Flink Savepoint 可控升级、可回滚、可分叉的“状态快照”
Savepoint 是 Flink 流作业的一致性状态快照,包含二进制状态文件和元数据文件。其核心机制基于 OperatorID 与状态的映射关系,恢复时依赖算子显式设置的 uid 进行准确匹配。生产环境必须为所有算子设置 uid,避免因自动生成 ID 变更导致状态恢复失败。Savepoint 支持两种格式:跨后端的 canonical 格式和性能优先的 native 格式。运维操作包括触发保存、
1. Savepoint 是什么
Savepoint 可以理解为:Flink 为流作业拍下的一张一致性状态照片。
它由两部分构成:
- 一个目录:里面是(通常很大)的二进制状态文件,存放在稳定存储上(HDFS、S3、对象存储等)
- 一个相对较小的元数据文件:通常叫
_metadata,里面记录了该 Savepoint 包含哪些状态文件、这些文件的相对路径等“索引信息”
从恢复角度看,Savepoint 让你可以:
- Stop & Resume:停掉作业,再从保存的状态继续跑
- Fork:从同一个 Savepoint 派生出多个作业(做灰度、实验分支)
- Upgrade:代码升级/拓扑调整后继续沿用旧状态
2. Savepoint 里到底存了什么:OperatorID -> State
Savepoint 本质上保存的是一张映射表:
| Operator UID | 对应状态 |
|---|---|
| source-id | StatefulSource 的状态(如消费位点、内部缓存等) |
| mapper-id | StatefulMapper 的状态(如去重集合、窗口累加器等) |
注意:无状态算子不会出现在 Savepoint 中(例如简单 print() 这种)。
因此,Savepoint 恢复的关键在于:新作业能否把 Savepoint 里的状态条目,准确映射回新拓扑里的算子。
而这件事的成败,几乎全靠一个东西:uid(String)。
3. 为什么必须给算子显式设置 uid
如果你不手动设置 uid,Flink 会自动生成。自动生成的 ID 依赖程序结构,非常“敏感”:
- 你改了算子顺序、插了一个 map、重构了一段逻辑
- 自动 ID 可能就变了
- 结果:旧 Savepoint 里的状态找不到对应算子,恢复失败,或者更可怕的是映射错了(特别是在允许跳过未恢复状态时)
生产建议:给所有算子都设置 uid,不要只给你以为“有状态”的那部分。
原因很简单:Flink 内置的很多算子(如 window)是有状态的,而且不总是显而易见。
示例(你提供的结构我稍微补充了注释):
DataStream<String> stream = env
// Stateful source(例如 Kafka Source)建议显式 uid
.addSource(new StatefulSource())
.uid("source-id")
.shuffle()
// Stateful mapper 显式 uid
.map(new StatefulMapper())
.uid("mapper-id")
// Stateless sink(无状态)不在 savepoint 里
.print();
一句话总结:uid 是 Savepoint 恢复时的“身份证”。身份证不稳定,状态就无家可归。
4. Savepoint 的目录结构长什么样
假设配置目标目录为 /savepoints/,一次 savepoint 可能长这样:
- Savepoint 目标目录:
/savepoints/ - 本次 Savepoint 目录:
/savepoints/savepoint-<shortJobId>-<savepointId>/ - 元数据文件:
/savepoints/savepoint-.../_metadata - 具体状态文件:
/savepoints/savepoint-.../...
可迁移性:通常你把整个 savepoint 目录搬走(复制到新集群/新路径),仍然可以恢复。
但有两个常见例外(你给的内容也提到了):
- 开启了路径熵注入(entropy injection)
这会把文件打散到很多目录,元数据里可能出现绝对路径引用,导致“整体目录搬迁”失效 - 作业包含 task-owned state(任务自持有状态),例如某些 sink 的写前日志类实现
这类状态可能不完全由 savepoint 根目录可控
另外还有一个容易误判的点:如果你用的是 state.backend: jobmanager,状态可能都在 _metadata 文件里,看不到额外大文件别慌,不是丢了,是它就这么存的。
5. Savepoint vs Checkpoint:别混用概念
很多人第一次踩坑就是把 Savepoint 当成“手动 checkpoint”。
它们的核心差异可以这么理解:
- Checkpoint:主要用于故障自动恢复,由系统周期性触发,生命周期通常由 Flink 管
- Savepoint:主要用于运维控制(升级/迁移/分叉),由用户触发,通常由用户管理
你给的内容里还有一个非常关键的语义变化:
从 Flink 1.15 开始,中间 Savepoint(非 stop-with-savepoint 生成的)不用于故障恢复,也不会提交副作用。
这意味着在“多个作业共享同一 checkpoint 时间线”时会出现复杂风险:
原作业打了 savepoint 后又失败,可能回退到更早的 checkpoint;而你从 savepoint 恢复的新作业可能会提交一些“在原时间线里从未真正发生”的事务(遇到非确定性更危险)。
更稳妥的做法(你给的建议非常实用):
在这些复杂场景下,对事务型 sink 丢弃其状态更安全,最直接的方法就是“改 sink 的 uid”,让它不再继承旧状态。
如果你是单作业串行升级(先停旧作业,再从 savepoint 起新作业),风险会小很多。
6. Savepoint 的两种格式:canonical vs native
Savepoint 支持两种二进制格式:
canonical(默认,最稳定)
- 跨 State Backend 更友好:例如从一个 backend 生成的 savepoint,在另一个 backend 上恢复
- 兼容性目标更强:更倾向于长期稳定、可升级
代价:往往更慢(保存和恢复都可能偏慢)。
native(Flink 1.15 引入,性能优先)
- 用当前 backend 的“原生快照格式”存,比如 RocksDB 的 SST 文件
- 优点:通常更快
- 对 RocksDB:还支持增量 RocksDB savepoint(语义上更贴近 RocksDB 的增量 checkpoint)
实际选择建议:
- 你要跨 backend、跨环境迁移、追求兼容:优先 canonical
- 你 RocksDB 状态很大、savepoint/恢复时间敏感:优先 native
7. 常用运维命令:触发、停机保存、恢复、销毁
7.1 触发 Savepoint
bin/flink savepoint :jobId [:targetDirectory]
指定格式:
bin/flink savepoint --type [native/canonical] :jobId [:targetDirectory]
状态很大时,客户端可能等待超时,可以用 detached 模式:
bin/flink savepoint :jobId [:targetDirectory] -detached
detached 会立刻返回 trigger id,你可以通过 REST API 查询进度。
7.2 YARN 环境触发
bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
7.3 原子化“停机并保存”(强烈推荐用于升级)
bin/flink stop --type [native/canonical] --savepointPath [:targetDirectory] :jobId
这个动作的价值在于“原子”:savepoint 成功 + 作业停止作为一个整体完成,升级链路更可控。
7.4 从 Savepoint 恢复运行
bin/flink run -s :savepointPath [:runArgs]
:savepointPath 可以是 savepoint 目录,也可以直接指向 _metadata 文件。
7.5 允许跳过无法映射的状态(慎用)
bin/flink run -s :savepointPath -n [:runArgs]
# -n 等价于 --allowNonRestoredState
风险点必须说清楚:
如果你没显式 uid,Flink 默认会按拓扑顺序重新分配 uid,可能导致“状态映射到错误算子”,造成正确性事故。
所以这条命令在生产里要配套两件事:
- 所有算子显式 uid
- 你明确知道哪些状态被丢弃,以及丢弃后业务语义仍然正确
7.6 Claim Mode:恢复后谁拥有这些文件
恢复时可以指定 claim mode:
bin/flink run -s :savepointPath -claimMode :mode -n [:runArgs]
有三个模式(其中 LEGACY 已弃用):
NO_CLAIM(默认,通常最稳妥)
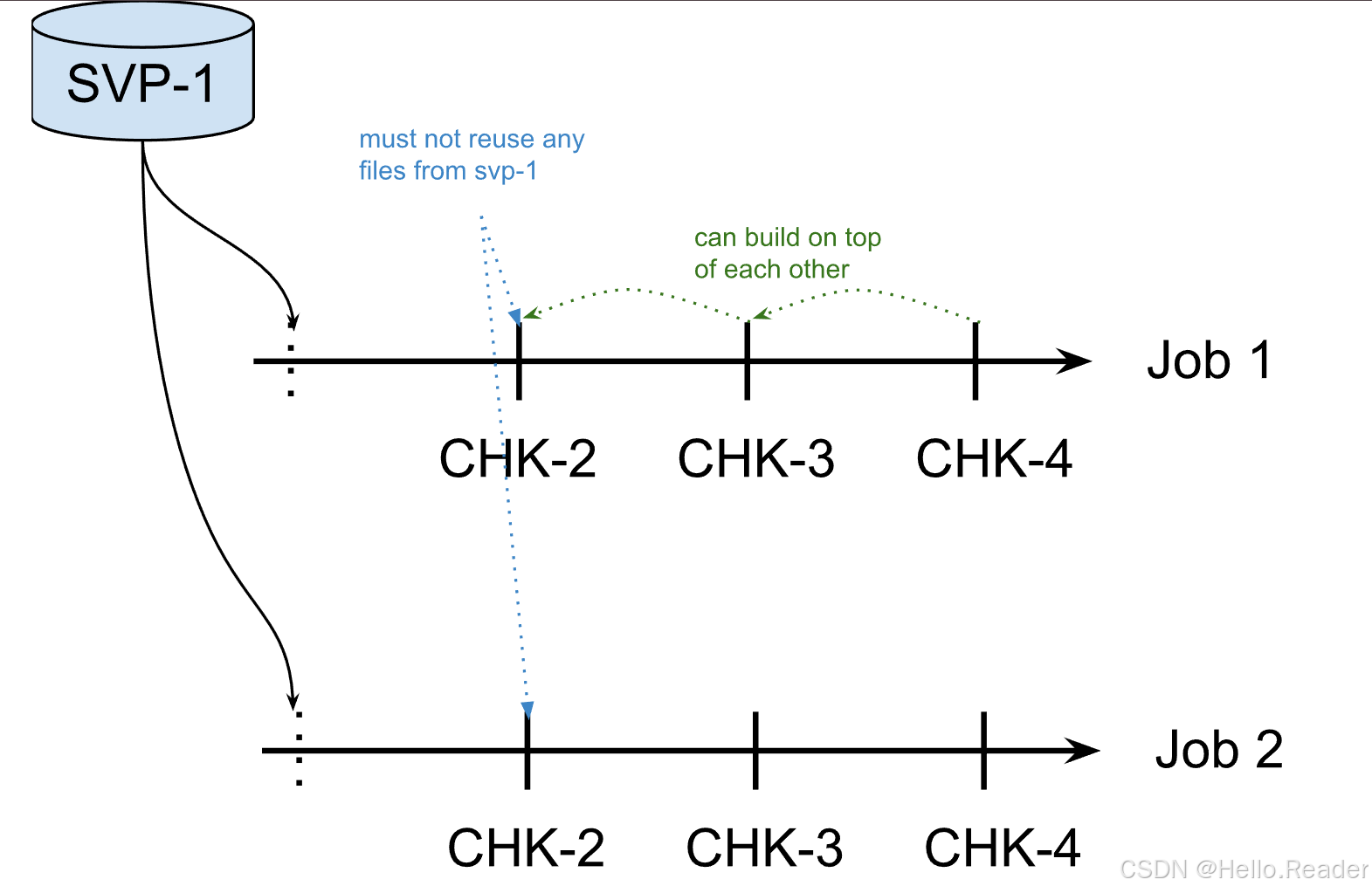
- Flink 不“接管” snapshot 文件
- 不会删除这些文件
- 你可以从同一 snapshot 启多个作业(分叉实验很方便)
代价:为了避免依赖旧文件,Flink 会强制第一次 checkpoint 做全量(对 RocksDB 才有明显影响,因为其他 backend 本来就是全量)。
一旦新作业跑出一次成功 checkpoint,你就可以考虑手动删除旧 snapshot(删除太早会导致失败时无法回退)。
CLAIM(Flink 接管,像 checkpoint 一样管理生命周期)
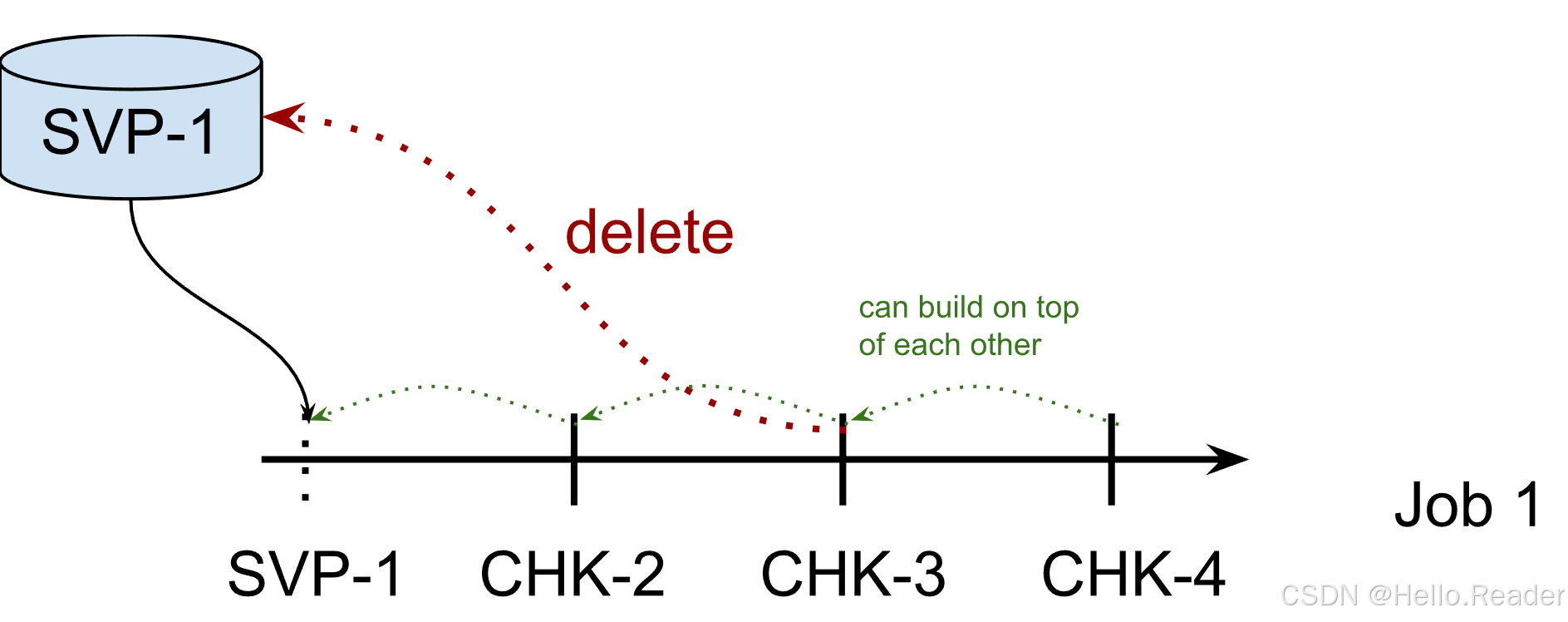
- Flink 可能在不需要时删除 snapshot 文件
- 不安全:不能从同一 snapshot 启多个作业
- 也不建议你手动删除 snapshot
另外一个细节:Flink 只接管 <job_id>/chk-x 这种 checkpoint 单元,不会删除旧 job 的根目录。
LEGACY(deprecated)
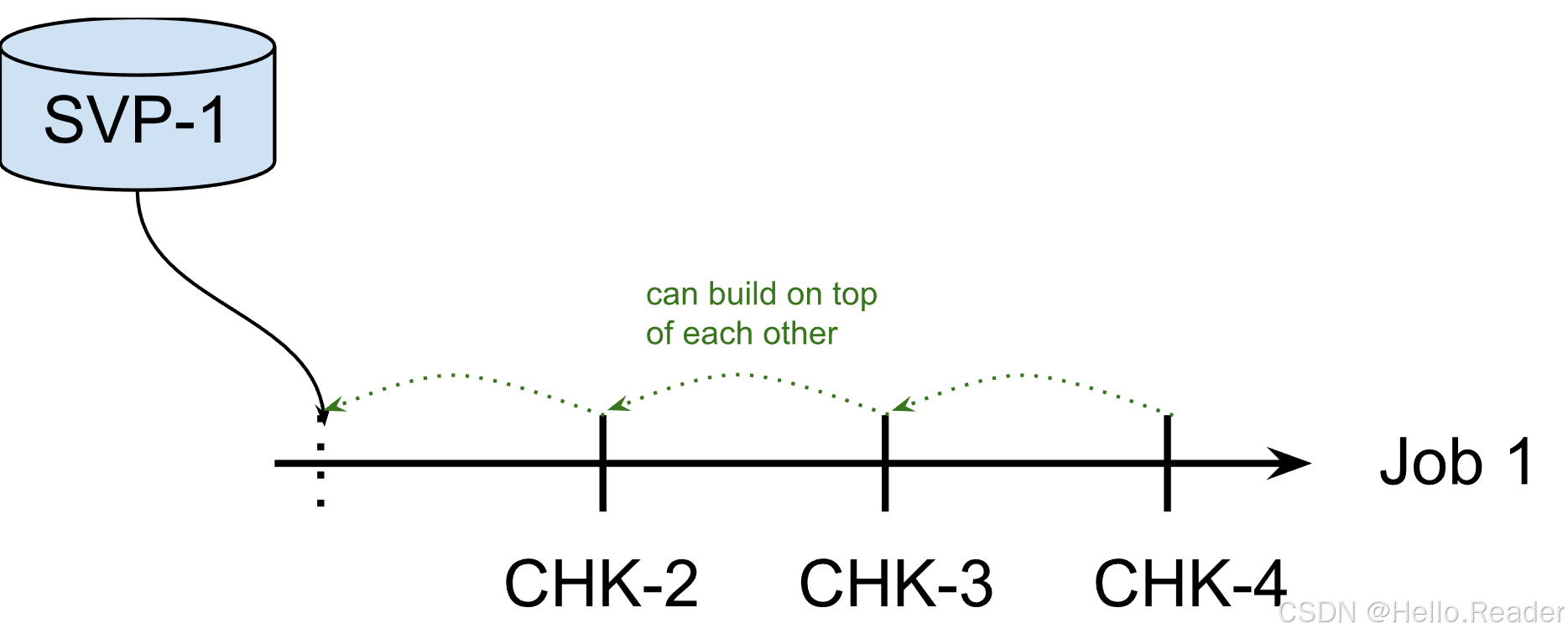
- 1.15 前的行为,所有权不清晰
- 已废弃,Flink 2.0 会移除
生产上别用
7.7 销毁 Savepoint(由 Flink 清理文件)
bin/flink savepoint -d :savepointPath
也可以手工删目录(savepoint 通常自包含),但用 -d 更“有仪式感”,适合做标准化运维流程。
8. 配置默认 Savepoint 目录
如果不配置默认目录、也不在命令里传 targetDirectory,触发 savepoint 会失败。
配置项:
execution.checkpointing.savepoint-dir
示例(你提供的是 hdfs):
execution.checkpointing.savepoint-dir: hdfs:///flink/savepoints
前提条件永远别忘:目标目录必须 JobManager 与 TaskManager 都可访问
也就是说:本地磁盘路径通常不行,除非你确定所有节点共享挂载。
9. 生产最佳实践清单(可直接抄进你的运维规范)
- 所有算子显式
uid(),包括你觉得“无状态”的算子 - 升级优先用
stop --savepointPath,保证“停机+保存”原子化 - RocksDB 状态很大且时间敏感:评估
--type native - 需要从同一 snapshot 起多个作业(分叉/灰度/回放):用
NO_CLAIM - 使用
--allowNonRestoredState前,先确保 uid 全稳定,再明确“丢哪些状态不会出事故” - 涉及事务型 sink、多作业共享 checkpoint 时间线:谨慎处理中间 savepoint 的语义差异,必要时通过更改 sink uid 丢弃其旧状态
- Savepoint 迁移通常可行,但如果开启 entropy injection 或存在 task-owned state,要提前验证“可搬迁性”
- 恢复后至少跑通一次成功 checkpoint,再考虑删除旧 snapshot(避免失败时无路可退)
10. FAQ:最常见的五个问题
Q1:我是不是只要给有状态算子设置 uid 就行?
理论上是,但生产上更推荐“全设置”。因为内置算子是否有状态不总是明显,少设一个就可能在升级时踩坑。
Q2:新增一个需要状态的算子,会发生什么?
Savepoint 里没有它的状态,它会以“空状态”启动,相当于初始运行。
Q3:删除一个有状态算子,会发生什么?
默认恢复会失败,因为旧 savepoint 里有它的状态条目但新拓扑找不到映射。
你可以用 --allowNonRestoredState 跳过,但要确保不会破坏业务语义。
Q4:我调整了算子顺序还能恢复吗?
如果你设置了 uid,一般没问题。
如果依赖自动生成 ID,顺序变了很可能就恢复不了。
Q5:恢复时能改并行度吗?
可以。Flink 支持从 savepoint 恢复时调整并行度(会做状态重分布)。
结语
Savepoint 的价值不在“能不能用”,而在“能不能可控地用”:
- 用 uid 把状态映射锁死
- 用 stop-with-savepoint 把升级链路锁死
- 用 claim mode 把文件所有权锁死
- 用格式选择(canonical/native)把时间成本锁死

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献59条内容
已为社区贡献59条内容

所有评论(0)