【AI大模型前沿】Qwen-Doc:阿里通义千问的长文本理解与推理技术解析
Qwen-Doc 是一个基于 Qwen3-30B-A3B 架构的长文本推理模型,通过系统化的后训练方案,显著提升长文本推理能力。该项目的核心目标是解决传统模型在长文本任务中的不足,如训练不稳定、上下文窗口有限等问题,并在多个长文本推理基准测试中表现出色,性能接近甚至超越顶尖模型。
系列篇章💥
目录
前言
随着人工智能技术的不断发展,长文本理解与推理成为自然语言处理领域的重要研究方向。Qwen-Doc 是阿里通义实验室推出的一个专注于长文本理解与推理的项目,旨在通过技术创新提升模型在处理复杂长文本任务中的表现。本文将详细介绍 Qwen-Doc 的项目背景、核心功能、技术原理、性能评估以及应用场景等内容,帮助读者全面了解这一前沿技术。
一、项目概述
Qwen-Doc 是一个基于 Qwen3-30B-A3B 架构的长文本推理模型,通过系统化的后训练方案,显著提升长文本推理能力。该项目的核心目标是解决传统模型在长文本任务中的不足,如训练不稳定、上下文窗口有限等问题,并在多个长文本推理基准测试中表现出色,性能接近甚至超越顶尖模型。
二、核心功能
(一)长文本推理
Qwen-Doc 能够处理和推理超长文本,如百万级 Token 的文档,解决跨段落、跨文档的复杂问题。它通过记忆增强框架,突破传统模型的上下文窗口限制,实现对超长文本的高效推理,显著提升长文本任务的处理能力。
(二)多跳推理
Qwen-Doc 支持多跳逻辑推理,能够通过多个步骤串联信息,完成复杂的推理任务。这种能力使其在处理需要多步逻辑推理的问题时表现出色,例如在长文档中寻找分散信息之间的关联。
(三)信息整合
Qwen-Doc 可以从长文本中提取和整合分散的信息,用于回答需要全局理解的问题。它通过高质量的数据合成管线,生成复杂的推理数据,提升模型在信息整合任务中的表现。
(四)记忆管理
Qwen-Doc 通过记忆管理框架,处理超出物理上下文窗口的任务。它采用多阶段融合强化学习训练,将单次推理与迭代式记忆处理相结合,将全局信息“折叠”到紧凑的记忆表示中,突破物理窗口的限制。
(五)通用能力提升
Qwen-Doc 在数学推理、智能体记忆和长对话等通用任务上有显著提升,表现出良好的泛化能力。它不仅在长文本推理任务中表现出色,还在其他通用任务中展现出强大的性能,提升了模型的整体能力。
三、技术揭秘
(一)高质量数据合成管线
通过“先拆解,后组合”的方式构建高质量的长文本推理数据。模型将长文档拆解为原子事实及其关系,利用知识图谱、多文档表格等工具,程序化地合成需要多跳推理和全局信息整合的复杂问题。
(二)稳定的强化学习方法
引入任务均衡采样和任务专属优势估计策略,应对长文本多任务训练中的数据分布偏移和奖励信号不稳定问题。同时,提出自适应熵控制策略优化(AEPO)算法,通过动态调控负梯度,平衡模型的探索与利用,有效解决长文本强化学习中的不稳定性,确保模型在更长的序列上稳定训练。
(三)突破物理窗口的记忆管理框架
设计记忆管理框架,通过多阶段融合强化学习训练,将单次推理与迭代式记忆处理相结合。模型在处理超长文本时,不依赖于有限的上下文窗口,通过分块处理和迭代记忆更新,将全局信息“折叠”到紧凑的记忆表示中,突破物理窗口的限制,实现对超长文本的高效推理。
四、性能表现
Qwen-Doc 在多个长文本推理基准测试中表现出色,性能接近甚至超越 GPT-5 等顶尖模型。例如,在 LongBench-V2 测试中,Qwen-Doc 的平均得分比基线模型 Qwen3-30B-A3B-Thinking 提高了 9.9 分,达到了 71.82 分,与 Gemini-2.5-Pro 的 72.40 分相当。在 MRCR 基准测试中,Qwen-Doc 的得分高达 82.99 分,显示出其在复杂推理任务中的强大能力。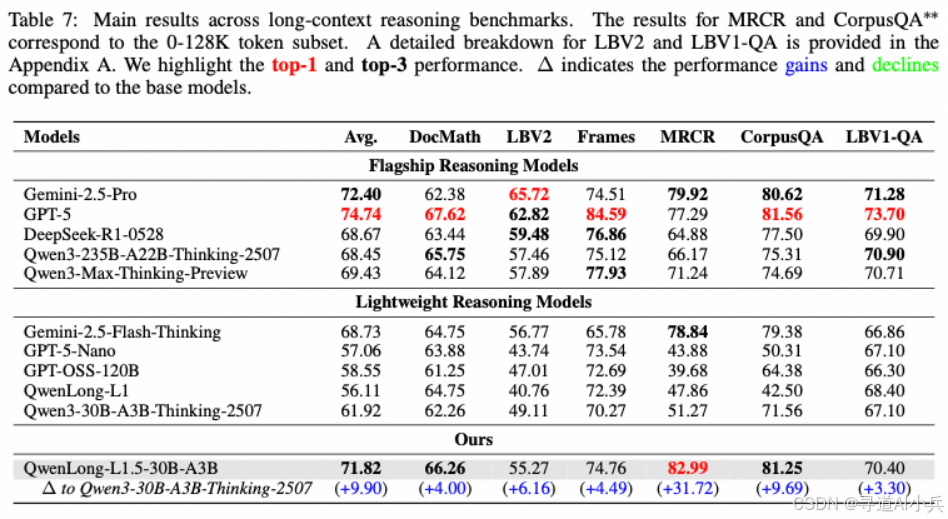
五、应用场景
(一)长文档分析
Qwen-Doc 能够高效分析财务报告、法律文件和学术文献等长文档,提取关键信息并进行多跳推理。它帮助专业人员快速理解复杂内容,辅助决策和研究。例如,在处理百万级 Token 的文档时,Qwen-Doc 可以准确地找到跨段落的关联信息,提供深度分析。
(二)代码理解和生成
Qwen-Doc 可以帮助开发者理解大型代码库,生成代码片段和补全建议。它通过长文本推理能力,理解代码逻辑和结构,提供精准的代码生成和优化建议,提升编程效率和代码质量。例如,在处理复杂的 Python 代码库时,Qwen-Doc 能够生成高质量的代码补全和优化建议。
(三)复杂问答系统
Qwen-Doc 适用于多跳问答和长文档查询,为智能客服和知识问答系统提供准确、深度的答案。它能够处理复杂的多步推理问题,从长文本中提取关键信息,生成高质量的回答。例如,在处理法律咨询或学术问题时,Qwen-Doc 能够提供详细的推理和答案。
(四)信息检索与整合
Qwen-Doc 优化搜索引擎结果,从长文本中提取知识构建知识图谱,提升信息检索的准确性和效率。它能够处理大规模文本数据,整合分散的信息,为用户提供全面的知识视图。例如,在处理新闻报道或学术文献时,Qwen-Doc 能够生成结构化的知识图谱,帮助用户快速找到所需信息。
(五)教育与学习
Qwen-Doc 辅助在线教育平台和智能辅导系统,帮助学生理解复杂学术问题,支持个性化学习。它能够生成详细的解释和推理过程,帮助学生更好地掌握知识。例如,在处理数学问题或科学实验时,Qwen-Doc 能够提供清晰的推理步骤和答案,辅助学生学习。
六、快速使用
Qwen-Doc 提供了多种部署和使用方式,方便用户快速上手。以下是基于 Hugging Face 的快速使用示例:
(一)安装依赖
# Create the conda environment
conda create -n qwenlongl1_5 python==3.10
conda activate qwenlongl1_5
# Install requirements
pip3 install -r requirements.txt
# Install verl, we use the 0.4 version of verl
git clone --branch v0.4 https://github.com/volcengine/verl.git
cd verl
pip3 install -e .
(二)模型推理
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B"
# load the tokenizer and the model
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map="auto"
)
# prepare the model input
template = """Please read the following text and answer the question below.
<text>
$DOC$
</text>
$Q$
Format your response as follows: "Therefore, the answer is (insert answer here)"."""
context = "<YOUR_CONTEXT_HERE>"
question = "<YOUR_QUESTION_HERE>"
prompt = template.replace('$DOC$', context.strip()).replace('$Q$', question.strip())
messages = [
# {"role": "system", "content": "You are QwenLong-L1, created by Alibaba Tongyi Lab. You are a helpful assistant."}, # Use system prompt to define identity when needed.
{"role": "user", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
# conduct text completion
generated_ids = model.generate(
**model_inputs,
max_new_tokens=50000,
temperature=0.7,
top_p=0.95
)
output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
# parsing thinking content
try:
# rindex finding 151649 (</think>)
index = len(output_ids) - output_ids[::-1].index(151668)
except ValueError:
index = 0
thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")
content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")
print("thinking content:", thinking_content)
print("content:", content)
七、结语
Qwen-Doc 作为阿里通义实验室在长文本理解与推理领域的重要成果,通过技术创新显著提升了模型在处理复杂长文本任务中的表现。其高质量的数据合成管线、稳定的强化学习方法和突破物理窗口的记忆管理框架,为长文本推理提供了强大的技术支持。Qwen-Doc 不仅在基准测试中表现出色,还在多个实际应用场景中展现出广泛的应用价值。未来,随着技术的进一步发展和优化,Qwen-Doc 有望在更多领域发挥重要作用。
项目地址
- GitHub 仓库:https://github.com/Tongyi-Zhiwen/Qwen-Doc
- Hugging Face 模型库:https://huggingface.co/Tongyi-Zhiwen/QwenLong-L1.5-30B-A3B
- 技术论文:https://arxiv.org/pdf/2512.12967

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 4
4 0
0- 0



 已为社区贡献52条内容
已为社区贡献52条内容

所有评论(0)