Heartbeat 高可用集群完全指南
Heartbeat集群摘要:Heartbeat是Linux高可用集群软件,通过节点间心跳信号监测状态,实现故障自动切换。核心组件包括心跳守护进程、资源管理(haresources/CRM)和配置文件(ha.cf/authkeys)。支持单播/组播通信,配置需定义节点、心跳间隔(keepalive)和死亡判定时间(deadtime)。提供两种资源管理方式:简单的haresources脚本和复杂的CR
想象两个心脏跳动,如果一颗心脏停止了,另一颗立即接管维持生命。这就是 Heartbeat 集群的核心思想——通过心跳信号监测对方状态,确保服务永不停止!
📑 目录
- 什么是 Heartbeat?
- 名词解释(命令与术语)
- Heartbeat 架构与组件
- Heartbeat 配置详解
- 安装与配置
- 基于 CRM 的资源管理
- Heartbeat 状态监控
- 故障排查
- Heartbeat vs Corosync 对比
- 最佳实践
- 总结
- 官方文档与参考
🎯 什么是 Heartbeat?
核心概念
Heartbeat 是 Linux 平台上最早的高可用集群软件之一,通过节点间定期发送"心跳"信号来监测对方状态,当检测到对方故障时自动接管资源。
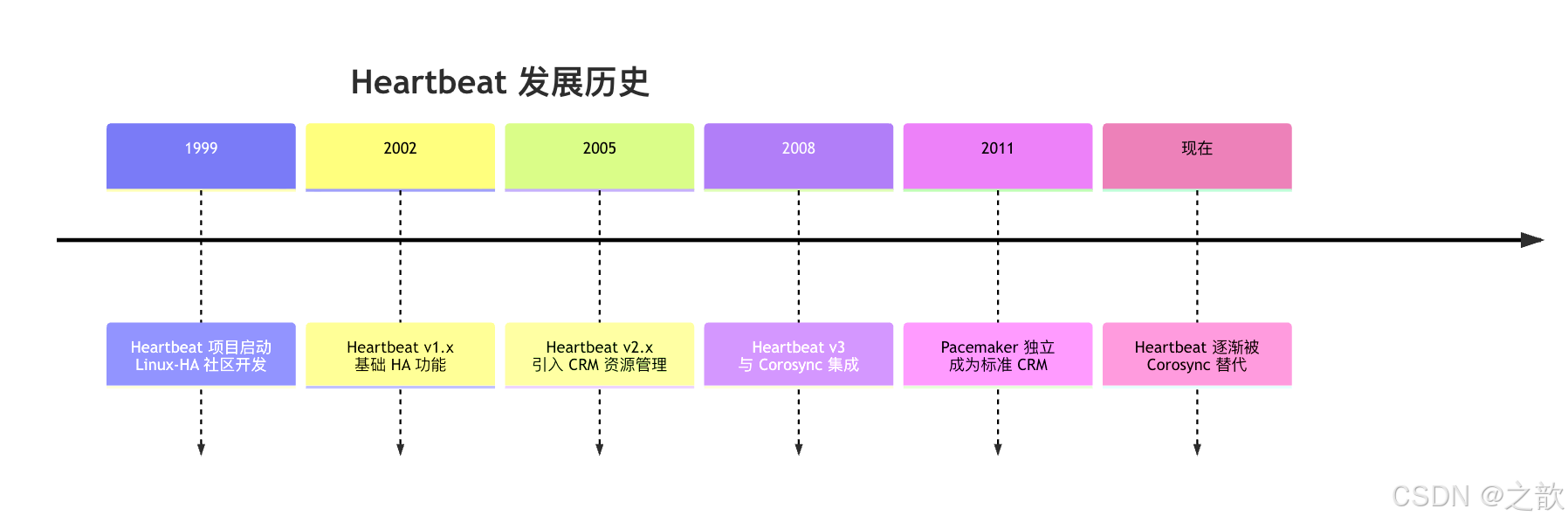
官方/社区定义简述(来源:Linux-HA):Heartbeat 是 Linux-HA 项目中的集群基础设施守护进程,负责在节点间传递心跳、在节点上下线时执行脚本、并通过免费 ARP 实现 IP 接管。支持双节点并可扩展至更多节点;通信方式包括 UDP 广播/组播/单播及串口(串口已不推荐)。v2 起可搭配 CRM(后独立为 Pacemaker)做资源管理。项目最终版本为 3.0.6(2015),新项目推荐使用 Corosync + Pacemaker。
生活类比:
- 心跳信号 = 两个保安对讲机,每隔几秒说"我还在"
- 故障检测 = 长时间没听到对方说话,可能出事了
- 资源接管 = 另一个保安马上接替他的岗位
Heartbeat 的历史
📖 名词解释(命令与术语)
以下对文档中出现的命令、配置文件、概念做简要解释,并配上生活例子与「为什么」,便于记忆与理解。
常用命令
| 命令/名称 | 含义 | 说明 | 生活例子 | 为什么? |
|---|---|---|---|---|
| cl_status | Cluster Status | 查看 Heartbeat 集群当前状态(节点、资源等) | 像「看考勤板」:谁在岗、当前谁在干活 | 为什么常用?快速确认集群是否正常、资源在哪个节点,排障第一步 |
| crm_mon -1 | CRM Monitor,单次输出 | 查看 Pacemaker 集群状态(节点、资源、约束),输出一次后退出 | 像「打印一份当前排班表」 | 为什么用 -1?不加 -1 会持续刷新;-1 适合脚本或一次性查看 |
| crm configure | CRM 配置 | 进入或执行集群配置(show/primitive/group/colocation/order/commit) | 像「改排班表」:加人、编组、规定谁和谁一起 | 为什么改完要 commit?配置在内存中,commit 才真正生效并同步到各节点 |
| crm_resource --move | 迁移资源 | 将指定资源迁移到某节点(常用于测试切换) | 像「临时把某人的岗位调到另一人」 | 为什么测试时用?验证故障切换是否正常,不真关节点也能看到资源迁移 |
| ucast / mcast / serial | 心跳传输方式 | ha.cf 中配置:单播、组播、串口 | 像「单播=单独打电话、组播=群发、串口=专用对讲线」 | 为什么推荐 ucast?单播不依赖交换机组播、跨网段简单,每台填对端 IP 即可 |
配置文件与概念
| 名词 | 含义 | 生活例子 | 为什么? |
|---|---|---|---|
| ha.cf | Heartbeat 主配置文件 | 像「公司考勤与通讯制度」:谁算成员、多久报一次到、多久没报到算缺勤 | 为什么节点要写两边的 hostname?两边都要知道「集群里有哪些人」,才能判断谁掉了 |
| authkeys | 心跳认证密钥 | 像「对暗号」:只有知道密钥的包才认,防伪造心跳 | 为什么必须 chmod 600?密钥泄露别人可伪造心跳把资源抢走,只能 root 读 |
| haresources | 脚本方式资源列表 | 像「任务清单」:主节点负责按顺序启动 VIP、挂盘、MySQL 等 | 为什么只写一个节点名?表示「这份清单默认由该节点执行」,该节点挂了对方接管整份清单 |
| keepalive | 心跳发送间隔(秒) | 像「每隔几秒喊一声我还活着」 | 为什么常用 2 秒?太短网络抖一下就误判;太长故障发现慢,2 秒是经验折中 |
| deadtime | 判定对方死亡的时间(秒) | 像「连续多久没回应就当他出事了」 | 为什么要比 keepalive 大很多?要留出丢包、网络抖动的余量,通常 30 秒左右 |
| auto_failback | 主节点恢复后是否自动切回 | 像「主人回来了,要不要把岗位还给他」 | 为什么生产常关?避免主节点恢复后资源又切回去,造成二次抖动;若主节点更强可开 |
| CRM | Cluster Resource Manager | 像「调度中心」:决定资源在谁上、启停顺序、约束 | 为什么 v2 引入?haresource 只能简单「一份清单」,CRM 能做约束、组、粘性等复杂策略 |
心跳方式对比(为什么选哪种?)
| 方式 | 配置关键字 | 优点 | 缺点 | 为什么选/不选? |
|---|---|---|---|---|
| 单播 ucast | ucast 接口 对端IP | 不依赖组播、跨网段简单 | 每台要对端 IP 不同 | 跨网段、交换机不支持组播时首选 |
| 组播 mcast | mcast 接口 组地址 端口 | 配置一致、多节点方便 | 需交换机支持组播、同网段 | 多节点、同网段且网络可控时可用 |
| 串口 serial | serial 设备 baud | 与网络隔离,防网络分区误判 | 需物理线、已不推荐 | 仅作第二心跳路径时可选,主路径用网络 |
🏗️ Heartbeat 架构与组件
系统架构
核心组件
| 组件 | 说明 | 生活类比 |
|---|---|---|
| heartbeat | 核心守护进程,负责心跳传递 | 通讯系统 |
| haresources | 资源列表文件(脚本方式) | 工作清单 |
| ha.cf | 主配置文件 | 公司规章制度 |
| authkeys | 认证密钥文件 | 门禁卡密码 |
| crm | 集群资源管理器(v2+) | 调度中心 |
| ccm | 集群一致性成员服务 | 人事考勤系统 |
两种资源管理方式
| 特性 | haresource | CRM (Pacemaker) |
|---|---|---|
| 配置方式 | 简单文本文件 | XML + 命令行 |
| 灵活性 | 低 | 高 |
| 复杂度 | 简单 | 复杂 |
| 适用场景 | 简单双机热备 | 复杂多节点集群 |
| 生活类比 | 手写清单 | 智能调度系统 |
⚙️ Heartbeat 配置详解
主配置文件 ha.cf
配置示例:
# /etc/ha.d/ha.cf
# 日志文件位置
logfacility local0
logfile /var/log/ha-log
keepalive 2 # 心跳间隔(秒)
deadtime 30 # 超时时间(秒)
warntime 10 # 警告时间(秒)
initdead 120 # 启动时的超时时间
# 节点定义
node node1.magedu.com
node node2.magedu.com
# 心跳传递方式
# 方式1:串口心跳
serial /dev/ttyS0
baud 115200
# 方式2:多播心跳
mcast eth0 225.0.0.1 694 1 0
# 接口 多播地址 端口 TTL 回环
# 方式3:单播心跳(推荐)
ucast eth0 192.168.1.11
# 接口 对端IP
# 自动故障恢复
auto_failback on # 主节点恢复后自动切回
auto_failback off # 主节点恢复后不切回(推荐)
# 资源管理方式
# 使用 haresource(旧方式)
#use_logd yes # 使用 logd 守护进程
# 使用 CRM(新方式)
crm respawn # 使用 Pacemaker
配置参数详解
| 参数 | 说明 | 推荐值 | 生活类比 |
|---|---|---|---|
| keepalive | 心跳发送间隔 | 2秒 | 每几秒说一次"我还活着" |
| deadtime | 判定死亡的时间 | 30秒 | 多久没反应认为挂了 |
| warntime | 发出警告的时间 | 10秒 | 开始担心的时间点 |
| initdead | 启动时的超时时间 | 120秒 | 刚开机时多等一会 |
| auto_failback | 自动切回 | on/off | 主人回来了让不让位 |
心跳间隔选择原则:
- 太短:网络抖动就误判故障
- 太长:故障发现延迟太长
- 推荐:2秒心跳,30秒超时
为什么 deadtime 要远大于 keepalive? 例如 keepalive=2、deadtime=30 表示「每 2 秒发一次,连续 30 秒收不到才判死」。中间可以丢多包或短暂断网而不误判;若 deadtime 只比 keepalive 大一点,一次丢包就可能触发故障转移。
认证配置 authkeys
# /etc/ha.d/authkeys
# 文件权限必须是 600 (root only)
auth 1
1 sha1 my-secret-key-here
# 或使用 md5
auth 2
2 md5 another-secret-key
设置正确权限:
chmod 600 /etc/ha.d/authkeys
ls -l /etc/ha.d/authkeys
# -rw------- 1 root root ...
资源配置 haresource
# /etc/ha.d/haresources
# 格式:节点名 资源1 资源2 资源3...
# 示例1:简单 VIP + Apache
node1.magedu.com 192.168.1.100/24/eth0 httpd
# 示例2:VIP + Filesystem + MySQL
node1.magedu.com \
192.168.1.100/24/eth0 \
Filesystem::/dev/sdb1::/data::ext4 \
mysqld
# 示例3:指定资源启动脚本
node1.magedu.com \
IPaddr::192.168.1.100/24/eth0 \
httpd
资源配置语法:
| 资源类型 | 语法 | 说明 |
|---|---|---|
| IPaddr | IPaddr::IP/NETMASK/INTERFACE |
VIP 地址 |
| Filesystem | Filesystem::DEVICE::MOUNTPOINT::FSTYPE |
文件系统挂载 |
| 服务 | 直接写服务名 | 系统服务脚本 |
生活类比:
- haresources = 任务清单,按顺序执行
- 优先级 = 清单上的顺序,先来后到
- 节点指定 = 指定谁负责这份清单
🚀 Heartbeat 安装与配置
环境准备
准备工作:
# 1. 配置主机名(两台都执行)
hostnamectl set-hostname node1.magedu.com # 节点1
hostnamectl set-hostname node2.magedu.com # 节点2
# 2. 配置 hosts 文件(两台都执行)
cat >> /etc/hosts << EOF
192.168.1.10 node1.magedu.com node1
192.168.1.11 node2.magedu.com node2
EOF
# 3. 时间同步(两台都执行)
yum install ntpdate -y
ntpdate time.nist.gov
# 4. 测试连通性(节点1执行)
ping -c 3 node2
ssh node2 hostname
安装 Heartbeat
# 1. 安装 EPEL 源(两台都执行)
yum install epel-release -y
# 2. 安装 Heartbeat(两台都执行)
yum install heartbeat -y
# 3. 创建配置目录(两台都执行)
mkdir -p /etc/ha.d
cd /etc/ha.d
配置示例(简单双机热备)
# /etc/ha.d/ha.cf(两台都相同配置)
cat > /etc/ha.d/ha.cf << 'EOF'
# 日志配置
logfacility local0
logfile /var/log/ha-log
debugfile /var/log/ha-debug
# 时间配置
keepalive 2
deadtime 30
warntime 10
initdead 120
# 节点配置
node node1.magedu.com
node node2.magedu.com
# 单播心跳
ucast eth0 192.168.1.11 # 节点1填写对端IP
# ucast eth0 192.168.1.10 # 节点2填写对端IP
# 自动故障恢复
auto_failback off
# 使用 Pacemaker
crm respawn
EOF
# 节点2修改 ucast 为对端IP
sed -i 's/192.168.1.11/192.168.1.10/' /etc/ha.d/ha.cf
认证配置
# /etc/ha.d/authkeys(两台都相同配置)
cat > /etc/ha.d/authkeys << 'EOF'
auth 1
1 sha1 heartbeat-key-2025
EOF
# 设置权限(重要!)
chmod 600 /etc/ha.d/authkeys
chown root:root /etc/ha.d/authkeys
配置资源文件
# /etc/ha.d/haresources(两台都相同配置)
cat > /etc/ha.d/haresources << 'EOF'
# VIP + Apache 示例
node1.magedu.com IPaddr::192.168.1.100/24/eth0 httpd
EOF
# 或者使用更复杂的配置
cat > /etc/ha.d/haresources << 'EOF'
# VIP + 文件系统 + MySQL
node1.magedu.com \
IPaddr::192.168.1.100/24/eth0 \
Filesystem::/dev/drbd0::/data::ext4 \
mysqld
EOF
启动 Heartbeat
# 1. 配置防火墙(两台都执行)
firewall-cmd --permanent --add-port=694/udp
firewall-cmd --reload
# 或者使用 iptables
iptables -I INPUT -p udp --dport 694 -j ACCEPT
service iptables save
# 2. 启动服务(两台都执行)
systemctl enable heartbeat
systemctl start heartbeat
# 3. 查看状态
cl_status
为什么心跳用 UDP 694 端口? Heartbeat 约定默认使用 UDP 694,便于防火墙统一放行;心跳包小、无需可靠传输,UDP 足够,且 694 为 IANA 分配给 Linux-HA 的端口。
🔄 基于 CRM 的资源管理
CRM 配置方式
常用 CRM 命令
# 查看集群状态
crm_mon -1
# 配置模式(进入配置界面)
crm configure show
# 添加资源
crm configure primitive vip ocf:heartbeat:IPaddr2 \
params ip=192.168.1.100 cidr_netmask=24
# 添加资源组
crm configure group webgroup vip apache
# 添加约束
crm configure colocation apache_with_vip apache: vip INFINITY
crm configure order start_vip_before_apache vip:start apache:start
# 提交配置
crm configure commit
# 清理资源
crm resource cleanup
配置示例(MySQL HA)
# 1. 配置 DRBD 资源
crm configure primitive drbd_mysql ocf:linbit:drbd \
params drbd_resource=mysql \
op monitor interval=15s role=Master \
op monitor interval=30s role=Slave
# 2. 配置主从资源
crm configure ms ms_drbd_mysql drbd_mysql \
meta master-max=1 master-node-max=1 clone-max=2 clone-node-max=1
# 3. 配置文件系统
crm configure primitive fs_mysql ocf:heartbeat:Filesystem \
params device="/dev/drbd0" directory="/data" fstype="ext4" \
op monitor interval=20s
# 4. 配置 VIP
crm configure primitive vip_mysql ocf:heartbeat:IPaddr2 \
params ip=192.168.1.100 cidr_netmask=24 \
op monitor interval=10s
# 5. 配置 MySQL
crm configure primitive mysql systemd:mysqld \
op monitor interval=20s timeout=30s
# 6. 配置资源组
crm configure group mysql_group vip_mysql fs_mysql mysql
# 7. 配置约束
crm configure colocation mysql_on_drbd \
mysql_group ms_drbd_mysql INFINITY
crm configure order mysql_after_drbd \
ms_drbd_mysql:start mysql_group:start
📊 Heartbeat 状态监控
查看集群状态
# 1. 查看 Heartbeat 状态
cl_status
# 输出示例:
# Cluster name: mycluster
# Cluster ID: 1234
# Nodes: node1.magedu.com node2.magedu.com
# Resources:
# IPaddr::192.168.1.100/24/eth0
# httpd
# 2. 查看详细状态
crm_mon -1
# 3. 查看资源状态
crm_resource --list
# 4. 查看节点状态
crm_node --list
日志查看
# 主日志
tail -f /var/log/ha-log
# 调试日志
tail -f /var/log/ha-debug
# 系统日志
journalctl -u heartbeat -f
# 查看最近的错误
grep -i error /var/log/ha-log | tail -20
⚠️ 故障排查
常见问题
1. 节点无法检测到对方
现象:两个节点都认为自己是主节点
解决步骤:
# 1. 检查网络连通性
ping -c 3 node2
# 2. 检查端口监听
netstat -tulnp | grep 694
# 3. 检查防火墙
iptables -L -n | grep 694
# 4. 抓包分析
tcpdump -i eth0 udp port 694
2. 资源无法启动
现象:资源一直处于 Starting 状态
# 1. 手动测试资源脚本
/etc/init.d/httpd start
# 2. 查看资源日志
grep -i httpd /var/log/ha-log
# 3. 清理资源状态
crm_resource -C -r httpd
# 4. 查看详细错误
crm_resource --fail -r httpd -H node1
3. 频繁切换
现象:资源在两个节点间反复切换
解决方案:
# 1. 调整超时参数
# ha.cf
keepalive 5 # 增加心跳间隔
deadtime 60 # 增加超时时间
# 2. 调整监控间隔
crm_resource meta httpd set failure-timeout 60s
# 3. 关闭 auto_failback
auto_failback off
🔄 Heartbeat vs Corosync 对比
功能对比
| 特性 | Heartbeat | Corosync |
|---|---|---|
| 复杂度 | 简单 | 复杂 |
| 功能 | 基础 HA | 丰富的集群功能 |
| 性能 | 中等 | 高性能 |
| 扩展性 | 适合双节点 | 支持多节点 |
| 维护状态 | 基本停止 | 活跃开发 |
| 官方支持 | RHEL 6 之前 | RHEL 7 及之后 |
| 生活类比 | 老式座机 | 现代智能手机 |
迁移建议
💡 最佳实践
配置建议
- 多心跳路径:网络 + 串口(或双网卡)
为什么? 单一路径故障(如网卡或交换机挂)会被误判为对方节点挂,触发不必要切换;多路径下只有「所有路径都不通」才判死,减少误判。生活例子:不只靠微信报平安,还有电话线备用。 - 合理的超时设置:避免误判故障
为什么? deadtime 太小网络一抖就切换;太大则真故障时恢复慢。生活例子:迟到 5 分钟算缺勤太严,迟到 2 小时才算又太松。 - 资源粘性:防止资源频繁迁移
为什么? 无粘性时集群可能因小波动把资源在两边来回迁,导致服务抖动。生活例子:给「当前节点」加点「留恋分」,不轻易搬家。 - 定期测试:故障切换演练
为什么? 不演练的话真故障时不知道脚本、顺序、网络是否都正常。生活例子:消防演练。 - 监控告警:及时发现问题
为什么? 心跳断、资源迁移、节点状态变化都应有告警,便于运维介入。生活例子:考勤异常要提醒主管。
生产环境检查清单
# 1. 确认时间同步
ntpdate pool.ntp.org
# 2. 确认主机名解析
getent hosts node1
getent hosts node2
# 3. 确认 SSH 免密登录
ssh node2 hostname
# 4. 确认防火墙规则
iptables -L -n | grep 694
# 5. 确认资源脚本可执行
ls -l /etc/init.d/httpd
# 6. 测试资源切换
crm_resource --move --node node2 httpd
# 7. 查看集群状态
crm_mon -1
🎯 总结
Heartbeat 是 Linux HA 的开山鼻祖,虽然逐渐被 Corosync 替代,但仍然在许多老系统中服役。
核心要点记忆口诀:
- Heartbeat 传心跳,超时判生死
- haresource 简单,CRM 强大
- auto_failback 慎用,来回切换伤不起
- 多心跳路径好,网络故障不误判
- Corosync 趋势,新项目用它好
生活类比总结:
- 心跳信号 = 对讲机定期报平安
- deadtime = 多久没联系就报警
- auto_failback = 主人回来让不让位
- 资源粘性 = 习惯了现在的岗位
最后提醒:如果是新项目,建议直接使用 Corosync + Pacemaker!Heartbeat 已经过时,官方支持逐渐减少。
📚 官方文档与参考
| 资源 | 链接/说明 | 用途 |
|---|---|---|
| Linux-HA 官网 | linux-ha.org | 项目首页、文档入口 |
| Getting Started | Getting Started with Linux-HA (heartbeat) | 入门与基础配置 |
| Heartbeat 与 Corosync | 见本仓库 Corosync + Pacemaker 指南、HA 高可用集群指南 | 了解替代方案与 CRM 概念 |
相近方案速览(Heartbeat 在其中的位置)
| 方案 | 说明 | 与 Heartbeat 的关系 |
|---|---|---|
| Heartbeat | 早期 Linux-HA 心跳与资源脚本 | 本文主角;维护趋停,多用于老环境 |
| Corosync | 替代 Heartbeat 的心跳/成员层,与 Pacemaker 配套 | RHEL 7+ 及新项目推荐,概念类似、功能更强 |
| Pacemaker | CRM,可与 Heartbeat 或 Corosync 搭配 | Heartbeat v2+ 通过 crm respawn 启动 Pacemaker 做资源管理 |
| Keepalived | 基于 VRRP,主做 VIP 漂移与轻量 HA | 不做通用资源管理,只做「谁当主」;与 Heartbeat 定位不同 |

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献34条内容
已为社区贡献34条内容

所有评论(0)