Cursor+Claude AI编程 - Cursor模型会话上下文窗口介绍
《Cursor+ClaudeAI编程快速入门》课程简介 本课程系统讲解Cursor工具的使用,从基础安装到项目实战。重点介绍200K上下文窗口的技术原理与实用价值:1个token≈0.75个英文单词或2-3个中文字符,200K容量可处理约15-20万单词(相当于中型项目完整代码+文档)。课程包含Java/Python全栈项目实战(SpringBoot+Vue3/Flask+Vue3学生管理系统),
大家好,我是小锋老师,最近更新《2027版 Cursor+Claude AI编程 1天快速上手》专辑,感谢大家支持。
本课程主要讲解Cursor简介,Cursor下载安装,Cursor生成helloWorld网页,Cursor会话里的Cursor会话里的Agent,Plan,Debug,Ask区别以及使用,Cursor常用模型介绍,Cursor模型会话上下文介绍,以及最后利用Cursor Opus4.6快速生成一个Java项目 -SpringBoot4+Vue3的学生信息管理系统,利用Cursor Opus4.6快速生成一个Python项目 - Flask2+Vue3的学生信息管理系统。这个作为Cursor入门介绍和简单实战,让大家一天时间快速上手Cursor AI编程。后面我们将会发布高级的Cursor AI编程实战,会讲道一些实用的高级技巧。

视频教程+课件+源码打包下载:
链接:https://pan.baidu.com/s/1Oo7dtFf_Zt7hJyl6aYX6TA?pwd=1234
提取码:1234
Cursor+Claude AI编程 - Cursor模型会话上下文窗口介绍
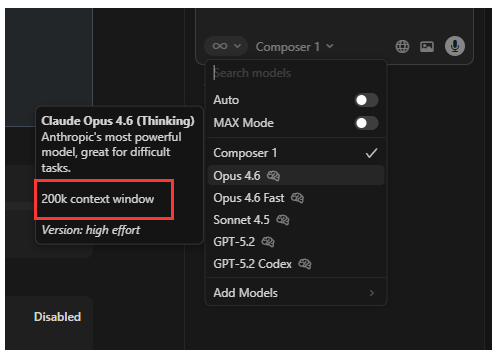
我们选择模式的时候,会看到一个 200k context windows
1. 基础概念
Context Windows(上下文窗口) 指的是 AI 模型一次性能处理的最大文本量,200K 表示:
-
200,000 tokens(约 15-20 万单词)
-
相当于 150-200 页技术文档
-
或 3000-5000 行代码
2. Tokens 是什么?
在 AI 语境中:
-
1 token ≈ 0.75 个英文单词
-
1 token ≈ 2-3 个中文字符
-
代码通常更紧凑:100 行代码约 500-800 tokens
3. 200K Context 的实际意义
优势:
# 场景1:完整项目理解 # 200K 可以容纳: # - 整个中型项目代码(约 30-50 个文件) # - 技术文档 # - 依赖说明 # - 错误日志 @src/ # 整个源码目录 @docs/ # 所有文档 @package.json # 依赖配置 # 提问:基于整个项目结构,如何实现新功能 X?
场景2:长会话历史
对话轮次 tokens消耗 剩余容量 第1轮: 5,000 195,000 第5轮: 25,000 175,000 第20轮: 80,000 120,000 第50轮: 150,000 50,000
4. 200K 与之前版本的对比
| 版本 | Context | 可处理内容 | 适用场景 |
|---|---|---|---|
| 旧版 | 8K | 单个文件+简单对话 | 简单代码问答 |
| GPT-4 | 32K | 多个文件+中等对话 | 功能开发 |
| Cursor 200K | 200K | 整个项目+长对话 | 企业级开发 |
实际影响:
// 以前(32K限制): // 只能分析:当前文件 + 2-3个相关文件 // 对话:约 20-30 轮后需要重置 // 现在(200K): // 可以分析:整个项目 + 所有文档 // 对话:50-100 轮完整对话历史 // 多任务:连续多个复杂任务
5. 在 Cursor 中的具体应用
a. 智能项目分析
# 一次性理解完整项目 @整个项目文件夹 @技术设计文档.md @API文档.md @错误日志.txt # 提问:分析项目架构瓶颈并提出优化方案 # AI 可以基于所有材料给出综合建议
b. 长流程开发
// 从需求到实现的完整流程: // 1. 分析需求文档(10K tokens) // 2. 设计数据库结构(5K tokens) // 3. 设计 API 接口(8K tokens) // 4. 实现业务逻辑(15K tokens) // 5. 编写测试用例(7K tokens) // 总消耗:约 45K tokens,仍在 200K 内 // AI 能记住所有步骤的上下文
c. 复杂的重构任务
# 重构涉及的文件: # - model.py (3K tokens) # - service.py (4K tokens) # - controller.py (2K tokens) # - test files (5K tokens) # - 文档说明 (2K tokens) # - 历史讨论 (3K tokens) # 总:19K tokens,AI 能理解所有关联
6. 如何最大化利用 200K Context
策略1:分层级加载
# 第一层:核心代码(约 50K) @src/core/ @package.json # 第二层:工具和配置(约 20K) @src/utils/ @config/ # 第三层:测试和文档(约 30K) @tests/ @docs/ # 保留 100K 给对话历史
策略2:智能上下文管理
// 使用 .cursorrules 优化
{
"priority_files": [
"src/",
"package.json",
"README.md"
],
"exclude_patterns": [
"node_modules/",
"*.log",
"dist/"
],
"max_tokens_per_file": 5000
}策略3:分阶段对话
阶段1:项目概览(消耗 30K) - 加载项目结构 - 理解业务逻辑 阶段2:具体开发(消耗 50K) - 实现功能A - 实现功能B - 编写测试 阶段3:优化调试(消耗 40K) - 性能优化 - 错误修复 - 文档更新
7. 实际容量计算示例
一个中型 React 项目:
文件类型 数量 平均大小 总tokens .tsx 组件 20 150 行 15,000 .ts 工具类 15 80 行 7,500 .css/scss 10 100 行 5,000 配置文件 5 50 行 1,500 测试文件 25 50 行 7,500 文档 - - 10,000 node_modules - 排除 0 ----------------------------------------- 项目总计: 约 46,500 tokens 剩余容量:200,000 - 46,500 = 153,500 tokens 可用于:长达 100+ 轮对话
8. 注意事项
性能影响:
-
200K 满载时响应可能变慢
-
建议保持实际使用在 100-150K 最佳区间
-
定期清理不必要的上下文
成本考虑:
-
更大的 context 意味着更高的 API 成本
-
Cursor 已优化计费策略
最佳实践:
# 1. 开始新项目时 @整个项目代码 # "请理解我的项目结构" # 2. 开发过程中 @相关文件 + 最近修改 # "基于这些代码,实现..." # 3. 定期清理 /clear # 重置上下文但保留知识 /new # 全新会话
9. 技术实现原理
输入层:[你的代码 + 问题 + 历史] → Tokenization ↓ 嵌入层:向量化表示(约 200K tokens) ↓ 注意力层:全局关系建模 ↓ 输出层:生成回答
关键特点:
-
真正的 200K 理解,不是简单的缓存
-
跨文档引用能力增强
-
长期记忆更稳定

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 19
19 0
0- 0



 已为社区贡献32条内容
已为社区贡献32条内容

所有评论(0)