OpenClaw + Ollama:在 macOS 上部署本地大模型的完整实践指南
`reasoning`| `true` / `false`| 模型是否支持推理链(thinking)|| **模型规模**| 无限制| 受限于本地硬件|| **隐私性**| ⚠️ 数据上传到云端| ✅ 数据完全不出本机|
**摘要**:本文详细记录了在 MacBook Pro(M1 Pro / 32GB)上,通过 Ollama 部署本地大模型并接入 OpenClaw AI 平台的全过程。涵盖环境准备、Ollama 安装与模型拉取、OpenClaw 配置修改、模型性能基准测试,以及本地模型与 OpenClaw 的通信架构原理。
一、背景与目标
1.1 为什么要本地部署?
| 维度 | 云端 API | 本地部署 |
|----------------------|---------------------------------------------|-------------------------------|
| **隐私性** | ⚠️ 数据上传到云端 | ✅ 数据完全不出本机 |
| **网络依赖** | 需要稳定网络 + 可能需要代理 | 无需网络,离线可用 |
| **延迟** | 100-500ms 网络延迟 | ~0ms 网络延迟 |
| **成本** | 按 token 计费 | 一次下载,永久免费推理 |
| **模型规模** | 无限制 | 受限于本地硬件 |
1.2 硬件环境
| 项目 | 配置 |
|------------|---------------------------------------------------------|
| **设备** | MacBook Pro (2021) |
| **芯片** | Apple M1 Pro(10核 CPU + 16核 GPU) |
| **内存** | 32GB 统一内存(CPU/GPU 共享) |
| **存储** | 1TB SSD |
| **系统** | macOS Sonoma 14.5 |
1.3 软件环境
| 组件 | 版本 |
|--------------------|-----------------|
| **OpenClaw** | v2026.2.15 |
| **Ollama** | v0.16.1 |
| **Node.js** | v22.x |
| **pnpm** | v10.x |
二、Ollama 安装与模型准备
2.1 安装 Ollama
推荐使用 Homebrew 安装,便于后续升级管理:
```bash
# 安装 Homebrew(如果尚未安装)
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"
# 通过 Homebrew 安装 Ollama
brew install --cask ollama
# 验证安装
ollama --version
# 输出: ollama version is 0.16.1> **提示**:国内网络环境下,可使用清华/中科大镜像安装 Homebrew:
> ```bash
> /bin/bash -c "$(curl -fsSL https://mirrors.ustc.edu.cn/misc/brew-install.sh)"
> ```2.2 拉取模型
根据硬件条件(32GB 统一内存),选择以下两个模型:
```bash
# 模型 1:gpt-oss:20b(13GB,支持推理链)
ollama pull gpt-oss:20b
# 模型 2:qwen3-coder(18GB,擅长编程和中文)
ollama pull qwen3-coder
```2.3 验证模型可用性
```bash
# 查看已下载的模型
ollama list
# 输出:
# NAME ID SIZE MODIFIED
# gpt-oss:20b xxxxxxxxxxxx 13 GB 2 hours ago
# qwen3-coder:latest xxxxxxxxxxxx 18 GB 2 hours ago
# 快速测试
ollama run gpt-oss:20b "Say hello"
```### 2.4 验证 API 端点
Ollama 启动后会在 `127.0.0.1:11434` 提供服务,同时暴露 OpenAI 兼容 API:
# 测试 Ollama API
curl http://127.0.0.1:11434/api/tags | python3 -m json.tool
# 测试 OpenAI 兼容端点
curl http://127.0.0.1:11434/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss:20b",
"messages": [{"role":"user","content":"Hello"}],
"stream": false,
"max_tokens": 50
}'三、OpenClaw 配置修改
将本地 Ollama 模型接入 OpenClaw,总共需要修改 **2 个文件、4 处配置**。
3.1 配置文件总览
```
~/.openclaw/
├── openclaw.json ← 主配置文件(改 3 处)
│ ├── auth.profiles["ollama:default"] ← ① 认证声明
│ ├── models.providers.ollama ← ② 模型提供商定义
│ └── agents.defaults.model ← ③ 默认模型 + 回退链
│
└── agents/main/agent/
└── auth-profiles.json ← 密钥文件(改 1 处)
└── profiles["ollama:default"] ← ④ 认证凭据
```3.2 修改主配置文件 `~/.openclaw/openclaw.json`
① 新增认证 Profile
在 `auth.profiles` 中添加 Ollama 的认证声明:
```json
{
"auth": {
"profiles": {
"zai:default": {
"provider": "zai",
"mode": "api_key"
},
"ollama:default": {
"provider": "ollama",
"mode": "api_key"
}
}
}
}
```② 新增模型提供商
在 `models.providers` 中添加 Ollama 提供商及模型定义:
```json
{
"models": {
"mode": "merge",
"providers": {
"ollama": {
"baseUrl": "http://127.0.0.1:11434/v1",
"api": "openai-completions",
"models": [
{
"id": "gpt-oss:20b",
"name": "GPT-OSS 20B (Local)",
"reasoning": true,
"input": ["text"],
"contextWindow": 131072,
"maxTokens": 8192
},
{
"id": "qwen3-coder",
"name": "Qwen3 Coder (Local)",
"reasoning": false,
"input": ["text"],
"contextWindow": 131072,
"maxTokens": 8192
}
**关键字段说明**:
| 字段 | 值 | 说明 |
|------------------------|------------------------------------|---------------------------------------------------|
| `baseUrl` | `http://127.0.0.1:11434/v1` | Ollama 的 OpenAI 兼容 API 端点 |
| `api` | `openai-completions` | 使用 OpenAI Chat Completions 协议 |
| `reasoning` | `true` / `false` | 模型是否支持推理链(thinking) |
| `contextWindow` | `131072` | 最大上下文窗口(tokens) |
| `maxTokens` | `8192` | 单次生成最大 token 数 |
③ 设置默认模型与回退策略
在 `agents.defaults` 中配置模型优先级:
```json
{
"agents": {
"defaults": {
"model": {
"primary": "ollama/gpt-oss:20b",
"fallbacks": ["ollama/qwen3-coder", "zai/glm-4.5-air"]
},
"models": {
"ollama/gpt-oss:20b": {
"alias": "GPT-OSS 20B (Local)"
},
"ollama/qwen3-coder": {
"alias": "Qwen3 Coder (Local)"
},
"zai/glm-4.5-air": {}
}
}
}
}模型回退链**:
gpt-oss:20b (本地) → qwen3-coder (本地) → glm-4.5-air (云端智谱)
主模型 第一备用 第二备用(兜底)3.3 修改密钥文件 `~/.openclaw/agents/main/agent/auth-profiles.json`
④ 新增 Ollama 认证条目
```json
{
"version": 1,
"profiles": {
"ollama:default": {
"type": "api_key",
"provider": "ollama",
"key": "ollama"
}
}
}
```**说明**:Ollama 本地运行无需真实 API Key,但 OpenClaw 框架要求每个 provider 都有认证条目,此处 `key` 填写任意非空字符串即可。
3.4 重启 Gateway 使配置生效
```bash
# 停止现有 Gateway
openclaw gateway stop
# 清除旧的会话记录(避免 Context overflow)
echo '{}' > ~/.openclaw/agents/main/sessions/sessions.json
# 重新启动 Gateway
openclaw gateway
# 验证健康状态
openclaw health
```> ⚠️ 重要提示**:如果环境中设置了 `http_proxy` / `https_proxy`,在启动 Gateway 前需要清除,否则对本地 Ollama 的请求会被转发到代理导致失败:
> ```bash
> unset http_proxy https_proxy HTTP_PROXY HTTPS_PROXY
> openclaw gateway
> ```四、模型性能基准测试
4.1 模型基本信息
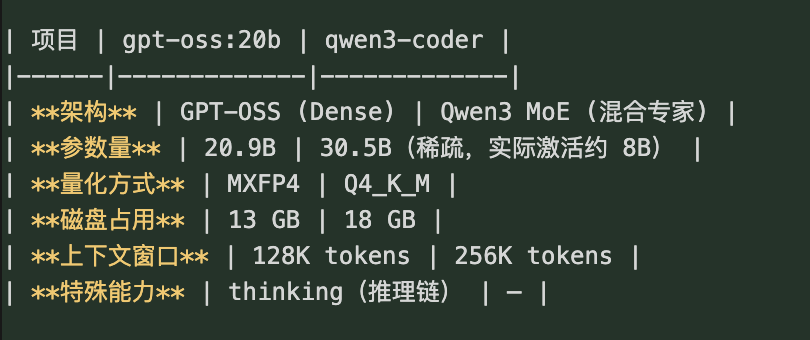
4.2 速度测试
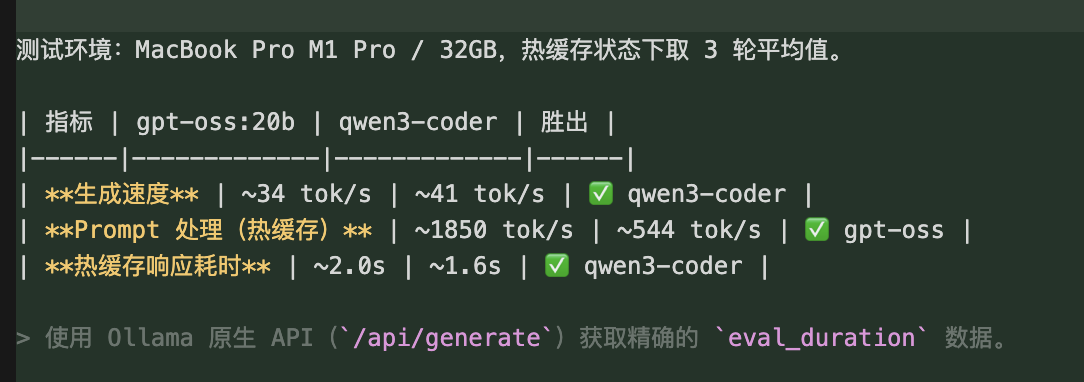
4.3 综合对比结论
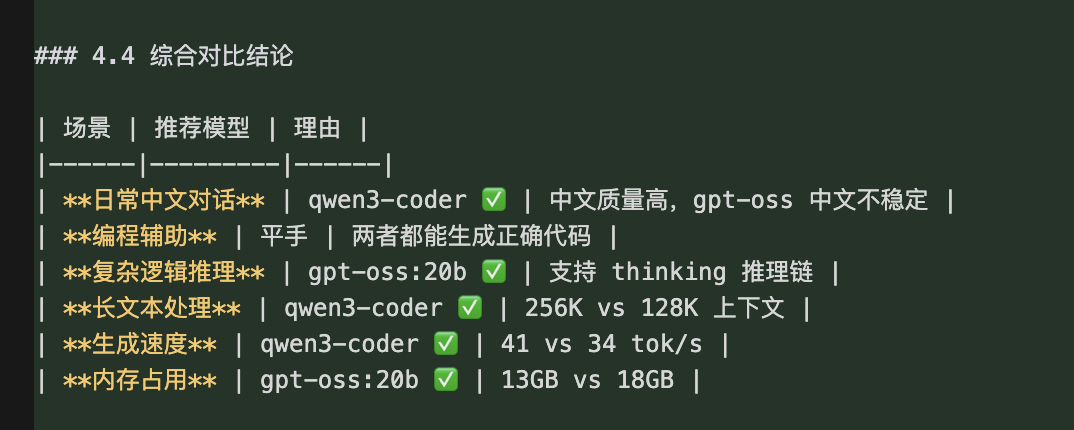
五、通信架构原理
5.1 整体架构
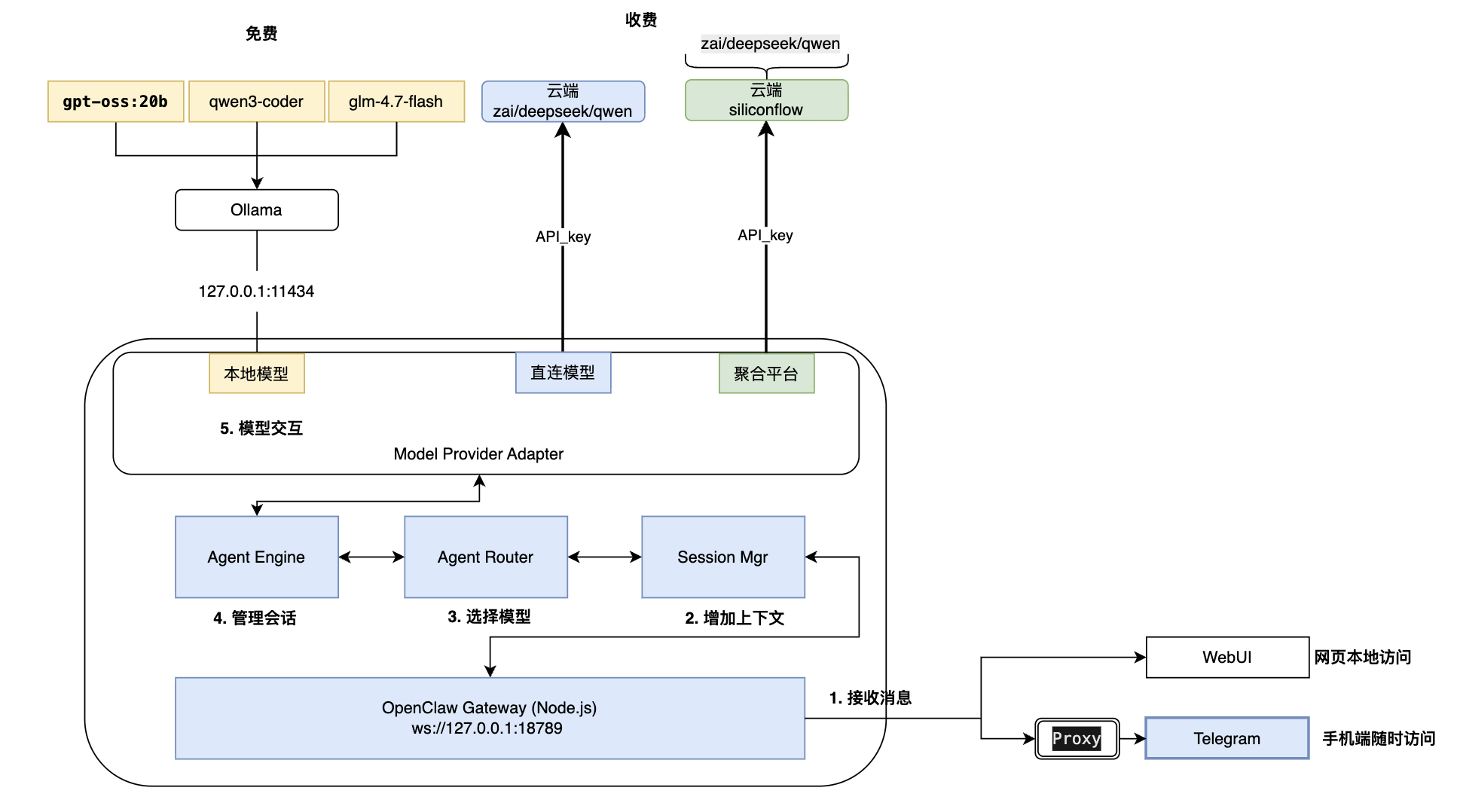
5.2 通信协议与端口

5.3 请求处理全流程
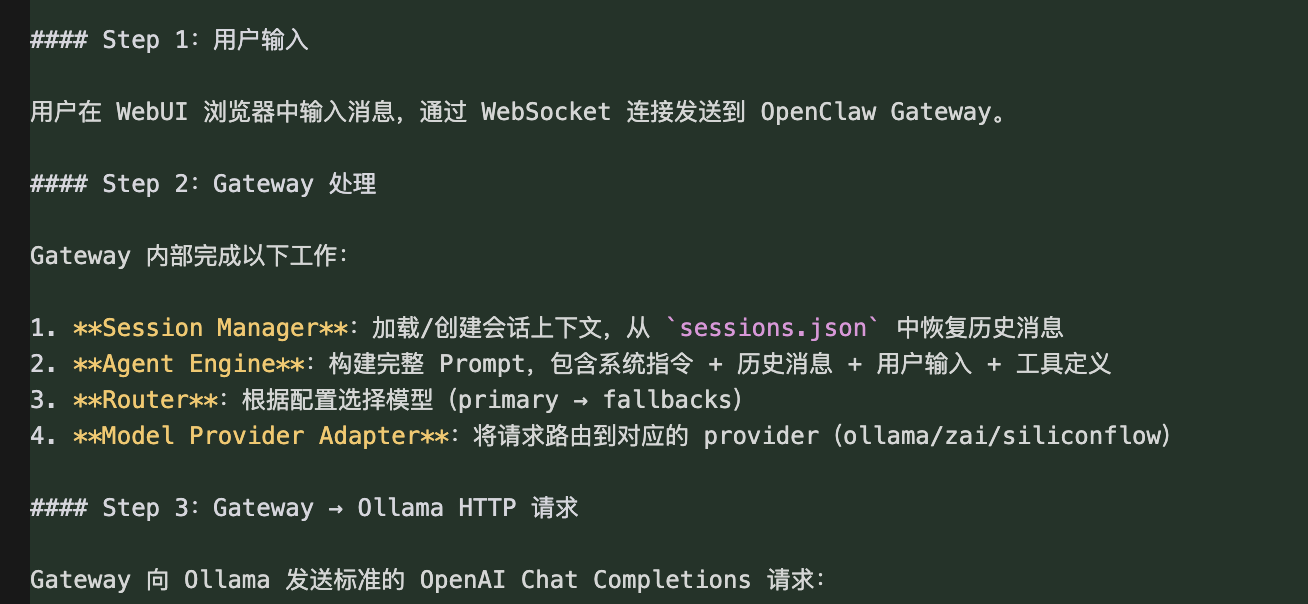
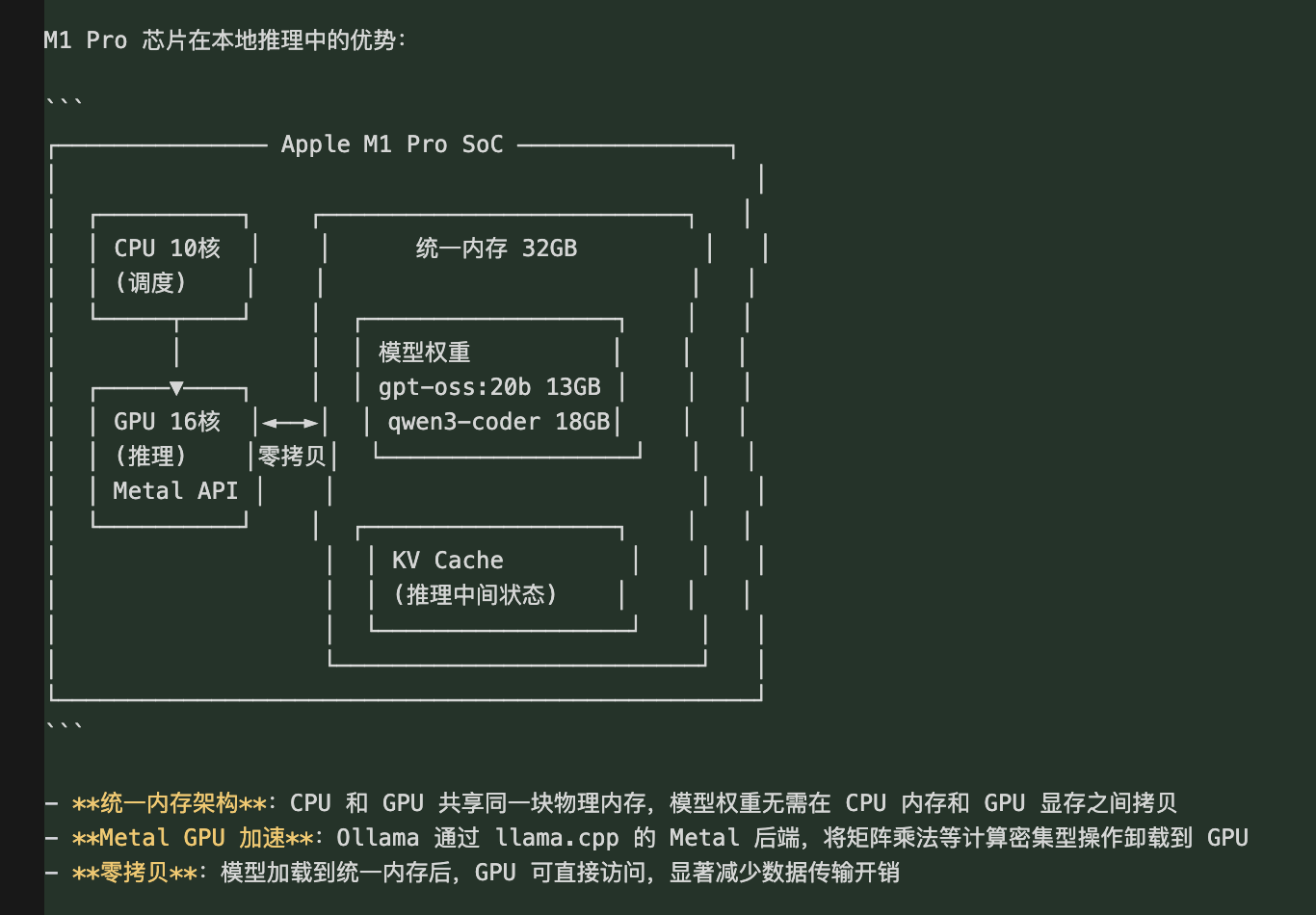
5.4 Apple Silicon 硬件加速原理
5.5 模型回退(Failover)机制
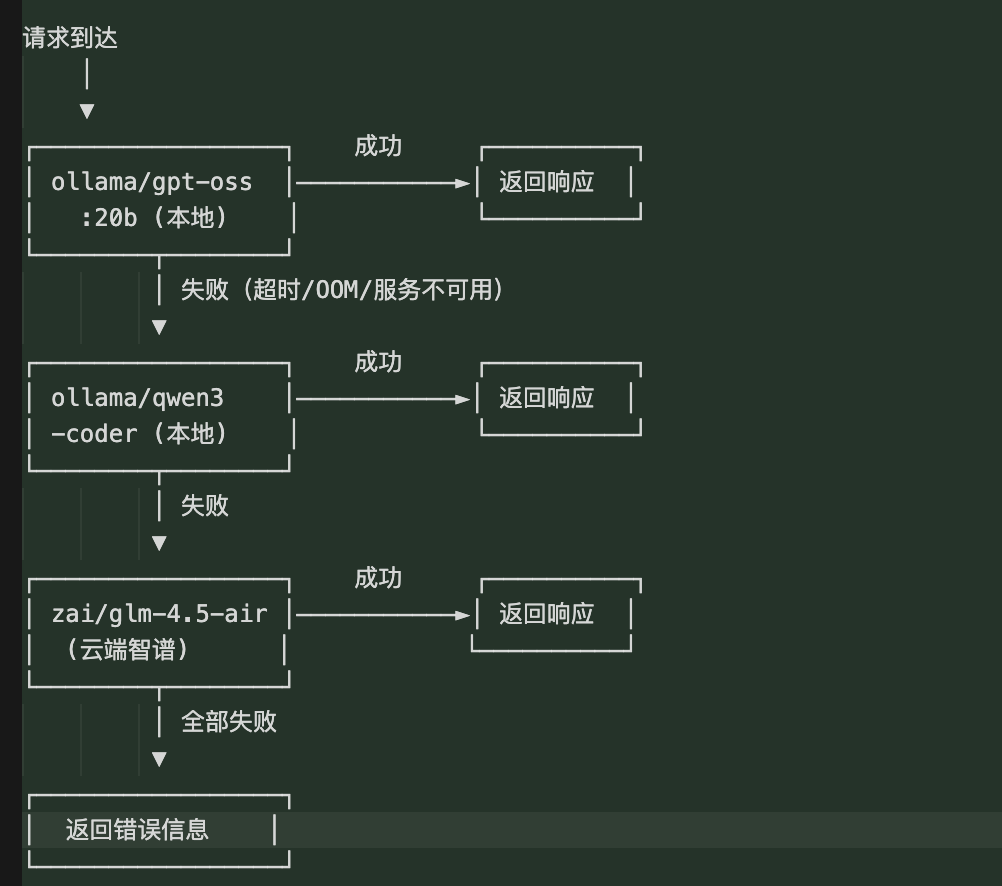
这种三级回退策略确保了:
**优先本地**:省成本、低延迟、保隐私
- **本地备用**:主模型不可用时切换到另一个本地模型
- **云端兜底**:本地全部不可用时,仍可通过云端 API 提供服务5.6 本地模型 vs 云端模型的数据路径对比

六、常见问题与排障
6.1 Gateway 启动报 "gateway already running"
```bash
# 先停止旧进程
openclaw gateway stop
# 如果仍然报错,强制 kill
kill $(lsof -ti :18789)
# 重新启动
openclaw gateway
```6.2 "Context overflow: prompt too large for the model"
会话历史过多导致上下文溢出,清除会话记录:
```bash
echo '{}' > ~/.openclaw/agents/main/sessions/sessions.json
openclaw gateway stop && openclaw gateway
```6.3 "Failed to discover Ollama models: fetch failed"
通常是因为设置了 `http_proxy` 环境变量,导致对本地 Ollama 的请求被转发到代理:
```bash
# 启动 Gateway 前清除代理
unset http_proxy https_proxy HTTP_PROXY HTTPS_PROXY
openclaw gateway
```6.4 Ollama 版本不匹配(client/server version mismatch)
```bash
# 检查版本
ollama --version
# 如果提示 server/client 版本不一致,重启 Ollama 服务
pkill -f "ollama serve"
# 等待 Ollama 自动重启(macOS LaunchAgent 会自动拉起),或手动启动:
ollama serve &
```6.5 如何查看当前 Ollama 运行状态
```bash
# 查看正在运行的模型
ollama ps
# 查看所有已下载模型
ollama list
# 测试 API 连通性
curl -s http://127.0.0.1:11434/api/tags | python3 -m json.tool
```七、关键技术点总结


有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 34
34 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)