大模型开发(一):大模型微调
人工智能和大模型, Llama Factory大模型微调
1、人工智能和大模型

图灵测试
1950年图灵发表论文《Computing Machinery and Intelligence》,第一次提出“机器思维”:
一个人在不接触计算机的情况下,通过特殊方式和计算机进行一系列问答,如果在相当长时间内,无法判断对方是人还是计算机,那就可以认为这台计算机具有与人相当的智力,即这台计算机是能思维的,这就是著名的“图灵测试”
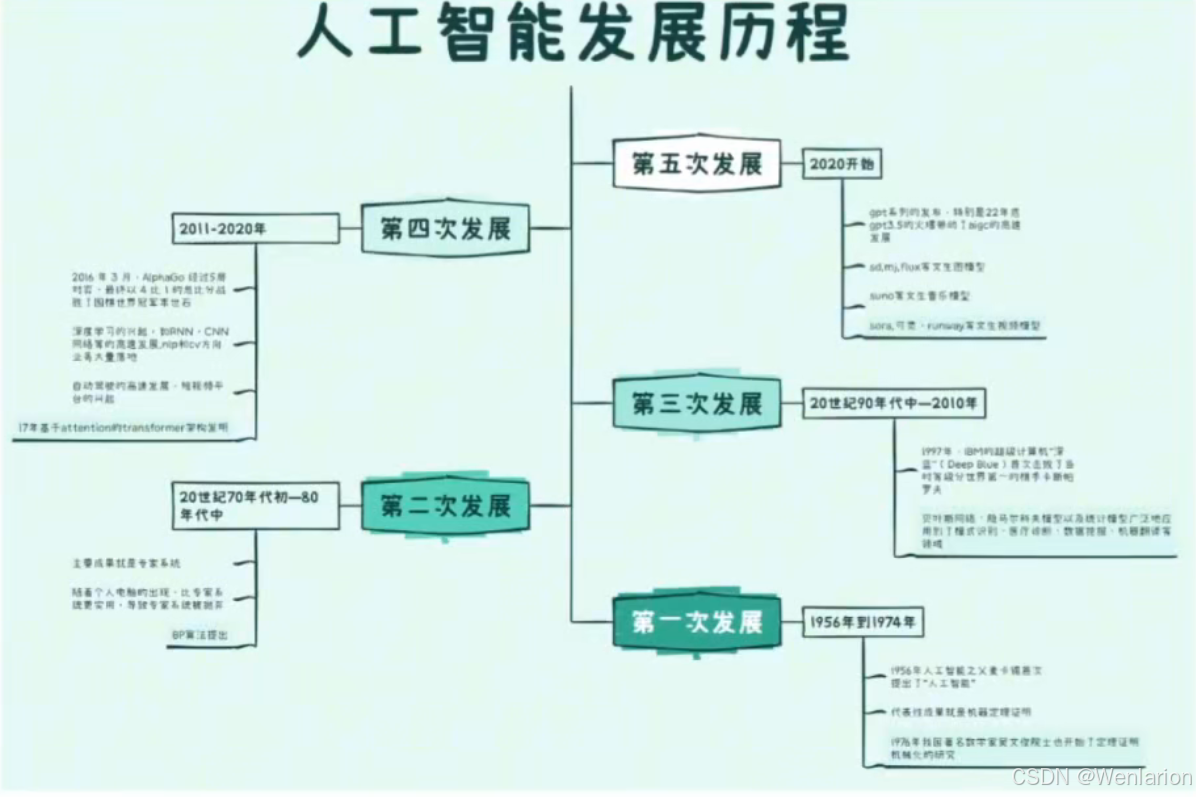
人工智能发展
第一次发展:1956 年到 1974 年
1956 年人工智能之父麦卡锡首次提出了 “人工智能”(简称 AI)这一术语,1956 年到 1974 年出现了第一次人工智能的发展浪潮,代表性成果就是机器定理证明1976 年我国著名数学家吴文俊院士也开始了定理证明机械化的研究。他从理论上证明:初等几何主要一类定理可以机械化证明,创立了机器证明的 “吴方法”软件安全验证中用到的形式化方法属于机器定理证明的相关技术
第二次发展:20 世纪 70 年代初 —80 年代中
主要成果就是专家系统随着个人电脑的出现,比专家系统更实用,导致专家系统被抛弃反向传播算法被发明1974 年,Paul Werbos (反向传播之父) 首次给出了 back propagation,可以高效的计算每一次迭代过程中的梯度,不过当时神经网络学术圈无人知晓 Paul 的 BP 算法。直到 80 年代中期,BP 算法才重新被 David Rumelhart、Geoffrey Hinton 及 Ronald Williams、David Parker 和 Yann LeCun 独立发现
第三次发展:20 世纪 90 年代中 —2010 年
1997 年,IBM 的超级计算机 “深蓝”(Deep Blue)首次击败了当时等级分世界第一的棋手卡斯帕罗夫传统机器学习模型高速发展贝叶斯网络、隐马尔科夫模型以及统计模型广泛地应用到了模式识别、医疗诊断、数据挖掘、机器翻译等领域
第四次发展:2011-2020 年
2016 年 3 月,AlphaGo 经过 5 局对弈,最终以 4 比 1 的总比分战胜了围棋世界冠军李世石深度学习的兴起,RNN,CNN 网络等的高速发展,以 AlexNet 的成功为起点,nlp 和 cv 方向业务大量落地还有包括如推荐算法和美颜技术进步带来的抖音等短视频平台自动驾驶的高速发展17 年基于 attention 的 transformer 架构发明,大名顶顶的论文:Attention Is All You Need https://arxiv.org/pdf/1706.03762
第五次高速发展
2020 开始,GPT 系列的发布,特别是 22 年底 GPT-3.5 的火爆带动了 AIGC 的高速发展。SD、MJ、Flux 等文生图模型,Suno 等文生音乐模型,Sora、可灵、Runway 等文生视频模型。大模型开源的有 Llama 系列,包括多模态的 3.2,千问 2.5 等,闭源的 Claude3.5 系列,GPT4o 以及 o1 等。
大语言模型的发展
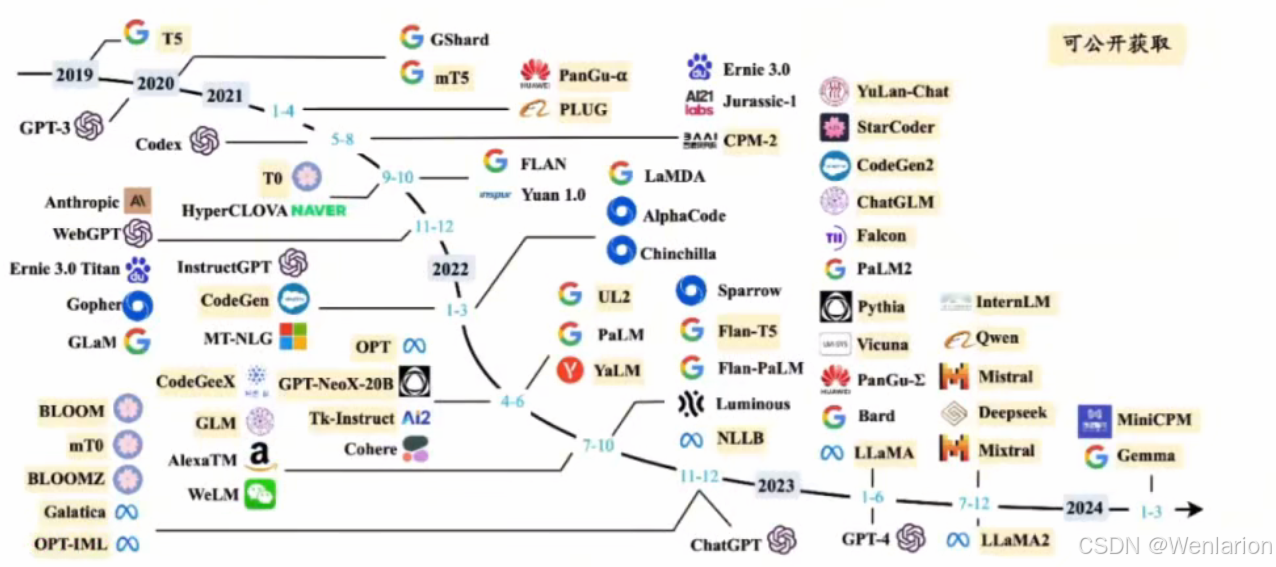
基本也是 transformer 架构的发展史,早期主要用来做机器翻译,文本挖掘,信息提取直到 gpt3.5 的爆火。
OpenAI
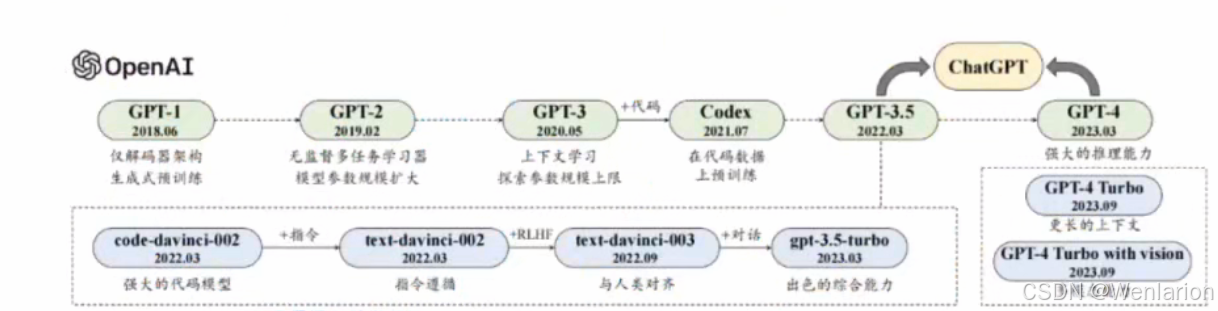
- GPT-3.5 → GPT-4 → GPT-4o
- 2024 年 2 月发布了 Sora 的 Demo,不过由于算力成本和视频生成可控性的原因,一直没有公开上线
- 2024 年 9 月底正式上线 GPT-4o 实时对话版
- 2024 年 9 月推出 o1
- 提出 RL 与 CoT 结合后的 RL scaling law
- Test Time computing 的 scaling law
Anthropic
- Claude 系列
- 由 OpenAI 前核心团队创立
- Claude 3.5 在代码生成等方面完成了对 GPT-4o 的超越
- 2023 年推出 PaLM,2024 年升级成 Gemini
- 2024 年开源大模型 Gemma
Meta
- Llama 系列开源:Llama1 → Llama2 → Llama3
- 2023 年 2 月推出 Llama1,有 7B、13B、30B 和 65B 四种参数规模版本
- 后来 Llama3 开源 8B、13B、70B
- Llama3.1 开源 8B、13B、70B、405B
- Llama3.1 系列小模型是由 405B 模型蒸馏出来
- Llama3.2 是多模态模型,基于 3.1 的权重初始化继续训练
阿里巴巴
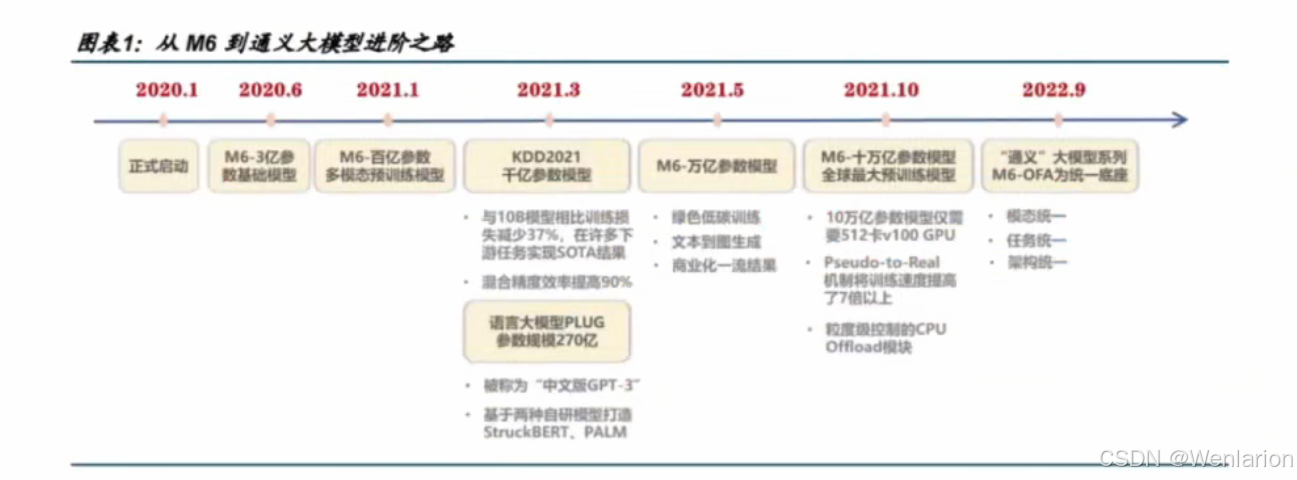
- 2023 年发布通义大模型
- 目前开源到 Qwen2.5
- Qwen2.5:语言大模型
- Qwen2.5-math:通过专门的数学语料训练
- Qwen2.5-coder:代码生成大模型
- Qwen2.5-VL:多模态大模型
清华智谱
- 开源了 ChatGLM,一直到 ChatGLM3-6B、GLM4-9B
- GLM-4V-9B:是多模态模型,基于 GLM4-9B
- CogVLM2:多模态模型,基于 Llama3-8b
- CogVideoX:文生视频模型
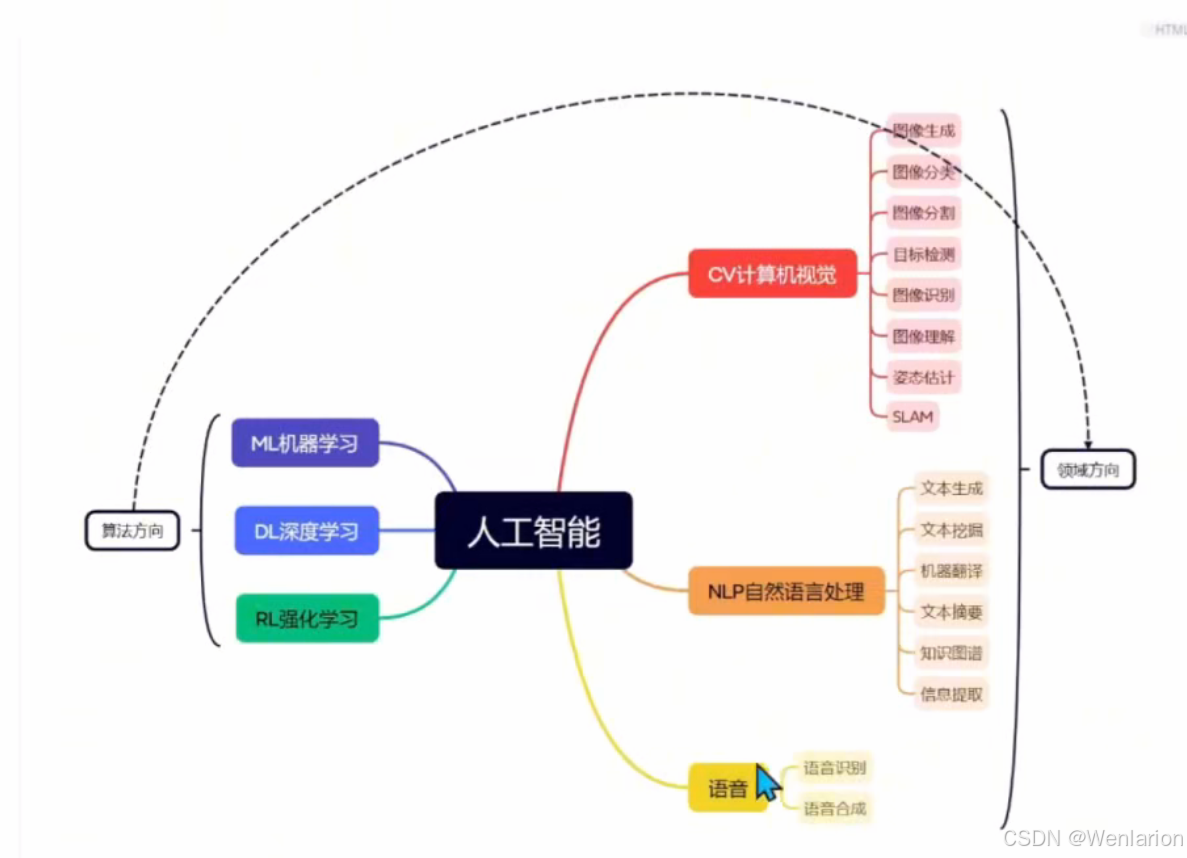
人工智能技术分类
算法方向
- 机器学习 ML(machine learning)
- 深度学习 DL(Deep learning)
- 强化学习 RL(Reinforcement learning)
领域方向
- 计算机视觉
- 自然语言
- 语音
综合应用
综合应用就是 AIGC 生成式人工智能:文生文、文生图、文生音频、文生视频、多模态。
机器学习的学习算法
监督学习 (Supervised Learning)
它使用标记的训练数据来训练模型,以便模型能够预测未见过数据的输出。
在监督学习中,每个训练样本都包括输入特征和一个相应的输出标签。模型的目标是学习输入特征和输出标签之间的映射关系。
监督学习主要用于两类问题:分类和回归。
主要算法包括:神经网络、支持向量机、最近邻居法、朴素贝叶斯法、决策树等。
无监督学习 (Unsupervised Learning)
它处理的是未标记的数据。无监督学习的目标是发现数据中的隐藏结构和模式,而不是预测特定的输出。这种类型的学习非常适合于数据探索和发现数据的内在属性。
无监督学习通常用于聚类、关联规则学习和降维等任务。
半监督学习 (Semi-supervised Learning, SSL)
它结合了有监督学习和无监督学习的特点,利用大量未标记数据和少量标记数据来训练模型。
这种方法特别适用于标记数据难以获得或成本较高的情况。
例如先用少量标记初步训练,然后用未标记数据训练。
强化学习 (Reinforcement Learning, RL)
通过与环境的互动来做出决策,一个智能体(Agent)通过执行动作(Action)并接收环境提供的奖励(Reward)信号来学习,目的是最大化累积的奖励。
在运筹学和控制论的语境下,强化学习被称作 “近似动态规划”(approximate dynamic programming, ADP)。
OpenAI 五级人工智能
-
第一级:就是 GPT-4 的水平。
-
第二级:人类的推理能力,据说 GPT-5 达到,应该是 GPT-5 的大模型能力 + o1 下一代的推理能力。
-
第三级:具身智能,AI 机器人具有人类的执行能力。
-
第四级:自我进化 AI,AI 能自我迭代进化出超过人类能力。
-
第五级:AI 组织,整个组织都是 AI 在协做、管理、工作、发展。

DeepMind 人工智能分级
-
将 AGI 分类为:非 AI、初级、中级、专家、大师、超级智能
-
GPT-3.5、Llama 2 是初级智能
-
GPT-4、Llama 3 等是初级智能中很厉害的,接近中级智能
-
AlphaFold3 是分类法中的第 5 级 “限定领域超人 AI”,因为它在一个任务(从氨基酸序列预测蛋白质的三维结构)上的表现高于全球顶级科学家的水平
DeepMind AGI 分级框架(性能 × 通用性,含引用标注)
| 性能 (行) \ 通用性 (列) | Narrow(明确限定的任务或任务集) | General(广泛的非物理任务,包括元认知任务如学习新技能) |
|---|---|---|
| Level 0: No AI | Narrow Non-AI计算器软件;编译器 | General Non-AI人在回路系统,如 Amazon Mechanical Turk |
| Level 1: Emerging(等于或略优于非熟练人类) | Emerging Narrow AIGOFAI (Boden, 2014);简单基于规则的系统,如 SHRDLU (Winograd, 1971) | Emerging AGIChatGPT (OpenAI, 2023)、Bard (Anil et al., 2023)、Llama 2 (Touvron et al., 2023)、Gemini (Pichai & Hassabis, 2023) |
| Level 2: Competent(至少达到熟练成年人的 50% 分位) | Competent Narrow AI毒性检测器(Jigsaw, Das et al., 2022);智能音箱(Siri (Apple), Alexa (Amazon), Google Assistant (Google));VQA 系统(PaLI (Chen et al., 2023), Watson (IBM));SOTA 大模型在部分任务(如短文写作、简单编码) | Competent AGI尚未实现 |
| Level 3: Expert(至少达到熟练成年人的 90% 分位) | Expert Narrow AI拼写语法检查器(Grammarly, 2023);生成式图像模型(Imagen (Saharia et al., 2022), DALL-E 2 (Ramesh et al., 2022)) | Expert AGI尚未实现 |
| Level 4: Virtuoso(至少达到熟练成年人的 99% 分位) | Virtuoso Narrow AIDeep Blue (Campbell et al., 2002)、AlphaGo (Silver et al., 2016, 2017) | Virtuoso AGI尚未实现 |
| Level 5: Superhuman(表现超过 100% 的人类) | Superhuman Narrow AIAlphaFold (Jumper et al., 2021; Varadi et al., 2021)、AlphaZero (Silver et al., 2018)、StockFish (Stockfish, 2023) | Artificial Superintelligence (ASI)尚未实现 |
柏拉图表征假说(The Platonic Representation Hypothesis)

由 MIT 的几位研究员发表的论文:https://phillipi.github.io/prh/
柏拉图表征假说有着几个重要推论,每个推论都对未来 AI 的发展有着方向性的指导意义。
Ilya 推荐的重磅论文,2024 年优秀论文之一。
现实世界的投影
不同的人工智能系统以不同的方式表示世界。
视觉系统可能表示形状和颜色,语言模型则可能侧重于语法和语义。
Phillip 等人研究发现,用于视觉模型和文本模型以及其他架构的模型,它们的模型表征都变得非常相似。
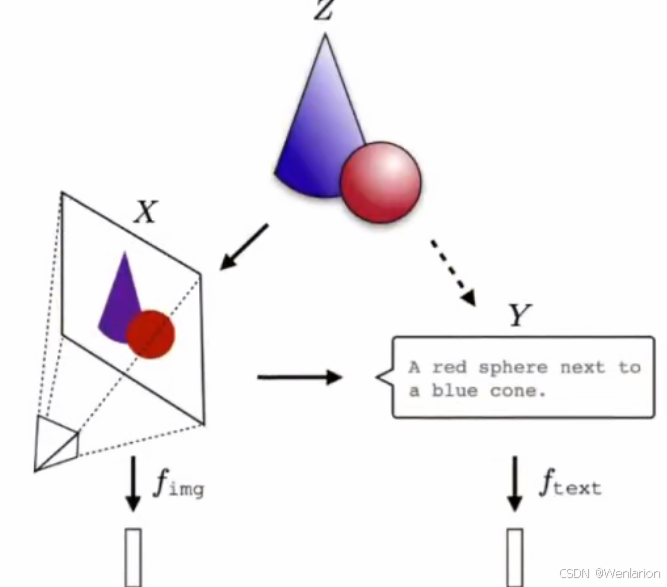
神经网络利用不同的数据和模式进行不同的目标训练,并在其表征空间中汇聚成一个共享的现实统计模型。
如果把现实 Z 想象成:圆锥 + 圆球。那么,X 是现实 Z 的图片模态的投影,Y 是文本模态的投影。这时训练两个模型:视觉模型 f_img,一个文本模型 f_text,各自学到了对于 X 和 Y 的表征方式。随着模型参数规模、训练数据的扩大,这两个模型最终会学到 X、Y 这两个投影背后现实 Z 的表征方式。
我们感知到的所有数据 —— 图像、文本、声音等 —— 都是某种潜在现实的投影。一个概念 “苹果,apple,🍎”,可以用许多不同的方式来看待,但其含义(所表示的内容)大致相同。表示学习算法可能会恢复这种共享含义。
全模态训练
现在训练大语言模型,或者文生视频模型,用全模态数据来训练,比如用文本数据、视频数据、声音数据、法线数据、点云数据、深度图等来训练,比单一模态数据训练能提高 20% 的任务性能。
其中香港中文大学、中科院一起最近发表过一篇全模态训练的论文:https://arxiv.org/pdf/2406.09412

多模态的训练,都是从一个大语言模型初始化开始进行其它模型训练,并进行多模态之间的对齐。
- 比如阿里的 Qwen2-VL 基于 Qwen2 进行训练,CogVLM2 从 Llama3 8B 开始训练。
柏拉图表征假说让我们能够从一个新的视角审视全模态或者多模态数据之间的关系:
- 假设你手上有 M 张图片和 N 段文字,为了训练出最强的视觉模型,你不止应该训练全部 M 张图片,还应该把 N 段文字也纳入训练集中。
- 前面讲过,视觉模型都是从预训练大语言模型上微调而来的。
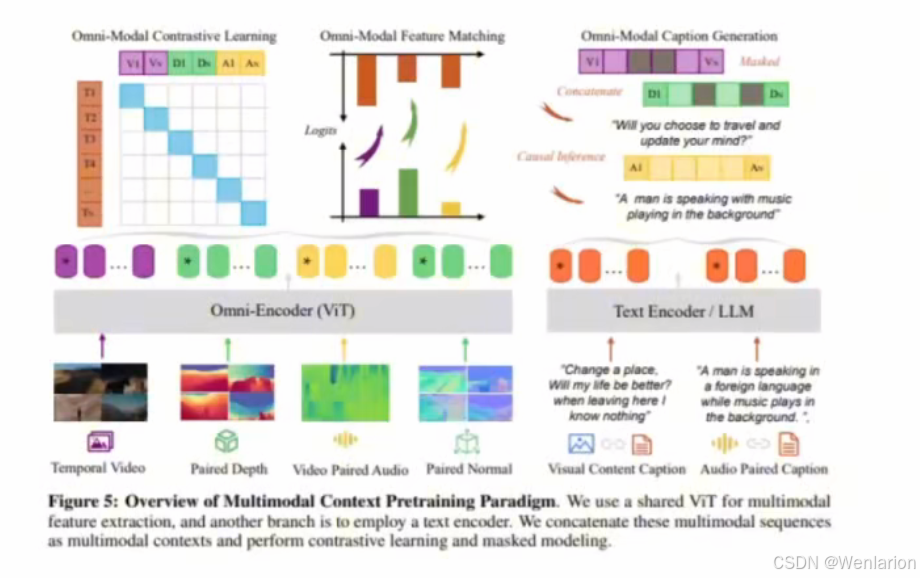
添加代码数据
- 知名 AI 公司 Cohere 发表论文:https://arxiv.org/pdf/2408.10914v1
- 在预训练数据中添加高质量代码数据,可大幅度提升模型性能。

-
添加代码数据可使自然语言推理能力相对增加 8.2%,世界知识增加 4.2%,生成胜率提高 6.6%,代码性能提高 12 倍。
一个重要的推论
-
不同模态、不同算法架构的 AI 模型都会汇聚到同一个终点目标,那就是形成对于高维现实世界的准确表征。
-
这种对现实的表征当然是一个概率模型,是现实世界事件的联合分布。
Scaling Law 能实现 AGI 吗?
-
根据柏拉图表征假说,随着模型参数、任务多样性、算力 FLOP 的增加,模型的表征会逐渐收敛趋同。
-
这是不是意味着 Scaling Law 可以实现 AGI 呢?
-
是也不是。虽然 Scaling Law 能够实现表征收敛,但是不同方法的收敛效率可能天差地别,也就是说 Scaling Law 是实现 AGI 最笨的方法。
-
举个例子,AlphaFold 3 能够有效预测包括蛋白质在内的生物大分子结构,FSD 能够通过图像识别实现无人驾驶。
-
蛋白质结构预测与无人驾驶可能是两类相对独立的任务。
-
虽然说用一个统一的 AI 模型来同时实现 AlphaFold 3 和 FSD 的能力,应该能让模型的能力进一步增强,但训练过程可能会非常低效,性价比比较低。
理想现实
-
存在一个理想的、统一的现实模型,所有的表征最终都趋向于这个模型。
-
这个模型能够以统计的方式捕捉到我们观察到的真实世界事件的联合分布。
大语言模型中的 “大型”
-
主要体现在参数规模和训练数据量上。
-
一般来说,模型参数规模达到了 1B(10 亿参数) 的数量级,才成为大模型。
-
因为只有达到这个参数以上时,才会有基于 Scaling Law 的涌现现象,而涌现现象正是大模型的魅力,有点像物态变化中的相变,如液态变固态。
缩放定律(Scaling Law)
KM 缩放定律
-
2020 年,Kaplan 等人(OpenAI 团队)提出模型性能与三个主要因素 ——模型规模(N)、** 数据规模(D)和计算算力(C)** 之间的幂律关系。

Chinchilla 缩放定律
-
Hoffmann 等人(DeepMind 团队)于 2022 年提出了一种扩展法则,旨在指导大语言模型充分利用给定的算力资源进行优化训练。
-
强调数据集的重要性,指出在给定的计算预算下,模型的大小和训练数据集的大小应该等比例增加。

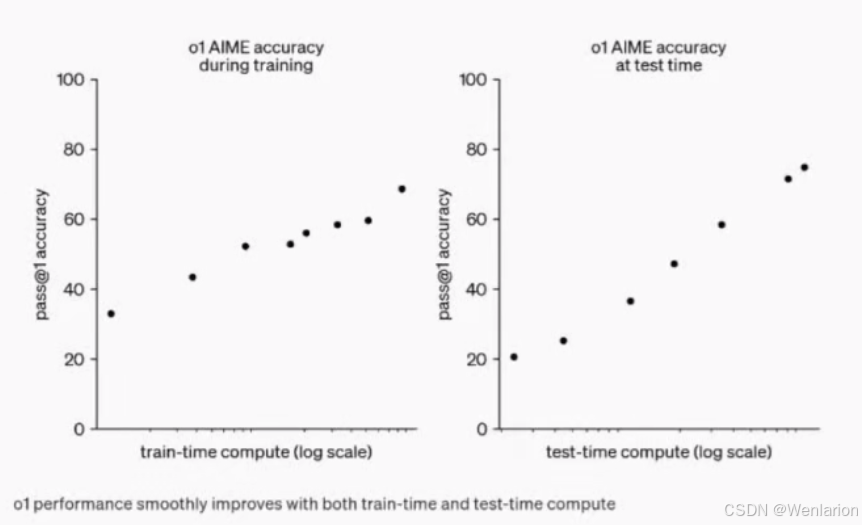
RL 和 TTC 缩放定律
- 谷歌 DeepMind 发表论文:https://arxiv.org/html/2408.03314v1

研究表明,增加测试时(test-time compute)计算比扩展模型参数更有效。
- test-time 其实就是指模型推理时。
- OpenAI o1 模型发布的技术报告也提及:https://openai.com/index/learning-to-reason-with-llms/
参数规模
在深度学习中,模型参数是指网络中可学习调整的权重(weight)和偏置(bias)。在大型语言模型(LLM)中,这些参数的数量非常庞大,通常达到数十亿甚至数千亿。
- GPT-4 达到 1.8 万亿参数
- Llama 3 正在训练 4 千亿参数版本
- 英伟达也开源过 340B 的 Nemotron-4
训练 LLM 的庞大数据集
为了训练大模型,需要大量文本数据,这些数据构成了模型学习的基础。数据集的规模和多样性对模型性能有重要影响。
-
常用数据集:维基百科、Common Crawl、C4、GitHub 等,训练语料大小达到 TB 级别。
-
典型案例:
-
Llama 2:使用 2T token 进行训练
-
Llama 3:使用 15T token 进行训练
-
英伟达 Nemotron-4:使用 9T token 进行训练
-
训练算力
训练大语言模型的预训练阶段,需要巨大的算力投入。
-
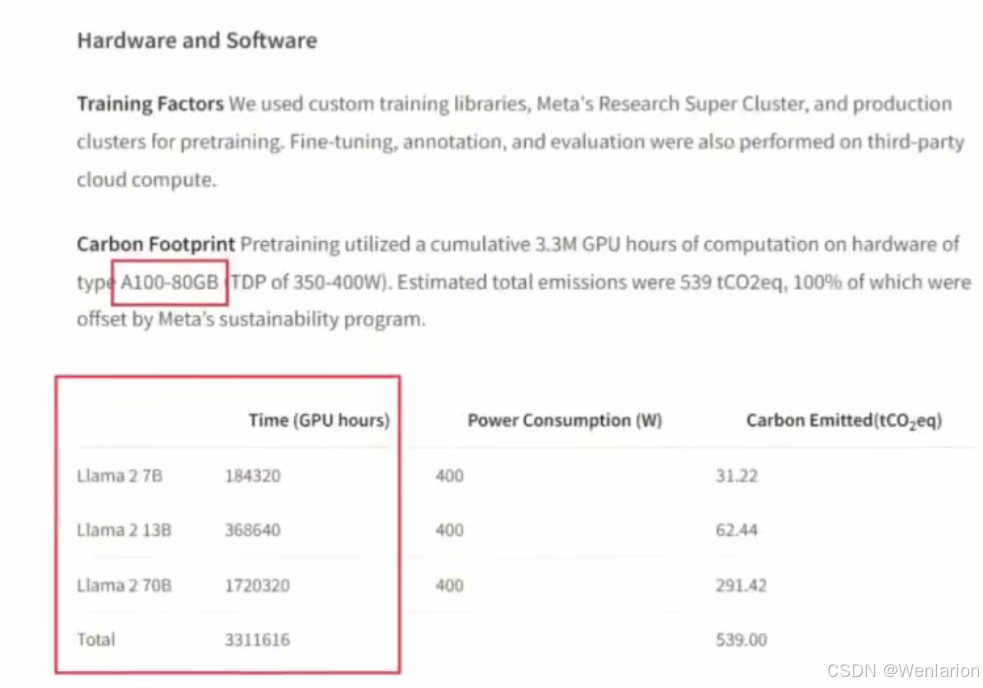
Llama 2:不同尺寸模型训练共消耗 330 多万 A100 小时,其中 70B 版本消耗 170 多万 A100 小时。
-
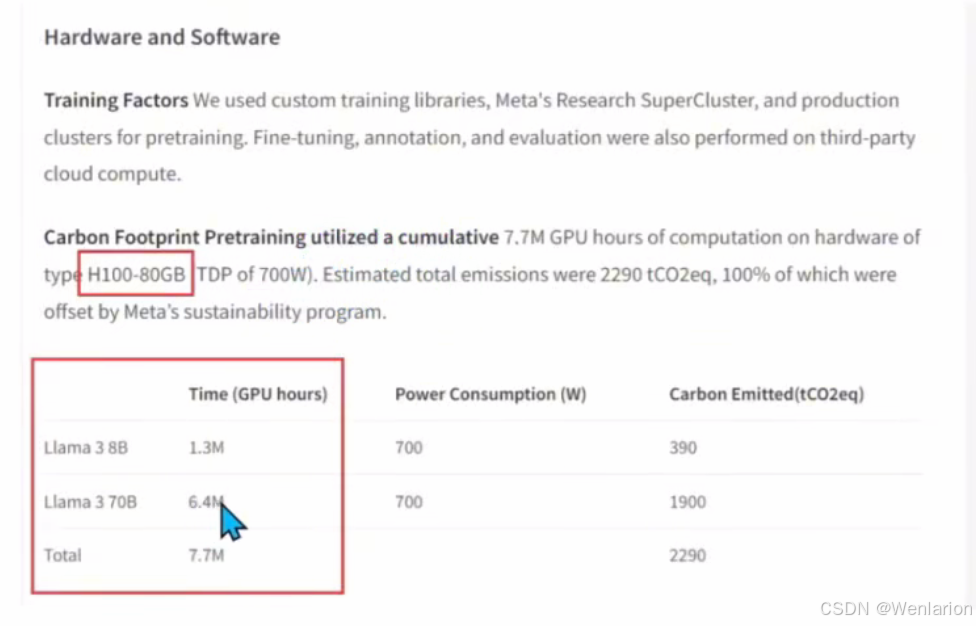
Llama 3:总训练消耗 770 万 H100 小时,其中 70B 版本消耗 640 万 H100 小时。
-
参考:1 万张 A100 在 100% 算力利用率下,也需要约 3 个月完成训练(90% 的利用率已是非常优秀的优化水平)。
Llama 3 算力参数
缩放定律计算示例

模型权重
以 Qwen2.5-7B 模型为例,其权重文件可参考:https://huggingface.co/Qwen/Qwen2.5-7B-Instruct/tree/main?show_file_info=model-00001-of-00004.safetensors
大模型训练本质
大模型在训练过程中本质上学习的是数据集中的知识和基本特征分布。
通过优化算法(如梯度下降)调整权重,以减少预测误差,即模型输出和真实值之间的差异。
LLM 训练常用方法:预测序列中的下一个单词。通过给定一系列单词预测下一个最可能出现的单词,LLM 不仅学习单词预测,还掌握单词在特定上下文中的含义,以及如何组合成有意义的句子和段落。
尽管 “预测下一个单词” 任务本身简单,但训练出的 LLM 展现出处理复杂语言任务的惊人能力,如文本生成、翻译、问答等。
环境准备
电脑配置
硬盘:最好有 80G 剩余空间(Python 虚拟环境及依赖约需 10G,7B 模型 float16 格式约 14G)。
显卡:最好有 8G 独立显卡;若无显卡,则需要 16G 以上 内存,否则无法完整加载 7B 模型。
虚拟环境:学习过程中至少需要安装 2-3 个虚拟环境。
Python 环境安装
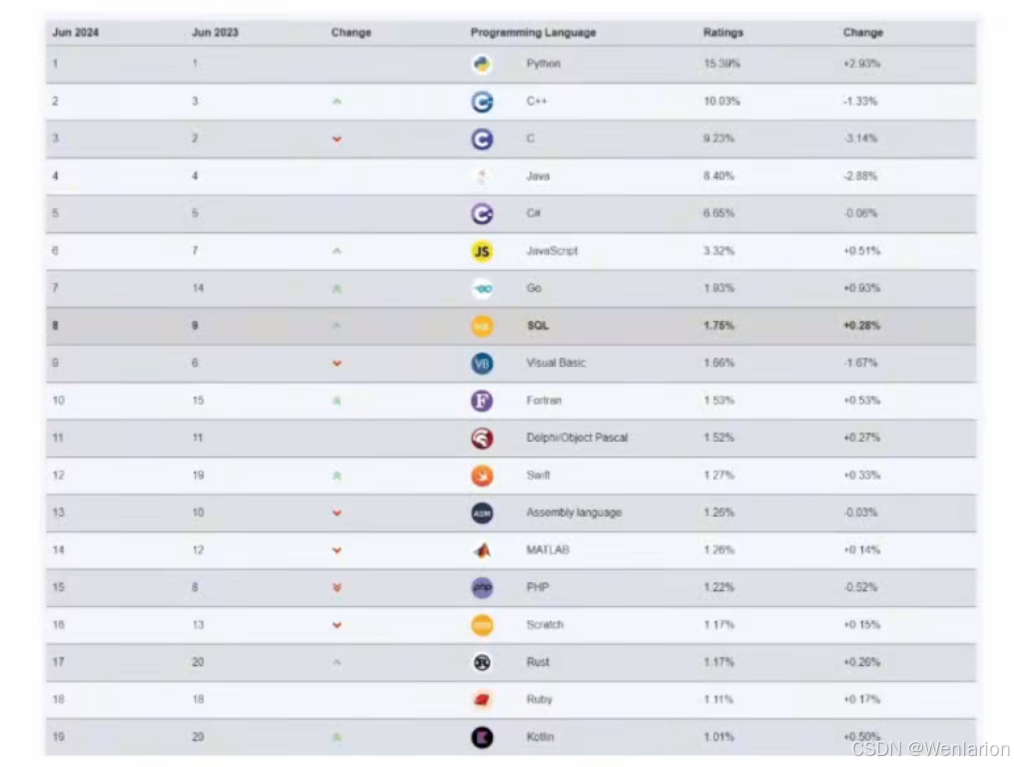
参考:TIOBE 编程语言指数排行榜:https://www.tiobe.com/tiobe-index/
Python 编程语言常年位居编程语言榜前 2,学习使用简单,编程高效,生态丰富,特别是对数据处理方便,在学术研究、数据分析、人工智能上使用得特别广泛。
随着人工智能的爆发,Python 编程语言更是一直稳居第一。
Python 在 AI 开发中的性能误区解析
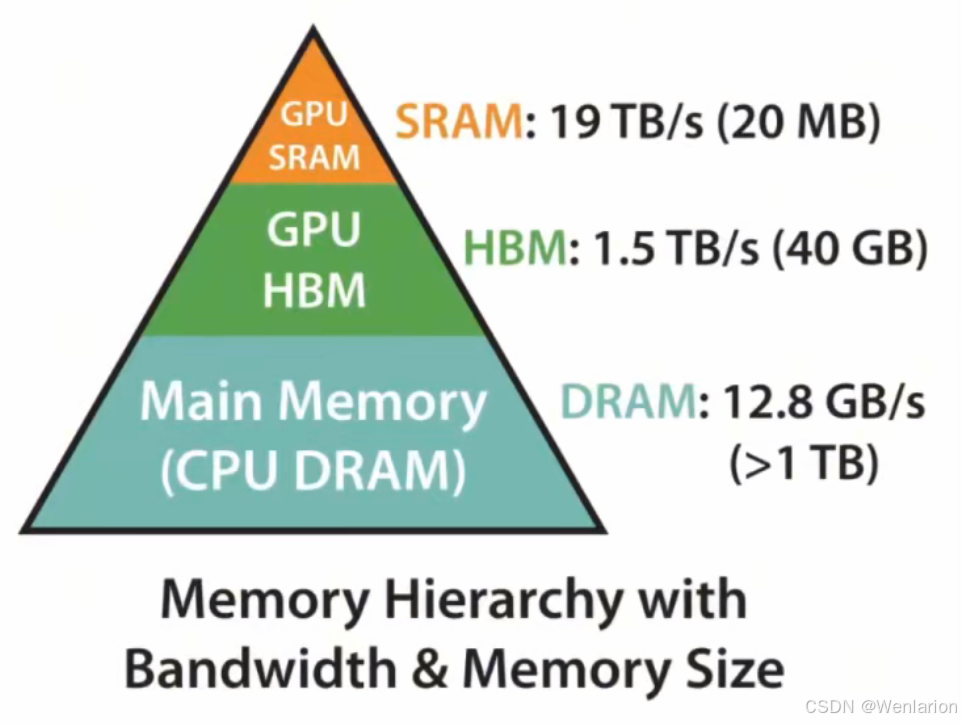
大模型的性能瓶颈主要分布如下:
-
80% 在算力:核心是各种大矩阵的乘法和加法并行性,主要靠 GPU 解决,依赖 CUDA 支持。
-
15% 在 I/O:包括内存到 GPU 的传输、GPU 的 HBM 和高速缓存的 I/O。
-
不到 5% 在编程语言本身:因此,Python 非常适合 AI 开发,同时 PyTorch 开发的模型也支持直接编译为二进制代码,进一步优化性能。
结论:
-
做 AI 开发时,不必为 Python 的性能焦虑。
-
但如果涉及 CPU 上的实时任务,编程语言的性能就变得至关重要。
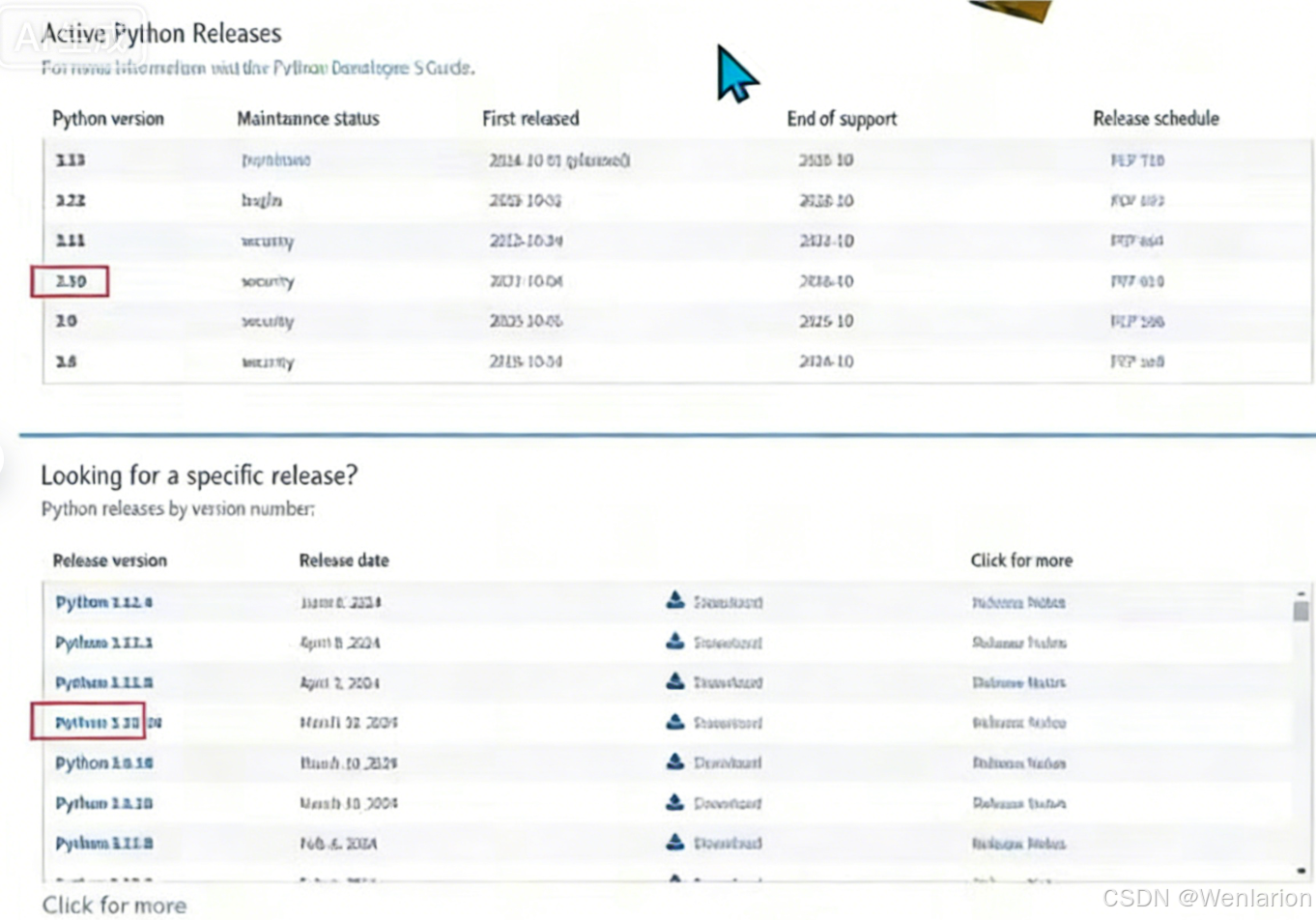
Python 环境安装建议
-
推荐版本:Python 3.10 版本
-
很多 AI 框架和项目都以 Python 3.10 为基础开发。
-
版本过老或过新都可能导致不兼容问题。
-
Miniconda 安装
下载地址:https://docs.anaconda.com/miniconda/
安装 Miniconda 会集成基础的 Python 依赖包,同时方便创建和管理虚拟 Python 环境。
VSCode 开发环境安装
下载地址:https://code.visualstudio.com/download
各系统均可免费下载使用。
安装好 VSCode 后,还需安装 Python 插件,可根据习惯安装中文插件、AI 编程助手等。
Python 基础语法
所有编程语言的基础语法都大同小异:
-
基础部分:变量类型、控制语句、条件语句,以及常用数据结构(Python 中如
list(列表,对应其他语言的数组)、dict(字典,对应其他语言的 map)、set(集合))。 -
进阶部分:文件操作、网络编程、数据库操作、线程操作等。
Python 特色
Python 的核心数据处理 “三剑客”:
-
NumPy:支持大量维度数组与矩阵运算的库,为 Python 提供强大的数值计算能力。
-
Pandas:开源的数据分析库,设计用于处理结构化(表格、多种数据类型)和时序数据。提供
DataFrame和Series两种主要数据结构,简化数据操作。 -
Matplotlib:用于创建静态、交互和实时 2D 图表的库,可生成条形图、折线图、散点图等多种格式图表。
机器学习
Python 中基于机器学习的库提供了各种工具和算法:
-
PyTorch:由 Facebook 开发的开源机器学习库,广泛用于计算机视觉和自然语言处理。
- TensorFlow:由 Google 开发的开源库,适合构建深度学习和机器学习模型,支持多种计算平台。
- Keras:一个高层神经网络 API,可以在 TensorFlow、Theano 和 CNTK 后端上运行,以简化深度学习模型的构建。
- Scikit-learn:一个简单高效的机器学习库,包含许多用于分类、回归、聚类和维度降低的算法。
- XGBoost:一个梯度增强库,非常适合用于分类和回归任务。
- LightGBM:一个梯度提升框架,使用基于树的学习算法,优化了速度和性能。
- spaCy:一个工业级自然语言处理库,专注于提供最好的性能和易用性。
- NLTK (Natural Language Toolkit):一个用于人类语言数据处理的库,包括分类、标记、解析、语义推理等功能。
思想转变
AI 模型都是概率模型:
- 从单纯的概率模型 → 现实世界事件联合分布的统一表征
- 从非线性拟合的通用逼近定理 → 柯尔莫哥洛夫信息论 → 压缩即智能
生成式 AI 乃至 AGI,本质上都是概率模型。现实世界本身也是概率模型,具有不确定性。工程师开发产品时讲究确定性,因此需要转变思维,这对理解 AI 本质和大模型有很大帮助。
2、大模型微调实操 -- Llama Factory
大模型微调的主流工具较多,使用较简单的是开源项目 llama-factory,常用的还有阿里的 swift、微软的 deepspeed-chat,以及 Colossal-AI、Firefly 等。
Llama Factory 环境安装
开源大模型(如 LLaMA 系列、Qwen 系列、Gemma 和 Mistral 系列等)主要使用通用数据进行预训练。本课程不深入预训练技术,重点在于实操微调,因为预训练成本高。全链路技术包括预训练(pt)、指令微调(sft)、基于人工反馈的对齐(rlhf)等,全链路模型在不同下游场景和垂直领域的效果有待进一步提升,从而催生了微调训练的需求。
LLaMA-Factory 的目标
整合主流的高效训练 / 微调技术,如(增量)预训练、(多模态)指令 / 监督微调、奖励模型训练、PPO 训练、DPO 训练、KTO 训练、ORPO 训练等。
- 支持 16 比特全参数微调、冻结微调、LoRA 微调,以及基于 AQLM/AWQ/GPTQ/LLM.int8/HQQ/EETQ 的 2/3/4/5/6/8 比特 QLoRA 微调。
- 适配了市场主流开源模型,如 LLaMA、LLaVA、Mistral、Mixtral-MoE、Qwen、Yi、Gemma、Baichuan、ChatGLM、Phi 等。
- 项目提供了多个高层次抽象的调用接口,包含多阶段训练、推理测试、benchmark 评测、API Server 等,使开发者开箱即用。同时借鉴 Stable Diffusion WebUI 相关思路,提供了基于 gradio 的网页版工作台,方便初学者快速上手操作,开发自己的第一个模型。
前置准备
训练顺利运行需要包含 4 个必备条件:
- 机器本身的硬件和驱动支持(包含显卡驱动、网络环境等)
- 本项目及相关依赖的 Python 库的正确安装(包含 CUDA、PyTorch 等)
- 目标训练模型文件的正确下载
- 训练数据集的正确构造和配置
相关下载地址:
- 英伟达显卡驱动更新地址:https://www.nvidia.cn/Download/index.aspx?lang=cn
- CUDA 下载安装地址:https://developer.nvidia.com/cuda-12-2-0-download-archive/
- PyTorch 下载安装地址:https://pytorch.org/get-started/previous-versions/
- Llama Factory 项目和文档地址:
环境下载地址
- Python 环境:https://www.python.org/downloads/
- Miniconda:https://docs.anaconda.com/miniconda/
硬件环境校验(显卡驱动与 CUDA)
下载地址
- 英伟达显卡驱动:https://www.nvidia.cn/Download/index.aspx?lang=cn
- CUDA 12.2.0:https://developer.nvidia.com/cuda-12-2-0-download-archive/
校验命令
检查显卡驱动:
nvidia-smi检查 CUDA 安装:
nvcc -V若输出版本信息,则表示安装成功。
版本建议
CUDA 建议安装 12.0 及以上版本,尤其是在使用 QLoRA 微调或大模型量化时,新的优化算法对较新的 CUDA 和 PyTorch 版本依赖更高。
软件环境准备
在安装 LLaMA-Factory 之前,需确保安装以下依赖:
必选依赖(Mandatory)
| 依赖包 | 最低版本 | 推荐版本 |
|---|---|---|
| python | 3.8 | 3.11 |
| torch | 1.13.1 | 2.3.0 |
| transformers | 4.41.2 | 4.41.2 |
| datasets | 2.16.0 | 2.19.2 |
| accelerate | 0.30.1 | 0.30.1 |
| peft | 0.11.1 | 0.11.1 |
| trl | 0.8.6 | 0.9.4 |
可选依赖(Optional)
| 依赖包 | 最低版本 | 推荐版本 |
|---|---|---|
| CUDA | 11.6 | 12.2 |
| deepspeed | 0.10.0 | 0.14.0 |
| bitsandbytes | 0.39.0 | 0.43.1 |
| vllm | 0.4.3 | 0.4.3 |
| flash-attn | 2.3.0 | 2.5.9 |
拉取 LLaMA-Factory 代码
运行以下命令安装 LLaMA-Factory 及其依赖:
git clone --depth 1 https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e ".[torch,metrics]"创建虚拟环境
为了避免依赖冲突,建议先创建一个独立的虚拟环境来安装项目。
使用 Conda/Miniconda
创建虚拟环境(Python 3.10):
conda create -n llama_factory python=3.10
激活虚拟环境:
conda activate llama_factory
安装 PyTorch(与 CUDA 12.1 匹配):
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
使用 venv(备选方案)
创建虚拟环境(在项目目录下):
python -m venv python310
激活虚拟环境(Windows):
python310/Scripts/activate
下载地址
- Python 环境:https://www.python.org/downloads/
- Miniconda:https://docs.anaconda.com/miniconda/
量化环境配置
1. 安装 bitsandbytes(Windows 下 QLoRA)
在 Windows 上启用量化 LoRA(QLoRA),需要根据 CUDA 版本安装适配的 bitsandbytes 预编译包:
pip install https://github.com/jllllll/bitsandbytes-windows-webui/releases/download/wheels/bitsandbytes-0.41.2.post2-py3-none-win_amd64.whl
注意:QLoRA 建议安装 CUDA 11.8 及以上版本(如 12.1),使用 AWQ 等量化算法时,CUDA 11.8 以下可能导致 PyTorch 报错。
2. 安装 AutoAWQ(AWQ 量化支持)
如果大模型使用 AWQ 量化,需要额外安装 autoawq 模块:
pip install autoawq
环境校验
安装完成后,运行以下 Python 代码校验 GPU 环境是否正常:
import torch
torch.cuda.current_device() # 检查当前 CUDA 设备
torch.cuda.get_device_name(0) # 检查设备名称
torch.__version__ # 检查 PyTorch 版本
- 如果识别不到可用的 GPU,说明环境准备有问题,需要先处理驱动、CUDA 或 PyTorch 安装问题。
硬件建议
- 不同模型和训练方式对 GPU 显存要求不同,可参考:LLaMA-Factory 硬件要求
- 新手建议从 RTX 3090 或 4090 起步,可较容易地训练主流入门级大模型(7B/8B 版本)。
- 先从单机训练开始,逐步熟悉流程。
大模型训练硬件配置(显存需求估计)
下表展示了不同训练方法、精度和模型规模下的显存需求(GB):
| 训练方法 | 精度 (Bits) | 7B | 13B | 30B | 70B | 110B | 8x7B | 8x22B |
|---|---|---|---|---|---|---|---|---|
| Full (全参数) | AMP | 120 | 240 | 600 | 1200 | 2000 | 900 | 2400 |
| Full (全参数) | 16 | 60 | 120 | 300 | 600 | 900 | 400 | 1200 |
| Freeze (冻结部分层) | 16 | 20 | 40 | 80 | 200 | 360 | 160 | 400 |
| LoRA/GaLore/BAdam | 16 | 16 | 32 | 64 | 160 | 240 | 120 | 320 |
| QLoRA | 8 | 10 | 20 | 40 | 80 | 140 | 60 | 160 |
| QLoRA | 4 | 6 | 12 | 24 | 48 | 72 | 30 | 96 |
| QLoRA | 2 | 4 | 8 | 16 | 24 | 48 | 18 | 48 |
关键结论 💡
-
QLoRA 量化 能显著降低显存需求,例如 7B 模型在 4bit 精度下仅需 6GB 显存。
-
LoRA 微调 在 16bit 精度下,7B/13B 模型分别只需 16GB/32GB 显存,适合消费级显卡(如 3090/4090)。
-
全参数训练 显存需求极高,仅适用于专业级多卡集群。
启动 LLaMA-Factory
安装 LLaMA-Factory 完成了以下几件事:
- 新建一个 LLaMA-Factory 使用的 Python 环境(可选)。
- 安装 LLaMA-Factory 所需的第三方基础库(
requirements.txt包含的库)。 - 安装评估指标所需的库,包含
nltk、jieba、rouge-chinese。 - 安装 LLaMA-Factory 本身,并在系统中生成命令
llamafactory-cli。
环境校验
在激活虚拟环境后,输入以下命令获取训练参数指导,校验库是否安装成功:
llamafactory-cli train -h
注意:
llamafactory-cli位于当前 Python 虚拟环境的scripts目录下,正常激活虚拟环境即可使用。
启动 WebUI
- 基础启动:
llamafactory-cli webui - 指定 GPU 启动(例如使用第 0 号 GPU):
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webui -
开启 Gradio Share 功能并修改端口:
CUDA_VISIBLE_DEVICES=0 GRADIO_SHARE=1 GRADIO_SERVER_PORT=7860 llamafactory-cli webui
注意:WebUI 版本目前只支持单机单卡和单机多卡。如果是多机多卡,请使用命令行版本。
LLaMA-Factory 支持模型速查表
以下是 LLaMA-Factory 支持的主流开源大模型汇总,包含模型大小和对应模板,方便你在微调时快速查找:
| 模型名 | 介绍 | 模型大小 | Template |
|---|---|---|---|
| Baichuan 2 | 搜狗创始人王小川创业的项目 | 7B/13B | baichuan2 |
| BLOOM/BLOOMZ | - | 560M/1.1B/1.7B/3B/7.1B/176B | - |
| ChatGLM3 | - | 6B | chatglm3 |
| Command R | Cohere 公司产品,在 RAG 方面表现突出 | 35B/104B | cohere |
| DeepSeek (Code/MoE) | 量化公司幻万旗下的模型 | 7B/16B/67B/236B | deepseek |
| Falcon | 阿拉伯的一家 AI 公司,推出了基于 Mamba 的大模型 | 7B/11B/40B/180B | falcon |
| Gemma/Gemma 2/CodeGemma | Google 家的模型 | 2B/7B/9B/27B | gemma |
| GLM-4 | 清华智谱,还开源了有文生视频的项目 CogVideo | 9B | glm4 |
| InternLM2/InternLM2.5 | 上海人工智能实验室、商汤等一起搞的 | 7B/20B | intern2 |
| Llama | - | 7B/13B/33B/65B | - |
| Llama 2 | - | 7B/13B/70B | llama2 |
| Llama 3/Llama 3.1 | Meta 开源,基于开源模型 | 8B/70B | llama3 |
| LLaVA-1.5 | 微软开源的多模态大模型 | 7B/13B | vicuna |
| MiniCPM | 面壁智能的,MiniCPM-llama2.5 小钢炮被斯坦福抄袭过 | 1B/2B | cpm |
| Mistral/Mixtral | Meta 和谷歌的研究人员在巴黎成立的公司,开源模型很强 | 7B/8x7B/8x22B | mistral |
| OLMo | - | 1B/7B | - |
| PaliGemma | - | 3B | gemma |
| Phi-1.5/Phi-2 | 微软开源的小模型 | 1.3B/2.7B | - |
| Phi-3 | - | 4B/7B/14B | phi |
| Qwen/Qwen1.5/Qwen2 (Code/Math/MoE) | 阿里开源的模型 | 0.5B/1.5B/4B/7B/14B/32B/72B/110B | qwen |
| StarCoder 2 | - | 3B/7B/15B | - |
| XVerse | - | 7B/13B/65B | xverse |
| Yi/Yi-1.5 | 开复老师家的零一万物 | 6B/9B/34B | yi |
| Yi-VL | - | 6B/34B | yi_vl |
| Yuan 2 | - | 2B/51B/102B | yuan |
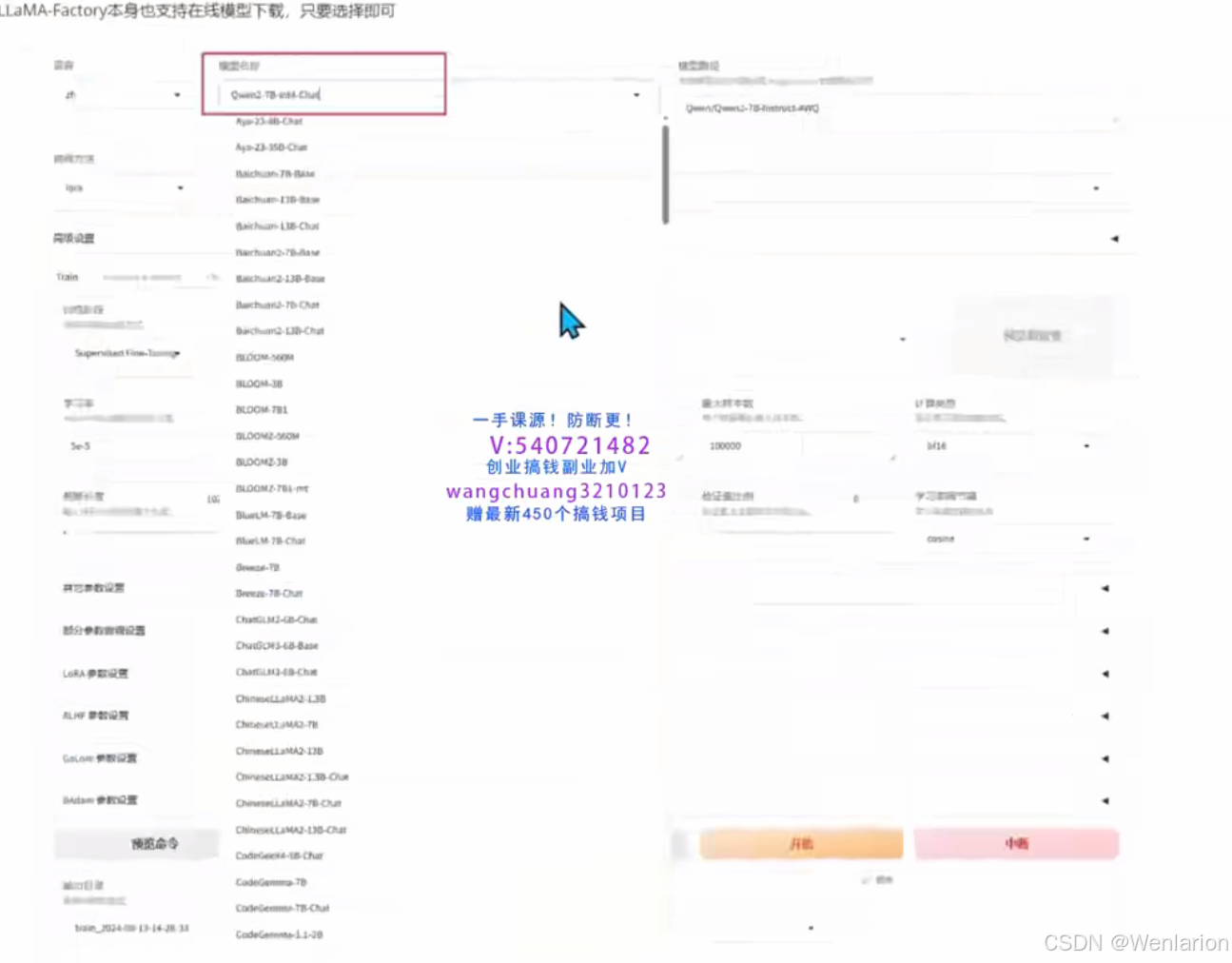
LLaMA-Factory本身也支持在线模型下载,只需选择即可
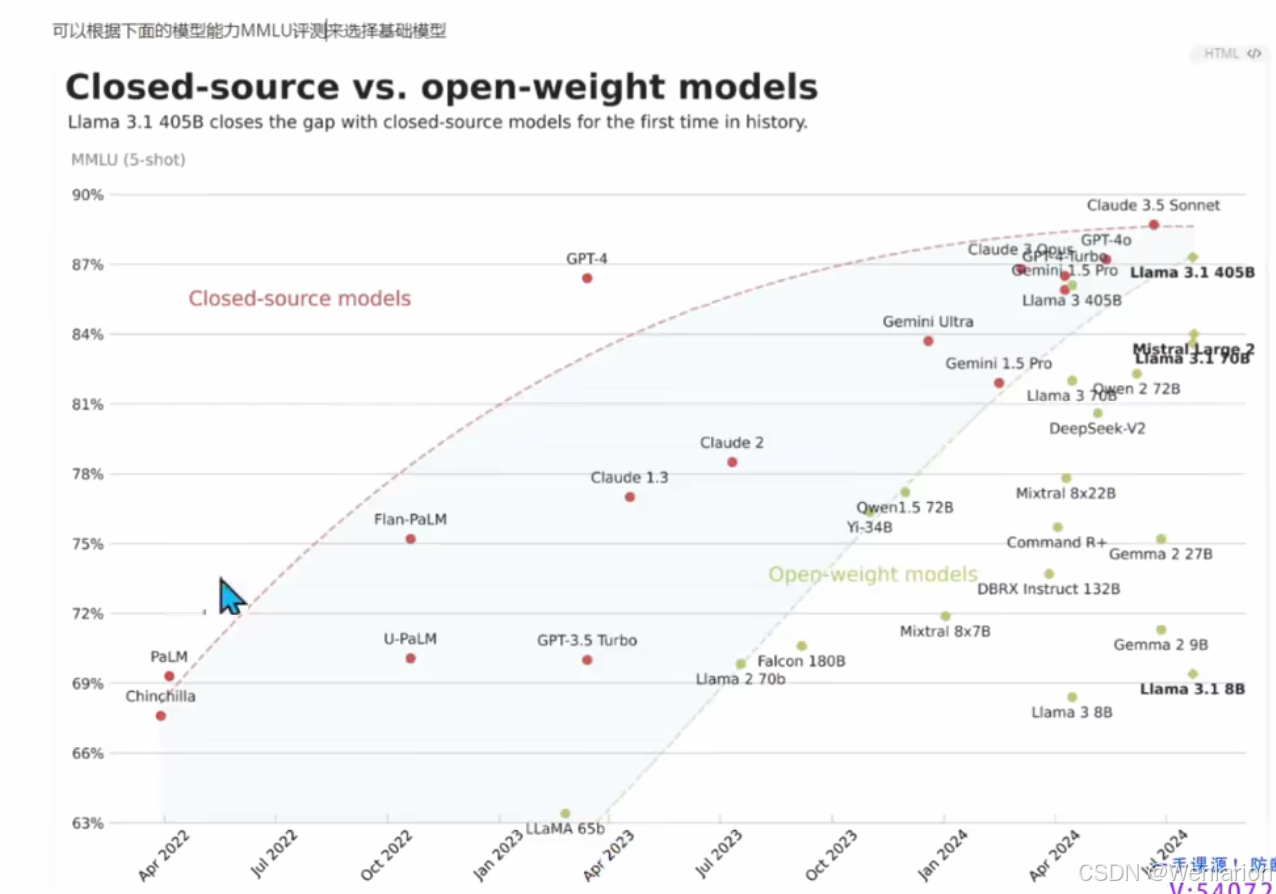
可以根据下面的模型能力MMLU评测来选择基础模型
手动下载模型
作为工程师,不应局限于傻瓜式操作,也可以手动从 Hugging Face 和 ModelScope 下载模型,后续使用时通过绝对路径控制使用哪个模型。
以 Meta-Llama3-8B-Instruct 为例,通过 Hugging Face 下载(可能需要先提交申请通过),一般不下载 Meta 官方原始模型:
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct
下面的地址可正常下载 Chat 版本:https://huggingface.co/shenzhi-wang/Llama3-8B-Chinese-Chat/tree/main
ModelScope 下载(适合中国大陆网络环境):
git clone https://www.modelscope.cn/LLM-Research/Meta-Llama-3-8B-Instruct.git
代码下载模型
由于 Llama3-8B 模型较大(8B 的 float16 精度也有 16G 大小),先用 Qwen2-1.5B-Instruct 做实验,下载速度更快。使用 ModelScope 库下载:
# 模型下载
from modelscope import snapshot_download
# Linux 系统
# local_dir = "/LLaMA-Factory/Qwen2-1.5B-Instruct"
# Windows 系统
local_dir = "F:/sotaAI/LLaMA-Factory/Qwen2-1.5B-Instruct"
model_dir = snapshot_download('qwen/Qwen2-1.5B-Instruct', local_dir=local_dir)使用 transformers 编写推理代码
import transformers
import torch
# 切换为你下载的模型文件目录,这里的demo是Qwen2-1.5B-Instruct
# 如果是其他模型,比如llama3, chatglm,请使用其对应的官方demo
# linux系统
#model_id = "/LLaMA-Factory/Qwen2-1.5B-Instruct"
#windows系统
model_id = "F:/sotaAI/LLaMA-Factory/Qwen2-1.5B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "你是一个电商客服,专业回答售后问题"},
{"role": "user", "content": "你们这儿包邮吗?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
# 不同模型的eos_token_id不同,比如llama3,"<|eot_id|>"
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|im_end|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
#输出示例
#您好!感谢您对我们的关注。我们提供全国范围内免费快递服务,但是具体的运费信息需要根据您的收货地址和订单详情来计算,请您在下单时仔细核对并确认运费信息。如果您有任何疑问或需要帮助,欢迎随时联系我们。祝您购物愉快!微调数据集
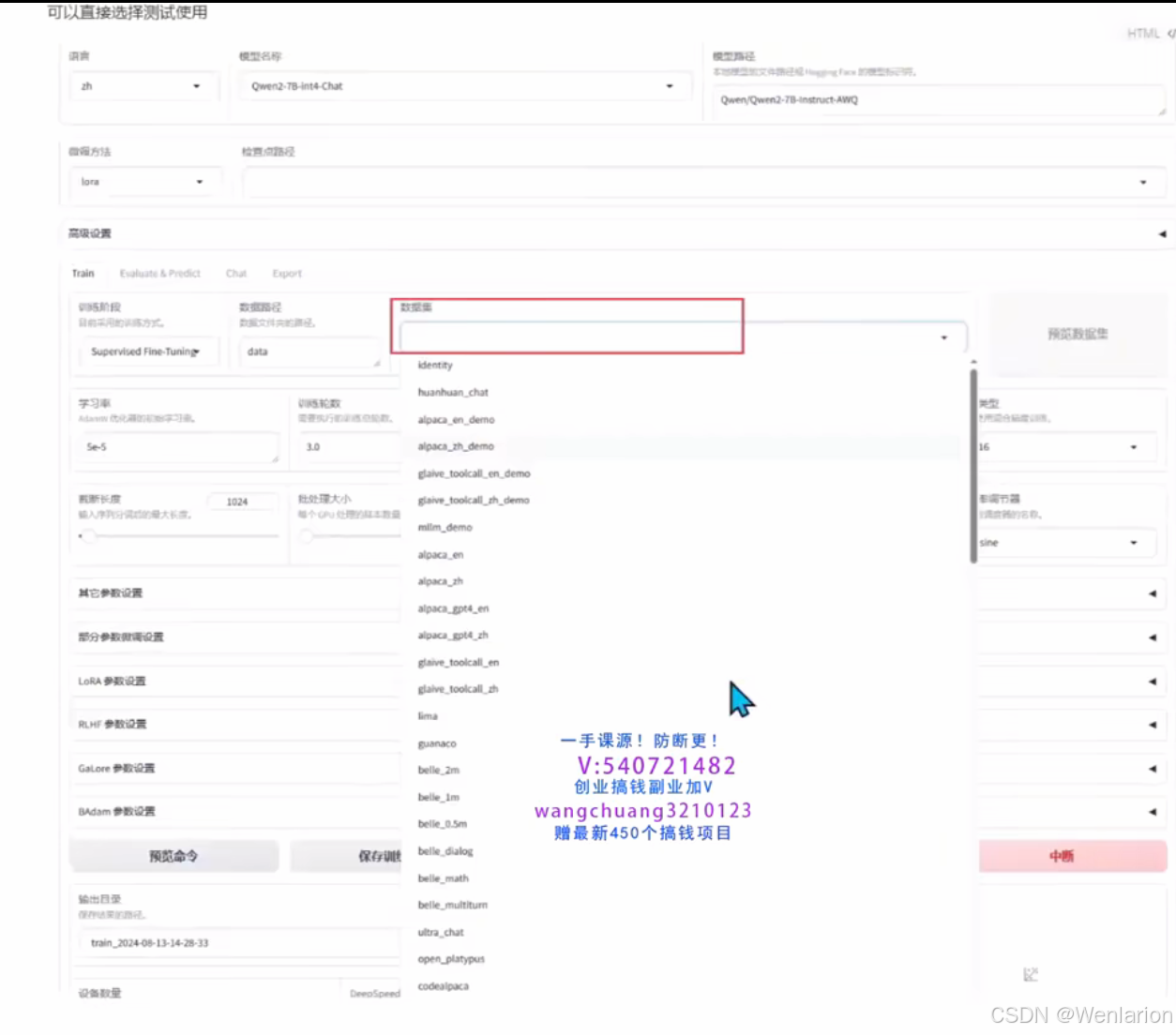
LLaMA-Factory 默认支持以下预训练、指令微调和偏好数据集:
预训练数据集
-
Wiki Demo (en)
-
RefinedWeb (en):Falcon 系列模型采用此数据集预训练,由阿布扎比技术创新研究院(TII)基于 Common Crawl 语料库构建。经过严格过滤和大规模去重处理,公开摘录包含约 10 亿个实例,约 968 万个独立网页,包含 500-650G Token(取决于标记器),可通过精选语料库增强。公开摘录下载量约 500GB,解压后需 2.8TB 本地存储空间。
-
RedPajama V2 (en):用于训练大型语言模型的开放数据集,包含超 1000 亿份文本文档,其中 300 亿份带有高质量注释,200 亿份为唯一文档。
去重文档和标记计数(head_middle):
| 语言 | # 份文件(总计) | 预估 token 数量(总计) |
|---|---|---|
| 英文 | 14.5 亿 | 20.5 T |
| 德 | 1.9 亿 | 3.0 T |
| 法国 | 1.6 亿 | 2.7 T |
| 西文 | 1.8 亿 | 2.8 T |
| 它 | 0.9 亿 | 1.5 T |
| 全部的 | 20.8 亿 | 30.4 T |
- Wikipedia (en)
- Wikipedia (zh):基于中文维基 2023 年 7 月 20 日的 dump 存档,仅保留了 254,547 条质量较高的词条内容。
- Pile (en)
- SkyPile (zh):昆仑万维开源的 600GB、150B Tokens 高质量中文语料数据集(Skypile/Chinese-Web-Text-150B),是目前最大的开源中文数据集之一,可用于大模型预训练和定制模型。
- FineWeb (en)
- FineWeb-Edu (en)
- The Stack (en)
- StarCoder (en)
指令微调数据集
LLaMA-Factory 默认支持以下指令微调数据集:
- Identity (en&zh)
- Stanford Alpaca (en)
- Stanford Alpaca (zh):包含弱智吧的 2449 个问题的微调数据集
- Alpaca GPT4 (en&zh):GPT-4 生成的数据,用于构建具有监督学习和强化学习的指令跟踪 LLM
- Glaive Function Calling V2 (en&zh):用于训练和评估大模型函数调用(Function Calling)能力的数据集
- LIMA (en):论文 LIMA: Less Is More for Alignment 用到的高质量数据集
- Guanaco Dataset (multilingual)
- BELLE 2M (zh):BELLE 项目提供的 150 万中文指令微调数据集
- BELLE 1M (zh)
- BELLE 0.5M (zh)
- BELLE Dialogue 0.4M (zh)
- BELLE School Math 0.25M (zh)
- BELLE Multiturn Chat 0.8M (zh)
- UltraChat (en)
- OpenPlatypus (en)
- CodeAlpaca 20k (en):专为代码生成任务设计的指令跟随数据集,包含 20,000 个独特指令及对应输出,用于微调大型预训练语言模型以执行代码相关任务
- Alpaca CoT (multilingual)
- OpenOrca (en)
- SlimOrca (en)
- MathInstruct (en):精心策划的指令调整数据集,结合了来自 13 个数学原理数据集的信息,强调混合使用思维链(CoT)和思维程序(PoT)原理,确保对不同数学领域的广泛覆盖,用于训练和评估模型在数学推理方面的性能
- Firefly 1.1M (zh):Firefly 项目的数据集,收集了 23 个常见的中文数据集,对每个任务由人工书写若干种指令模板,保证数据的高质量与丰富度,数据量为 115 万
- Wiki QA (en)
- Web QA (zh):用于训练和评估自然语言处理模型的数据集合,特点包括来源广发、问题多样
- WebNovel (zh):包含从 12560 本网文提取的约 21.7M 条可用于训练小说生成的中文指令数据
- Dolly 15k (de)
- Alpaca GPT4 (de)
- OpenSchnabeltier (de)
- Evol Instruct (de)
- Dolphin (de)
- Booksum (de)
- Airoboros (de)
- Ultrachat (de)
偏好数据集
- DPO mixed (en&zh)
- UltraFeedback (en)
- Orca DPO Pairs (en)
- HH-RLHF (en)
- Nectar (en)
- Orca DPO (de)
- KTO mixed (en)
可以直接测试使用
数据格式
在大语言模型训练中,预训练、监督微调(SFT)和偏好对齐的数据集有不同的格式要求,通常一个样本由(输入,输出)的数据对构成,主要分为以下 3 种场景:
预训练场景
- 核心特点:数据集无需手工处理标签,采用自监督学习方式,从大量无标签文本中学习语言结构。
- 任务目标:以自回归语言模型(如 GPT 系列)为例,模型根据前面的词预测下一个词。
- 输入输出生成:从文本中提取连续片段,通过滑动窗口生成标记序列。
- 示例:以
The cat is on the mat为例:
| 输入序列 | 预测目标 |
|---|---|
| [The] | cat |
| [The, cat] | is |
| [The, cat, is] | on |
| [The, cat, is, on] | the |
| [The, cat, is, on, the] | mat |
SFT(有监督微调 Supervised Fine-Tuning)
- 核心特点:核心是问题(Question)和答案(Answer)对,通常以 JSON 键值对形式出现。
- 示例场景:如 Text2SQL 任务,问题是文本提示词,答案是输出的 SQL 语句。
偏好对齐场景
- 核心特点:包含成对的输入和输出,输出被标记为 “首选”(preferred)或 “非首选”(Rejected),使模型学习生成更符合人类价值观的响应。
- 适用算法:主要适配 DPO 等热门强化学习算法。
LLaMA-Factory 支持格式:
- 支持 alpaca 格式 和 sharegpt 格式 的数据集,均为 JSON 格式文件。
alpaca 格式
[
{
"instruction": "人类指令(必填)",
"input": "人类输入(选填)",
"output": "模型回答(必填)",
"system": "系统提示词(选填)",
"history": [
["第一轮指令(选填)", "第一轮回答(选填)"],
["第二轮指令(选填)", "第二轮回答(选填)"]
]
}
]
格式说明:
- 在指令监督微调时,
instruction与input字段会拼接为instruction\ninput作为人类指令,output字段作为模型回答。 - 若指定
system字段,其内容将作为系统提示词。 history是一个由二元字符串列表构成的列表,代表历史对话中每轮的指令和回答;在指令监督微调时,历史消息中的回答也会用于模型学习。
alpaca 格式样例数据集
[
{
"instruction": "识别并解释给定列表中的两个科学理论:细胞理论和日心说。",
"input": "",
"output": "细胞理论是生物科学的一个理论,它认为所有生命体都是由微小的基本单元------细胞所构成。这是生物学的一个基础理论,认为细胞是所有生物的基本结构和功能单位,所有的生物都是由一个或多个细胞组成,细胞只能通过细胞分裂产生新的细胞。这一理论由薛定谔、施瓦内和雪莱于1839年首次提出。\n\n日心说是指太阳是太阳系的中心,也就是说,行星围绕太阳旋转的理论。这个理论打破了传统的地心说观点,认为地球并不是宇宙的中心。日心说的提出者是尼古拉·哥白尼,他在16世纪初发表了他的著作《天体运行论》,阐述了太阳系行星围绕太阳运行的模型,为天文学的发展做出了巨大贡献。"
},
{
"instruction": "输入三支篮球队的名称并生成一个适当的口号。",
"input": "输入:俄克拉荷马城雷霆队,芝加哥公牛队,布鲁克林网队。",
"output": "输出:\"雷霆,公牛和网队:各显神通,角逐群雄!\""
},
{
"instruction": "比较以下两位著名人物,使用特征列表并以句子形式提供输出。",
"input": "人物1:阿尔伯特·爱因斯坦\n人物2:斯蒂芬·霍金\n特征:智力、教育、对世界的影响",
"output": "阿尔伯特·爱因斯坦和斯蒂芬·霍金都是拥有极其出色智力的人物。两人都取得过非常高的教育成就,他们推进了科学发展并在世界范围内产生了深远的影响。爱因斯坦以其相对论和质能关系公式而闻名,而霍金以其关于黑洞和宇宙的发现而著称。两位科学家都以其深厚的学识和非凡的贡献影响了世界。"
}
]sharegpt 格式
相比 alpaca 格式,sharegpt 格式支持更多角色种类(如 human、gpt、observation、function 等),它们构成对象列表并出现在 conversations 列中。
格式规则:
human和observation必须出现在奇数位置gpt和function必须出现在偶数位置
[
{
"conversations": [
{
"from": "human",
"value": "人类指令"
},
{
"from": "function_call",
"value": "工具参数"
},
{
"from": "observation",
"value": "工具结果"
},
{
"from": "gpt",
"value": "模型回答"
}
],
"system": "系统提示词(选填)",
"tools": "工具描述(选填)"
}
]偏好数据格式说明
-
SFT 微调一般使用 alpaca 格式,而 DPO 优化的偏好数据通常采用 sharegpt 格式。
DPO 优化偏好数据集
DPO 数据集的核心是为每个输入提供 “首选(chosen)” 和 “拒绝(rejected)” 两种模型输出,用于训练模型区分高质量和低质量的响应。
示例结构:
| conversations (人类指令) | chosen (首选回答) | rejected (拒绝回答) |
|---|---|---|
[{"from": "human", "value": "Part 1. Definition\n在这个任务中,你会得到一些推特帖子。你的任务是标记帖子中用户表达的情感,如悲伤、喜悦、爱、愤怒、恐惧或惊讶..."}] |
{"from": "gpt", "value": "悲伤\n解释:这篇帖子的情绪是悲伤,因为用户提到“感觉相当悲伤和为自己感到抱歉”...因此,标签是“悲伤”。"} |
{"from": "gpt", "value": "悲伤\n\n解释:这篇帖子的情绪是悲伤,因为用户说自己“感到郁闷”和“几乎凌晨还清醒着在这里写”,这表明他们正在经历悲伤。"} |
[{"from": "human", "value": "选择以下类型的计算机语言:过程式、面向对象或并行\nJava"}] |
{"from": "gpt", "value": "Java是一种面向对象的编程语言。它以其平台独立性而闻名...Java被广泛用于Web应用程序、移动应用程序开发(Android)和企业级软件开发。"} |
{"from": "gpt", "value": "你好!我在这里帮助您解决问题。但是,我必须告诉您,您选择的计算机语言类型“Java”并不是一个有效的选项..."} |
[{"from": "human", "value": "哪一个富含蛋白质,床还是墙?"}] |
{"from": "gpt", "value": "床和墙都不是蛋白质的来源,因为它们都是无生命的物体。蛋白质通常存在于肉类、奶制品、豆类和坚果等食物中。"} |
{"from": "gpt", "value": "对不起,我无法回答那个问题。请提供更具体的信息,让我知道你需要什么帮助。"} |
在对齐(alignment)领域,不存在一个基准真实模型(ground truth model)能够对人类意图进行建模,因此学者们利用人类统一性相对较高的偏好数据来做对齐。然而,即使是偏好数据,在标注过程中也存在不一致,来源包括:
- 不同群体的价值观不同
- 人与人之间的认知有微小差别
- 标注标准模糊不清
- 错误标注
- 恶意标注
从目前主流大模型和常用的开源 dataset 构建数据的方式来看,数据标注往往会经历一个复杂的过程:标注人员筛选 → 撰写或采样 prompt → 不同模型生成响应对(response pairs) → 标注人员标注 → 质量监测团队筛选标注 → 形成最终的偏好数据集
HelpSteer2 数据集
HelpSteer2 数据集是由 NVIDIA 发布的一个开源数据集,旨在训练能够与人类偏好对齐的先进奖励模型,以便将大型语言模型与人类偏好对齐。该数据集包含 10,681 个提示 - 响应对。
HelpSteer2 是英伟达开源的 HelpSteer 数据集的后续产品,以后建议使用 HelpSteer2 而不是 HelpSteer。
HelpSteer 包含 21,362 个样本,每个样本包含一个提示、一个响应以及响应的五个人工注释属性,每个属性的范围在 0 到 4 之间,每个属性的值越大表示越好。
{
"prompt": "c#",
"response": "C# is a high-level, object-oriented programming language developed by Microsoft as part of its .NET initiative. It was created as a modern alternative to Java and supports a variety of programming paradigms, including imperative, functional, and event-driven. C# is primarily used for Windows application development, but it can also be used for web, mobile, and game development. The language is designed to be safe, secure, and efficient, and it provides developers with a rich set of libraries and tools for building robust and scalable applications. C# is also widely used in the game development industry, particularly in the development of games for the Xbox 360 and Xbox One consoles.",
"helpfulness": 3,
"correctness": 4,
"coherence": 4,
"complexity": 2,
"verbosity": 1
}
数据合成
- 提示来源:主要基于用户贡献的 ShareGPT 提示词收集,一小部分(~5%)由 Scale AI 人工生成。
- 答案生成:由 10 个不同的开源模型生成,使用采样技术为每个提示生成 2 个来自不同模型的答案,以提供多样化但合理的答案。
- 属性评分:由 Scale AI 完成,标注者根据 Likert 5 值(0 到 4 之间)对每个属性(有用性、正确性、连贯性、复杂性和冗长性)的每条回复进行评分。
HelperSteer 标注方法
-
外包公司:通过 Scale AI(华人创建的数据标注公司)外包标注员,提供了全面的标注指南,定义了每个属性和评级级别的标准及带注释的示例。
-
标注流程:
-
约 1000 名美国人工注释员参与,候选人先接受英语水平评估和入门培训,最后通过包含 35 个样本答案的测试。
-
每个样本由至少三名注释者独立注释,若初始注释者意见不一致(有用性为 2 分或更少),则最多由五名注释者独立注释。
-
最终注释(3.41 名注释者的平均值,四舍五入到最接近的整数)由多名注释者的平均值获得。
-
-
质量保证:Scale AI 进行大量质量保证,每个标注除自动检查外,至少经过两次人工审核;收到标注后,还进行独立质量保证,许多标注被过滤,最终只保留了 20,324 个样本。
自定义数据集配置(LLaMA-Factory)
在 LLaMA-Factory 中,若要使用自定义数据集,需先在 dataset_info.json 文件中添加数据集描述,再通过修改 dataset: 数据集名称 配置来使用。dataset_info.json 位于 LLaMA-Factory 根目录的 data 文件夹下:
LLaMA-Factory\data
dataset_info.json 注册结构
"数据集名称": {
"hf_hub_url": "Hugging Face 的数据仓库地址(若指定,则忽略 script_url 和 file_name)",
"ms_hub_url": "ModelScope 的数据仓库地址(若指定,则忽略 script_url 和 file_name)",
"script_url": "包含数据加载脚本的本地文件夹名称(若指定,则忽略 file_name)",
"file_name": "该目录下数据集文件夹或文件的名称(若上述参数未指定,则此项必填)",
"formatting": "数据集格式(可选,默认:alpaca,可以为 alpaca 或 sharegpt)",
"ranking": "是否为偏好数据集(可选,默认:False)",
"subset": "数据集子集的名称(可选,默认:None)",
"split": "所使用的数据划分(可选,默认:train)",
"folder": "Hugging Face 仓库的文件夹名称(可选,默认:None)",
"num_samples": "该数据集使用的样本数量(可选,默认:None)",
"columns(可选)": {
"prompt": "数据集代表提示词的表头名称(默认:instruction)",
"query": "数据集代表请求的表头名称(默认:input)",
"response": "数据集代表回答的表头名称(默认:output)",
"history": "数据集代表历史对话的表头名称(默认:None)",
"messages": "数据集代表消息列表的表头名称(默认:conversations)",
"system": "数据集代表系统提示的表头名称(默认:None)",
"tools": "数据集代表工具描述的表头名称(默认:None)",
"images": "数据集代表图像输入的表头名称(默认:None)",
"chosen": "数据集代表更优回答的表头名称(默认:None)",
"rejected": "数据集代表更差回答的表头名称(默认:None)",
"kto_tag": "数据集代表 KTO 标签的表头名称(默认:None)"
},
"tags(可选,用于 sharegpt 格式)": {
"role_tag": "消息中代表发送者身份的键名(默认:from)",
"content_tag": "消息中代表文本内容的键名(默认:value)",
"user_tag": "消息中代表用户的 role_tag(默认:human)",
"assistant_tag": "消息中代表助手的 role_tag(默认:gpt)",
"observation_tag": "消息中代表工具返回结果的 role_tag(默认:observation)",
"function_tag": "消息中代表工具调用的 role_tag(默认:function_call)",
"system_tag": "消息中代表系统提示的 role_tag(默认:system,会覆盖 system column)"
}
}自定义数据集注册示例
alpaca 格式
"数据集名称": {
"file_name": "data.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"system": "system",
"history": "history"
}
}
sharegpt 格式
"数据集名称": {
"file_name": "data.json",
"formatting": "sharegpt",
"columns": {
"messages": "conversations",
"system": "system",
"tools": "tools"
}
}数据集注册示例(以 huanhuan_chat 为例)
-
下载数据集下载
huanhuan.json数据集(alpaca 格式):https://www.modelscope.cn/datasets/longgeai3x3/huanhuan-chat/files -
配置
dataset_info.json打开 LLaMA-Factory 根目录下data文件夹中的dataset_info.json,添加如下配置:{ "identity": { "file_name": "identity.json" }, "huanhuan_chat": { "file_name": "huanhuan.json" }, "alpaca_en_demo": { "file_name": "alpaca_en_demo.json" }, "alpaca_zh_demo": { "file_name": "alpaca_zh_demo.json" }, "glaive_toolcall_en_demo": { "file_name": "glaive_toolcall_en_demo.json", "formatting": "sharegpt", "columns": { "messages": "conversations", "tools": "tools" } }, ... } -
使用数据集刷新 WebUI 界面,即可在数据集列表中看到
huanhuan_chat,选择后即可用于微调专属模型。
微调过程
最简单的方式是按照下面 8 步选择一下,其他用默认参数就可以训练。当然,如果没有显卡,或者根据显卡大小,参数可以有一些区别。
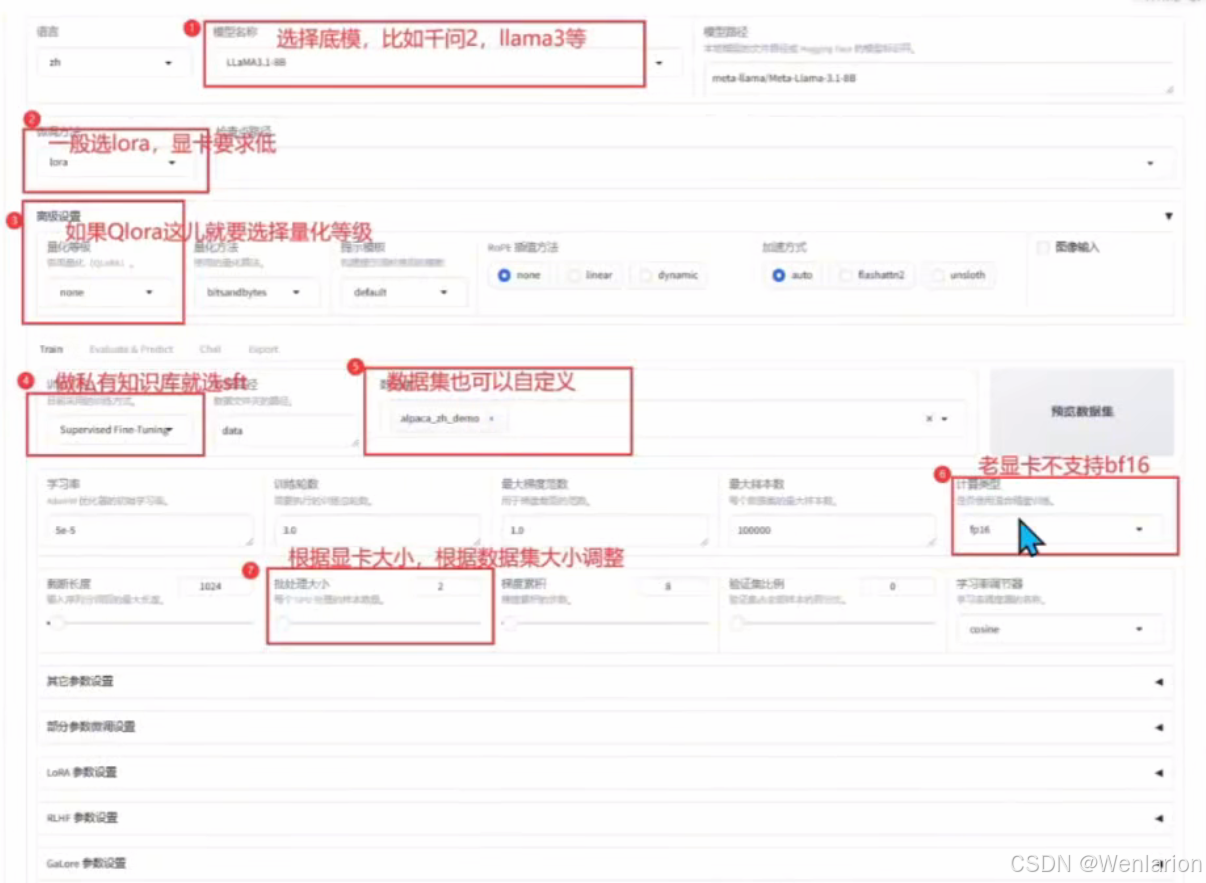
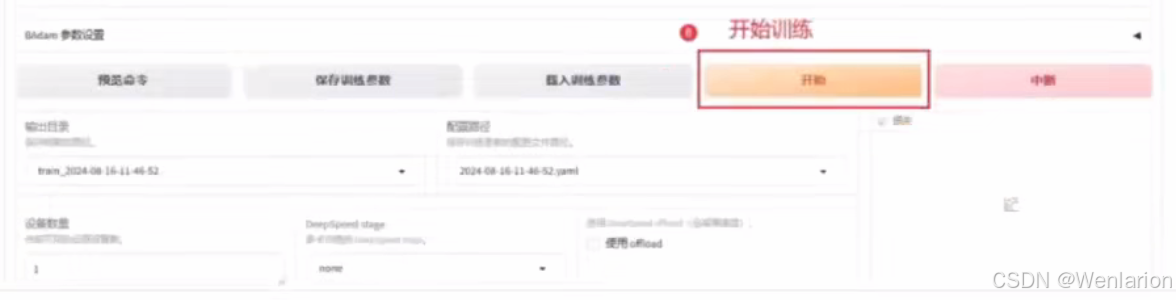
如此点击最下方开始按键后,模型就会很快开始进行模型训练。底部会有日志刷新并可视化loss曲线,直至训练结束。
参数解析(LLaMA-Factory 训练命令)
llamafactory-cli train \
--stage sft \ # 训练阶段:可选 rm (reward modeling), pt (pretrain), sft (Supervised Fine-Tuning), PPO, DPO, KTO, ORPO
--do_train True \ # True 用于训练,False 用于评估
--model_name_or_path /data1/models/Llama3-8B-Chinese-Chat \ # 模型名称或路径
--preprocessing_num_workers 16 \ # 用于数据预处理的工作线程数
--finetuning_type lora \ # 微调方式:可选 freeze, LoRA, full
--template llama3 \ # 数据集模板,需与模型对应
--flash_attn auto \
--dataset_dir /data1/workspaces/llama-factory/data/fiance-neixun \ # 数据集所在目录
--dataset yinlian-sharegpt-neixun \ # 使用的数据集,用 "," 分隔多个数据集
--cutoff_len 1024 \ # 截断长度,输入序列的最大长度
--learning_rate 5e-05 \ # 学习率
--num_train_epochs 3.0 \ # 训练轮数
--max_samples 100000 \ # 用于训练的最大样本数量
--per_device_train_batch_size 2 \ # 每个设备上训练的批次大小
--gradient_accumulation_steps 8 \ # 梯度积累步数
--lr_scheduler_type cosine \ # 学习率调度曲线:可选 linear, cosine, polynomial, constant 等
--max_grad_norm 1.0 \ # 梯度裁剪阈值
--logging_steps 5 \ # 日志输出步数间隔
--save_steps 100 \ # 模型断点保存间隔
--warmup_steps 0 \
--optim adamw_torch \ # 优化器
--packing False \ # 是否启用数据打包
--report_to none \
--output_dir saves/LLaMA3-8B-Chat/lora/train_2024-06-18-09-02-25 \ # 输出路径
--fp16 True \ # 使用 float16 格式;bf16 True 表示使用 bf16 格式
--plot_loss True \ # 是否绘制损失图
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \ # LoRA 的秩,决定低秩矩阵大小
--lora_alpha 16 \ # LoRA 的 alpha 参数,控制权重更新比例
--lora_dropout 0 \ # LoRA 的 dropout 率,防止过拟合
--lora_target all \ # 应用 LoRA 的目标模块,默认 all(全部层)
--deepspeed cache/ds_z3_config.json # 使用 DeepSpeed 加速和优化训练LLaMA-Factory 训练参数说明
| 名称 | 描述 |
|---|---|
model_name_or_path |
模型名称或路径 |
stage |
训练阶段,可选:rm (reward modeling), pt (pretrain), sft (Supervised Fine-Tuning), PPO, DPO, KTO, ORPO |
do_train |
true 用于训练,false 用于评估 |
finetuning_type |
微调方式,可选:freeze, LoRA, full |
lora_target |
采取 LoRA 方法的目标模块,默认值为 all |
dataset |
使用的数据集,使用 , 分隔多个数据集 |
template |
数据集模板,请保证数据集模板与模型相对应 |
output_dir |
输出路径 |
logging_steps |
日志输出步数间隔 |
save_steps |
模型断点保存间隔 |
overwrite_output_dir |
是否允许覆盖输出目录 |
per_device_train_batch_size |
每个设备上训练的批次大小 |
gradient_accumulation_steps |
梯度积累步数 |
learning_rate |
学习率 |
lr_scheduler_type |
学习率曲线,可选 linear, cosine, polynomial, constant 等 |
num_train_epochs |
训练周期数 |
bf16 |
是否使用 bf16 格式 |
基本训练参数
--stage sft:指定训练阶段为 “Supervised Fine-Tuning”(SFT)。--do_train True:表示执行训练过程。--model_name_or_path /data1/models/Llama3-8B-Chinese-Chat:预训练模型的路径。--dataset_dir /data1/workspaces/llama-factory/data/fiance-neixun:数据集所在目录。--dataset yinlian-sharegpt-neixun:数据集的具体名称。
数据处理参数
--preprocessing_num_workers 16:用于数据预处理的工作线程数。--cutoff_len 1024:截断长度,表示输入序列的最大长度。
训练设置参数
--learning_rate 5e-05:学习率,用于控制模型参数的更新幅度。--num_train_epochs 3.0:训练的轮数,即数据集将被循环使用的次数。--max_samples 100000:用于训练的最大样本数量。--per_device_train_batch_size 2:每个设备上的训练批次大小。--gradient_accumulation_steps 8:梯度累积步数,意味着每 8 个批次的梯度将被累积一次。--lr_scheduler_type cosine:学习率调度类型,这里使用余弦退火调度。--max_grad_norm 1.0:最大梯度范数,用于梯度裁剪以防止梯度爆炸。
模型微调参数
--finetuning_type lora:指定微调方法为 LoRA(Low-Rank Adaptation)。--lora_rank 8:LoRA 的秩,决定了低秩矩阵的大小。--lora_alpha 16:LoRA 的 alpha 参数,控制权重更新的比例。--lora_dropout 0:LoRA 的 dropout 率,防止过拟合。--lora_target all:指定 LoRA 应用的层,此处为全部层。
训练优化参数
--optim adamw_torch:优化器类型,此处为 AdamW 优化器。--warmup_steps 0:学习率预热步数。--fp16 True:使用 16 位浮点点数进行训练,加速训练过程并减少显存占用。--flash_attn auto:闪存注意力机制,自动决定是否启用。--deepspeed cache/ds_z3_config.json:使用 DeepSpeed 来加速和优化训练。--ddp_timeout 180000000:分布式数据并行的超时时间。--template llama3:模型模板类型,需与所使用的模型对应。--packing False:是否启用数据打包,将短文本拼接以提高训练效率。--report_to none:训练报告的输出目标,此处为不输出到任何平台。--output_dir saves/LLaMA3-8B-Chat/lora/train_2024-06-18-09-02-25:训练输出目录,用于保存模型权重、日志和配置。--plot_loss True:是否绘制损失图,训练结束后会生成 loss 曲线可视化文件。--logging_steps 5:日志记录的步数间隔,每 5 步输出一次训练状态。--save_steps 100:模型保存的步数间隔,每 100 步保存一次检查点。--include_num_input_tokens_seen True:记录训练过程中已处理的输入 token 数量。
训练过程中,系统会按照logging_steps的参数设置,定时输出训练日志,包含当前loss,训练进度等
训练完后就可以在设置的output_dir下看到如下内容,主要包含3部分
- adapter开头的就是LoRA保存的结果了,后续用于模型推理融合
- training_loss 和trainer_log等记录了训练的过程指标
- 其他是训练当时各种参数的备份
loss在正常情况下会随着训练的时间慢慢变小,最后需要下降到1以下的位置才会有一个比较好的效果,可以作为训练效果的一个中间指标。
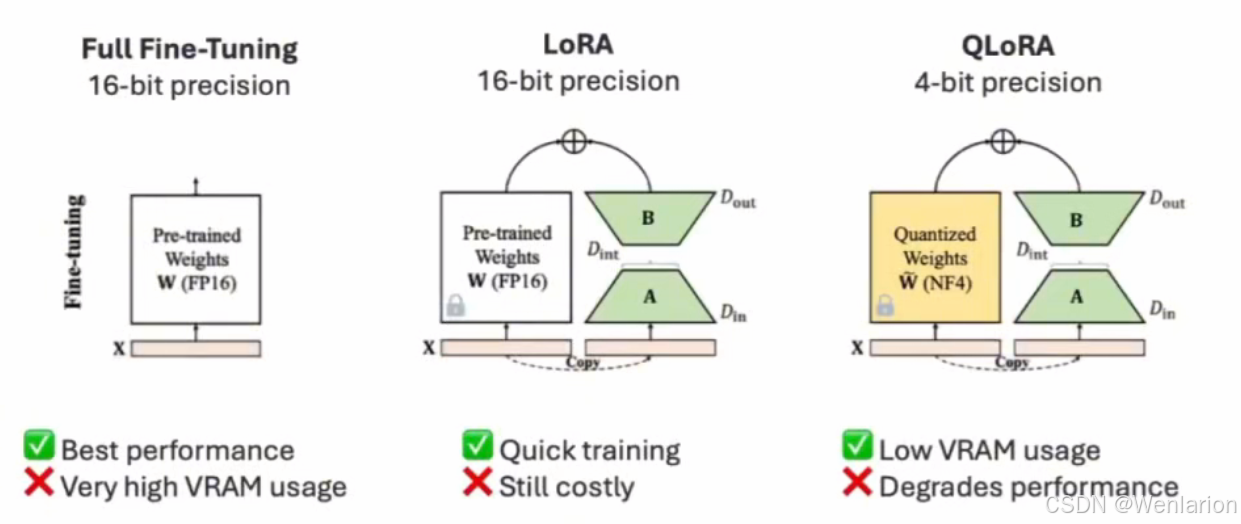
finetuning_type选择
从而减少了内存使用量和训练时间。这种方法是非破坏性的,因为原始参数被冻结,然后可以随意切换或组合适配器。
QLoRA(量化感知低秩自适应)是 LoRA 的扩展,可进一步节省内存。与标准 LoRA 相比,它最多可额外节省 33% 的内存,这在 GPU 内存受限时光其有用。效率的提高是以更长的训练时间为代价的,QLoRA 的训练时间通常比常规 LoRA 多 39%。
指令模板
本项目 Llama-3-Chinese-Instruct 沿用原版 Llama-3-Instruct 的指令模板。以下是一组对话示例:
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
You are a helpful assistant. 你是一个乐于助人的助手。<|eot_id|><|start_header_id|>user<|end_header_id|>
你好<|eot_id|><|start_header_id|>assistant<|end_header_id|>
你好!有什么可以帮助你的吗?<|eot_id|>
batch size 如何设置
在深度学习中,选择合适的 batch size(批次大小)对模型的训练效果、训练时间和资源消耗有重要影响:
小 batch size(如 1-32)
- 模型泛化性好:小的 batch size 往往会产生更多的梯度噪声,这种噪声有助于避免模型陷入局部最优解,从而提高模型的泛化能力。
- 内存占用少:适合在 GPU 显存有限的情况下使用。
- 训练时间长:由于每个 batch 的数据较少,完整训练完一遍数据需要很长的时间,训练效率很低。
- 不稳定的梯度:由于个体的差异性或者异常值的影响,模型的参数变化也会很大,每一层的梯度都具有很高的随机性,梯度波动较大,可能会导致训练过程不稳定,导致模型难以收敛,有可能导致模型欠拟合。
大 batch size(如 128 及以上)
- 训练速度快:由于每个 batch 包含更多的数据,模型的并行计算效率更高,每轮迭代的时间更短。
- 稳定的梯度:梯度更加平滑,模型训练曲线会更加平滑,训练过程更稳定,尤其是对于深层网络,一般来说 batch size 越大,其确定的下降方向越准,引起训练震荡越小。
- 需要更多的内存:大 batch size 需要更大的 GPU 显存,对于资源受限的环境不适用。
- 可能导致泛化性下降:大 batch size 会降低梯度的随机性,可能导致模型更容易过拟合,导致模型泛化能力下降。
如何平衡 batch size 的大小?
batch size 太大或者太小都不好。所以 batch size 的值越大,梯度也就越稳定,而 batch size 越小,梯度具有越高的随机性,但如果 batch size 太大,对于内存的需求就更高,同时也不利于网络跳出局部极小点。所以,我们需要设置一个合适的 batch size 值,在训练速度和内存容量之间寻找到最佳的平衡点。
- 一般在 Batch size 增加的同时,我们需要对所有样本的训练次数(也就是后面要讲的 epoch)增加(以增加训练次数达到更好的效果)这同样会导致耗时增加,因此需要寻找一个合适的 batch size 值,在模型总体效率和内存容量之间做到最好的平衡。
- 由于上述两种因素的矛盾,batch size 增大到某个时候,达到时间上的最优。由于最终收敛精度会陷入不同的局部极值,因此 batch size 增大到某些时候,达到最终收敛精度上的最优。
- 线性调节学习率:有些研究表明,当 batch size 增加时,学习率可以成比例增大,以稳定训练效果。例如,如果 batch size 增加 2 倍,学习率可以相应增加 2 倍。
- 逐步增加:在训练的早期使用较小的 batch size,随着训练的进行,逐渐增大 batch size,这种策略有时能帮助模型更快地收敛。
- 数据集规模:对于非常大的数据集,较大的 batch size 可能更合适,因为它能加快训练速度。
- 任务类型:对于某些任务(如图像分类),较大的 batch size 可能效果更好,而对于其他任务(如语音识别、文本生成),可能需要较小的 batch size 以获得更好的泛化性。
- 使用自适应 batch size 技术:动态调整:有些优化器(如 LAMB)支持自适应调整 batch size,根据训练的不同阶段自动调整,以获得最佳的训练效果。还有比如 batch scaling 等。
- 硬件资源的限制:如果 GPU 显存限制了 batch size,可以考虑梯度累积(Gradient Accumulation)技术,在多次小 batch 的基础上累积梯度,以模拟更大的 batch size。
选择合适的 batch size 是一个需要平衡训练速度、资源使用和模型性能的问题。可以通过实验和验证来找到适合你具体任务的最佳 batch size,通常从一个较小的值开始,然后逐步调整。
微调命令
llamafactory-cli train \
--stage sft \
--do_train True \
--model_name_or_path /data1/models/Llama3-8B-Chinese-Chat \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--template llama3 \
--flash_attn auto \
--dataset_dir /data1/workspaces/llama-factory/data/fiance-neixun \
--dataset yinlian-sharegpt-neixun \
--cutoff_len 1024 \
--learning_rate 5e-05 \
--num_train_epochs 3.0 \
--max_samples 100000 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 8 \
--lr_scheduler_type cosine \
--max_grad_norm 1.0 \
--logging_steps 5 \
--save_steps 100 \
--warmup_steps 0 \
--optim adamw_torch \
--packing False \
--report_to none \
--output_dir saves/LLaMA3-8B-Chat/lora/train_2024-06-18-09-02-25 \
--fp16 True \
--plot_loss True \
--ddp_timeout 180000000 \
--include_num_input_tokens_seen True \
--lora_rank 8 \
--lora_alpha 16 \
--lora_dropout 0 \
--lora_target all \
--deepspeed cache/ds_z3_config.json
也可以将参数安装格式保存为 ymal 文件,然后如下使用,具体格式可以参考根目录下的 examples 文件夹下的例子。
llamafactory-cli train examples/train_lora/llama3_lora_sft.yaml
如果是在 Windows 下,在 cmd 窗口中,把命令中的 \ 和换行删掉,当成一行命名即可:
llamafactory-cli train --stage sft --do_train True --model_name_or_path Qwen/Qwen2-7B-Instruct-AWQ --preprocessing_num_workers 16 --finetuning_type lora --template qwen --flash_attn auto --dataset_dir data --dataset huanhuan_chat --cutoff_len 1024 --learning_rate 5e-05 --num_train_epochs 3.0 --max_samples 100000 --per_device_train_batch_size 2 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --max_grad_norm 1.0 --logging_steps 5 --save_steps 100 --warmup_steps 0 --optim adamw_torch --packing False --report_to none --resume_from_checkpoint F:\sotaAI\LLaMA-Factory\saves\Qwen2-7B-int4-Chat\lora\train_2024-08-17-15-56-58\checkpoint-500 --output_dir saves/Qwen2-7B-int4-Chat/lora/train_2024-08-18-14-43-59 --fp16 True --plot_loss True --ddp_timeout 180000000 --include_num_input_tokens_seen True --quantization_bit 4 --quantization_method bitsandbytes --lora_rank 8 --lora_alpha 16 --lora_dropout 0 --lora_target all
上面命令可以用来基于 qwen2-7b 训练 huanhuan_chat 的 lora。
中断继续训练
经常因为设备故障,或者调整超参数等中断了训练,从头训练则费时费力,则可以从保存的 checkpoint 处继续训练。
中断之后继续训练,可以使用下面命令,训练步数也会从保存的 checkpoint 处开始,比如 checkpoint 保存点是 400 步,但是在 450 步中断,会从 400 步开始继续:
--resume_from_checkpoint /workspace/checkpoint/codellama34b_5k_10epoch/checkpoint-4000
--output_dir new_dir
#--resume_lora_training #这个可以不设置
如果不需要换 output_dir,另外两条命令都不加,脚本会自动寻找最新的 checkpoint:
--output_dir /workspace/checkpoint/codellama34b_5k_10epoch
当然使用命令训练,没有用 webui 看 loss 那么直观,需要加一个命令:
--plot_loss # 添加此参数以生成 loss 图
在训练结束后,loss 图会保存在 --output_dir 指定的目录中。
如果可以通过添加命令,从检查点开始继续训练,但训练集会从头开始训练,适合用新数据集继续训练。
# lora的保存路径在llama-factory根目录下,如saves\Qwen2-7B-int4-Chat\lora\train_2024-07-17-15-56-58\checkpoint-500
--adapter_name_or_path lora_save_patch
也可以在 webui 中指定检查点路径,把路径复制进去。
动态合并 LoRA 的推理
本脚本参数改编自 LLaMA-Factory/examples/inference/llama3_lora_sft.yaml at main · hiyouga/LLaMA-Factory。
当基于 LoRA 的训练进程结束后,如果想做动态验证,在网页端与新模型对话,与步骤 4 的原始模型直接推理相比,唯一的区别是需要通过 finetuning_type 参数告诉系统,我们使用了 LoRA 训练,然后将 LoRA 的模型位置通过 adapter_name_or_path 参数即可。
CUDA_VISIBLE_DEVICES=0 llamafactory-cli webchat \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora
效果如下,可以看到,模型已经在学习新的数据知识,学习了新的身份认知和商品文案生成的格式。作为对比,如果删除 LoRA 相关参数,只使用原始模型重新启动测试,可以看到模型还是按照通用的一种回答。
模型评估
LoRA 动态加载测试
利用 LLaMA-Factory 的 Chat 功能进行实时 LoRA 测试,步骤如下:
-
选择训练时使用的基础模型。
-
选择对应的微调 LoRA 适配器。
-
在 Chat 页面,选择合适的推理数据类型。
-
等待模型加载完成后,输入提示词并提交,即可进行推理测试。
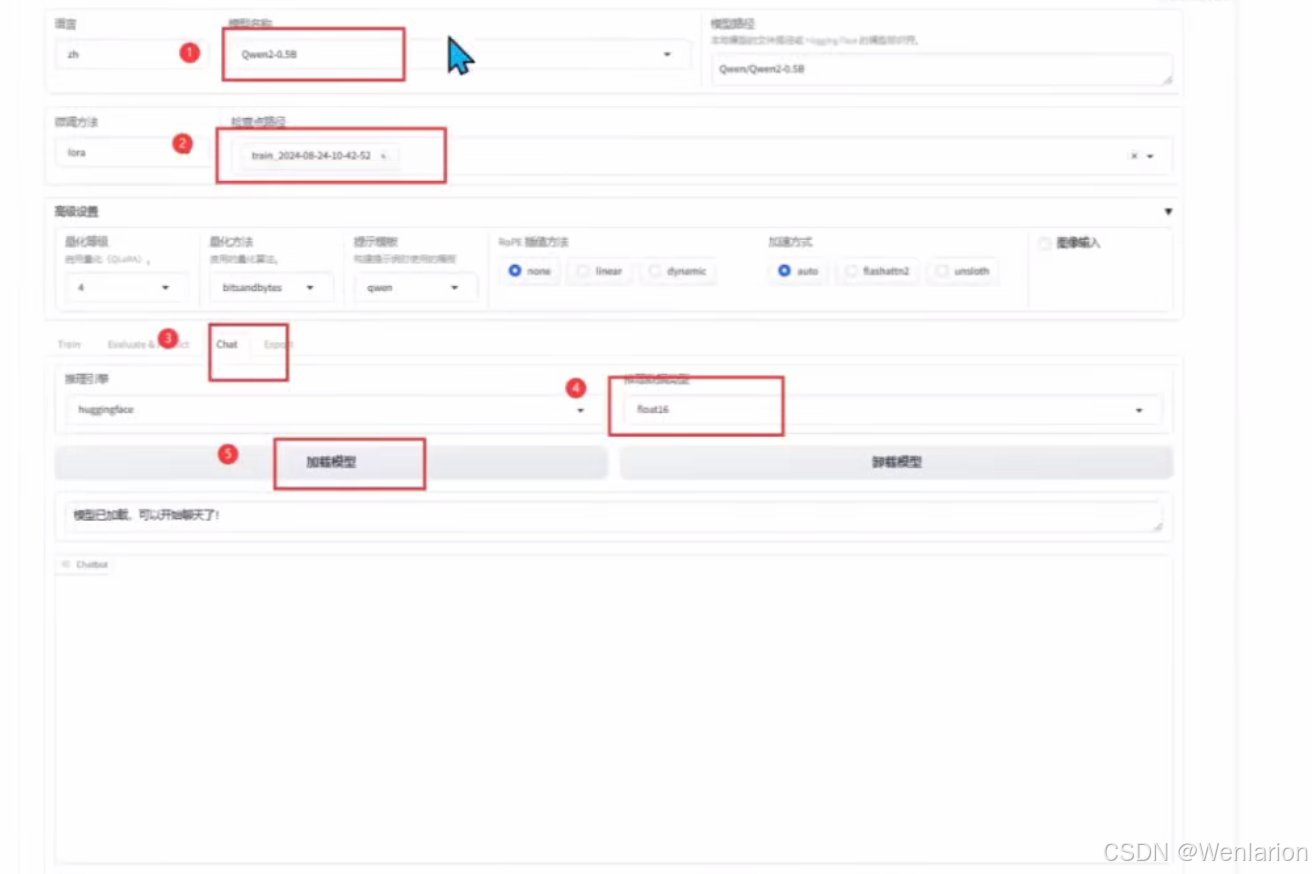

当然上文中的人工交互测试,会偏感性,我们需要用一些自动化评测工具或者批量推理的方法来做效果评估。
0-shot 和 5-shot 评测
0-shot 和 5-shot 评测是评估大型语言模型(LLMs)在没有或有限样本下解决问题能力的方法。
0-shot 评测
0-shot 评测是指在没有任何针对特定任务的训练或示例的情况下,直接评估模型在新任务上的表现。这种方法测试了模型能否利用其预训练期间获得的知识和推理能力来解决新问题。
示例:假设我们有一个预训练的语言模型,我们想评估它在解析法律问题上的能力。在 0-shot 评测中,我们不会提供任何法律问题的例子或训练数据给模型。我们直接给模型一个法律问题,比如:
"What is the difference between a tort and a crime?"
然后,我们评估模型生成的答案是否准确和全面。
5-shot 评测
5-shot 评测提供了一个折中的方法,其中模型在尝试任务之前会看到几个示例。这些示例提供了一些上下文和任务的基本信息,但仍然要求模型展示其泛化能力。
示例:继续使用法律问题的例子,但在 5-shot 评测中,我们会先给模型提供 5 个类似的法律问题和它们的答案,例如:
- "What is the legal definition of theft?"
- "What are the elements of a contract?"
- "Can you explain the concept of due process?"
- "What is the difference between civil law and criminal law?"
- "What rights do defendants have in a criminal trial?"
然后,模型会被要求回答一个新的问题,比如:
"What are the key differences between common law and statutory law?"
在这种情况下,模型已经通过前 5 个问题获得了一些关于法律术语和概念的知识,我们可以评估它是否能够利用这些信息来正确回答问题。
大模型主流评测 benchmark
虽然大部分同学的主流需求是定制一个下游的垂直模型,但是在部分场景下,也可能有同学会使用本项目来做更高要求的模型训练,用于大模型刷榜单等,比如用于评测 mmlu 等任务。当然这类评测同样可以用于评估大模型二次微调之后,对于原来的通用知识的泛化能力是否有所下降。(因为一个好的微调,尽量是在具备垂直领域知识的同时,也保留了原始的通用能力)
在完成模型训练后,您可以通过 llamafactory-cli eval examples/train_lora/llama3_lora_eval.yaml 来评估模型效果。
配置示例文件 examples/train_lora/llama3_lora_eval.yaml 具体如下:
### examples/train_lora/llama3_lora_eval.yaml
### model
model_name_or_path: meta-llama/Meta-Llama-3-8B-Instruct
adapter_name_or_path: saves/llama3-8b/lora/sft # 可选项
### method
finetuning_type: lora
### dataset
task: mmlu_test
template: fewshot
lang: en
n_shot: 5
### output
save_dir: saves/llama3-8b/lora/eval
### eval
batch_size: 4
下面是相关参数的介绍:
| 参数名称 | 类型 | 介绍 |
|---|---|---|
| task | str | 评估任务的名称,可选项有 mmlu_test, ceval_validation, cmmlu_test |
| task_dir | str | 包含评估数据集的文件夹路径,默认值为 evaluation |
| batch_size | int | 每个 GPU 使用的批量大小,默认值为 4 |
| seed | int | 用于数据加载器的随机种子,默认值为 42 |
| lang | str | 评估使用的语言,可选值为 en、zh,默认值为 en |
| n_shot | int | few-shot 的示例数量,默认值为 5 |
| save_dir | str | 保存评估结果的路径,默认值为 None。如果该路径已经存在则会抛出错误 |
| download_mode | str | 评估数据集的下载模式,默认值为 DownloadMode.REUSE_DATASET_IF_EXISTS。如果数据集已存在则重复使用,否则则下载 |
本项目提供了 mmlu、cmmlu、ceval 三个常见数据集的自动评测脚本,按如下方式进行调用即可。
说明:task 目前支持 mmlu_test, ceval_validation, cmmlu_test
本脚本改编自 https://github.com/hiyouga/LLaMA-Factory/blob/main/examples/train_lora/llama3_lora_eval.yaml
如果是 chat 版本的模型:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B-Instruct \
--template llama3 \
--task mmlu_test \
--lang en \
--n_shot 5 \
--batch_size 1
输出如下,具体任务的指标定义请参考 mmlu、cmmlu、ceval 等任务原始的相关资料,和 llama3 的官方报告基本一致。
Average: 63.64
STEM: 50.83
Social Sciences: 76.31
Humanities: 56.63
Other: 73.31
如果是 base 版本的模型,template 改为 fewshot 即可:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli eval \
--model_name_or_path /media/codingma/LLM/llama3/Meta-Llama-3-8B \
--template fewshot \
--task mmlu \
--split validation \
--lang en \
--n_shot 5 \
--batch_size 1
Windows 下,评测命令实例:
llamafactory-cli eval --model_name_or_path Qwen/Qwen2-7B-Instruct-AWQ --adapter_name_or_path F:\sotaAI\LLaMA-Factory\sav拿 huanhuan_chat.json 训练的 LoRA,评测 cmmlu_test 的过程日志如下


Qwen2-7B-Instruct-4bit 底模的 cmmlu_test 评测
llamafactory-cli eval --model_name_or_path Qwen/Qwen2-7B-Instruct-AWQ --template qwen --task cmmlu_test --lang zh --n_shot 3 --batch_size 1
Average: 80.39
STEM: 71.51
Social Sciences: 80.81
Humanities: 85.09
Other: 83.57
总体来说,微调后的模型和底模 cmmlu 中文能力略有下降,但总体差别不大。
大语言模型评估集
常见的有以下几个方向的评测集:
- 知识与语言理解
- 推理能力
- 多轮开放式对话
- 综述抽取与生成能力
- 内容审核和叙事控制
- 编程能力
两个自动化评测项目:
- https://github.com/open-compass/opencompass
- https://github.com/EleutherAI/lm-evaluation-harness/tree/main
支持非常全面的自动化评测任务
行业模型评估
行业模型评估其行业知识能力,最好是根据行业知识和企业私有知识,构建一个评估集,然后评估模型回答的准确率等指标。
批量推理
BLEU (Bilingual Evaluation Understudy) 和 ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是两种在自然语言处理(NLP)领域中广泛使用的评估指标。
BLEU
- BLEU 是一种评估机器翻译质量的指标,它通过计算机器翻译输出与一组参考翻译之间的重叠程度来评分。
- 它主要关注 n-gram 的精确度,即机器翻译输出中的 n-gram(连续的 n 个词,预测后面的词)与参考翻译中的 n-gram 有多少是匹配的。
- BLEU 分数越高,表示机器翻译的质量越接近人类翻译。
- BLEU 也考虑了短句惩罚,以避免机器翻译输出过短而获得不准确的高分数。
ROUGE
- ROUGE 主要用于评估自动文本摘要的质量,它可以评估生成的摘要与一组参考摘要之间的相似度。
- ROUGE 有多个变体,包括 ROUGE-N(评估 n-gram 的重叠)、ROUGE-L(最长公共子序列的重叠)和 ROUGE-S(skip-gram 的重叠)等,注:skip-gram(连续 m 个词,中间空 n 个词)。
- ROUGE 的分数也是越高越好,表示生成的摘要与参考摘要的相似度越高。
这两种指标都是基于召回率(recall)的,即它们更关注机器生成的文本中包含了多少参考文本(也就是标签)信息。
在批量推理的过程中,模型的 BLEU 和 ROUGE 分数会被自动计算并保存,您也可以通过此方法评估模型。
环境准备
使用自动化的 bleu 和 rouge 等常用的文本生成指标来做评估。指标计算会使用如下 3 个库,请先做一下 pip 安装:
pip install jieba # 中文文本分词库
pip install rouge-chinese
pip install nltk # 自然语言处理工具包 (Natural Language Toolkit)参数解释
下面是一个批量推理的命令例子:
CUDA_VISIBLE_DEVICES=0 llamafactory-cli train \
--stage sft \ # 监督微调
--do_predict \ # 现在是预测模式
--model_name_or_path ./llama3/Meta-Llama-3-8B-Instruct \ # 底模路径
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \ # LoRA路径
--eval_dataset alpaca_gpt4_zh,identity,adgen_local \ # 评测数据集
--dataset_dir ./data \ # 数据集路径
--template llama3 \ # 提示词模版,比如llama3、qwen,和训练微调一样
--finetuning_type lora \ # 微调方式 lora
--output_dir ./saves/LLaMA3-8B/lora/predict \ # 评估预测输出文件夹
--overwrite_cache \
--overwrite_output_dir \
--cutoff_len 1024 \ # 提示词截断长度
--preprocessing_num_workers 16 \ # 预处理数据的线程数量
--per_device_eval_batch_size 1 \ # 每个设备评估时的batch size
--max_samples 20 \ # 每个数据集采样多少用于预测对比
--predict_with_generate # 现在用于生成文本
与训练脚本主要的参数区别如下:
| 参数名称 | 参数说明 |
|---|---|
do_predict |
切换为预测模式 |
predict_with_generate |
启用文本生成模式 |
max_samples |
控制每个数据集的采样数量,用于预测对比 |
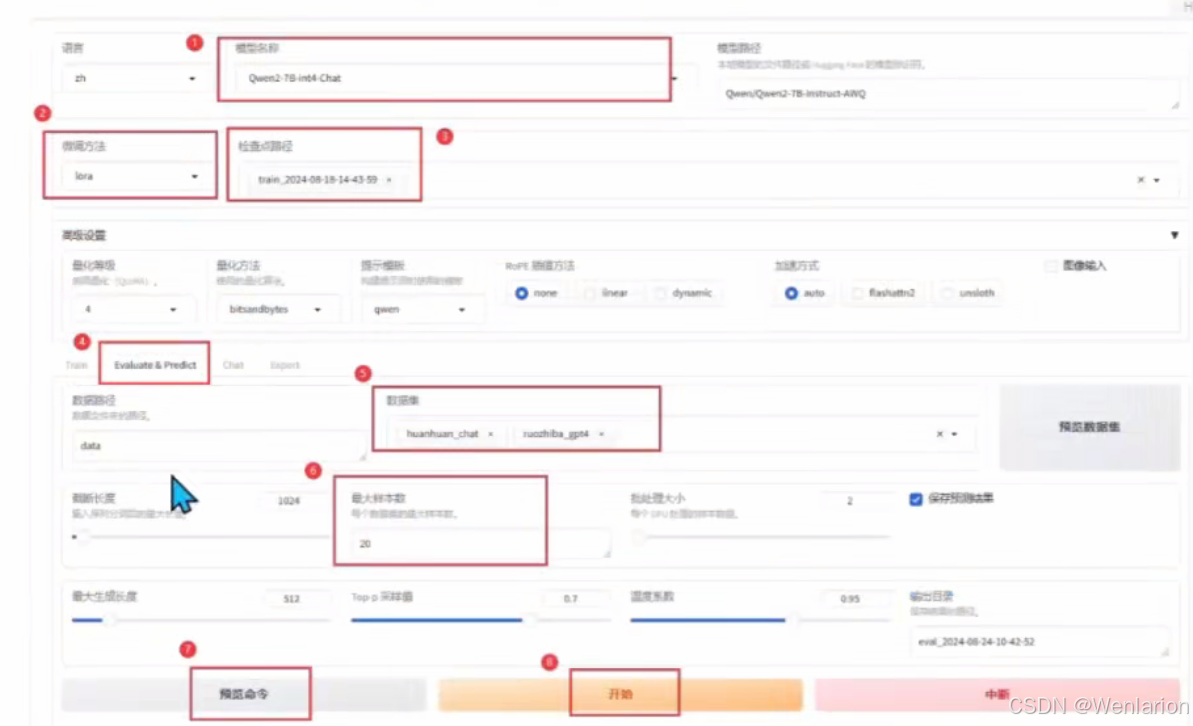
推理示例
选好底模和 LoRA,在 eval 页面,最大样本数酌情调下,因为不需要每个数据集全部推理,数据量太大。
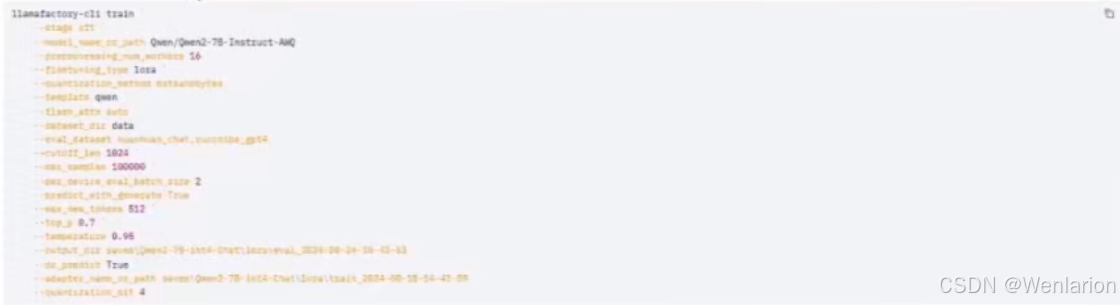
Linux 批量推理命令
llamafactory-cli train \
--stage sft \
--model_name_or_path Qwen/Qwen2-7B-Instruct-AWQ \
--preprocessing_num_workers 16 \
--finetuning_type lora \
--quantization_method bitsandbytes \
--template qwen \
--flash_attn auto \
--dataset_dir data \
--eval_dataset huanhuan_chat,ruozhiba_gpt4 \
--cutoff_len 1024 \
--max_samples 100000 \
--per_device_eval_batch_size 2 \
--predict_with_generate True \
--max_new_tokens 512 \
--top_p 0.7 \
--temperature 0.95 \
--output_dir saves/Qwen2-7B-int4-Chat/lora/eval_2024-08-24-10-42-52 \
--do_predict True \
--adapter_name_or_path saves/Qwen2-7B-int4-Chat/lora/train_2024-08-18-14-43-59 \
--quantization_bit 4Windows 批量推理命令
llamafactory-cli train --stage sft --model_name_or_path Qwen/Qwen2-7B-Instruct-AWQ --preprocessing_num_workers 16 --fin批量推理结果
可以看出 BLEU 和 ROUGE 分数在爆爆的任务评测中并不高,这也说明不同的指标试用任务也不一样。其实像行业模型、角色模型很多时候微调出来都要求一定的泛化性,要求更多的是上下文语义理解能力,像 BLEU 和 ROUGE 这种评估叠词比例的评估,其实效果不明显。
行业模型评估其行业知识能力,最好是根据行业知识和企业私有知识,构建一个评估集,然后评估模型回答的准确率等指标。
{
"predict_bleu-4": 4.4868925,
"predict_model_preparation_time": 0.0229,
"predict_rouge-1": 17.4837975,
"predict_rouge-2": 5.5763774999999995,
"predict_rouge-l": 15.5605625,
"predict_runtime": 35.6997,
"predict_samples_per_second": 1.12,
"predict_steps_per_second": 0.56
}正常这个 output_dir 会是 saves\Qwen2-7B-Int4-Chat\lora\ 目录下,eval_ 开头的文件夹。最后会在 output_dir 下看到如下内容:
| 文件名称 | 说明 |
|---|---|
all_results.json |
就是上面的评估结果内容 |
generated_predictions.jsonl |
保存每一条输入、标签、预测结果;prompt 是输入,原始 label 是给出的结果,predict 是预测的结果 |
llamaboard_config.yaml |
评估的参数配置 |
predict_results.json |
保存的预测结果分数内容 |
trainer_log.jsonl |
训练日志 |
training_args.yaml |
LoRA 的训练参数 |
指标含义解释
|
指标 |
含义 |
|---|---|
| BLEU-4 | BLEU (Bilingual Evaluation Understudy) 是一种常用的用于评估机器翻译质量的指标。BLEU-4 表示四元语法 BLEU 分数,它衡量模型生成文本与参考文本之间的 n-gram 匹配程度,其中 n=4。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_rouge-1 和 predict_rouge-2 | ROUGE (Recall-Oriented Understudy for Gisting Evaluation) 是一种用于评估自动摘要和文本生成模型性能的指标。ROUGE-1 表示一元 ROUGE 分数,ROUGE-2 表示二元 ROUGE 分数,分别衡量模型生成文本与参考文本之间的单个词和双词序列的匹配程度。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_rouge-l | ROUGE-L 衡量模型生成文本与参考文本之间最长公共子序列(Longest Common Subsequence)的匹配程度。值越高表示生成的文本与参考文本越相似,最大值为 100。 |
| predict_runtime | 预测运行时间,表示模型生成一批样本所花费的总时间。单位通常为秒。 |
| predict_samples_per_second | 每秒生成的样本数量,表示模型每秒钟能够生成的样本数量。通常用于评估模型的推理速度。 |
| predict_steps_per_second | 每秒执行的步骤数量,表示模型每秒钟能够执行的步骤数量。对于生成模型,一般指的是每秒钟执行生成操作的次数。 |
模型评估中常见问题解答
1. 模型评估中 OOM?可以设置 --eval_accumulation_steps=1 或者 --per_device_eval_batch_size 1,这样就不会 OOM。
2. LoRA 微调如何自定义评价指标?可以自己修改 llama-factory 根目录下的 src/llamafactory/train/sft/metric.py 和 src/llamafactory/train/sft/workflow.py 文件,例如:
compute_metrics=ComputeMetrics(tokenizer) if training_args.predict_with_generate else None,
支持如 recall、accuracy、precision、F1 等指标。
3. 如何得到各个评测样本单独的 bleu 和 rouge?分开评测即可,一起评测得到的是总分数。
4. 模型对话时不会停止?看下模型的提示词模版,如果对应模型的模版也不行,可以改为 default。
模型部署
LoRA 模型合并导出
核心功能
将训练好的 LoRA 适配器与原始大模型进行融合,输出一个完整的模型文件,方便后续推理或继续训练,避免每次推理时分别加载预训练模型和 LoRA 适配器。
合并导出命令示例
CUDA_VISIBLE_DEVICES=0 llamafactory-cli export \
--model_name_or_path /Llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora \
--export_dir merged-model-path \
--export_size 2 \
--export_device cpu \
--export_legacy_format False
参数说明
| 参数名 | 说明 |
|---|---|
CUDA_VISIBLE_DEVICES=0 |
环境变量,指定程序使用的 GPU 设备编号,这里设置为 0 |
--model_name_or_path |
预训练模型的名称或路径 |
--adapter_name_or_path |
LoRA 适配器的路径,量化导出时可省略 |
--template |
模型模板(如 llama3) |
--finetuning_type |
微调方式(如 lora) |
--export_dir |
合并后模型的导出路径 |
--export_size 2 |
导出每个分片文件的大小(单位:GB),例如一个 8GB 的模型会分成 4 个 2GB 文件 |
--export_device cpu |
导出操作使用的设备(cpu 或 gpu),不影响模型本身的运行设备 |
--export_legacy_format False |
是否使用旧格式导出,新格式默认为 safetensors,旧格式为 pt, bin 等 |
其他可选参数
export_quantization_bit: 量化位数,全精度导出时无需填写export_quantization_dataset: 量化校准数据集export_size: 最大导出模型文件大小,若模型权重较大,会分成多个文件导出export_device: 导出设备export_legacy_format: 是否使用旧格式导出
参考文档
https://llamafactory.readthedocs.io/zh-cn/latest/getting_started/merge_lora.html
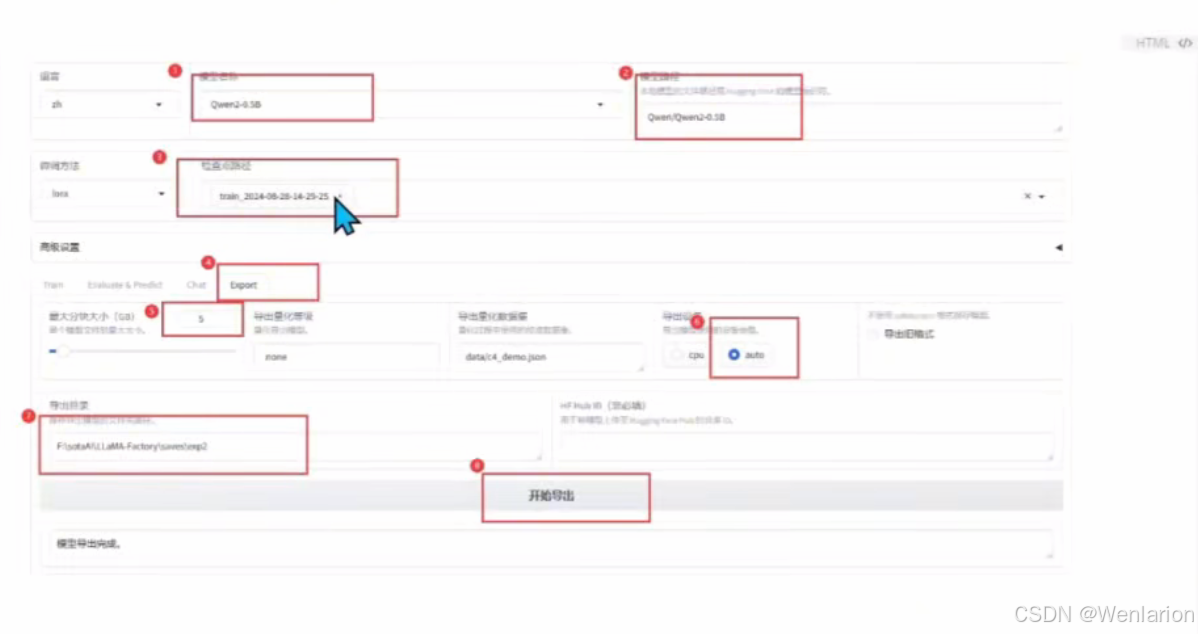
模型导出
核心原则
模型导出必须遵循先全精度、后量化的流程:
-
合并 LoRA 时,只能先导出全精度版本的模型。
-
再基于全精度模型,导出量化版本。
-
合并阶段无法直接导出量化模型。
一、全精度导出
-
模型路径:保持默认,使用训练时选择的原始模型路径。
-
适配器路径:选择训练结束后生成的 LoRA 适配器保存文件。
-
最大分块大小:根据需求设置,用于将大模型拆分为多个文件导出。
-
导出量化等级:必须选择
none,否则无法成功导出全精度模型。 -
导出目录:填写全精度模型的目标导出路径。
-
点击 “开始导出”,完成全精度模型的合并与导出。
二、量化导出
-
模型路径:修改为上一步全精度模型导出文件的路径(路径 2)。
-
适配器路径:取消选择,此时不再需要 LoRA 适配器。
-
导出量化等级:选择需要的量化等级(如 4bit、8bit 等)。
-
导出路径:填写新的量化模型导出目标路径。
-
点击 “开始导出”,完成量化模型的导出。
导出结果
-
导出后的模型文件为
safetensors格式。 -
会生成两个文件夹:
-
上方:全精度模型
-
下方:量化模型
-
导出 GGUF
核心背景
Ollama 框架仅支持 GGUF 格式的模型文件。
LLaMA-Factory 训练输出的是 Safetensors 格式,需要通过 llama.cpp 工具进行格式转换。
GGUF 是 llama.cpp 设计的高效存储格式,可压缩模型体积、降低内存占用,提升推理速度。
后续步骤(可选)
完成环境安装后,即可使用 llama.cpp 提供的脚本,将合并后的 Safetensors 模型转换为 GGUF 格式,用于 Ollama 本地部署。
1. LoRA 模型合并
先完成 LoRA 与原始模型的合并(步骤与前文一致),得到全精度的 Safetensors 模型。
注意:若 Ollama 推理出现无限停止、重复输出或胡言乱语,排查方向如下:
二次训练后,
tokenizer_config.json和special_tokens_map.json可能发生变化。解决方案:删除合并后模型目录下的这两个文件,从 Llama3 原始模型文件中复制并覆盖,再继续后续流程。
2. 安装 GGUF 转换环境(llama.cpp)
不推荐直接 pip install gguf,因为版本不兼容,建议从源码安装 llama.cpp:
# 1. 创建并激活Python 3.10虚拟环境
conda create -n llama_cpp python=3.10
conda activate llama_cpp
# 2. 安装PyTorch(与CUDA版本匹配)
conda install pytorch==2.3.1 torchvision==0.18.1 torchaudio==2.3.1 pytorch-cuda=12.1 -c pytorch -c nvidia
# 3. 拉取llama.cpp源码并安装
git clone https://github.com/ggerganov/llama.cpp.git
cd llama.cpp
pip install --editable .
如有必要,可按照模型训练环境的要求,单独配置
llama.cpp所需的 Python 虚拟环境。
3. 格式转换
在 llama.cpp 项目根目录下,使用官方提供的 convert-hf-to-gguf.py 脚本,将 HuggingFace 格式(如 safetensors)的模型转换为 GGUF 格式:
# 在 llama.cpp 根目录执行
python convert_hf_to_gguf.py F:\sotaAI\LLaMA-Factory\saves\export
- 脚本参数:需要转换的模型路径(即上一步全精度导出的目录)
- 转换成功后,在该路径下会生成对应的 GGUF 文件(如
Qwen2-0.5B-F16.gguf)
Ollama 安装
Ollama 是常用的本地大模型部署工具,仅支持 GGUF 格式,因此需要先完成格式转换。
- 下载地址:https://ollama.com/
- GitHub 地址:https://github.com/ollama/ollama
- 文档参考:https://github.com/ollama/ollama/tree/main/docs
Linux 安装
一般线上 GPU 算力服务器,驱动程序通常已预装。
- AMD GPU:若使用 AMD 显卡,建议从 AMD 官方驱动页面 安装最新版驱动,以获得对 Radeon GPU 的最佳支持。
安装 Ollama
方法一:一键脚本安装(推荐)
curl -fsSL https://ollama.com/install.sh | sh
方法二:手动下载安装
sudo curl -L https://ollama.com/download/ollama-linux-amd64 -o /usr/bin/ollama
sudo chmod +x /usr/bin/ollama
配置为系统服务(推荐)
1. 创建专用用户
sudo useradd -r -s /bin/false -m -d /usr/share/ollama ollama
2. 创建 Systemd 服务文件
在 /etc/systemd/system/ollama.service 中写入以下内容:
[Unit]
Description=Ollama Service
After=network-online.target
[Service]
ExecStart=/usr/bin/ollama serve
User=ollama
Group=ollama
Restart=always
RestartSec=3
[Install]
WantedBy=default.target
3. 启动并启用服务
sudo systemctl daemon-reload
sudo systemctl enable --now ollama
Linux 服务管理
验证安装, 服务启动后,可通过以下命令检查状态:
systemctl status ollama启动 Ollama 服务
sudo systemctl start ollama
移除 Ollama 服务
sudo systemctl stop ollama
sudo systemctl disable ollama
sudo rm /etc/systemd/system/ollama.serviceWindows 安装
核心变化
Ollama 现在已作为 Windows 原生应用程序运行,不再需要 WSL,支持 NVIDIA 和 AMD Radeon GPU。
下载与安装
-
选择 Windows 系统,直接下载安装包并启动安装程序。
默认安装位置
-
程序文件目录:
C:\Users\Administrator\AppData\Local\Programs\Ollama -
日志文件夹:
C:\Users\Administrator\AppData\Local\Ollama -
模型和数据文件夹:
C:\Users\Administrator\.ollama(可通过OLLAMA_MODELS环境变量自定义)
系统要求
-
操作系统:Windows 10 或更新版本(家庭版 / 专业版均可)
-
NVIDIA 显卡:驱动版本需 ≥ 452.39
-
AMD Radeon 显卡:需安装最新版 AMD Radeon 驱动
启动 Ollama
安装 Ollama Windows 预览版后,Ollama 会在后台运行,ollama 命令可在 cmd、PowerShell 或其他终端中使用。
后台命令管理 Ollama
# 启动 Ollama 服务
./ollama serve
# 加载 gemma2 模型的 2B 版本(建议指定版本,避免下载过大模型)
# 若模型未下载,会自动下载到 OLLAMA_MODELS 环境变量指定的目录
./ollama run gemma2:2b
环境变量配置
可通过以下两个环境变量,自定义模型存储目录和 Ollama API 服务地址:
|
环境变量 |
示例值 |
说明 |
|---|---|---|
|
|
|
自定义模型存储目录,默认在 |
|
|
|
自定义 API 服务端口,默认端口为 11434 |
说明
下载好模型(如谷歌 gemma2:2b)后,可直接在命令窗口聊天,但交互体验不如图形化界面直观。
Ollama 命令介绍
一、官方支持模型
-
官方模型列表:https://ollama.com/library
- 常用部署命令:
ollama pull llama3.1 # 下载模型 ollama rm llama3.1 # 删除模型 ollama show llama3.1 # 显示模型信息 ollama list # 列出已下载的模型
二、自定义模型
Ollama 仅支持 GGUF 格式,其他格式需先转换为 GGUF。需创建 Modelfile 定义模型配置,示例如下:
# 使用官方模型
# FROM llama3.1
# 或使用自定义模型(路径需指向 GGUF 文件)
FROM d:/ollama/llama3-huanhuan.gguf
# 可选:温度参数(值越大,输出越随机)
PARAMETER temperature 1
# 可选:系统提示词
SYSTEM """
You are Mario from Super Mario Bros. Answer as Mario, the assistant, only.
"""
注意:Llama3 模型的
Modelfile编写相对简洁;部分其他模型可能需要在Modelfile中自主完成prompt格式注册,否则问答时会出现答非所问的情况。
三、注册模型
注册自定义模型(示例中模型名为 huanhuan):
ollama create huanhuan -f d:/ollama/longgemf
# -f 后接自定义的 Modelfile 路径
四、命令聊天示例
运行已注册的模型进行对话:
ollama run huanhuan实验示例
-
设置模型目录环境变量
OLLAMA_MODELS=F:\sotaAI\ollama-openwebui\llm_models -
longgemfModelfile 文件内容FROM F:\sotaAI\LLaMA-Factory\saves\export\Qwen2-0.5B-F16.gguf -
运行命令注册模型
huanhuanollama create huanhuan -f F:\sotaAI\ollama-openwebui\llm_models\longgemf -
使用
huanhuan进行推理ollama run huanhuan
open-webui 本地模型部署 UI 项目
- 项目简介:开源的本地模型推理 WebUI,后端与 Ollama 兼容,可用于管理模型、文档资料,并提供类似 GPT 的聊天界面。
- 项目地址:https://github.com/open-webui/open-webui
- 启动方式:按项目文档启动服务后,即可在浏览器中访问图形界面,管理和使用本地部署的大模型。
启动openwebUI
启动后的聊天界面
API 调用服务
llama-factory 的 API 服务
训练完成后,可将模型能力封装为可访问的服务,通过 API 调用接入 LangChain 等下游业务。项目自带 API 能力,实现标准参考 OpenAI 接口协议,基于 uvicorn 框架开发。
基础启动命令
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path /llama3/Meta-Llama-3-8B-Instruct \
--adapter_name_or_path ./saves/LLaMA3-8B/lora/sft \
--template llama3 \
--finetuning_type lora
使用 vLLM 加速推理(仅支持 Linux)
若需加速推理,可使用 vLLM 后端,但需先将 LoRA 模型合并(merge),使用合并后的完整模型目录或训练前的原始模型目录。
CUDA_VISIBLE_DEVICES=0 API_PORT=8000 llamafactory-cli api \
--model_name_or_path merged-model-path \
--template llama3 \
--infer_backend vllm \
--vllm_enforce_eager
vLLM 开源地址:https://github.com/vllm-project/vllm
服务访问方式
服务启动后,可按 OpenAI API 协议远程访问,只需将base_url替换为部署机器的 URL 和端口号即可。
import os
from openai import OpenAI
from transformers.utils.versions import require_version
require_version("openai>=1.5.0", "To fix: pip install openai>=1.5.0")
if __name__ == '__main__':
# 自定义端口
port = 8000
client = OpenAI(
api_key="0",
base_url="http://localhost:{}/v1".format(os.environ.get("API_PORT", 8000)),
)
messages = []
messages.append({"role": "user", "content": "hello, where is USA"})
result = client.chat.completions.create(messages=messages, model="test")
print(result.choices[0].message)
Ollama API 服务
启动 Ollama 服务后,即可通过 API 进行推理,API 地址可通过环境变量 OLLAMA_BASE_URL 指定,默认地址为:
http://127.0.0.1:11434
支持的 API 端点
POST /api/generate:文本生成POST /api/chat:聊天对话(支持流式和非流式生成)
详细 API 文档
https://github.com/ollama/ollama/blob/main/docs/api.md
Ollama OpenAI 兼容 API
Ollama 支持 OpenAI 兼容的 API 接口,国内大部分闭源模型也支持该协议。这意味着无需重复开发多套接口,只需在原有模型支持的基础上,更换模型和 API URL 地址,即可无缝切换到 Ollama 模型推理。
from openai import OpenAI
client = OpenAI(
base_url='http://localhost:11434/v1/',
# API key 为必填项,但 Ollama 会忽略其值
api_key='ollama',
)
# 使用 llama3 进行聊天
chat_completion = client.chat.completions.create(
messages=[
{
'role': 'user',
'content': 'Say this is a test',
}
],
model='llama3',
)
print(chat_completion.choices[0].message.content)

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 10
10 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)