k8s集群内的ollama pod持久化调用本地大模型
法一:通过共享存储(nfc)让本地和集群 Pod 共用一份模型文件,集群 Pod 挂载 NFS 共享目录调用本地大模型。法二:提前在本地windows部署大模型,上传到集群节点,再拷贝到pod中。最后为 Pod 配置持久化存储,这样即使重启虚拟机模型也不会丢失,能够实现持久化调用本地大模型。弊端:大文件传输kubectl cp的效率太低,同一大模型占用本地和集群两处存储空间。本文介绍方法二。
1.首先确保在集群内已经配置了ollama,pod状态是running
![]()
2.我们当然可以进入ollama pod内直接拉取大模型,但这会受网络、虚拟机内存等原因的限制。
kubectl exec -it $OLLAMA_POD -n ai-services -- ollama pull qwen 3:4b
3.本文介绍如何利用本地已经部署的大模型,实现在集群内部调用。此处考虑两种方法。
法一:通过共享存储(nfc)让本地和集群 Pod 共用一份模型文件,集群 Pod 挂载 NFS 共享目录调用本地大模型。
法二:提前在本地windows部署大模型,上传到集群节点,再拷贝到pod中。最后为 Pod 配置持久化存储,这样即使重启虚拟机模型也不会丢失,能够实现持久化调用本地大模型。弊端:大文件传输kubectl cp的效率太低,同一大模型占用本地和集群两处存储空间。
本文介绍方法二。
4.分两步完成,第一步把本地大模型调入集群ollama的pod中,打开windows命令行实现该操作,按提示输入密码;第二步实现持久化存储。
第一步:传递大模型到pod
①传递顺序:windows→k8s节点→pod
前提:确保本地电脑和集群节点在同一内网,能互相ping通。
scp -r <大模型在本地的路径>\* <节点用户名>@<节点ip>:<目标路径>
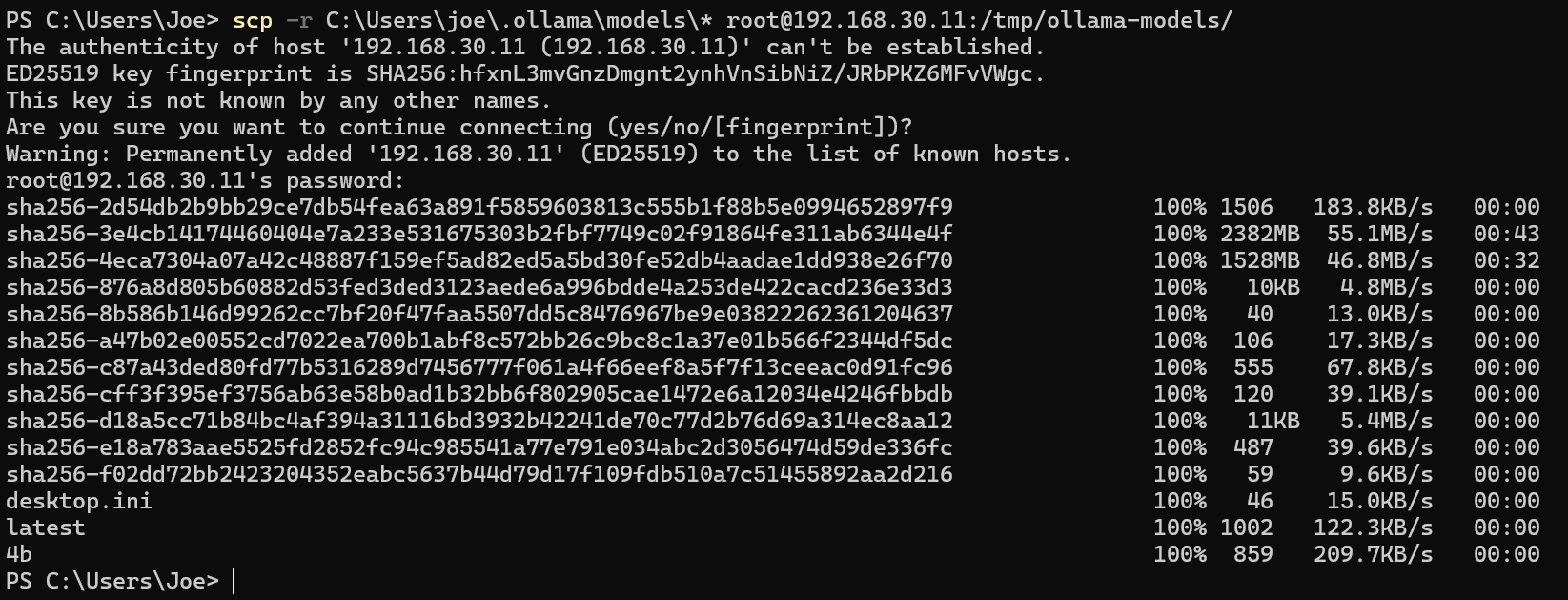
②在节点目标目录查看
#blobs(模型二进制文件)和manifests(模型清单)两个核心文件夹,必须完整拷贝这两个文件夹
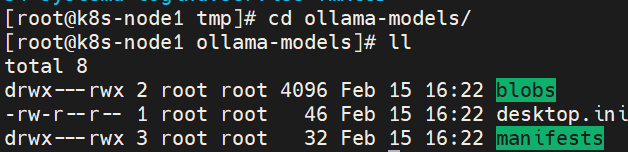
③导入pod
# 找到Ollama Pod名
OLLAMA_POD=$(kubectl get pods -n ai-services -l app=ollama -o jsonpath='{.items[0].metadata.name}')# 把虚拟机/tmp/ollama-models下的文件拷贝到Pod的模型目录
kubectl cp /tmp/ollama-models/ ai-services/$OLLAMA_POD:/root/.ollama/ -n ai-services
④进入pod验证
k8s节点→pod的过程中,注意两个点。
Ⅰ看ollama-models下的manifests文件夹是有文件的,若没有说明cp命令失败,会导致ollama list结果为空。可能是因为kubectl cp /tmp/ollama-models/漏了最后的“/”,导致没有完整拷贝该目录下的所有内容(包括所有子目录、文件) 到目标路径。

ⅡOllama 默认从 ~/.ollama/models 目录加载模型,要确保~/.ollama/models/blobs 和 ~/.ollama/models/manifests 必须直接存在。
⑤使用ollama list 查看大模型,ollama run qwen3:4b运行

qwen3:4b需要约3.3G内存,建议根据电脑内存调整合适大模型。
第二步:持久化挂载,让模型永久保留(Pod 重启不丢失)。
①创建pv,新建ollama-pv.yaml文件并执行。
②修改 Ollama Deployment 挂载 PVC。deployment会自动滚动更新,新的pod完成处于running状态后旧的pod开始终止。一切准备就绪后重启虚拟机,依然能成功调用大模型,说明持久化部署成功。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)