选项。
4.合规性与审计要求
金融、医疗、政务、教育等行业往往受到严格监管,需要对数据流向、访问记录、模型决策路径进行审计与追踪。只有在自己可控的环境下,才能真正做到“说得清、查得到、追得回”。
5.高度定制化与深度集成
当你希望用大量内部非公开数据对模型做持续微调,或者把大模型深度嵌入到 CRM、ERP、知识库、生产系统中时,公共 API 往往捉襟见肘——你需要的是一套可以自由改造的“本地大脑”。
6.性能、延迟与稳定性
对于高并发、强实时的业务(如在线客服、交易风控、工业控制建议等),每多 100 毫秒延迟,都是一次用户体验与业务指标上的折损。私有化部署可以将调用链路缩短到内网,显著提升稳定性。
7.成本可控性(尤其是中长期)
对于调用量很小的团队,公开 API 非常划算;但当调用量达到一定规模,持续“按量付费”往往会比自建更贵。私有化更像买房:前期压力大,但长期成本可预测且受自己掌控。
8.技术自主可控
当你不希望自己的关键业务完全绑在某一家外部厂商身上,或者希望自己掌握模型版本、迭代节奏、评估标准与风控策略时,私有化部署能给你真正的话语权。
四、我需不需要私有化?一个简单的决策问卷
与其在技术细节里纠结,不如先用几个问题快速筛一筛:你到底适不适合做大模型私有化部署。下面这个简单的决策问卷,来自实际项目中的常见判断逻辑:
1. 五个关键问题
•【数据与合规】你的核心场景,是否涉及隐私数据、机密数据或者受强监管的数据?
•【模型定制化】你是否计划用大量内部非公开数据,持续对模型做微调或训练?
•【性能与集成】你的关键业务,是否需要低延迟、高并发,并且要深度嵌入内网系统?
•【成本与规模】预计调用量是否很大,以至于长期 API 费用会非常可观?
•【技术与运维】你是否有能力(或预算)组建小规模的平台 / 运维团队,来管理服务器、网络与模型服务?
2. 如何解读你的答案?
可以用一个很直观的规则来判断:
•“是” ≥ 3 个:强烈建议认真规划私有化部署。
•“是” 为 1–2 个:可以考虑混合云或者高安全等级的托管方案。
•全部为“否”:公共云 API 可能是更省钱、更省心的选择。
这套问卷的价值,在于把“技术问题”先还原成“业务与管理问题”:你的目标是什么、你能接受多大的风险、你愿意投入多少资源。
五、典型适用场景:哪些组织更适合私有化?

从行业与场景角度来看,以下类型的组织,往往更有动力、也更有必要推进大模型私有化部署:
•金融服务:内部信贷风控、交易分析、智能投顾、反洗钱监测等,需要处理大量非公开的交易与客户数据。
•医疗健康:基于电子病历、影像报告、检验结果生成辅助诊疗建议,任何数据外流都可能构成严重事故。
•政府与公共事业:在内网环境中进行情报分析、政策评估、辅助决策,对安全与主权有极高要求。
•法律与专业服务:分析案件材料、合同与合规文件,涉及大量机密文档与客户隐私。
•大型企业内部“知识大脑”:把研发文档、制度流程、项目沉淀等全部接入模型,为员工提供统一的智能助理。
•先进制造与工业互联网:分析包含配方、工艺参数与良率数据的生产日志,为工艺优化与质量控制提供决策支持。
六、实施前的需求分析:先画清楚这三张图
很多项目一开始就陷入“买哪台服务器、用哪个框架”的争论,其实更重要的是在决策之前,先把需求分析做扎实。可以从三张“管理视角”的图开始:
1. 场景图:列出你真正想解决的问题
把目前所有和大模型相关的想法与需求,整理成清晰的场景清单,例如:文案生成、代码助手、内部搜索、客服机器人、数据分析助手等,并按“价值 / 紧急程度”做简单排序。

2. 数据图:搞清楚哪些数据可以“离家”,哪些绝不能
对每一个场景,标注会涉及到的数据类型,做一个粗粒度的数据分级:公开数据、内部公开数据、敏感数据与受监管数据。不同级别的数据,对应完全不同的部署策略。

3. 系统图:标出需要集成的关键系统
列出需要与大模型打通的核心系统(如客服系统、工单系统、知识库、业务中台等),思考:它们处于什么网络环境?有没有访问限制?是只读调用,还是需要写入?
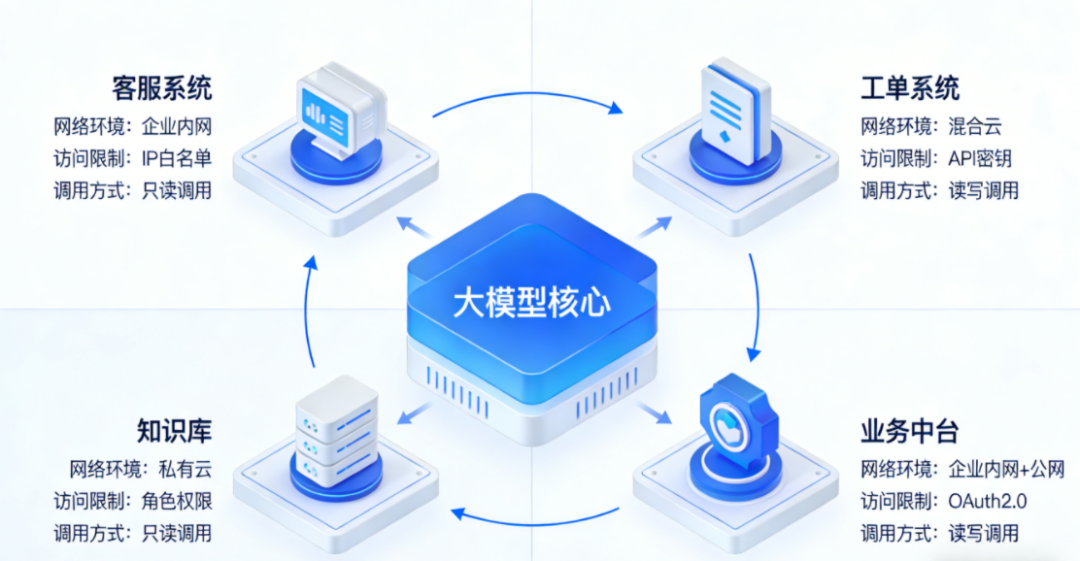
当这三张图画清楚之后,你就会发现:很多原本抽象的“要不要私有化”问题,会自然变成一组可以讨论、可以权衡、可以记录的管理决策。
七、总结:技术选型之前,先把决策问题想清楚
大模型私有化部署不是一场“技术冲动”,而是一场“长期承诺”:它决定了你未来几年如何使用和管理智能能力。
在真正决定之前,不妨先记住三个关键点:
•这是从“租房”到“自建房”的选择,本质是对控制权和责任的重新分配。
•先答好“需不需要”的问题,再讨论“怎么做”,避免为了技术而技术。
•把数据、安全、场景与组织能力一起纳入考量,才可能做出真正稳妥的决策。
最后
我在一线科技企业深耕十二载,见证过太多因技术更迭而跃迁的案例。那些率先拥抱 AI 的同事,早已在效率与薪资上形成代际优势,我意识到有很多经验和知识值得分享给大家,也可以通过我们的能力和经验解答大家在大模型的学习中的很多困惑。
我整理出这套 AI 大模型突围资料包:
- ✅AI大模型学习路线图
- ✅Agent行业报告
- ✅100集大模型视频教程
- ✅大模型书籍PDF
- ✅DeepSeek教程
- ✅AI产品经理入门资料
完整的大模型学习和面试资料已经上传带到CSDN的官方了,有需要的朋友可以扫描下方二维码免费领取【保证100%免费】👇👇

为什么说现在普通人就业/升职加薪的首选是AI大模型?
人工智能技术的爆发式增长,正以不可逆转之势重塑就业市场版图。从DeepSeek等国产大模型引发的科技圈热议,到全国两会关于AI产业发展的政策聚焦,再到招聘会上排起的长队,AI的热度已从技术领域渗透到就业市场的每一个角落。
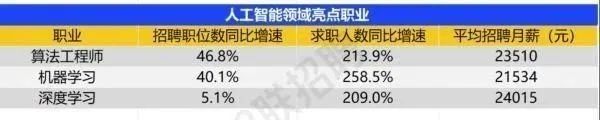
智联招聘的最新数据给出了最直观的印证:2025年2月,AI领域求职人数同比增幅突破200% ,远超其他行业平均水平;整个人工智能行业的求职增速达到33.4%,位居各行业榜首,其中人工智能工程师岗位的求职热度更是飙升69.6%。
AI产业的快速扩张,也让人才供需矛盾愈发突出。麦肯锡报告明确预测,到2030年中国AI专业人才需求将达600万人,人才缺口可能高达400万人,这一缺口不仅存在于核心技术领域,更蔓延至产业应用的各个环节。


资料包有什么?
①从入门到精通的全套视频教程⑤⑥
包含提示词工程、RAG、Agent等技术点
② AI大模型学习路线图(还有视频解说)
全过程AI大模型学习路线

③学习电子书籍和技术文档
市面上的大模型书籍确实太多了,这些是我精选出来的

④各大厂大模型面试题目详解

⑤ 这些资料真的有用吗?
这份资料由我和鲁为民博士共同整理,鲁为民博士先后获得了北京清华大学学士和美国加州理工学院博士学位,在包括IEEE Transactions等学术期刊和诸多国际会议上发表了超过50篇学术论文、取得了多项美国和中国发明专利,同时还斩获了吴文俊人工智能科学技术奖。目前我正在和鲁博士共同进行人工智能的研究。
所有的视频教程由智泊AI老师录制,且资料与智泊AI共享,相互补充。这份学习大礼包应该算是现在最全面的大模型学习资料了。
资料内容涵盖了从入门到进阶的各类视频教程和实战项目,无论你是小白还是有些技术基础的,这份资料都绝对能帮助你提升薪资待遇,转行大模型岗位。


智泊AI始终秉持着“让每个人平等享受到优质教育资源”的育人理念,通过动态追踪大模型开发、数据标注伦理等前沿技术趋势,构建起"前沿课程+智能实训+精准就业"的高效培养体系。
课堂上不光教理论,还带着学员做了十多个真实项目。学员要亲自上手搞数据清洗、模型调优这些硬核操作,把课本知识变成真本事!


如果说你是以下人群中的其中一类,都可以来智泊AI学习人工智能,找到高薪工作,一次小小的“投资”换来的是终身受益!
应届毕业生:无工作经验但想要系统学习AI大模型技术,期待通过实战项目掌握核心技术。
零基础转型:非技术背景但关注AI应用场景,计划通过低代码工具实现“AI+行业”跨界。
业务赋能 突破瓶颈:传统开发者(Java/前端等)学习Transformer架构与LangChain框架,向AI全栈工程师转型。
👉获取方式:
😝有需要的小伙伴,可以保存图片到wx扫描二v码免费领取【保证100%免费】🆓**


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 9
9 0
0- 0



 已为社区贡献650条内容
已为社区贡献650条内容

所有评论(0)