用sklearn库实现URL恶意性检测特征提取与分类
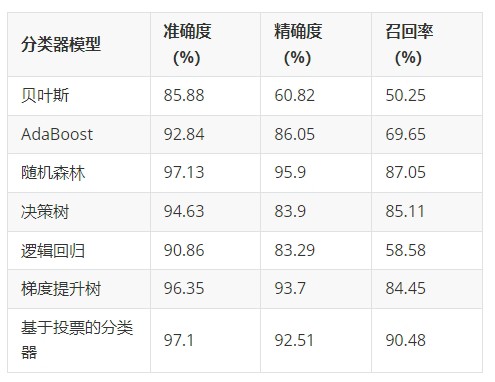
DL00488-URL恶意性检测特征提取sklearn库的机器学习模型进行分类URL异常检测本质上是一个分类问题,将输入的URL经过处理后得到特征,输入到分类其中,分类器输出分类结果,恶意的还是良性的。在训练集和验证集的基础上训练了多个分类模型,训练集用于训练、验证集用来调整参数。从malwaredomains.com等恶意域数据集收集了26251条恶意域URL,用来提取出现频率较高的恶意词,作为
DL00488-URL恶意性检测特征提取sklearn库的机器学习模型进行分类 URL异常检测本质上是一个分类问题,将输入的URL经过处理后得到特征,输入到分类其中,分类器输出分类结果,恶意的还是良性的。 在训练集和验证集的基础上训练了多个分类模型,训练集用于训练、验证集用来调整参数。 从malwaredomains.com等恶意域数据集收集了26251条恶意域URL,用来提取出现频率较高的恶意词,作为后续的数据特征。 从Alexa获取了世界排名前500的网站,提取出现过的网站名称,用来统计数据集中的URL出现流行网站名次数。
在网络安全领域,URL异常检测至关重要,它本质上是个分类问题,要把输入URL处理成特征,喂给分类器,得出恶意或良性的结果。今天咱就聊聊用sklearn库的机器学习模型来进行URL恶意性检测特征提取与分类(DL00488这个代号,就像给这个任务贴了个独特标签)。
数据收集与特征提取
- 恶意域URL收集与恶意词提取
从malwaredomains.com等恶意域数据集收集到26251条恶意域URL。目的是提取高频恶意词作为数据特征。这里我们可以用Python的collections.Counter来统计词频。假设我们已经将URL数据读取到malicious_urls列表中:
from collections import Counter
import re
malicious_word_counter = Counter()
for url in malicious_urls:
# 简单的按非字母数字字符分割URL
words = re.split(r'\W+', url)
malicious_word_counter.update(words)
# 获取出现频率较高的恶意词
high_freq_malicious_words = [word for word, count in malicious_word_counter.most_common(100)]这里先按非字母数字字符分割URL,再用Counter统计每个词出现的次数,最后取前100个高频词作为恶意特征词。
- 流行网站名统计
从Alexa获取世界排名前500的网站,提取网站名称,统计数据集中URL出现流行网站名的次数。同样假设我们已经获取到流行网站名列表popularsitenames和所有URL列表all_urls。
popular_site_count = []
for url in all_urls:
count = 0
for site_name in popular_site_names:
if site_name in url:
count += 1
popular_site_count.append(count)这段代码遍历每个URL,看其中包含多少个流行网站名,把这个次数记录下来,这也是一个重要的特征。
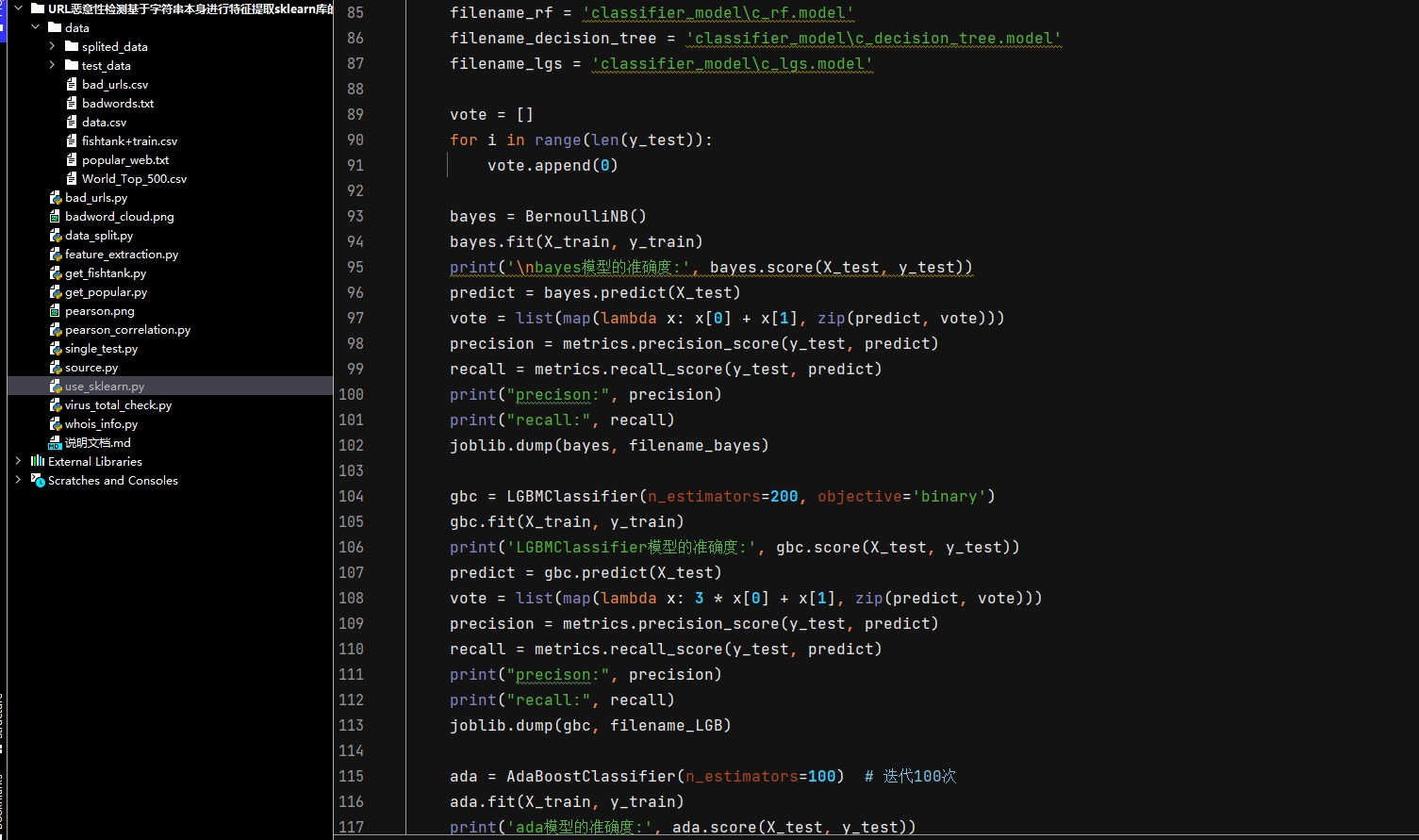
模型训练
在收集好数据和提取特征后,我们有训练集和验证集。训练集用来训练模型,验证集调整参数。下面以简单的逻辑回归模型为例,用sklearn库实现。
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# 假设我们已经将特征处理成X矩阵,标签(恶意或良性)处理成y向量
X_train, X_val, y_train, y_val = train_test_split(X, y, test_size=0.2, random_state=42)
model = LogisticRegression()
model.fit(X_train, y_train)
y_pred = model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
print(f"验证集上的准确率: {accuracy}")这里先用traintestsplit把数据分成训练集和验证集,比例是80%训练,20%验证。然后初始化逻辑回归模型并在训练集上训练,最后在验证集上预测并计算准确率。通过在验证集上的表现,我们可以调整逻辑回归模型的参数,比如正则化参数等,来提高模型性能。
DL00488-URL恶意性检测特征提取sklearn库的机器学习模型进行分类 URL异常检测本质上是一个分类问题,将输入的URL经过处理后得到特征,输入到分类其中,分类器输出分类结果,恶意的还是良性的。 在训练集和验证集的基础上训练了多个分类模型,训练集用于训练、验证集用来调整参数。 从malwaredomains.com等恶意域数据集收集了26251条恶意域URL,用来提取出现频率较高的恶意词,作为后续的数据特征。 从Alexa获取了世界排名前500的网站,提取出现过的网站名称,用来统计数据集中的URL出现流行网站名次数。
通过上述步骤,我们就初步实现了利用sklearn库,基于收集的数据和提取的特征,训练分类模型来检测URL的恶意性。当然,实际应用中还可以尝试更多不同的机器学习模型和更复杂的特征工程方法,来提升检测的准确性和可靠性。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 0
0 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)