谁给了 AI “上帝模式”?4万个 Agent Skills 背后的疯狂、泡沫与隐患
论文标题:Agent Skills: A Data-Driven Analysis of Claude Skills for Extending Large Language Model Functionality
核心看点:生态泡沫、供需错位、上下文税、上帝模式风险
论文链接:https://arxiv.org/pdf/2602.08004
想象这样一个场景:你给你的 AI 助手安装了一个名为“超级管家”的插件,期待它能帮你自动订票、理财、回复邮件。你以为你只是在一个聊天窗口里增加了一个功能,但实际上,你可能刚刚亲手把系统的 Root 权限、SSH 密钥甚至加密货币钱包的控制权,交给了一段由陌生人编写、从未经过严格安全审计的代码。
这并非危言耸听。随着 Agent Skills(智能体技能)生态的爆发,大语言模型(LLM)正在从“只会说话的聊天机器人”进化为能通过工具(Tools)和 API 操作现实世界的“智能体”。
然而,这个新生的生态系统究竟是繁荣的乌托邦,还是充满隐患的“狂野西部”?
在一篇最新的论文《Agent Skills: A Data-Driven Analysis of Claude Skills》中,研究人员对市面上 40,285 个公开的 Agent Skills 进行了大规模的数据驱动分析。结果令人咋舌:9% 的技能拥有“上帝模式”般的高危权限,近一半的技能是重复的“僵尸代码”,而开发者狂热开发的工具与用户真正想要的功能之间,存在着巨大的鸿沟。
本文将剥开 Agent Skills 繁荣表象下的真实数据,带你深入理解这一新兴基础设施的现状与危机。
01. 什么是 Agent Skills?给 AI 装上“机械臂”
在深入数据之前,我们需要先理解什么是 Agent Skill。
对于计算机专业的学生来说,你可以这样理解:如果 LLM 是操作系统(OS),那么 Agent Skill 就是应用程序(App)。在没有 Skill 之前,AI 只能生成文本;有了 Skill,AI 就能执行特定的程序逻辑、调用外部工具或 API。
论文指出,一个标准的 Agent Skill 通常包含三个核心部分,形成了一个模块化的“黑盒子”:
- 元数据 (Metadata):类似于 API 的签名(Signature),定义技能的名称和描述,用于 AI 在海量技能中进行语义检索(Discovery)。
- 指令逻辑 (Instructions):一段类似程序的 Prompt,告诉 AI 如何一步步执行任务(例如:“先搜索产品,再对比价格,最后生成报告”)。
- 资源 (Resources):关联的脚本、API 配置或文件。
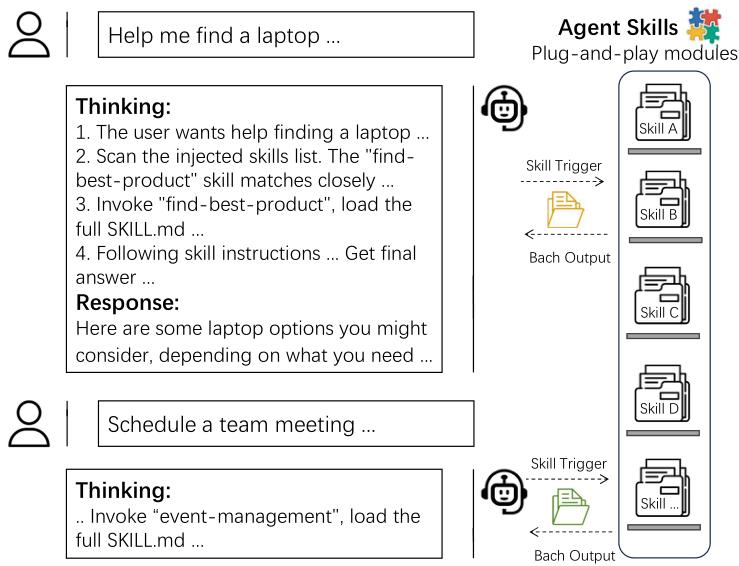
图 1:典型 Agent Skill 的内部结构。AI 首先通过元数据匹配用户意图(如“找笔记本电脑”),然后加载对应的 Markdown 指令,最后按步骤调用外部工具。这种设计让 AI 的能力可以像乐高积木一样无限扩展。
这种**模块化设计(Modular Design)**本意是为了让 AI 的能力标准化。但当这种扩展失去控制时,问题就出现了。为了搞清楚这个生态的真实面貌,研究团队爬取了 skills.sh(一个主要的 Claude Skills 公开市场)截止 2026 年 2 月 5 日的全量数据,并使用 Qwen2.5-32B-Instruct 模型配合 tiktoken 工具,对这 4 万个技能进行了“AI 审计 AI”式的深度体检。
02. 疯狂的泡沫:脉冲式增长与“复制粘贴”
Agent Skills 的增长速度是惊人的,但这种增长是健康的吗?
脉冲式增长 (Bursty Growth)
数据显示,技能数量在短短 20 天内增长了 18.5 倍(从 2,179 激增至 40,285)。但这种增长并非线性,而是呈现出极强的“脉冲性”。最夸张的一天(1月25日),单日新增了 8,857 个技能。研究发现,这一增长曲线与 GitHub 上热门项目 OpenClaw 的 Star 数增长高度同步。这暗示了目前的生态繁荣很大程度上是由**社交媒体热度(Hype)**驱动的——开发者们像游客一样蜂拥而至,发布一个技能打卡,而非持续的工程投入。
惊人的重复率 (Redundancy)
在 4 万个技能中,有多少是真正独特的创新?答案可能让你失望。
研究发现,如果仅进行严格的名称去重,只有 53.7% 的技能是唯一的。这意味着近一半的技能是重复上传或简单的“换皮”。
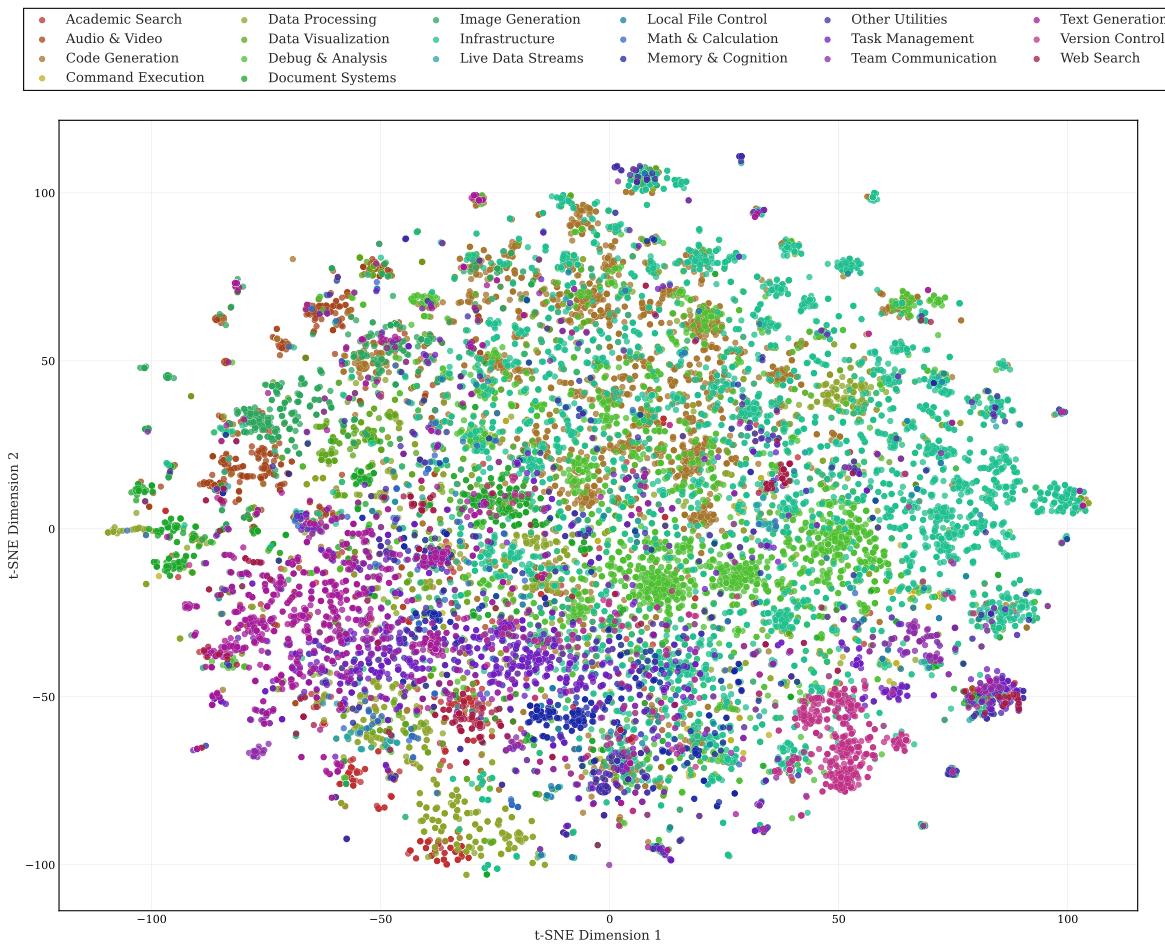
图 2:技能语义嵌入的 t-SNE 可视化。可以看到大量技能在语义空间中紧密聚类(Tight Clusters),表明功能高度雷同。
这种高冗余度造成了严重的“信噪比”问题:用户想找一个好用的工具,却被淹没在无数同质化的垃圾技能中。这就像 App Store 里有 1000 个完全一样的“手电筒”应用,用户根本无法分辨哪个是安全的,哪个是好用的。
03. 供需错位:开发者在“自嗨”,用户在“等待”
当我们将技能按功能分类(Taxonomy)后,一个巨大的**供需错位(Supply-Demand Mismatch)**浮出水面。市场正在生产大量用户不需要的东西,而用户急需的东西却没人做。
供应端:程序员的“回声室”
数据显示,54.7% 的技能都属于 Software Engineering(软件工程) 类别。
- 代码生成、环境配置、Git 操作……
- 这典型地反映了“开发者为开发者开发工具”的现象。因为编写这类技能对程序员来说门槛最低,最容易上手,也最容易复制。
需求端:用户的真实渴望
然而,当我们看**下载量(Installs)**时,情况截然不同。
- 用户最想要的是 Web Search(网络搜索) 和 Content Creation(内容创作)。
- Web Search 类技能的平均下载量高达 1,268 次,是绝对的“顶流”。
- 但讽刺的是,Web Search 仅占技能总供应量的 1.4%。
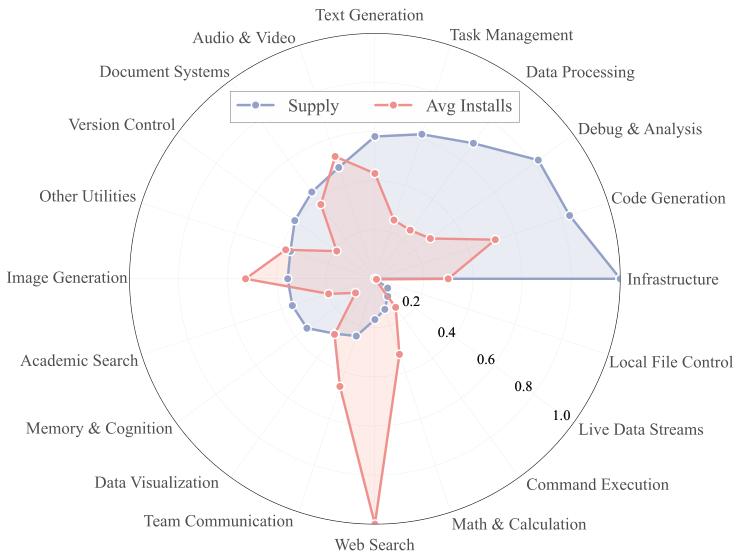
图 3:供需错位示意图。软件工程类技能泛滥成灾,而用户急需的搜索和创作类技能却供给不足。
为什么会有这种错位? 论文指出,构建一个高质量的搜索技能成本很高(需要稳定的连接器、API 维护、处理反爬、清洗数据),而写一个“帮我写 Python 代码”的 Prompt 却几乎零成本。这种激励机制的偏差,导致了市场的结构性失衡。
04. 隐形的“上下文税”:你的 Token 去哪了?
技能不是免费的,它们消耗的是昂贵的 Context Window(上下文窗口)。
在 Agent 的工作流中,为了让 AI 知道怎么使用技能,通常需要把技能的说明文档(Prompt)加载到上下文中。研究发现,虽然大多数技能的长度在 2000 token 以内,但存在一个严重的长尾效应(Heavy-tailed Distribution)。
- 前 1% 的技能长度超过 9,253 tokens。
- 最大的技能甚至达到了 116,239 tokens!
想象一下,你只是想让 AI 帮你做个简单的数据转换,结果它加载了一个 10 万 token 的技能包(包含了冗余的文档、巨大的模板、甚至没用的代码注释)。这不仅会瞬间耗尽你的 Token 预算,还会挤占推理空间,导致 AI 变得“健忘”甚至产生幻觉。
这揭示了当前生态缺乏**模块化(Modularization)和按需加载(Selective Loading)**的机制。未来的 Agent 系统需要像操作系统管理内存一样,精细化地管理技能的上下文占用。
05. God Mode——9% 的技能处于“高危”状态
这是整篇论文最令人不安的发现。研究团队基于 L0(安全) 到 L3(高危) 的标准对技能进行了审计。
- L0 (54%):只读公共数据(如查天气)。
- L1 (5%):读取隐私数据(如读邮件)。
- L2 (30%):中等风险操作(如发邮件、写文件)。
- L3 (9%):关键风险(Critical Risk)。
9% 的 L3 技能意味着什么?
这意味着有接近 4000 个公开可用的技能,拥有对系统造成不可逆破坏的能力。论文列举了具体的高危能力:
- 任意命令执行:允许 AI 执行
shell command,甚至是rm -rf。 - 密钥管理:读取或生成 SSH 私钥。
- 金融操作:直接连接加密货币钱包,进行转账或交易。
- Root 权限:修改系统级配置。

图 4:L3 高危技能实例。注意高亮部分:处理 API Key、执行 Shell 命令、管理加密货币钱包。这些技能一旦被恶意利用或 AI 产生幻觉,后果不堪设想。
在当前的架构下,很多 Agent 是在缺乏严格沙盒(Sandboxing)的环境中运行的。安装一个 L3 技能,本质上就是给了 AI 一个“上帝模式”的开关。如果遭遇提示词注入攻击(Prompt Injection),攻击者可以轻易诱导 AI 甚至直接接管用户的系统。
06. 总结与启示:从“狂野西部”走向“法治社会”
这篇论文为当前过热的 Agent 市场泼了一盆冷水,也指明了未来的方向。Agent Skills 无疑是扩展 LLM 能力的关键基础设施,但目前的生态更像是一个充满了泡沫和地雷的“狂野西部”。
对于开发者和研究者来说,有三个关键的启示:
- 安全必须前置(Security First):我们不能再依赖“默认信任”。未来的 Agent 系统必须引入严格的沙盒机制和最小权限原则(Principle of Least Privilege)。一个查天气的技能,绝不应该有权限访问你的 SSH 密钥。
- 去伪存真(Canonicalization):生态系统需要更好的发现机制和质量控制,过滤掉那些复制粘贴的僵尸代码,让优质的规范技能(Canonical Skills)脱颖而出。
- 关注真实需求:别再写第 10001 个“代码生成器”了。用户真正需要的是能够连接真实世界数据、稳定可靠的搜索与检索工具。
当 AI 从 Chatbot(聊天机器人)进化为 Agent(智能体),本质上是从 Read-Only(只读) 模式切换到了 Read-Write(读写) 模式。这种能力的跃升令人兴奋,但我们是否已经准备好,为 AI 的每一次“写入”操作承担责任?在给你的 AI 安装“上帝模式”之前,请先确认它不会变成毁灭你数字资产的“破坏神”。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 13
13 0
0- 0



 已为社区贡献7条内容
已为社区贡献7条内容

所有评论(0)