DeepSeek-OCR 2 人眼进化:OCR 最大问题,从来不是识字,而是不会读
传统OCR技术在处理复杂文档时存在明显缺陷,仅按像素顺序扫描会导致阅读顺序错乱、表格结构破坏等问题。DeepSeek-OCR2创新性地引入视觉因果流机制,通过语言模型Qwen2-0.5B作为编码器,模拟人类阅读时的逻辑顺序理解。该系统采用双注意力设计,既保留全局视觉特征,又强化因果推理能力,在保持计算效率的同时显著提升对公式、表格等复杂结构的识别准确率。这一突破标志着OCR技术从"识别字
第一次真正意识到 OCR 有问题,是在一篇论文 PDF 上。
那是一篇很标准的学术论文:双栏排版、公式穿插、表格横跨页面、图注在下方。我把它丢进一个号称“高精度 OCR”的系统里,结果输出让我哭笑不得:
-
左栏读到一半,突然跳到右栏的参考文献
-
公式被拆成零碎字符
-
表格像是被随机洗牌过

那一刻我突然意识到一个问题:这些 OCR 系统,其实根本不会“读文档”。它们只是——在“扫像素”。传统 OCR:像计算机一样“看”,而不是像人一样“读”绝大多数传统 OCR(包括很多今天仍在用的系统),本质逻辑都非常朴素:
-
从左上角开始
-
一行一行
-
一块一块
-
按像素顺序读完
这在简单文本块上是成立的,比如扫描合同、小说、说明书。但问题是——人类根本不是这样读文档的。
当你拿到一份复杂文档时,你几乎是下意识地:
-
先扫标题,建立全局预期
-
在段落之间跳转,而不是逐行盯着
-
看到表格、公式、图像,会自动“切换阅读模式”
-
追随的是逻辑与语义流,而不是固定的二维网格
也正因为如此,强行把二维文档压成一维阅读顺序,本身就会破坏语义。

我们要诚实一点:现在的 OCR(光学字符识别)技术,有时候真的挺像个不知变通的机器人。
你给它一张复杂的财务报表,或者一篇排版花哨的双栏论文,它大概率会做一件事:从左上角开始,一行一行地往右扫,直到右下角。
这就是所谓的“光栅扫描”(Raster Scan)。对于纯文本小说,这没问题。但对于那个夹杂着表格、公式、侧边栏注释的 PDF 文档,这种读取方式简直是灾难。它会把左栏的句子直接连到右栏去,或者把表格的表头和数据混成一锅粥。
作为人类,我们可不是这么阅读的。拿到一张报表,我会先看标题,然后跳到我关心的那个表格,扫一眼表头,再看具体数据,最后看看底下的备注。我们是按照“语义逻辑”在阅读,而不是按照“像素网格”。

最近,DeepSeek 发布的 DeepSeek-OCR 2 论文,让我眼前一亮。因为它终于问出了那个核心问题:
“我们能不能教 AI 像人一样,学习‘怎么读’,而不仅仅是‘读到了什么’?”
为什么传统 OCR 编码器会失败?
先说一个技术事实。大多数 OCR 编码器(包括很多 ViT-based 方案)都在做一件事:
-
把图像切成 patch
-
展平成一维序列
-
加上位置编码
-
丢进 Transformer
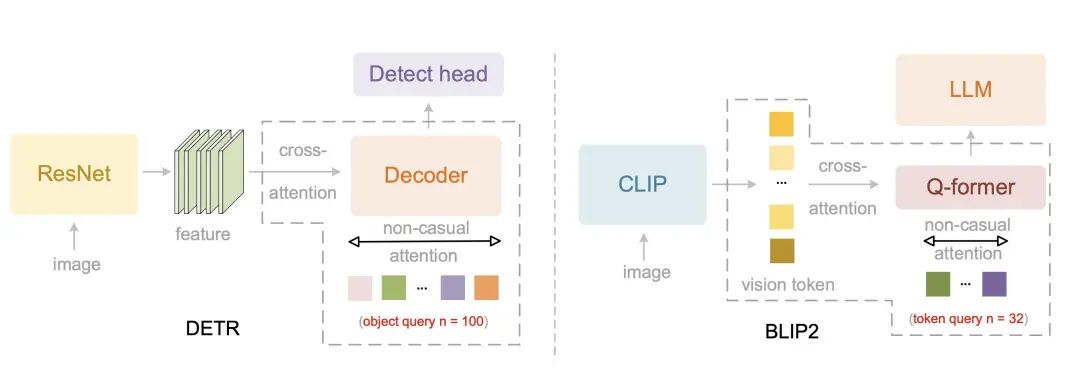
这在自然图像上问题不大,但在文档场景中会直接崩盘:
-
多列布局 → 阅读顺序错乱
-
表格 → 行列语义消失
-
数学公式 → 结构被压扁
-
杂志 / 报纸 → 图文关系断裂
问题不在 Transformer,而在“顺序假设本身是错的”。
你不能假设文档天生就有一个“正确的一维顺序”,然后再指望模型自己悟出来。
DeepSeek-OCR 2 的关键变化:编码器从“看图”变成“阅读”
这次升级的重头戏是一个叫 DeepEncoder V2 的新架构。
如果你熟悉之前的 DeepSeek-OCR,你会知道原来的流程是:图像 -> 编码器 -> LLM 解码。这个大框架没变(解码器还是那个强力的 3B MoE LLM)。
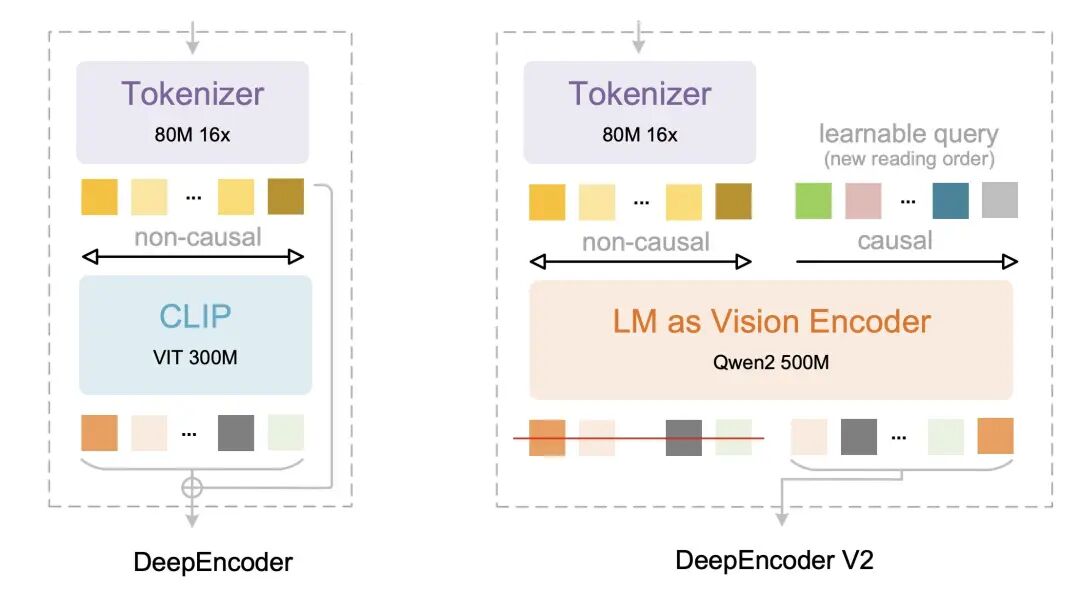
1. 踢掉 CLIP,换上 Qwen
以前,DeepSeek-OCR 用的是 CLIP ViT 作为视觉编码器。CLIP 很强,但它更像是“为了匹配图片和文字而生”的,它的推理能力其实很弱。
DeepSeek-OCR 2 做了一个大胆的决定:踢掉 CLIP,换上了 Qwen2-0.5B。
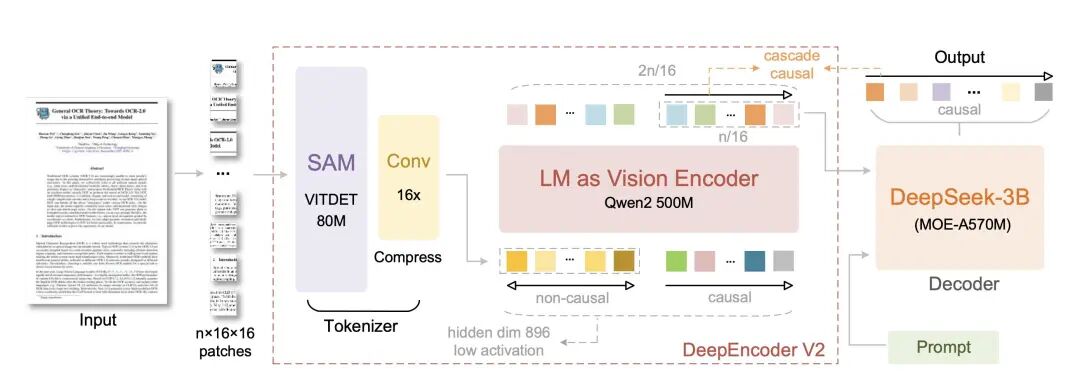
等等,Qwen 不是个语言模型吗?
没错!这正是天才之处。语言模型天生就擅长理解顺序、逻辑和因果关系。把一个小型的语言模型当作视觉编码器,就好比给眼睛装了一个微型大脑。它不再只是提取特征,而是在进行视觉推理。
2. 视觉因果流(Visual Causal Flow):教 AI “顺藤摸瓜”
这是论文里最让我兴奋的概念。
DeepEncoder V2 引入了一种可学习的查询标记(Query Tokens)。你可以把它想象成阅读时的“手指”。
传统的编码器是一眼看全图,不分先后。
DeepEncoder V2 创造了一个循序渐进的过程:每一个查询 Token 都只能看到“过去”的信息,而不能看“未来”

这就倒逼模型去学习一个符合逻辑的阅读顺序。它必须先理解了“表头”,才能去理解下面的“数据”。这完全模拟了人类的认知过程:如果不先读懂前面的主语,你很难理解后面的动词。
这也带来了一个很有趣的双重注意力设计:
看内容时:它像 ViT 一样,全局扫描(双向注意力)。
定顺序时:它像 LLM 一样,严格遵循因果逻辑(单向注意力)。
效果:少一点幻觉,多一点逻辑
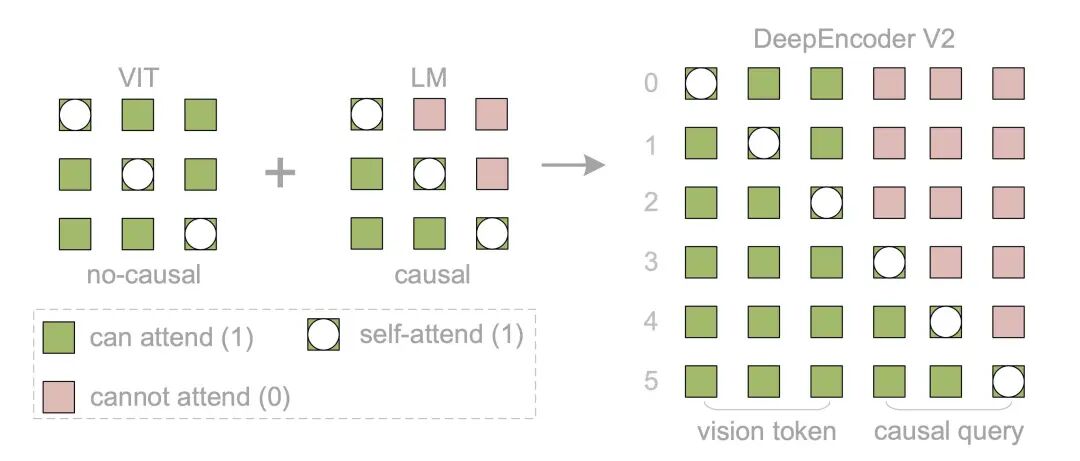
双注意力机制:内容 vs 阅读方式
DeepSeek-OCR 2 在编码器里同时保留了两种注意力:
1.视觉 token:双向注意力:表示“页面上有什么”
2.因果查询 token:单向因果注意力:表示“我是怎么读的”
而只有后者会被送入 LLM 解码器。这一设计我非常喜欢,因为它等于是明确告诉模型:“我不关心你看到多少,我关心你理解的顺序是否合理。”
说了这么多架构,效果怎么样?
在 OmniDocBench v1.5 的测试中,DeepSeek-OCR 2 的总分比上一代提高了 3.73%。
你可能会觉得 3% 不多,但在 OCR 领域,尤其是针对公式、表格这种“硬骨头”,这 3% 往往决定了这段代码是能直接跑通,还是需要你手动修半天。
最重要的是,论文提到它能显著减少幻觉结构。这太关键了。我不怕 OCR 认不出字,我最怕它无中生有地给我编造一个表格行,或者把公式里的上下标搞反。
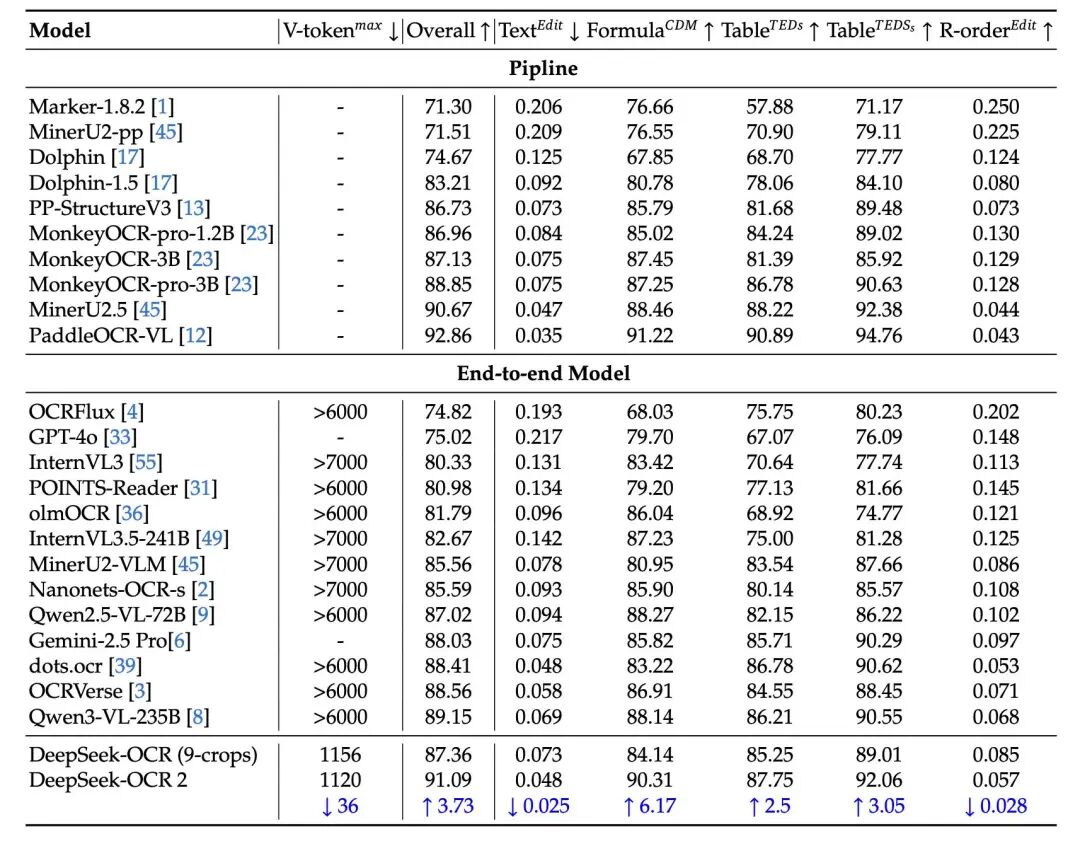
而且,这一切是在不增加计算成本的情况下做到的。它依然保持了极高的 Token 效率(全局视图只需 256 个 Token),这对于我们要把模型部署到生产环境的人来说,简直是福音。
这不仅仅是 OCR
读完论文,我有一个强烈的感受:DeepSeek-OCR 2 正在模糊 OCR 和多模态大模型(MLLM)的界限。
论文里抛出了一个惊人的论断:
“二维理解可以分解为两个级联的一维因果推理步骤。”
编码器负责 因果视觉推理(搞清楚看的顺序)。
解码器负责 因果语言推理(搞清楚文字的意思)。这不仅是解决了 OCR 的问题,这其实是在探索原生多模态架构的未来。如果编码器本身就能理解逻辑,那我们是不是离真正的“统一视觉-语言-音频架构”又近了一步?
过去十几年,OCR 一直在“看得更清楚”,而 DeepSeek-OCR 2 是少数在问:你到底会不会读?
当编码器开始具备因果、顺序与语义意识时,OCR 才第一次真正靠近“理解文档”这件事。这一步,来得不算早,但来得很对。如果你和我一样,长期被论文 PDF、扫描文档、复杂报表折磨过——你大概也会理解我读完这篇论文时的那种感觉:
终于有人,开始教机器怎么读书了。
DeepSeek-OCR 2已经在 GitHub 上面开源,可以直接使用代码尝试:
torch==2.6.0
transformers==4.46.3
tokenizers==0.20.3
einops
addict
easydict
pip install flash-attn==2.7.3 --no-build-isolation
from transformers import AutoModel, AutoTokenizer
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = '0'
model_name = 'deepseek-ai/DeepSeek-OCR-2'
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, _attn_implementation='flash_attention_2', trust_remote_code=True, use_safetensors=True)
model = model.eval().cuda().to(torch.bfloat16)
# prompt = "<image>\nFree OCR. "
prompt = "<image>\n<|grounding|>Convert the document to markdown. "
image_file = 'your_image.jpg'
output_path = 'your/output/dir'
res = model.infer(tokenizer, prompt=prompt, image_file=image_file, output_path = output_path, base_size = 1024, image_size = 768, crop_mode=True, save_results = True)
更多transformer,VIT,swin tranformer
参考头条号:人工智能研究所
v号:人工智能研究Suo, 启示AI科技动画详解transformer 在线视频教程



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 30
30 0
0- 0



 已为社区贡献47条内容
已为社区贡献47条内容

所有评论(0)