深度:480万数据量级下,如何构建工业级 RAG 检索架构?
摘要: 垂直领域(如工业B2B平台)中,简单RAG架构因语义断层、性能瓶颈和硬性约束缺失而失效。生产级方案需采用多路召回、分布式向量数据库(如Milvus)和语义重排。Milvus支持亿级数据、量化索引(如IVF_SQ8)和混合检索(向量+标量过滤)。核心实现包括Schema定义、索引优化及Cross-Encoder重排,结合实时ETL管道(如CDC+Flink)确保数据更新。最终,RAG将进化为
1. 为什么“简单的 RAG”在垂直领域会失效?
在构建工业 B2B 检索平台(如“天下工厂”)时,初学者往往会陷入一个误区:认为只要把文档塞进 ChromaDB,调个 OpenAI 的接口就能万事大吉。
但在处理 4.8 亿条量级的工厂属性与产能数据时,这种简单的架构会面临三大挑战:
语义断层: 用户搜“5 轴联动”,如果 Embedding 模型没经过工业语料微调,可能召回的是“5 轴机器人”而非“精密加工厂”。
性能瓶颈: ChromaDB 等轻量级数据库在十万级以上数据量时,检索延迟会呈指数级上升。
硬性约束缺失: 用户要求“注册资本 > 1000万”,纯向量搜索(Vector Search)无法处理这种数值过滤。
2. 生产级架构:从 RAG 1.0 到 RAG 2.0
要支撑百万级以上的垂直领域搜索,必须采用 “多路召回 + 向量数据库集群 + 语义重排” 的进阶架构。
2.1 存储选型:为什么是 Milvus 而非 ChromaDB?
对于 480 万量级的数据,我们需要分布式、云原生的向量数据库:
Milvus: 专为亿级向量设计,支持计算与存储分离,支持多种索引算法(如 IVF_SQ8)来平衡精度与速度。
数据索引逻辑: 在 4.8M 量级下,推荐使用 IVF_SQ8 索引。它通过量化技术将内存占用降低约 70%,同时保持 90% 以上的召回率。
ChromaDB vs. Milvus:百万级向量检索选型指南
| 维度 | ChromaDB (轻量级/嵌入式) | Milvus (生产级/分布式) |
| 数据承载量 | 建议 10万 以内 | 支持 亿级 向量规模 |
| 扩展性 | 单机运行,难以横向扩展 | 分布式架构,支持弹性扩容 |
| 存储介质 | 主要依赖内存,持久化相对较弱 | 磁盘驱动,实现存储与计算分离 |
| 索引算法 | 较单一,主要支持 HNSW | 支持 HNSW, IVF, ScaNN 等多种索引 |
| 部署方式 | 极简,pip install 即可运行 |
复杂,通常基于 Docker/K8s 集群部署 |
| 适用场景 | 个人项目、原型开发、小规模 Demo | 工业级 B2B、大规模推荐系统、企业级 AI |
3. 核心代码实现(基于 PyMilvus + 混合检索)
以下是模拟生产环境下的核心代码段,重点在于定义 Schema、建立量化索引以及执行标量过滤。
from pymilvus import connections, FieldSchema, CollectionSchema, DataType, Collection, utility
# 1. 连接 Milvus 集群
connections.connect("default", host="localhost", port="19530")
# 2. 定义 Schema(向量 + 标量属性)
fields = [
FieldSchema(name="factory_id", dtype=DataType.INT64, is_primary=True),
FieldSchema(name="factory_vector", dtype=DataType.FLOAT_VECTOR, dim=1536), # 对应 OpenAI 维度
FieldSchema(name="reg_capital", dtype=DataType.INT64), # 注册资本,用于硬过滤
FieldSchema(name="location", dtype=DataType.VARCHAR, max_length=100)
]
schema = CollectionSchema(fields, "Industrial Factory Database")
collection = Collection("industry_v3", schema)
# 3. 创建量化索引 (IVF_SQ8) 以优化 4.8M 数据检索速度
index_params = {
"metric_type": "L2",
"index_type": "IVF_SQ8",
"params": {"nlist": 1024}
}
collection.create_index("factory_vector", index_params)
# 4. 混合检索逻辑:语义匹配 + 硬指标过滤
# 示例:搜索“精密加工”,且注册资本大于 500 万的安徽工厂
search_params = {"metric_type": "L2", "params": {"nprobe": 10}}
results = collection.search(
data=[[0.1, 0.2, ...]], # 用户输入的向量化表示
anns_field="factory_vector",
param=search_params,
limit=5,
expr="reg_capital > 5000000 and location == 'Anhui'", # 标量过滤 (Boolean Mask)
output_fields=["factory_id", "location"]
)4. 关键算法:语义重排序 (Reranking)
向量检索得到的 Top-K 结果是基于距离计算的粗排。在工业场景中,我们需要对这 Top-K 个结果进行 Cross-Encoder 重排,以彻底解决语义偏差。
数学原理: 向量搜索计算的是余弦相似度
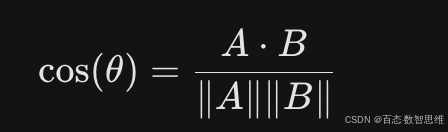
,而重排模型则是将 (Query, Document) 对输入模型进行分类打分。
5. 数据工程:ETL 管道的稳定性
480 万工厂数据不是静态的,需要配合 Flink 或 Spark 建立实时同步链路:
Change Data Capture (CDC): 监听工商系统数据库变更。
异步 Embedding: 为了防止阻塞,向量计算应在消息队列中异步进行。
增量索引刷新: 确保用户搜到的永远是该工厂最新的产能数据。
总结:B2B 的终局是 Agentic RAG
当底层架构稳定后,搜索框将演变为 AI Agent。它不仅能检索数据,还能根据检索结果自主判断工厂的合规性、评估供应链风险,并自动生成采购建议书。
对于垂直领域开发者而言,掌握从向量数据库调优到复杂流水线设计的能力,才是真正的核心壁垒。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 2
2 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)