Q-Learning 算法实现网格路径规划(附完整代码 + 动态可视化)
本文通过3×3网格路径规划案例,详细介绍了Q-Learning算法的实现过程。智能体从起点(0,0)出发,需避开障碍物到达终点(2,2)。算法采用ε-贪婪策略平衡探索与利用,通过Q值更新公式迭代优化动作选择。实验包含动态可视化功能,直观展示训练过程中智能体的路径选择与奖励变化。结果表明,经过1000轮训练后,智能体能够学习到最优路径,避开障碍物并最大化奖励。文章完整呈现了环境构建、参数设置、核心算
在强化学习领域,Q-Learning 是最经典的无模型时序差分(TD)学习算法之一,核心思想是通过学习动作价值函数(Q 函数)来指导智能体在环境中选择最优行为。本文将通过一个 3×3 网格路径规划案例,从零实现 Q-Learning 算法,并加入动态可视化效果,帮助大家直观理解算法的训练过程和核心原理。
一、案例场景设定
我们构建一个 3×3 的网格世界,智能体从起点 (0,0) 出发,需要避开障碍物到达终点 (2,2)。核心规则如下:
- 动作空间:上、下、左、右 4 个离散动作
- 奖励机制:终点奖励 + 10,障碍物惩罚 - 5,普通格子根据到终点的距离给予负奖励(距离越远惩罚越大)
- 额外约束:智能体返回上一位置时给予 - 5 的后退惩罚,避免无效往复
二、代码核心模块解析
1. 环境与参数初始化
首先定义网格环境的基础属性和强化学习核心参数:
import numpy as np
import random
import matplotlib.pyplot as plt
# 1. 网格环境初始化
grid_size = 3 # 3×3网格
actions = [0, 1, 2, 3] # 动作定义:0=上,1=下,2=左,3=右
action_names = ['上', '下', '左', '右']
obstacle = [(1,1),(0,2)] # 障碍物位置
goal = (grid_size-1, grid_size-1) # 终点位置(2,2)
# 2. 奖励矩阵初始化
rewards = np.zeros((grid_size, grid_size))
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
rewards[r, c] = 10 # 终点奖励
elif (r, c) in obstacle:
rewards[r, c] = -5 # 障碍物惩罚
else:
# 普通格子:距离终点越远,奖励越低(负奖励)
l = ((r-goal[0])**2 + (c-goal[1])**2)**0.5
rewards[r, c] = -0.1 * l
# 3. Q表初始化:(网格行数, 网格列数, 动作数)
Q = np.zeros((grid_size, grid_size, len(actions)))
# 4. 强化学习核心参数
alpha = 0.1 # 学习率:控制每次更新的步长
gamma = 0.9 # 折扣因子:重视未来奖励(0.9表示较重视未来)
epsilon = 0.2 # 初始探索率:20%概率随机选动作
num_episodes = 1000 # 训练总回合数
epsilon_min = 0.01 # 探索率最小值:避免完全不探索
epsilon_decay = 0.995 # 探索率衰减系数:每回合探索率×0.995关键参数说明:
- Q 表:维度为 (3,3,4),每个元素 Q [r,c,a] 表示在位置 (r,c) 执行动作 a 的价值
- 学习率 α:0.1 表示每次只更新 Q 值的 10%,避免更新幅度过大
- 折扣因子 γ:0.9 表示智能体愿意为了未来的更大奖励放弃即时小奖励
- ε- 贪婪策略:训练初期探索为主,后期利用为主(探索率逐渐衰减)
2. 状态转移函数
定义智能体执行动作后的状态转移规则,确保智能体不会超出网格边界:
def get_new_state(state, action):
"""根据当前状态和动作,计算新状态(边界处理)"""
r, c = state
if action == 0: # 上:行号减1,不小于0
return max(0, r-1), c
elif action == 1: # 下:行号加1,不大于网格最大行号
return min(grid_size-1, r+1), c
elif action == 2: # 左:列号减1,不小于0
return r, max(0, c-1)
elif action == 3: # 右:列号加1,不大于网格最大列号
return r, min(grid_size-1, c+1)3. 动态可视化设置
使用 matplotlib 的交互式绘图功能,实时展示训练过程:
# 开启实时绘图模式
plt.ion()
fig,(ax1, ax2) = plt.subplots(1, 2, figsize=(10,5)) # 1行2列子图
# 左图:每回合总奖励变化曲线
reward_record = [] # 记录每回合总奖励
reward_line, = ax1.plot([], [], 'b-', linewidth=0.5)
ax1.set_title('Total Reward per Episode', fontsize=16)
ax1.set_xlabel('Episode')
ax1.set_ylabel('Reward')
ax1.grid(True, alpha=0.3)
ax1.set_xlim(0, num_episodes)
ax1.set_ylim(-20, 20)
# 右图:智能体实时位置可视化
# 绘制静态网格(终点黄色、障碍物黑色、普通格子白色)
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
color = 'yellow'
elif (r, c) in obstacle:
color = 'black'
else:
color = 'white'
# 绘制正方形格子(坐标系转换:网格行→y轴,列→x轴)
ax2.fill([c, c+1, c+1, c],
[grid_size-1-r, grid_size-1-r, grid_size-r, grid_size-r],
color, edgecolor='black', linewidth=2)
ax2.set_title('Agent Real-Time Position', fontsize=16)
ax2.set_aspect('equal') # 保证网格为正方形
ax2.set_xticks([]) # 隐藏坐标轴
ax2.set_yticks([])
agent_dot, = ax2.plot([], [], 'rs', markersize=15) # 红色方块表示智能体4. Q-Learning 核心训练逻辑
这是整个代码的核心,实现 ε- 贪婪策略、Q 值更新、奖励记录和动态可视化:
print(f"开始训练(共{num_episodes}回合)")
for episode in range(num_episodes):
current_state = (0,0) # 每回合从起点(0,0)出发
prev_state = None # 记录上一位置(用于判断后退)
total_reward = 0 # 记录当前回合总奖励
# 探索率衰减:每回合更新,不低于最小值
current_epsilon = max(epsilon_min, epsilon * (epsilon_decay ** episode))
# 单回合训练:直到到达终点
while current_state != goal:
# 1. ε-贪婪策略选择动作
if random.uniform(0, 1) < current_epsilon:
action = random.choice(actions) # 探索:随机选动作
else:
# 利用:选择当前Q值最大的动作
action = np.argmax(Q[current_state[0], current_state[1]])
# 2. 执行动作,获取新状态
new_state = get_new_state(current_state, action)
# 3. 计算奖励(基础奖励+后退惩罚)
base_reward = rewards[new_state]
back_penalty = -5 if (prev_state is not None and new_state == prev_state) else 0
total_reward += base_reward + back_penalty
# 4. Q值更新(核心公式)
old_q = Q[current_state[0], current_state[1], action]
# 未来最优Q值:新状态下所有动作的最大Q值
best_future_q = np.max(Q[new_state[0], new_state[1]])
# Q-Learning更新公式:Q(s,a) = Q(s,a) + α[R + γ*maxQ(s',a') - Q(s,a)]
Q[current_state[0], current_state[1], action] = old_q + alpha * (
(base_reward + back_penalty) + gamma * best_future_q - old_q
)
# 5. 更新智能体位置可视化
x = new_state[1] + 0.5 # 格子中心x坐标
y = grid_size - 1 - new_state[0] + 0.5 # 格子中心y坐标
agent_dot.set_data([x], [y])
plt.pause(0.0001) # 快速刷新
# 6. 更新状态
prev_state = current_state
current_state = new_state
# 7. 记录并更新奖励曲线
reward_record.append(total_reward)
reward_line.set_data(range(episode+1), reward_record)
ax1.relim()
ax1.autoscale_view()
fig.canvas.draw()
# 8. 更新标题,显示训练进度
ax2.set_title(f'Episode {episode+1} | ε={current_epsilon:.3f}')
# 9. 每100回合打印一次平均奖励
if (episode+1) % 100 == 0:
avg_reward = np.mean(reward_record[-100:])
print(f"第{episode+1}回合 | 近100回合平均奖励:{avg_reward:.2f}")Q 值更新公式解析:
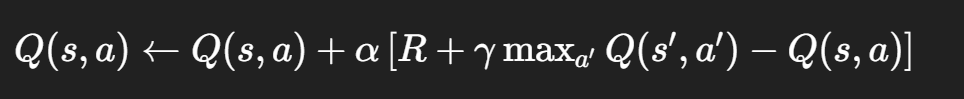
- R:执行动作后的即时奖励(基础奖励 + 后退惩罚)
- γmaxa′Q(s′,a′):新状态下能获得的最优未来奖励
- 整个公式的核心是 “时序差分误差”:R+γmaxQ(s′,a′)−Q(s,a),即当前估计值与实际值的差值
5. 训练结果可视化与输出
训练结束后,关闭交互式绘图,绘制最优路径并输出 Q 表结果:
# 关闭实时绘图
plt.ioff()
print("\n训练结束!绘制最优路径")
# 重新绘制网格,展示最优路径
ax2.clear()
# 重新绘制静态网格
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
color = 'yellow'
elif (r, c) in obstacle:
color = 'black'
else:
color = 'white'
ax2.fill([c, c+1, c+1, c],
[grid_size-1-r, grid_size-1-r, grid_size-r, grid_size-r],
color, edgecolor='black', linewidth=2)
# 计算最优路径:仅选择Q值最大的动作
optimal_path = []
current_state = (0, 0)
optimal_path.append(current_state)
while current_state != goal:
action = np.argmax(Q[current_state[0], current_state[1]])
current_state = get_new_state(current_state, action)
optimal_path.append(current_state)
# 绘制最优路径
x_path = [p[1] + 0.5 for p in optimal_path]
y_path = [grid_size - 1 - p[0] + 0.5 for p in optimal_path]
ax2.plot(x_path, y_path, 'r-', linewidth=3, marker='s', markersize=8, label='Optimal Path')
ax2.legend()
ax2.set_title('Optimal Path', fontsize=12)
ax2.set_aspect('equal')
ax2.set_xticks([])
ax2.set_yticks([])
# 输出Q表和最优路径
print("\n=== 训练结果 ===")
print("Q表(每个位置的4个动作Q值:[上、下、左、右]):")
for r in range(grid_size):
for c in range(grid_size):
if (r, c) in obstacle:
print(f"位置({r},{c}):障碍物")
elif (r, c) == goal:
print(f"位置({r},{c}):终点")
else:
q_scores = Q[r, c].round(2)
best_action = action_names[np.argmax(Q[r, c])]
print(f"位置({r},{c}):{q_scores} → 最优动作:{best_action}")
print(f"\n最优路径:{' → '.join([f'({r},{c})' for r, c in optimal_path])}")
# 绘制每100回合平均奖励曲线
plt.figure(figsize=(8, 5))
x_data = [i*100 for i in range(1, len(avg_reward_record)+1)]
plt.plot(x_data, avg_reward_record, 'b-o', linewidth=2, markersize=6)
plt.title('Average Reward per 100 Episodes', fontsize=14)
plt.xlabel('Training Episodes', fontsize=12)
plt.ylabel('Average Reward', fontsize=12)
plt.grid(True, alpha=0.3)
# 显示所有图表
plt.tight_layout()
plt.show()三、运行效果与关键结论
1. 训练过程
- 训练初期:智能体大量探索,奖励波动较大,路径随机
- 训练中期:探索率降低,智能体逐渐学会避开障碍物,奖励稳步上升
- 训练后期:智能体收敛到最优路径,奖励趋于稳定
2. 核心输出
- Q 表:每个非障碍 / 终点位置会输出 4 个动作的 Q 值,并标注最优动作
- 最优路径:智能体从 (0,0) 出发,避开 (1,1) 和 (0,2),到达 (2,2) 的最短路径
- 奖励曲线:平均奖励随训练回合数上升,验证算法收敛性
四、扩展与优化建议
- 参数调优:可尝试调整学习率(α=0.05~0.2)、折扣因子(γ=0.8~0.95)、探索率衰减系数,观察对收敛速度的影响
- 环境扩展:增加网格大小(如 5×5)、动态障碍物、多终点等复杂场景
- 算法优化:引入经验回放(Replay Buffer)、双 Q-Learning 等改进算法
- 可视化增强:增加 Q 值热力图、动作选择概率分布等
五、完整代码获取
本文所有代码均可直接复制运行:
import numpy as np
import random
import matplotlib.pyplot as plt
#初始化设置
#网格环境初始化
grid_size=3 #nxn网格
actions=[0, 1, 2, 3] #4个动作:0=上,1=下,2=左,3=右
obstacle=[(1,1),(0,2)] #障碍物设置
goal=(grid_size-1, grid_size-1) #终点设置
action_names=['上', '下', '左', '右']
#奖励矩阵初始化:
rewards=np.zeros((grid_size, grid_size))
#奖励规则设置
for r in range(grid_size):
for c in range(grid_size):
if (r, c)==goal:
rewards[r, c]=10
elif (r, c) in obstacle:
rewards[r, c]=-5
else:
l=((r-goal[0])**2+(c-goal[1])**2)**0.5
rewards[r, c]=-0.1*l
#Q表初始化
Q=np.zeros((grid_size, grid_size, len(actions)))
#参数设置
alpha=0.1 #学习率
gamma=0.9 #折扣因子
epsilon=0.2 #初始探索率
num_episodes=1000 #训练回合
epsilon_min=0.01 #探索率最低值
epsilon_decay=0.995 #每回合探索率降低0.001
#定义一个空间状态函数
def get_new_state(state, action):
r,c=state
if action==0:
return max(0, r-1), c
elif action==1:
return min(grid_size-1, r+1), c
elif action==2:
return r, max(0, c-1)
elif action==3:
return r, min(grid_size-1, c+1)
#可视化设置,进行绘图
plt.ion() #开启实时绘图
fig,(ax1, ax2)=plt.subplots(1, 2, figsize=(10,5)) #1行2列的图,左边用来绘制奖励函数,右边绘制运动轨迹
#左图:奖励值随训练次数的变化
reward_record=[] #记录每回合的总奖励
avg_reward_record=[] #记录每100次的奖励平均值
reward_line, = ax1.plot([], [], 'b-', linewidth=0.5) #在左图中用蓝色细线进行绘制
#设置第一个图的标题及横纵坐标
ax1.set_title('total_reward_per_round', fontsize=16)
ax1.set_xlabel('training_round')
ax1.set_ylabel('reward')
ax1.grid(True, alpha=0.3) #设置网格进行辅助
ax1.set_xlim(0, num_episodes) #设置x轴范围
ax1.set_ylim(-20, 20) #设置y轴范围
#右图:网格和智能体位置动图
#先画静态网格:
for r in range(grid_size):
for c in range(grid_size):
if (r, c)==goal:
color = 'yellow' #终点黄色
elif (r, c) in obstacle:
color = 'black' #障碍物黑色
else:
color = 'white' #普通格子白色
#画正方形格子
ax2.fill([c, c+1, c+1, c], [grid_size-1-r, grid_size-1-r, grid_size-r, grid_size-r],
color, edgecolor='black', linewidth=2)
ax2.set_title('Real-Time Location of Intelligent Agent', fontsize=16)
ax2.set_aspect('equal') #正方形网格
ax2.set_xticks([]) #隐藏坐标轴
ax2.set_yticks([])
agent_dot, = ax2.plot([], [], 'rs', markersize=15) #红色方框代表智能体
#进行循环训练
print(f"开始训练(共{num_episodes}回合)")
for episode in range(num_episodes):
current_state=(0,0) #每次从起点开始
prev_state=None #记录上一个位置,用于判断是否后退,如果后退就给负奖励
total_reward=0 #初始化总奖励,用于记录当前回合的总奖励
#贪婪策略:
#探索率衰减
current_epsilon=max(epsilon_min, epsilon * (epsilon_decay ** episode))
while current_state != goal:
if random.uniform(0, 1) < current_epsilon:
action = random.choice(actions) # 随机探索
else:
action = np.argmax(Q[current_state[0], current_state[1]]) #选Q值最高的动作
#执行动作,得到新位置
new_state = get_new_state(current_state, action)
#计算奖励:基础奖励+后退惩罚
base_reward = rewards[new_state] #格子本身的奖励(终点/障碍/距离奖励)
back_penalty = 0 #后退惩罚初始为0
#判断是否返回上一位置(prev_state不为None时才判断,避免起点误判)
if prev_state is not None and new_state==prev_state:
back_penalty=-5 #说明智能体返回上一步,进行扣分
total_reward += base_reward + back_penalty #累计总奖励
#更新Q表
#新Q值=旧Q值+学习率×(当前总奖励+未来最好分数-旧分数)
old_q = Q[current_state[0], current_state[1], action]
best_future_q = np.max(Q[new_state[0], new_state[1]]) #未来能拿到的最高Q值
Q[current_state[0], current_state[1], action] = old_q + alpha * ((base_reward + back_penalty) + gamma * best_future_q - old_q)
#更新动图中智能体位置
x = new_state[1] + 0.5 #列→x轴(加0.5是为了在格子中心)
y = grid_size - 1 - new_state[0] + 0.5 #行→y轴(网格坐标系转换)
agent_dot.set_data([x], [y])
#更新位置:当前位置变上一个位置,新位置变当前位置
prev_state = current_state
current_state = new_state
#快速刷新画面
plt.pause(0.0001)
#记录当前回合奖励,更新奖励曲线
reward_record.append(total_reward)
reward_line.set_data(range(episode+1), reward_record)
ax1.relim() #自动调整坐标轴
ax1.autoscale_view()
fig.canvas.draw()
#更新标题,显示当前进度
ax2.set_title(f'round{episode+1} | exploration rate{current_epsilon:.3f}')
# 每100回合打印一次进度
if (episode+1) % 100 == 0:
avg_reward = np.mean(reward_record[-100:])
print(f"第{episode+1}回合--平均奖励:{avg_reward:.2f}")
avg_reward_record.append(avg_reward) #将当前100回合平均奖励存入列表
plt.pause(0.001)
#训练结束,显示最优路径
plt.ioff() # 关闭实时绘图
print("\n训练结束!绘制最优路径")
#重新画网格,显示最优路径
ax2.clear()
for r in range(grid_size):
for c in range(grid_size):
if (r, c) == goal:
color = 'yellow'
elif (r, c) in obstacle:
color = 'black'
else:
color = 'white'
ax2.fill([c, c+1, c+1, c], [grid_size-1-r, grid_size-1-r, grid_size-r, grid_size-r],
color, edgecolor='black', linewidth=2)
#计算最优路径:只选Q值最高的动作
optimal_path=[]
current_state=(0, 0)
optimal_path.append(current_state)
while current_state != goal:
action = np.argmax(Q[current_state[0], current_state[1]])
current_state = get_new_state(current_state, action)
optimal_path.append(current_state)
#绘制最优路径:
x_path = [p[1] + 0.5 for p in optimal_path]
y_path = [grid_size - 1 - p[0] + 0.5 for p in optimal_path]
ax2.plot(x_path, y_path, 'r-', linewidth=3, marker='s', markersize=8, label='optimal path')
ax2.legend()
ax2.set_title('Optimal Path', fontsize=12)
ax2.set_aspect('equal')
ax2.set_xticks([])
ax2.set_yticks([])
#输出结果
print("\n学习结果如下:")
print("Q表(每个位置的4个动作Q值:[上、下、左、右]):")
for r in range(grid_size):
for c in range(grid_size):
if (r, c) in obstacle:
print(f"位置({r},{c}):障碍物")
elif (r, c) == goal:
print(f"位置({r},{c}):终点")
else:
q_scores = Q[r, c].round(2)
best_action = action_names[np.argmax(Q[r, c])]
print(f"位置({r},{c}):{q_scores} → 最优动作:{best_action}")
print(f"\n最优路径:{' → '.join([f'({r},{c})' for r, c in optimal_path])}")
#训练结束后弹出新窗口,绘制每100回合平均奖励曲线
plt.figure(figsize=(8, 5)) #新建窗口(独立于之前的双图窗口)
x_data = [i*100 for i in range(1, len(avg_reward_record)+1)] #x轴
plt.plot(x_data, avg_reward_record, 'b-o', linewidth=2, markersize=6)
plt.title('Average Reward per 100 Episodes', fontsize=14)
plt.xlabel('Training Episodes', fontsize=12)
plt.ylabel('Average Reward', fontsize=12)
plt.grid(True, alpha=0.3)
#显示最终图表
plt.tight_layout()
plt.show()总结
本文通过 3×3 网格路径规划案例,完整实现了 Q-Learning 算法的核心逻辑,包括环境构建、Q 表初始化、ε- 贪婪策略、Q 值更新和动态可视化。核心要点:
- Q-Learning 是无模型强化学习算法,通过迭代更新 Q 值逼近最优动作价值函数
- ε- 贪婪策略平衡探索与利用,是强化学习的核心策略
- Q 值更新公式是算法的核心,通过即时奖励 + 未来最优奖励修正当前 Q 值
- 动态可视化能直观展示算法的训练过程和收敛效果
通过这个案例,希望能帮助大家理解 Q-Learning 的核心原理。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 5
5 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)