基于YOLOv5的食物识别在Xilinx平台上的实现之旅
基于yolov5的食物识别Xilinx,vitis ai,模型 模型量化 模型编译 系统搭建
最近在捣鼓基于YOLOv5的食物识别,并且打算将它跑在Xilinx平台上,借助Vitis AI来进行模型量化和编译,最后搭建起完整的系统。这一路探索,那叫一个精彩,现在就来跟大家唠唠。
YOLOv5模型:食物识别的起点
YOLOv5作为目标检测领域的明星模型,其简洁高效的架构让人爱不释手。它的代码结构清晰,便于理解和修改。比如在models/yolo.py文件中,核心的Model类定义了整个网络的架构:
class Model(nn.Module):
def __init__(self, cfg='yolov5s.yaml', ch=3, nc=None, anchors=None): # model, input channels, number of classes
super().__init__()
if isinstance(cfg, dict):
self.yaml = cfg # model dict
else: # is *.yaml
import yaml # for torch hub
self.yaml_file = Path(cfg).name
with open(cfg) as f:
self.yaml = yaml.safe_load(f) # model dict
# Define model
ch = self.yaml['ch'] = self.yaml.get('ch', ch) # input channels
if nc and nc!= self.yaml['nc']:
LOGGER.info(f"Overriding model.yaml nc={self.yaml['nc']} with nc={nc}")
self.yaml['nc'] = nc # override yaml value
if anchors:
LOGGER.info(f'Overriding model.yaml anchors with anchors={anchors}')
self.yaml['anchors'] = round(anchors) # override yaml value
self.model, self.save = parse_model(self.yaml, ch=[ch]) # model, savelist
self.names = [str(i) for i in range(self.yaml['nc'])] # default names
self.inplace = self.yaml.get('inplace', True)这里通过解析配置文件(.yaml格式)来构建模型,不同的配置文件对应不同规模的模型,像yolov5s.yaml、yolov5m.yaml等。我们可以根据实际需求,比如对计算资源的限制和对检测精度的要求,选择合适的模型配置。
模型量化:精打细算资源
要在Xilinx平台上高效运行模型,模型量化是必不可少的一步。Vitis AI提供了强大的量化工具。量化简单来说,就是把原本高精度的模型参数,用低精度的数据格式来表示,这样可以减少存储和计算资源的消耗。
在Vitis AI中,量化操作可以通过命令行工具来完成。假设我们已经训练好一个基于YOLOv5的食物识别模型food_detection.pt,可以这样进行量化:
vai_q_tensorflow quantize \
--input_frozen_graph food_detection.pb \
--input_shapes 1,640,640,3 \
--output_dir quantized_model \
--calib_data_type int8 \
--calib_table_name calib_table \
--input_nodes input \
--output_nodes output这里通过vaiqtensorflow quantize命令,指定了输入的冻结图fooddetection.pb(需要先将PyTorch模型转换为TensorFlow的冻结图格式),输入数据的形状1,640,640,3(对应图像的尺寸和通道数),输出目录quantizedmodel,量化数据类型为int8,校准表名称calib_table以及输入输出节点名称。校准的过程就是让模型在少量校准数据上运行,统计激活值的分布,从而确定量化参数,尽可能减少量化带来的精度损失。
模型编译:为Xilinx平台量身定制
量化后的模型还不能直接在Xilinx平台上运行,需要通过Vitis AI的模型编译器进行编译。编译过程会针对特定的Xilinx硬件平台进行优化,生成可执行的模型文件。
vai_c_tensorflow compile \
--model quantized_model/quantized_graph.pb \
--arch xilinx_u50_gen3x16_xdma_201920_3 \
--output_dir compiled_model \
--net_name food_detection这里vaictensorflow compile命令将量化后的模型quantizedmodel/quantizedgraph.pb,针对xilinxu50gen3x16xdma2019203这个特定的硬件平台进行编译,输出到compiledmodel目录,模型命名为food_detection。编译后的模型会生成一系列文件,包括用于运行时加载的*.xmodel文件,这个文件包含了针对硬件平台优化后的模型结构和量化参数等信息。
系统搭建:让一切运转起来
完成模型量化和编译后,就可以着手搭建整个食物识别系统了。这部分涉及到硬件平台的配置、软件接口的编写等。
基于yolov5的食物识别Xilinx,vitis ai,模型 模型量化 模型编译 系统搭建
在硬件方面,确保Xilinx设备正确连接到主机,并且安装好相应的驱动程序。在软件层面,我们需要编写代码来加载编译后的模型,并对输入的图像进行预处理、推理和后处理。以下是一个简单的Python示例代码,用于加载编译后的模型并进行推理:
import cv2
import numpy as np
from vitis_ai_runtime import vitis_ai_core as vacore
# 加载模型
graph = vacore.Graph.create_graph('compiled_model/food_detection.xmodel')
input_tensor = graph.get_input_tensors()[0]
output_tensors = graph.get_output_tensors()
# 读取图像并预处理
image = cv2.imread('food_image.jpg')
image = cv2.resize(image, (640, 640))
image = np.transpose(image, (2, 0, 1))
image = np.expand_dims(image, axis=0)
image = image.astype(np.float32) / 255.0
# 推理
job_id = graph.execute_async([image])
graph.wait(job_id)
output = graph.get_output_data(job_id, output_tensors[0])
# 后处理,这里简单打印输出结果形状
print(output.shape)这段代码首先使用vitisairuntime库加载编译后的.xmodel文件创建计算图。然后读取一张食物图像,对其进行尺寸调整、通道转换和归一化等预处理操作。接着通过execute_async方法异步执行推理任务,并通过wait方法等待推理完成,最后获取输出结果。当然,实际的后处理过程会更复杂,比如解析检测到的目标框信息、类别信息等。
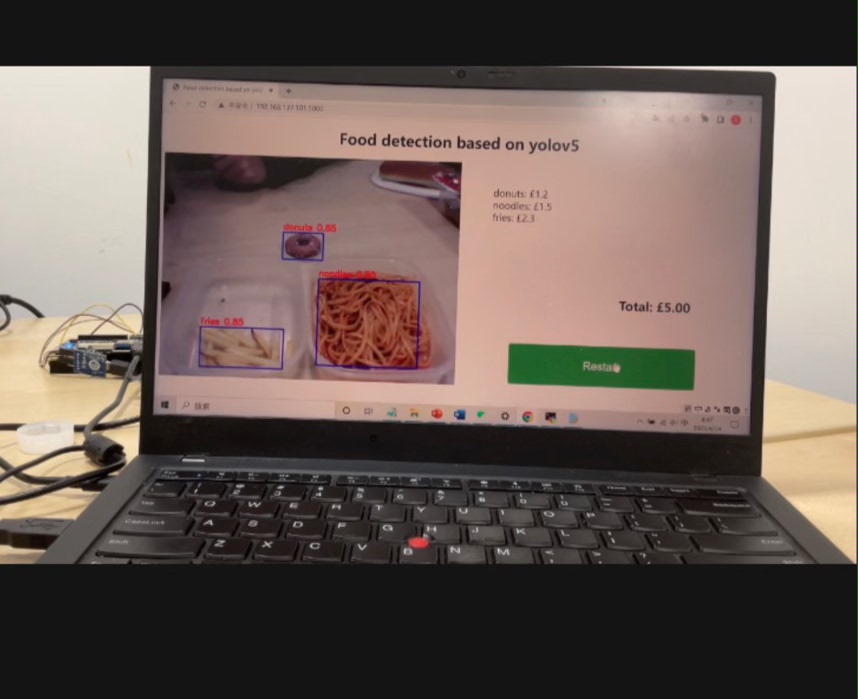
经过这一系列的操作,基于YOLOv5的食物识别系统在Xilinx平台上就基本搭建完成了。这过程虽然充满挑战,但当看到模型在硬件平台上高效准确地识别出食物时,那种成就感简直无法言表。希望这篇博文能给同样在探索相关领域的小伙伴们一些启发,大家一起交流进步!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 6
6 0
0- 0



 已为社区贡献23条内容
已为社区贡献23条内容

所有评论(0)