深入解析nanobot的原理与架构
用户输入 → 构建上下文 → LLM 推理 → 决定调用工具 / 直接回答 → 执行工具 → 把结果当作新观察 → 再次推理,直到任务完成。对于想学习 Agent 原理、搭建个人/团队 AI 助手的开发者来说,nanobot 是一个非常好的“教材级项目”。一个功能完整的 AI Agent,不需要几十万行代码,也不需要复杂的“平台化”设计。,按官方文档填写 Telegram / 飞书 / Disco
一、nanobot 是什么?一句话概括
nanobot 是一个超轻量级 AI Agent(智能体)框架:
用约 4000 行 Python 代码,实现了一个能接入多平台聊天软件、支持多 LLM、带记忆和工具系统的“个人 AI 助手”,代码量只有同类项目 Clawdbot / OpenClaw 的 1% 左右。

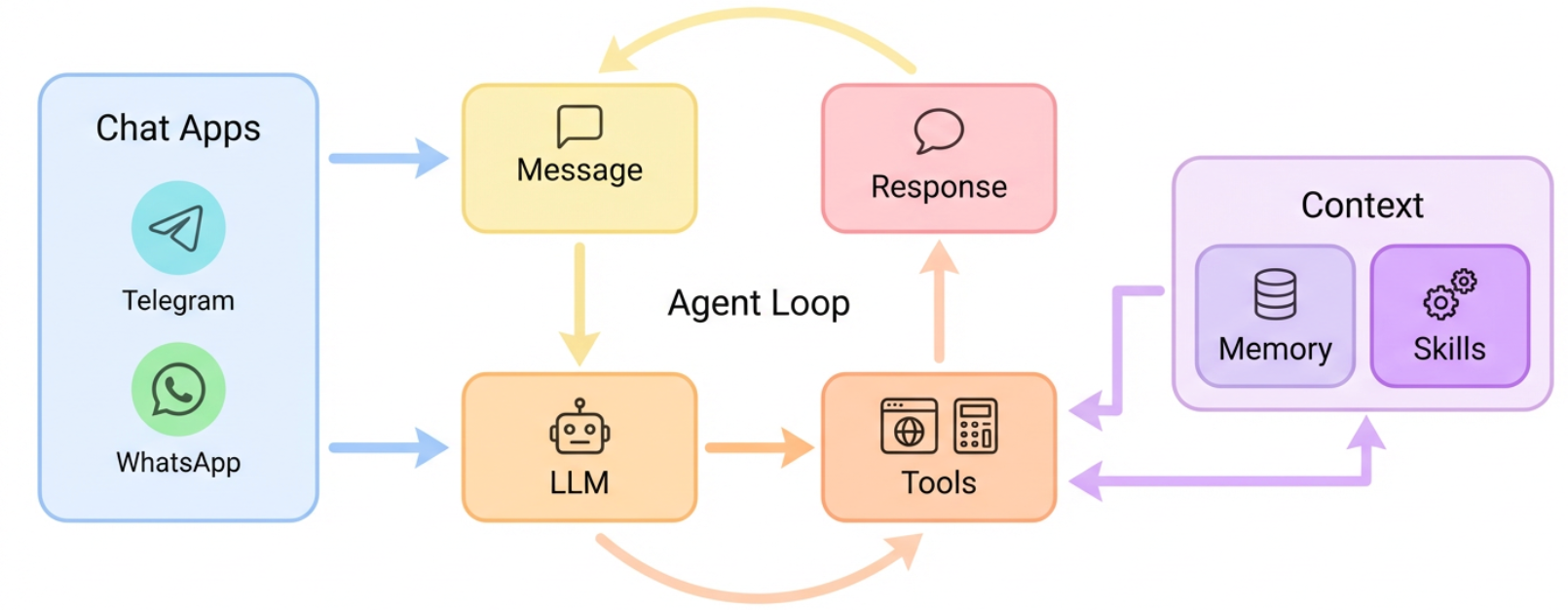
二、整体架构:从聊天窗口到 LLM 的“神经中枢”
先看一张整体架构示意图:
2.1 分层职责(从下往上理解)
- Channels 通道层
- 封装了各聊天平台的差异:Telegram、飞书、Discord、WhatsApp 等。
- 每个
Channel把平台消息转成统一的内部消息格式,推送到MessageBus。 - 出站时,把统一消息格式再转回各平台的 API 调用。
- MessageBus(消息总线)
- 一个
asyncio.Queue,负责接收所有通道的入站消息,按顺序交给AgentLoop处理。 - 解耦“平台接入”和“Agent 决策逻辑”。
- 一个
- Agent Core(核心引擎)
AgentLoop:主循环,负责从消息总线取消息、调用 LLM、执行工具、控制最大迭代次数(防止死循环)。ContextBuilder:组装系统提示词,包括身份信息、记忆、技能摘要、历史对话等。MemoryStore:管理长期记忆(MEMORY.md)和每日笔记(memory/YYYY-MM-DD.md)。SkillsLoader:加载“技能”(SKILL.md),让 Agent 动态获得新能力。ToolRegistry:注册文件操作、Shell 执行、Web 搜索等工具。
- LLM Providers
- 通过 LiteLLM 统一封装 OpenRouter、Anthropic、OpenAI、DeepSeek、Gemini、vLLM 等多种后端。
- 配置好 API Key / apiBase,Agent 就能透明切换模型。
- 外部世界
- 文件系统、Shell 命令、Web 搜索、定时任务等,通过工具系统与 Agent 交互。
三、核心原理:ReAct 循环 + 极简工程实现
3.1 Agent Loop:思考—行动—观察的闭环
nanobot 的核心是一个典型的 ReAct(Reasoning + Acting)循环:
用户输入 → 构建上下文 → LLM 推理 → 决定调用工具 / 直接回答 → 执行工具 → 把结果当作新观察 → 再次推理,直到任务完成。
简化版逻辑(概念性伪代码):
class AgentLoop:
def run(self, user_input: str) -> str:
# 1. 构建上下文:系统提示 + 记忆 + 历史
context = self.context_builder.build(user_input)
# 2. LLM 决策
response = self.llm.complete(context)
# 3. 如果要调用工具
if response.has_tool_call:
result = self.tool_executor.execute(response.tool_call)
# 把工具执行结果当作“观察”,再次进入循环
return self.run(f"Observation: {result}")
else:
# 直接回答用户
return response.content
关键点:
- 最大迭代次数:默认上限约 20 轮,防止工具调用死循环。
- 工具执行沙箱:生产环境建议配置
restrictToWorkspace: true,限制只能在工作目录内操作。
3.2 ContextBuilder:系统提示词是如何“拼出来”的
ContextBuilder 负责把多块信息拼成最终发给 LLM 的 messages:
- 核心身份:当前时间、运行环境、工作目录等。
- Bootstrap 文件:
AGENTS.md、SOUL.md、USER.md、TOOLS.md、IDENTITY.md等,用户可自定义。 - 记忆上下文:从
MEMORY.md和最近若干天的日记文件中读取。 - 技能摘要:列出可用技能及其描述。
- 历史对话:当前会话的聊天历史。
- 当前用户消息:支持多模态(如图片)。
这样设计的好处是:
所有“人格”“记忆”“技能”都是可读的 Markdown 文件,调试和定制非常直观。
3.3 Memory:两层记忆系统
nanobot 的记忆系统非常“工程化”又易于理解:
MEMORY.md:长期记忆,存放重要事实、用户偏好、项目背景等。memory/YYYY-MM-DD.md:每日笔记,自动按日期组织。MemoryStore提供:get_memory_context():返回长期记忆 + 最近 N 天的笔记作为上下文。append_today():追加到今天的日记。read_long_term() / write_long_term():读写长期记忆。
效果是:你告诉 nanobot “我的项目代号是 X”,它可以在合适的时候自动写入MEMORY.md,后续对话随时引用。
3.4 Skills & Tools:用 Markdown + Python 插件扩展能力
- 技能(Skills)
- 每个
SKILL.md文件描述一个能力,如天气查询、GitHub 操作、tmux 终端管理等。 - 头部 YAML 配置
always: true/false,决定是“始终加载”还是“按需加载”。
- 每个
- 工具(Tools)
- 内置工具包括:
read_file、write_file、edit_file、list_dir、shell、brave_search、fetch_url、message、spawn、cron等。 - 每个工具都是一个 Python 类,通过
ToolRegistry注册,Agent 根据工具描述和参数 schema 自动调用。
- 内置工具包括:
四、从代码视角看架构:为什么说它是“教学级”项目?
nanobot 的代码结构非常清晰,核心目录大致如下:
nanobot/
├── agent/
│ ├── loop.py # Agent 主循环:思考-行动-观察
│ ├── context.py # Prompt 构建
│ ├── memory.py # 持久记忆
│ ├── skills.py # 技能加载器
│ ├── subagent.py # 后台子代理
│ └── tools/ # 内置工具集
│ ├── filesystem.py
│ ├── shell.py
│ ├── web.py
│ ├── message.py
│ └── ...
├── skills/ # 内置技能(GitHub、天气、tmux 等)
├── channels/ # 各聊天平台适配
├── bus/ # 消息总线
├── providers/ # LLM 提供商封装
├── session/ # 会话管理
├── config/ # 配置加载
└── cli/ # 命令行入口
核心特点:
- 约 4000 行核心代码,对比 OpenClaw 的 43 万行,体量小两个数量级。
- 单文件可理解:每个核心模块基本可以在一屏内看完。
- 显式优于隐式:没有“魔法基类”和复杂的元编程,适合学习 Agent 架构。
五、应用案例:从“个人助手”到“团队虚拟员工”
下面是几个比较典型的应用方向,你可以结合自己公司的场景改写。
案例 1:个人知识助手 + 日程管理
场景:你每天在 Telegram / 飞书里跟 nanobot 对话,让它帮你:
- 整理会议纪要、项目文档。
- 记录“项目背景”“关键决策”到
MEMORY.md。 - 设置定时提醒:每天早上 9 点自动推送“今日待办”。
实现要点:
-
在
~/.nanobot/config.json中配置一个默认 Agent 和 LLM 提供商:{ "agents": { "defaults": { "model": "anthropic/claude-sonnet-4-20250514", "maxTokens": 8192, "temperature": 0.7 } }, "providers": { "openrouter": { "apiKey": "sk-or-v1-..." } } } -
在工作目录写
AGENTS.md/USER.md,定义你的“人格”:- 你是某产品的负责人;
- 你关心哪些指标;
- 你希望如何被称呼等。
-
使用内置工具:
write_file/edit_file:自动更新项目文档。cron工具:添加定时任务,例如每天早上提醒你查看某个看板。
案例 2:飞书群里的“虚拟运维员工”
场景:在飞书群里,@nanobot 发送:
查日志 xxx重启服务 yyy查最近 1 小时的异常
nanobot 调用后端 API / 日志平台,把结果回填到群里。
实现要点:
-
在飞书开放平台创建企业自建应用,获取 App ID / App Secret,开通机器人能力和相应权限。
-
在 nanobot 中配置
feishu通道:"channels": { "feishu": { "enabled": true, "appId": "...", "appSecret": "...", "allowFrom": [] } } -
编写自定义工具或技能:
- 封装公司内部的日志查询 / 发布部署接口。
- 在
SKILL.md中描述“运维技能”,让 Agent 知道何时调用。
-
在飞书群里 @机器人,即可触发运维操作,无需额外开发 UI。
案例 3:Telegram / Discord 的 7×24 小时监控助手
场景:
- 服务器有监控告警(Prometheus / 自定义脚本);
- 你希望异常发生时,nanobot 能自动在 Telegram / Discord 里发消息,甚至尝试自愈。
实现要点:
-
使用 nanobot 的 Telegram / Discord 通道:
nanobot telegram # 或 nanobot discord -
配置
cron工具,定时执行脚本检查监控指标。 -
当脚本发现异常时,调用 nanobot 的
message工具,向指定群 / 用户发送告警。 -
可进一步让 nanobot 执行“自愈脚本”(如重启服务、清理磁盘),实现自动修复。
案例 4:多模型“混合大脑”助手
场景:
- 常规对话用便宜模型;
- 复杂推理 / 代码任务用更强的模型。
实现要点:
- 在
providers中配置多个 LLM 后端。 - 在
AGENTS.md中写:- 对于简单聊天,使用模型 A;
- 对于代码、数据分析,调用模型 B。
- 通过工具 / 技能封装“切换模型”的能力,让 Agent 根据任务类型自动选择模型。
六、与 OpenClaw / Clawdbot 的对比:极简主义的代价
从公开数据对比一下:
| 指标 | OpenClaw(Clawdbot) | nanobot |
|---|---|---|
| 核心代码量 | 430,000+ 行 | ~4,000 行 |
| 启动时间 | 数十秒到分钟级 | < 1 秒 |
| 部署复杂度 | 较高,依赖多 | pip install 即可 |
| 可读性 | 认知负荷大 | 一天可通读核心模块 |
| 浏览器自动化等 | 支持 | 不支持 |
| 平台集成数量 | 50+ 平台 | 8–10 个主流平台 |
| nanobot 的取舍是:砍掉 20% 的“高级功能”,换取 99% 的代码减少和更高的可维护性。 | ||
| 对于个人开发者、小团队、研究者来说,这是一个非常“舒服”的平衡。 |
七、如何在一台服务器上快速部署 nanobot?
简要步骤(你可以整理成“部署实战”章节):
-
安装(任选其一)
pip install nanobot-ai # 或 uv tool install nanobot-ai # 或从源码 git clone https://github.com/HKUDS/nanobot.git cd nanobot && pip install -e . -
初始化配置
nanobot onboard按提示填写 API Key 和默认模型。
-
启动
- 命令行对话:
nanobot agent - 启动 Telegram Bot:
nanobot telegram - 启动飞书等通道:
nanobot gateway
- 命令行对话:
-
配置通道
编辑~/.nanobot/config.json,按官方文档填写 Telegram / 飞书 / Discord 的凭证。
八、小结:nanobot 的意义
nanobot 并不是要取代所有大型 Agent 框架,而是用 极简架构 + 清晰代码 证明了一件事:
一个功能完整的 AI Agent,不需要几十万行代码,也不需要复杂的“平台化”设计。
对于想学习 Agent 原理、搭建个人/团队 AI 助手的开发者来说,nanobot 是一个非常好的“教材级项目”。你可以:
- 通读源码,理解 ReAct 循环、记忆管理、工具调用;
- 在它的基础上,增加你自己的工具和平台适配;
- 把它当作企业内部“虚拟员工”的原型,快速验证想法。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)