AI大模型:基于大数据Spark小说数据分析系统 可视化 Django框架 requests爬虫 Echarts可视化 python 大数据技术(源码)
AI大模型:基于大数据Spark小说数据分析系统 可视化 Django框架 requests爬虫 Echarts可视化 python 大数据技术(源码)
·
1、项目介绍
本系统以Python、Django为开发基础,整合requests爬虫、Echarts可视化及HTML技术,聚焦17k小说网数据,构建起“采集-分析-展示-管理”的完整功能体系,为用户提供全面的小说数据洞察。
数据采集模块是核心支撑,通过requests爬虫定向抓取17k小说网的作品信息、点击量、类型分布等数据,实现数据源的自动化获取与更新。可视化分析模块为系统亮点,借助Echarts生成多维度图表:涵盖各类型小说数量、新作品点击榜、月票房前20等统计分析,搭配词云图直观呈现小说内容核心词汇,让数据趋势清晰可见。
小说数据列表模块以规整形式展示爬虫采集的完整小说信息,便于用户快速检索详情。后台数据管理模块则为管理员提供数据管控入口,支持对采集的小说数据进行增删改查、校验筛选,确保数据准确性与系统稳定运行。各模块协同运作,实现从数据获取到价值呈现的全流程覆盖,满足用户对17k小说网数据的分析需求。
技术栈:
Python语言、Django框架、requests爬虫、Echarts可视化、HTML、17k小说网
2、项目界面
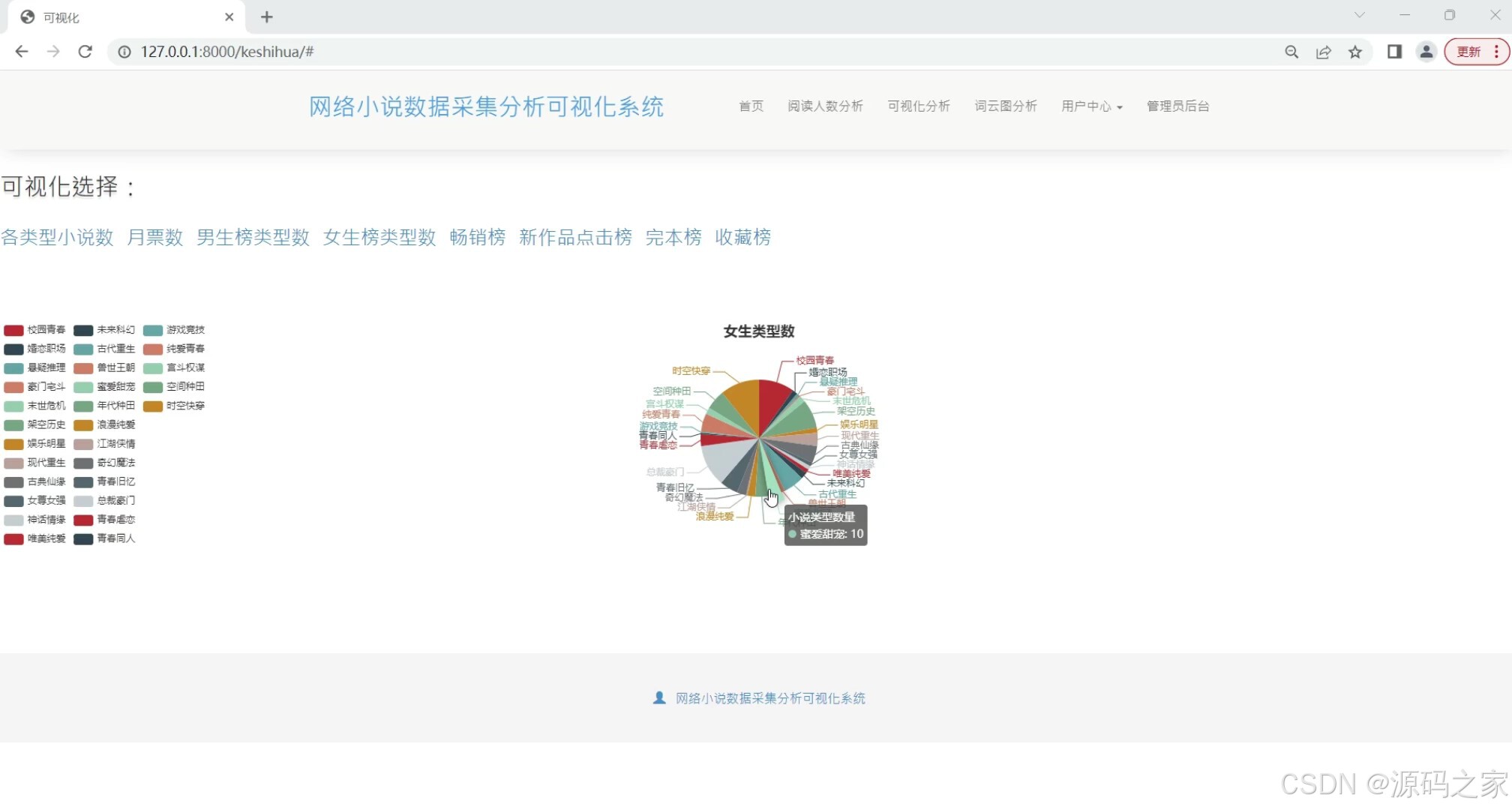
(1)各类型小说数据可视化分析
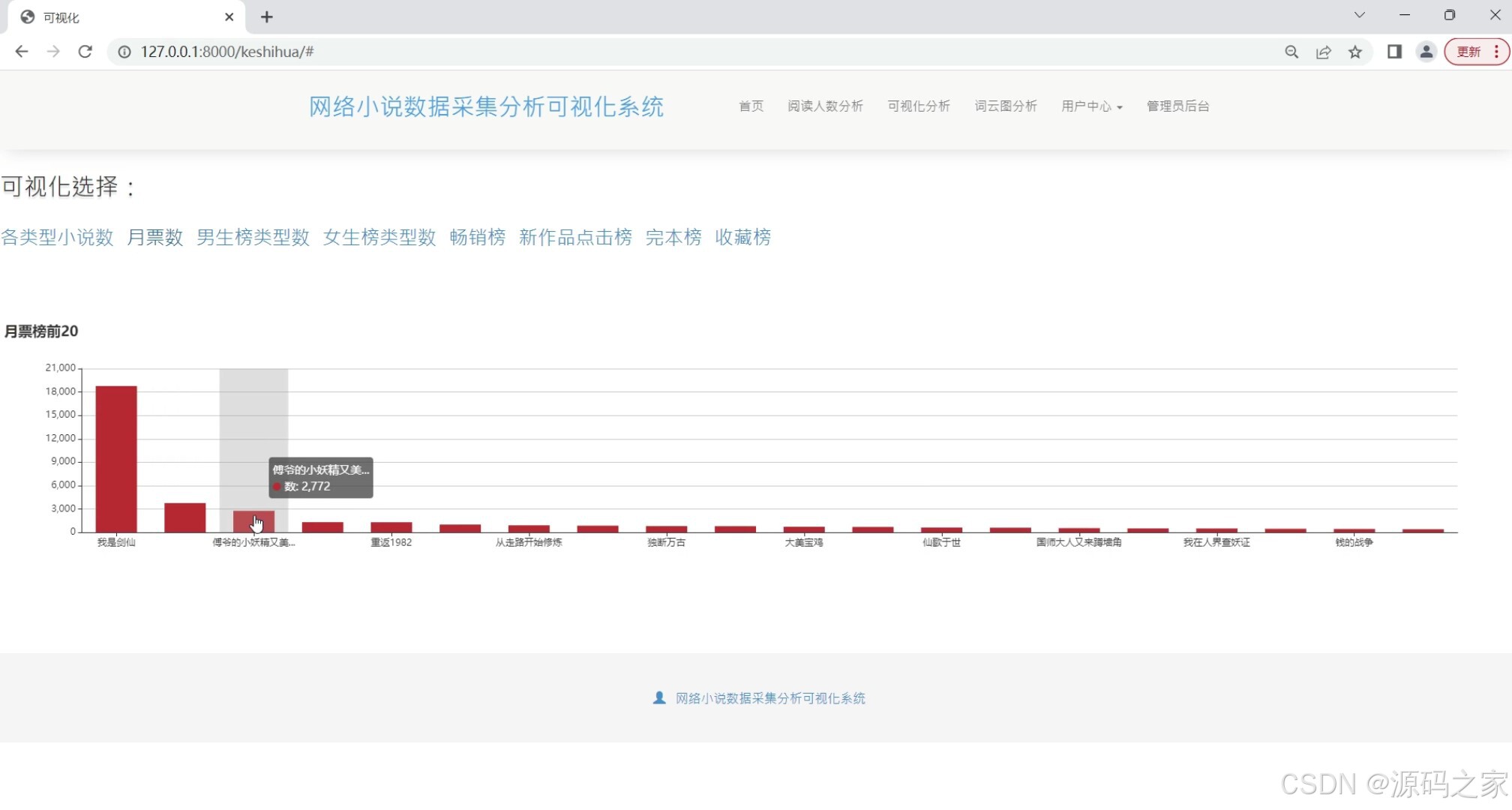
(2)月票房前20分析
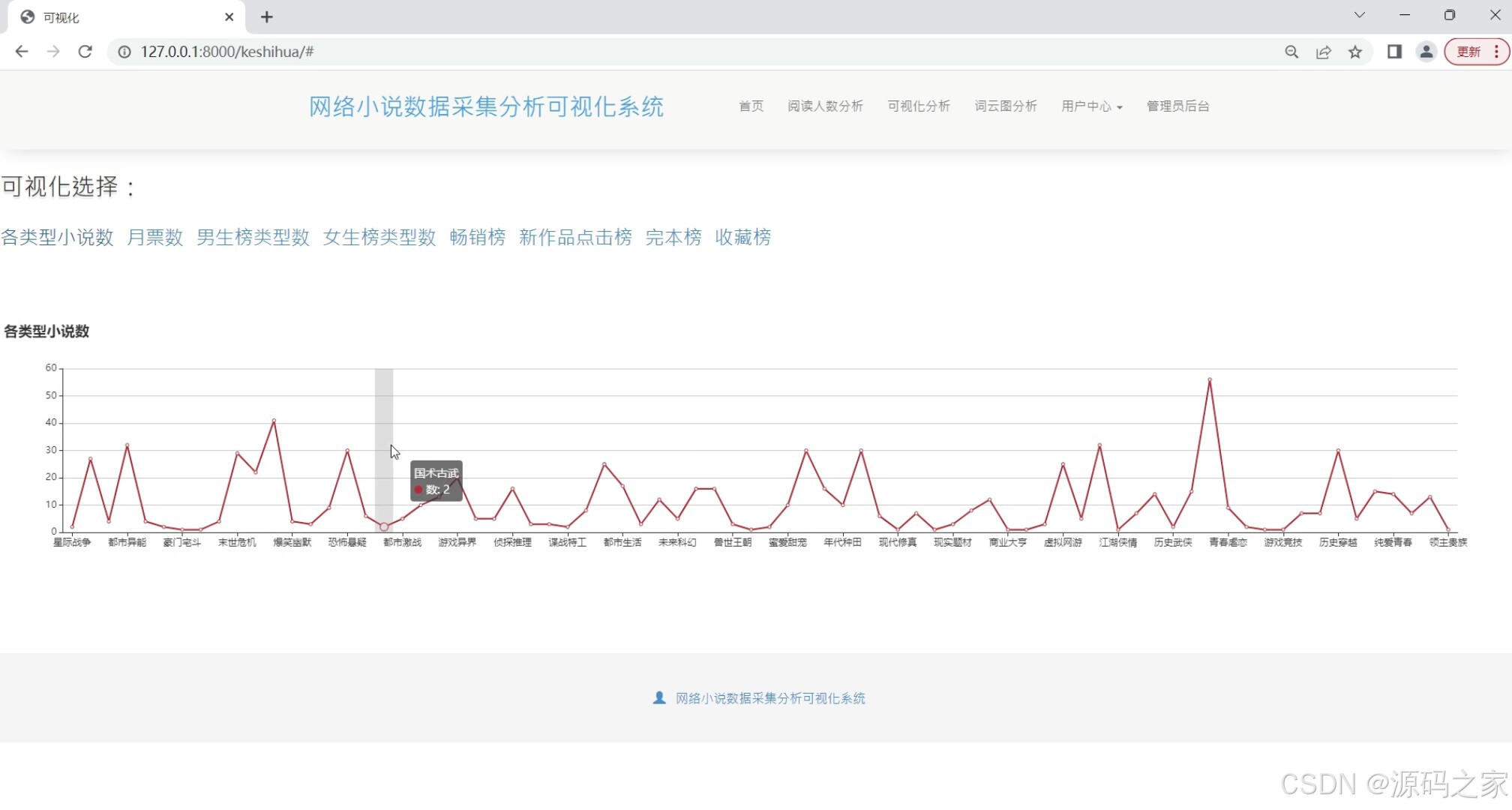
(3)各类型小说数量分析
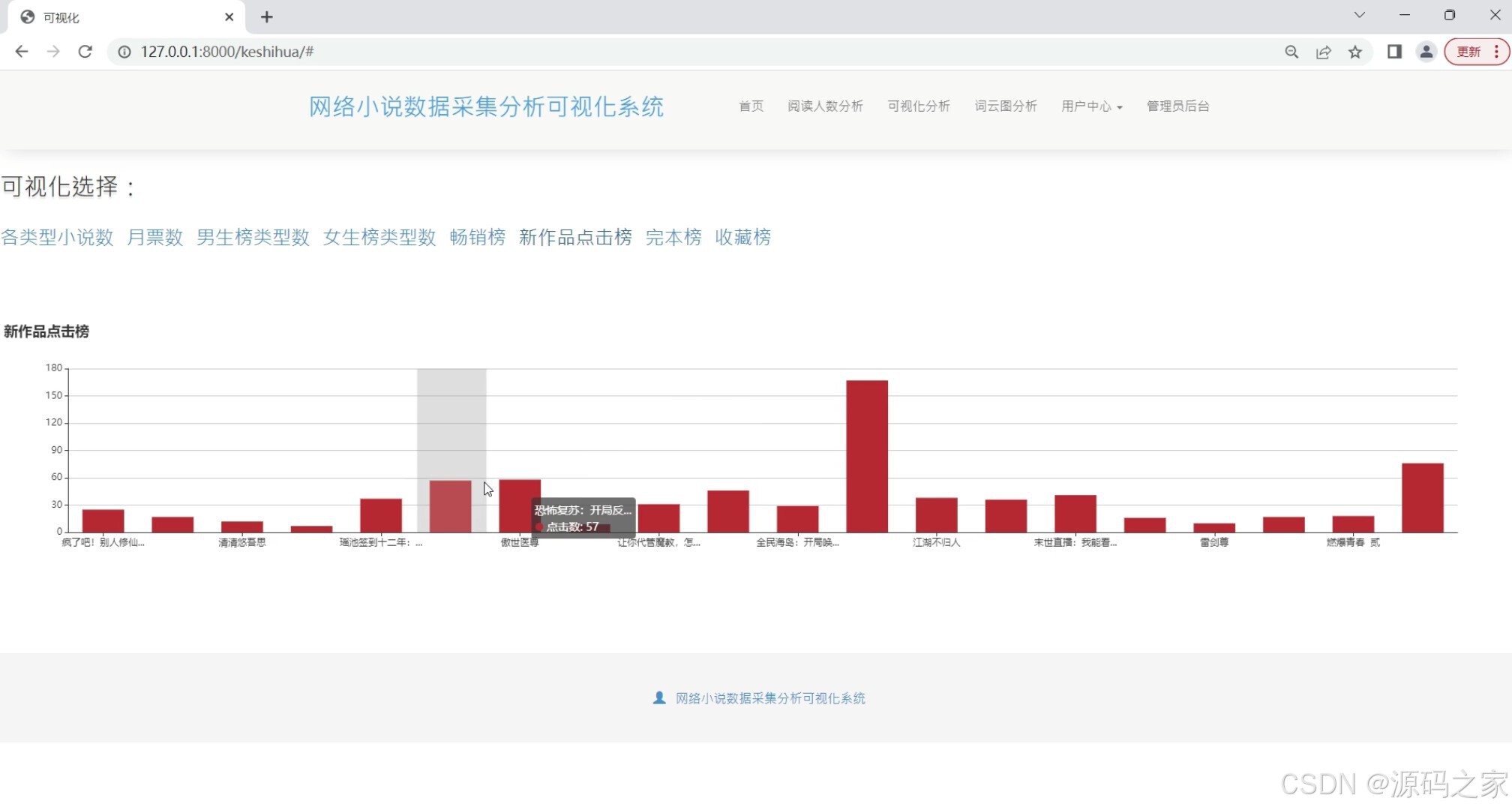
(4)新作品点击榜分析
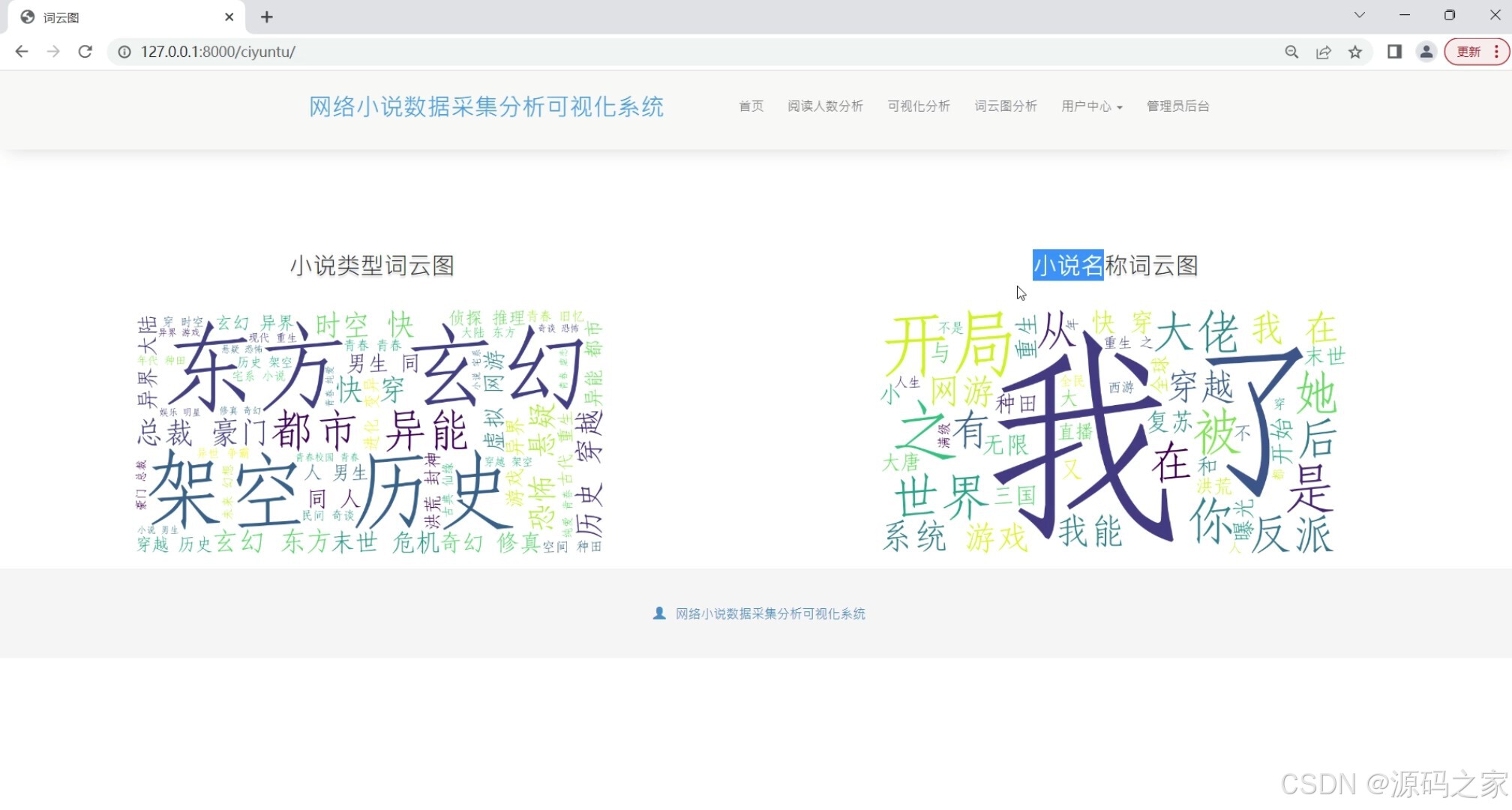
(5)词云图分析
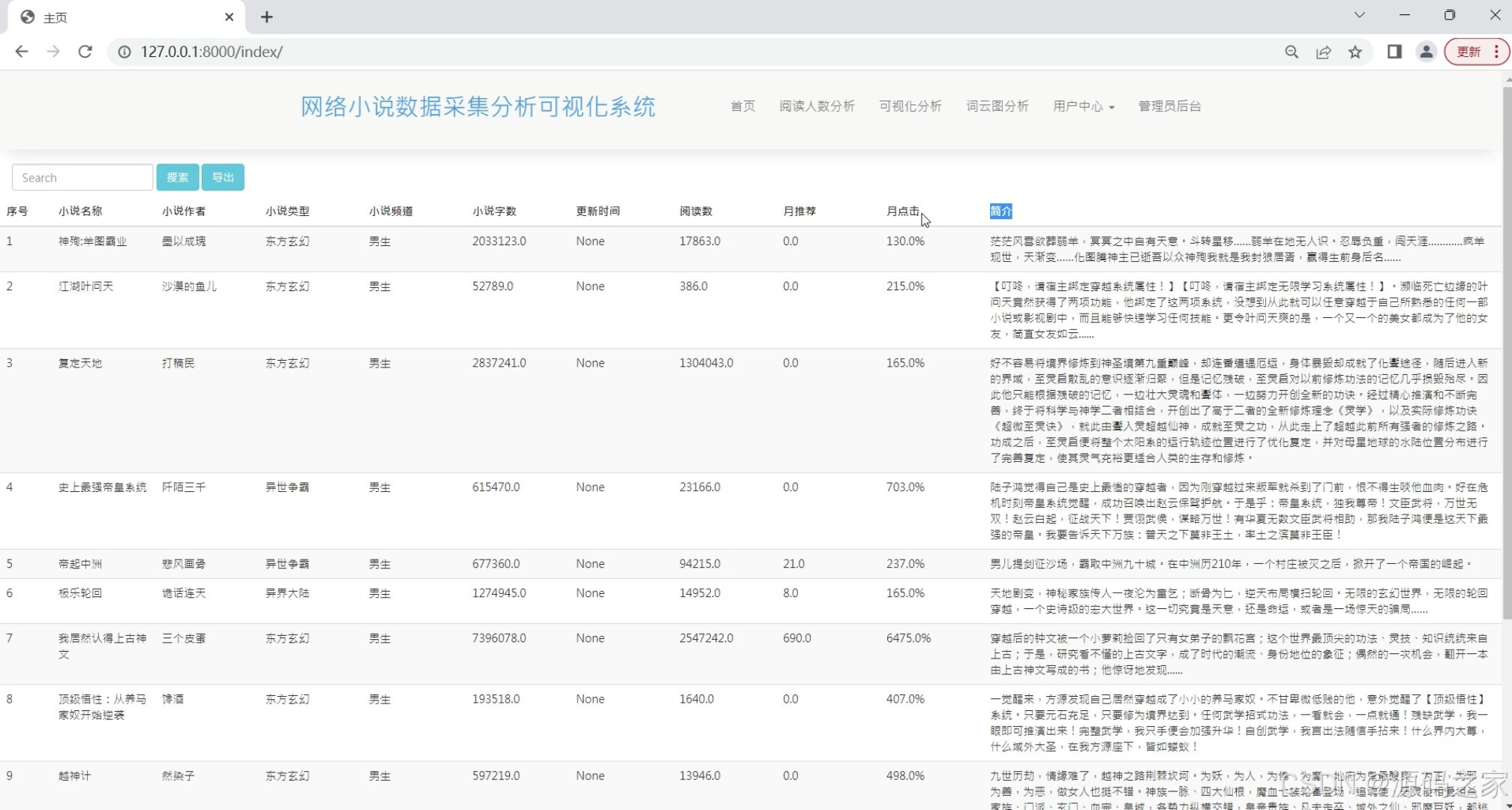
(6)小说数据列表
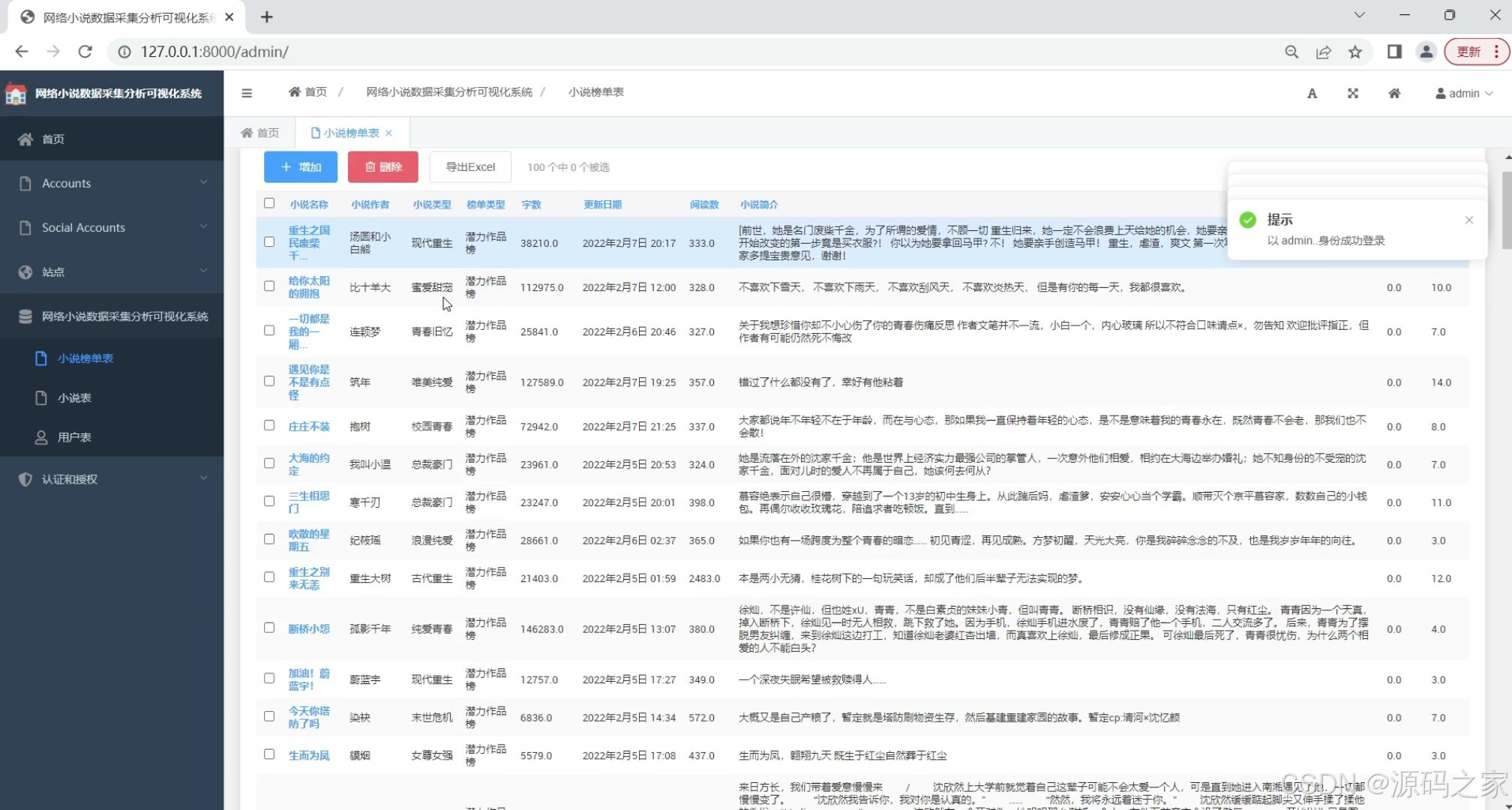
(7)后台数据管理
3、项目说明
17k小说网数据分析系统功能模块介绍
本系统以Python、Django为开发基础,整合requests爬虫、Echarts可视化及HTML技术,聚焦17k小说网数据,构建起“采集-分析-展示-管理”的完整功能体系,为用户提供全面的小说数据洞察。
数据采集模块是核心支撑,通过requests爬虫定向抓取17k小说网的作品信息、点击量、类型分布等数据,实现数据源的自动化获取与更新。可视化分析模块为系统亮点,借助Echarts生成多维度图表:涵盖各类型小说数量、新作品点击榜、月票房前20等统计分析,搭配词云图直观呈现小说内容核心词汇,让数据趋势清晰可见。
小说数据列表模块以规整形式展示爬虫采集的完整小说信息,便于用户快速检索详情。后台数据管理模块则为管理员提供数据管控入口,支持对采集的小说数据进行增删改查、校验筛选,确保数据准确性与系统稳定运行。各模块协同运作,实现从数据获取到价值呈现的全流程覆盖,满足用户对17k小说网数据的分析需求。
一、技术栈
本项目采用了以下技术栈进行开发:
编程语言:Python,一种解释型、面向对象的高级程序设计语言,具有简洁易读、学习曲线平缓的特点,非常适合于数据分析和Web开发。
框架:Django,一个用Python编写的高级Web框架,它允许快速开发安全和维护性高的网站,提供了丰富的功能和组件,大大简化了Web应用的开发过程。
爬虫技术:requests,一个简单易用的HTTP库,用于从17k小说网等网站抓取小说数据。
可视化工具:Echarts,一个使用JavaScript实现的开源可视化库,能够轻松实现数据的图形化展示,提升数据的可读性和理解度。
前端技术:HTML,用于构建网页的基本结构和内容,是Web开发的基础。
数据源:17k小说网,作为本项目的数据来源,提供了丰富的小说资源供我们进行抓取和分析。
二、项目界面与功能模块介绍
各类型小说数据可视化分析
通过图表展示不同类型小说的阅读量、评分等数据,帮助用户了解各类型小说的受欢迎程度。
月票房前20分析(注:此处可能与小说数据不直接相关,可能是项目中的一个额外功能或误植,但为保持原文完整性,仍进行翻译)
展示某个月份内阅读量或评分排名前20的小说,分析这些小说的特点和受欢迎的原因。
各类型小说数量分析
统计并展示不同类型小说的数量,帮助用户了解小说市场的分布和趋势。
新作品点击榜分析
展示新发布小说的点击量排名,分析新作品的受欢迎程度和市场潜力。
词云图分析
通过词云图展示小说中的关键词或高频词,帮助用户了解小说的主题和内容特点。
小说数据列表
展示抓取到的小说数据列表,包括小说名称、作者、类型、简介等基本信息,方便用户进行查找和筛选。
后台数据管理
提供后台管理界面,用于管理抓取到的小说数据、用户数据、日志数据等,确保数据的准确性和安全性。同时,后台管理界面还提供了数据导出、数据清洗等功能,方便用户进行进一步的数据分析和处理。
通过以上功能模块,本小说数据分析可视化系统为用户提供了全面的数据分析服务,帮助用户了解小说市场的趋势和变化,为小说创作和推广提供有力的数据支持。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 73
73 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)