多路转接epoll+Reactor反应堆
1. 多路转接poll接口
1.1 poll函数接口
1.函数接口
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// pollfd结构
struct pollfd {
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};
2.参数说明
(1) fds
- 指向
struct pollfd数组的指针,数组中每个元素对应一个待监听的文件描述符。 - 每个元素的核心逻辑:
fd:指定要监听的文件描述符;若fd = -1,则events会被忽略,revents始终为 0。events:你主动要求监听的事件(如读、写、异常),可通过宏组合(用|运算符)。revents:内核返回的实际发生的事件,只读,由内核根据文件描述符的状态填充。
(2) nfds
- 表示
fds数组的长度(待监听的文件描述符数量)。 - 类型
nfds_t是 Linux 系统定义的无符号整型(通常为unsigned int),定义在<poll.h>中。
(3) timeout
- 超时时间,单位为毫秒(ms),有三种取值:
timeout > 0:等待指定毫秒数,超时后无论是否有事件就绪,poll都会返回。timeout = 0:不阻塞,立即检查所有文件描述符的状态并返回。timeout = -1:无限阻塞,直到至少有一个文件描述符就绪才返回。
3.常用事件宏(events/revents 取值)
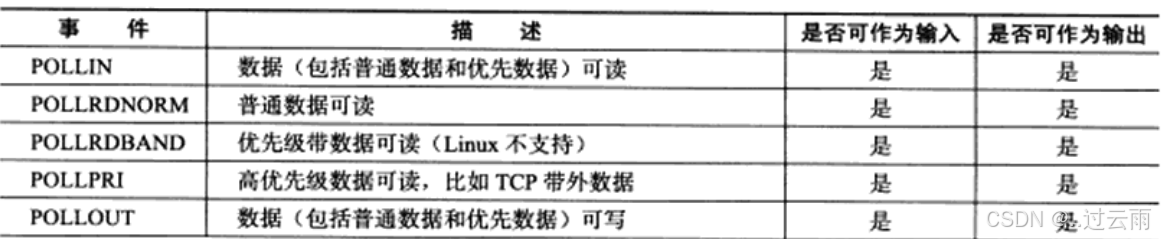

4.返回值说明(关键补充)
- 返回值 > 0:成功,返回就绪的文件描述符数量(
revents非 0 的 fd 数)。 - 返回值 = 0:超时,没有任何文件描述符就绪。
- 返回值 = -1:失败,同时设置
errno标识错误原因:EINTR:调用被信号中断;EINVAL:参数无效(如nfds超出范围);ENOMEM:内存不足,无法分配内核资源。
1.2 socket 就绪条件
poll 对 socket 文件描述符的就绪判定逻辑与 select 完全一致,核心分为读就绪、写就绪、异常就绪三类场景,具体如下:
(1)读就绪(对应 POLLIN 事件)
满足以下任一条件,socket 被判定为可读:
- socket 接收缓冲区中的数据字节数 ≥ 系统低水位标记(默认 1 字节),读操作不会阻塞;
- 监听态(listen)socket 有新的连接请求(accept 可立即返回);
- 对端关闭连接(收到 FIN 包),此时读操作会返回 0(无数据);
- socket 上有未处理的错误(可通过 getsockopt 获取错误码)。
(2)写就绪(对应 POLLOUT 事件)
满足以下任一条件,socket 被判定为可写:
- socket 发送缓冲区的可用空间 ≥ 系统低水位标记(默认 1 字节),写操作不会阻塞;
- socket 连接成功(非阻塞 connect 完成);
- socket 写端被关闭(如调用 shutdown (SHUT_WR)),此时写操作会触发 SIGPIPE 信号;
- socket 上有未处理的错误(可通过 getsockopt 获取错误码)。
(3)异常就绪(对应 POLLERR/POLLHUP/POLLNVAL)
这类事件无需手动设置到 events 中,由内核自动填充到 revents:
- POLLERR:socket 发生底层错误(如连接重置);
- POLLHUP:socket 连接被挂断(如对端主动关闭连接);
- POLLNVAL:socket 描述符无效(如未打开、已关闭)。
1.3 poll 的优点
poll 针对 select 的核心缺陷做了优化,同时简化了接口设计,具体优点如下:
-
接口设计更友好,无 “参数 - 值” 传递缺陷
select 使用
fd_set位图作为参数,该参数既是 “输入(要监听的事件)” 也是 “输出(就绪的事件)”,每次调用后需重新初始化;而 poll 通过pollfd结构体分离了events(输入,期望监听的事件)和revents(输出,实际发生的事件),无需每次重新设置监听事件,代码实现更简洁。 -
无文件描述符数量的硬限制
select 受限于
FD_SETSIZE(默认 1024),无法监听超过该值的文件描述符(需重新编译内核修改);而 poll 仅受限于系统可打开的最大文件描述符数(ulimit -n配置)和内存资源,无硬编码的数量上限(仅数量过大时性能会下降)。 -
事件管理更统一
select 需要维护读、写、异常三个独立的
fd_set集合,而 poll 仅需一个pollfd数组,每个元素对应一个描述符的监听 / 就绪事件,逻辑更清晰,代码可读性更高。
1.4 poll 的缺点
poll 并未解决 select 的核心性能瓶颈,当监听的文件描述符数量增多时,以下缺点会显著暴露:
-
轮询遍历的开销随描述符数量线性增长
poll 返回后,仅能告知 “就绪描述符的总数”,无法直接定位具体就绪的描述符,仍需遍历整个
pollfd数组,检查每个元素的revents是否非 0。监听的描述符越多,遍历的开销越大,性能线性下降。 -
用户态与内核态的拷贝开销大
每次调用 poll 时,需将整个
pollfd数组(包含所有监听的描述符信息)从用户态拷贝到内核态;poll 返回时,内核又需将revents信息拷贝回用户态。描述符数量越多,拷贝的数据量越大,系统开销越高。 -
水平触发(LT)的潜在低效
poll 仅支持水平触发(默认):若某个描述符就绪但未被处理,后续每次调用 poll 都会重复标记该描述符为就绪,可能导致不必要的轮询和处理逻辑(需业务层自行控制)。
-
无本质的性能优化
即使只有少量描述符就绪,poll 仍需处理所有监听的描述符(拷贝 + 遍历),随着监听数量增长,效率线性降低 —— 这是 poll 和 select 共同的核心缺陷。
1.5 总结
- poll 的 socket 就绪条件与 select 完全一致,核心分为读就绪、写就绪、异常就绪三类场景,是判定描述符是否可操作的核心依据。
- poll 的核心优势是接口设计更友好(分离输入输出事件)、无文件描述符数量的硬限制,解决了 select 的关键痛点。
- poll 未解决 select 的核心性能缺陷:描述符数量增多时,用户态 - 内核态拷贝、轮询遍历的开销均线性增长,性能下降明显。
1.6 poll示例: 使用poll监控标准输入
#include <poll.h>
#include <unistd.h>
#include <stdio.h>
int main() {
struct pollfd poll_fd;
poll_fd.fd = 0;
poll_fd.events = POLLIN;
for (;;) {
int ret = poll(&poll_fd, 1, 1000);
if (ret < 0) {
perror("poll");
continue;
}
if (ret == 0) {
printf("poll timeout\n");
continue;
}
if (poll_fd.revents == POLLIN) {
char buf[1024] = {0};
read(0, buf, sizeof(buf) - 1);
printf("stdin:%s", buf);
}
}
}
2. I/O多路转接之epoll
2.1 epoll 初识
根据 Linux 官方手册页(man 7 epoll)的定义:epoll 是为处理大批量文件描述符(file descriptors) 而设计的改进型多路 I/O 复用接口,是 poll 的增强版本(原文核心表述:An enhanced I/O event notification mechanism for Linux, designed to replace poll(2) for large numbers of file descriptors)。
epoll 并非简单的函数新增,而是一套完整的多路 I/O 复用机制,其首次以实验性特性出现在 Linux 内核 2.5.44 版本中(官方描述:epoll(4) is a new API introduced in Linux kernel 2.5.44),并在 Linux 2.6.0 正式版内核中被纳入稳定分支,成为生产环境可直接使用的系统调用。
相较于 select/poll,epoll 从底层设计上解决了二者的核心性能瓶颈(如无文件描述符数量硬限制、无需全量拷贝 / 遍历),几乎具备了多路 I/O 复用所需的全部优势,因此被公认为 Linux 2.6 及以上内核版本中性能最优的多路 I/O 就绪通知机制,也是 Nginx、Redis、Memcached 等高性能网络组件的核心底层依赖。
2.2 epoll的相关系统调用
epoll 提供了 3 个核心系统调用,构成一套完整的 “创建实例 - 注册事件 - 等待就绪” 的多路 I/O 复用流程,所有接口均需包含头文件 <sys/epoll.h>。
1. epoll_create(创建 epoll 实例)
#include <sys/epoll.h>
int epoll_create(int size);
// 现代推荐用法(Linux 2.6.27+)
int epoll_create1(int flags);
核心说明:
- 功能:创建一个 epoll 实例(句柄),内核会为该实例分配一块内核空间(红黑树 + 就绪链表),用于管理待监听的文件描述符和就绪事件。
- 参数
size:- 从 Linux 2.6.8 版本开始,
size参数仅作为内核的提示值(被忽略),不再限制 epoll 能监听的文件描述符数量; - 该参数必须传入一个大于 0 的整数(仅为兼容旧版本),实际监听数量由系统可打开的最大文件描述符数(
ulimit -n)决定。
- 从 Linux 2.6.8 版本开始,
- 现代推荐用法:
epoll_create1(EPOLL_CLOEXEC),EPOLL_CLOEXEC表示进程执行exec时自动关闭该 epoll 句柄,避免资源泄漏。 - 返回值:成功返回 epoll 实例的文件描述符(非负整数);失败返回 -1,并设置
errno(如ENOMEM表示内存不足)。 - 注意:epoll 实例用完后必须调用
close()关闭,否则会导致内核资源泄漏。
2. epoll_ctl(事件注册 / 修改 / 删除)
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event);
核心说明:
- 功能:向 epoll 实例(
epfd)中注册、修改或删除待监听的文件描述符(fd)及其事件类型,是 epoll 与 select/poll 的核心区别(select/poll 是 “监听时告知内核”,epoll 是 “提前注册”)。 - 参数详解:
epfd:epoll_create()/epoll_create1()返回的 epoll 实例句柄;op:表示对fd的操作类型,仅支持以下 3 个宏:EPOLL_CTL_ADD:向 epoll 实例中新增一个待监听的文件描述符fd;EPOLL_CTL_MOD:修改已注册的fd的监听事件类型;EPOLL_CTL_DEL:从 epoll 实例中删除fd(此时event参数可传NULL);
fd:需要监听的目标文件描述符(如 socket fd);event:指向struct epoll_event的指针,用于定义监听的事件类型及附加数据(不可为 NULL,除非op=EPOLL_CTL_DEL)。
struct epoll_event 完整定义:
typedef union epoll_data {
void *ptr; // 自定义指针,可指向任意用户数据
int fd; // 待监听的文件描述符(最常用)
uint32_t u32; // 32位无符号整数
uint64_t u64; // 64位无符号整数
} epoll_data_t;
struct epoll_event {
uint32_t events; // 监听的事件集合(位掩码)
epoll_data_t data; // 附加数据,用于标识就绪的文件描述符
};
events 事件宏(常用):
| 宏定义 | 核心含义 |
|---|---|
EPOLLIN |
对应 fd 可读(包括对端正常关闭连接、监听 socket 有新连接) |
EPOLLOUT |
对应 fd 可写(发送缓冲区有空闲空间) |
EPOLLPRI |
对应 fd 有紧急数据可读(如 TCP 带外数据) |
EPOLLERR |
fd 发生错误(无需手动注册,内核自动检测并返回) |
EPOLLHUP |
fd 被挂断(如对端关闭连接,无需手动注册) |
EPOLLET |
将 fd 的监听模式设为边缘触发(ET)(默认是水平触发 LT) |
EPOLLONESHOT |
仅监听一次事件,事件触发后 fd 会被自动禁用,需重新调用 epoll_ctl 启用 |
- 返回值:成功返回 0;失败返回 -1,并设置
errno(如EBADF表示 fd 无效,EEXIST表示重复添加 fd)。
3. epoll_wait(等待事件就绪)
int epoll_wait(int epfd, struct epoll_event *events, int maxevents, int timeout);
核心说明:
- 功能:等待 epoll 实例(
epfd)中监听的文件描述符发生就绪事件,收集并返回已就绪的事件。 - 参数详解:
epfd:epoll 实例句柄;events:用户态预先分配的struct epoll_event数组指针(不可为空),内核会将就绪的事件复制到该数组中;maxevents:告知内核events数组的最大长度(必须大于 0),该值与epoll_create()的size无任何关联;timeout:超时时间(单位:毫秒):timeout = -1:永久阻塞,直到至少有一个事件就绪;timeout = 0:立即返回,不阻塞;timeout > 0:阻塞指定毫秒数,超时后返回(即使无就绪事件)。
- 返回值:
- 成功:返回就绪的文件描述符数量(≥0);
- 返回 0:超时,无就绪事件;
- 失败:返回 -1,并设置
errno(如EINTR表示被信号中断,EINVAL表示参数无效)。
关键注意:
epoll_wait仅返回就绪的事件,无需遍历所有监听的 fd,这是 epoll 性能优于 select/poll 的核心原因;- 内核仅将就绪事件复制到
events数组,不会为用户态分配内存,因此需提前分配好数组空间。
总结
- epoll 包含
epoll_create(创建实例)、epoll_ctl(注册 / 修改 / 删除事件)、epoll_wait(等待就绪事件)三个核心调用,形成 “提前注册、按需返回” 的高效流程。 - 核心修正点:
epoll_wait的maxevents与epoll_create的size无关,size仅为旧版本兼容参数;epoll_ctl的EPOLL_CTL_DEL操作中event可传 NULL。 - epoll 性能优势的核心:仅返回就绪事件、无需全量拷贝监听集合、无文件描述符数量硬限制,且支持 ET(边缘触发)和 EPOLLONESHOT 等高级特性。
2.3 epoll 工作原理
epoll 的高性能源于其底层设计的革新,核心优势可与 select/poll 的缺点一一对应,具体原理如下:
(1)接口设计更高效
epoll 将 “事件注册” 与 “等待就绪” 拆分为 epoll_ctl 和 epoll_wait 两个独立调用,而非像 select/poll 那样在每次等待时重复指定监听事件:
- 只需通过
epoll_ctl一次性注册(或修改 / 删除)待监听的文件描述符和事件类型; epoll_wait仅负责收集就绪事件,输入输出参数分离,无需每次循环重置监听条件,使用更简洁。
(2)数据拷贝开销极小
select/poll 每次调用都需将完整的监听集合从用户态拷贝到内核态;而 epoll 仅在调用 epoll_ctl(注册 / 修改 / 删除)时,将文件描述符的事件信息拷贝到内核态,后续多次调用 epoll_wait 无需重复拷贝 —— 仅当事件就绪时,内核才将少量 “就绪事件信息” 拷贝回用户态,大幅减少拷贝开销。
(3)事件通知采用回调机制(核心性能优势)
select/poll 采用 “轮询遍历” 所有监听的文件描述符来判断就绪状态(时间复杂度 O(n));而 epoll 在内核中维护两个核心结构:
- 红黑树:存储所有通过
epoll_ctl注册的文件描述符和监听事件(增删改查效率为 O(logn)); - 就绪链表:内核为每个注册的 fd 绑定回调函数,当 fd 就绪时,回调函数会自动将该 fd 的事件加入就绪链表。
epoll_wait 只需直接读取就绪链表即可获取所有就绪事件(时间复杂度 O(1)),无需遍历全部监听 fd,即使监听的 fd 数量极多,效率也不会线性下降。
(4)无文件描述符数量硬限制
epoll 仅受限于系统可打开的最大文件描述符数(ulimit -n 配置),而非 select 那样的 FD_SETSIZE(默认 1024)硬限制,可支持上万甚至十万级别的 fd 监听。
关于 “内存映射(mmap)” 的澄清
网上部分博客称 “epoll 通过 mmap 映射就绪链表到用户态,避免内存拷贝”—— 该说法不准确:
- 内核的就绪事件最终仍需拷贝到用户态预先分配的
epoll_event数组中(无法省略); - epoll 并未依赖 mmap 减少拷贝,而是通过 “仅在注册时拷贝、仅拷贝就绪事件” 的设计,从根本上降低了拷贝的频率和数据量。
2.4 epoll 工作方式
epoll 支持两种事件触发模式:水平触发(Level Triggered,LT)和边缘触发(Edge Triggered,ET),可通过 epoll_event 的 EPOLLET 标志切换(默认 LT)。
为便于理解,先举生活化示例:
你正在打游戏,妈妈做好饭喊你吃饭:
- 水平触发(LT):妈妈喊一次你没动,会继续喊第二次、第三次…… 直到你去吃饭(亲妈模式);
- 边缘触发(ET):妈妈只喊一次,你没动就不再管你(后妈模式)。
核心示例场景
假设:
- 将一个 TCP socket 加入 epoll 监听读事件;
- 对端向该 socket 写入 2KB 数据;
- 第一次调用
epoll_wait返回,提示 socket 读就绪; - 调用
read仅读取 1KB 数据,缓冲区剩余 1KB; - 再次调用
epoll_wait……
(1)水平触发(LT,默认模式)
- 核心逻辑:只要 fd 满足 “就绪条件”(如上例中缓冲区还有数据可读),每次调用
epoll_wait都会返回该 fd 的就绪事件; - 示例结果:第二次调用
epoll_wait仍会立刻返回,提示该 socket 读就绪,直到缓冲区数据被全部读取完毕; - 特性:对开发者友好,支持阻塞 / 非阻塞读写,即使未一次性处理完就绪数据,也会被重复提示,不易遗漏事件。
(2)边缘触发(ET,需手动设置 EPOLLET)
- 核心逻辑:仅在 fd 的 “就绪状态发生变化” 时触发一次事件(即 “从未就绪变为就绪” 的瞬间),后续即使就绪条件仍满足,也不会再提示;
- 示例结果:第二次调用
epoll_wait不会返回(因为缓冲区剩余数据未导致 “就绪状态变化”); - 关键特性:
- 必须立刻处理完所有就绪数据(否则会遗漏事件);
- 工程实践中必须将 fd 设置为非阻塞(若 fd 为阻塞模式,一次性读取 / 写入数据时可能因无数据 / 缓冲区满而阻塞,导致程序卡死);
- 仅支持非阻塞读写;
- 性能更高(
epoll_wait返回次数大幅减少),Nginx 等高性能中间件默认采用 ET 模式。
补充说明
select/poll 本质上仅支持 LT 模式;epoll 是唯一同时支持 LT 和 ET 的 Linux 多路 I/O 复用接口。
2.5 对比 LT 和 ET
| 维度 | 水平触发(LT) | 边缘触发(ET) |
|---|---|---|
| 触发时机 | 只要 fd 处于就绪状态,每次 epoll_wait 都触发 |
仅 fd 从 “未就绪→就绪” 时触发一次 |
| 数据处理要求 | 可分多次处理就绪数据,无需一次性处理完 | 必须一次性处理完所有就绪数据(否则遗漏事件) |
| 读写模式支持 | 支持阻塞 / 非阻塞 | 仅支持非阻塞(工程实践要求) |
| 开发成本 | 低,逻辑简单,不易出错 | 高,需处理 “循环读写” 避免数据遗漏 |
| 性能 | 若及时处理就绪事件,性能与 ET 基本一致 | 触发次数少,高并发下性能略优 |
核心结论
- ET 的 “高效” 源于触发次数少,但并非绝对优于 LT:若 LT 模式下能做到 “就绪事件立刻处理、一次性处理完”,其性能与 ET 无差异;
- ET 强逼开发者一次性处理完所有就绪数据,代价是代码复杂度提升(需循环调用
read/write直到返回EAGAIN/EWOULDBLOCK); - 典型场景:
- LT:适合新手开发、数据量小且处理逻辑简单的场景;
- ET:适合高并发、大流量场景(如 Nginx/Redis),追求极致性能。
关键补充(ET 与非阻塞的关联)
使用 ET 模式时,必须将 fd 设置为非阻塞,核心原因:
假设服务器需读取 10KB 数据,第一次 read 仅读取 3KB(缓冲区剩余 7KB),若 fd 为阻塞模式,再次调用 read 会因无新数据到达而阻塞,导致程序无法处理其他 fd 的事件;而非阻塞模式下,read 会返回 EAGAIN(表示 “当前无数据可读,可稍后再试”),程序可退出循环,继续处理其他事件。
总结
- epoll 高性能的核心是 “红黑树 + 就绪链表 + 回调机制”,仅拷贝就绪事件、无需轮询全部 fd,且无 fd 数量硬限制;
- epoll 默认 LT 模式(重复提示就绪事件,支持阻塞 / 非阻塞),ET 模式需手动开启(仅触发一次,必须配非阻塞 fd);
- LT 开发成本低、容错性高,ET 性能略优但代码复杂度高,二者性能差异的核心在于 “是否及时处理完就绪数据”。
2.6 理解ET模式和非阻塞文件描述符
使用 ET 模式的 epoll 时,必须将文件描述符(fd)设置为非阻塞模式—— 这并非 epoll 接口的强制要求(接口层面无报错),而是工程实践中的硬性要求,不这么做会导致程序卡死或数据永久遗漏。
核心问题场景(结合示例说明)
假设以下业务逻辑:
- 客户端向服务器发送 10KB 请求数据,需服务器读完 10KB 后才返回应答;
- 客户端未收到应答前,不会发送下一次请求;
- 服务器使用 ET 模式的 epoll 监听读事件,且 fd 为阻塞模式,每次调用
read仅读取 1KB 数据(或因信号中断等原因未读全)。
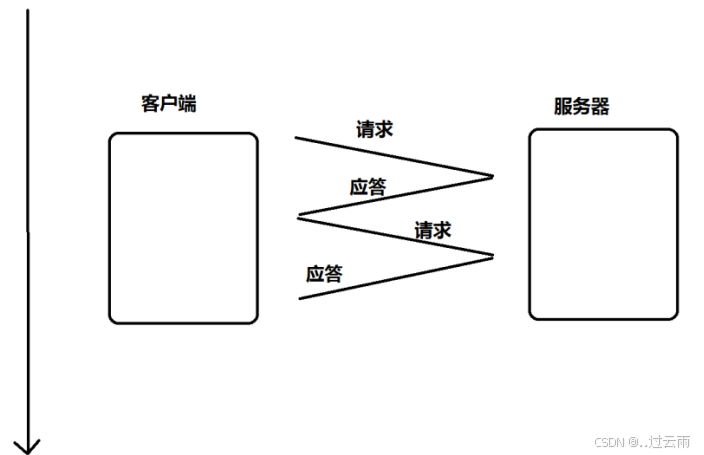
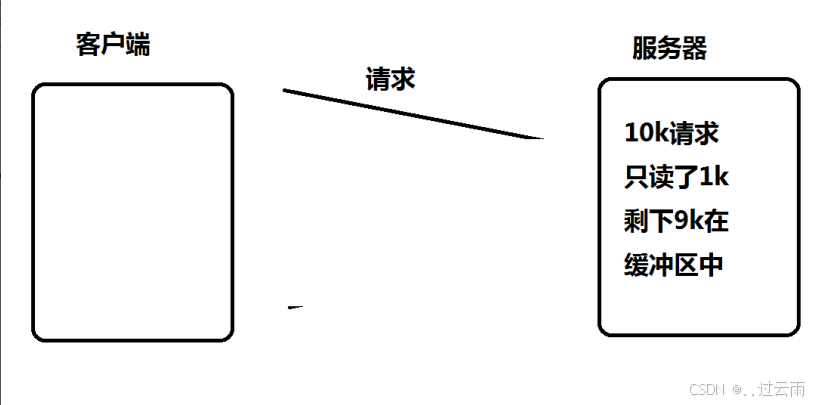
问题产生的完整逻辑链
- 客户端发送 10KB 数据,socket 缓冲区有数据,fd 从 “未就绪” 变为 “就绪”,epoll 触发读事件,
epoll_wait返回; - 服务器调用阻塞式
read读取 1KB 数据,缓冲区剩余 9KB 数据; - 由于是 ET 模式,fd 已处于 “就绪状态”(无状态变化),后续调用
epoll_wait不会再触发该 fd 的读事件; - 服务器需读完 10KB 才返回应答,但剩余 9KB 数据因无 epoll 事件触发,无法被读取;
- 客户端未收到应答,不会发送新数据,fd 永远不会再次触发读事件;
- 最终结果:缓冲区剩余的 9KB 数据永久滞留,服务器和客户端陷入 “互相等待” 的死锁。
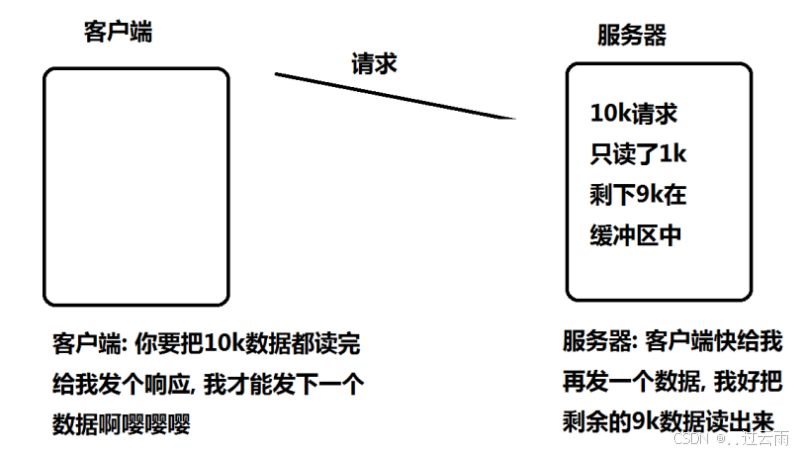
非阻塞 fd 的解决方案
将 fd 设置为非阻塞模式后,可通过循环轮询读取的方式解决上述问题:
- 当 epoll 触发读事件时,服务器以循环方式调用非阻塞
read; - 每次
read读取尽可能多的数据,直到read返回-1且errno = EAGAIN(或EWOULDBLOCK)—— 该错误表示 “当前缓冲区已无数据可读,需等待新数据”; - 此方式能确保一次性读完缓冲区中所有就绪数据(示例中 10KB 全部读取),避免数据滞留;
- 循环读取过程中,因 fd 是非阻塞的,
read不会卡死,仅会返回错误码,程序可正常退出循环处理其他事件。
LT 模式无此问题的原因
LT 模式下,只要缓冲区有未读取的数据(fd 处于就绪状态),每次调用 epoll_wait 都会触发读事件:
- 即使服务器用阻塞
read每次只读 1KB,下次epoll_wait仍会返回读事件,直到 10KB 数据全部读完; - 因此 LT 模式对 fd 类型无强制要求,支持阻塞 / 非阻塞读写,容错性更高。
工程实践补充
非阻塞 fd 的设置方法(以 socket 为例):
// 获取当前 fd 的状态
int flags = fcntl(fd, F_GETFL, 0);
// 添加非阻塞标志
fcntl(fd, F_SETFL, flags | O_NONBLOCK);
总结
- ET 模式必须使用非阻塞 fd:核心是避免 “数据未读全但 epoll 不再触发事件” 导致的数据滞留 / 程序死锁,需循环读取直到
EAGAIN; - 阻塞 fd 适配 ET 会引发死锁:ET 仅触发一次就绪事件,阻塞
read无法一次性读全数据时,剩余数据无事件触发读取; - LT 模式无需强制非阻塞:因就绪状态会重复触发事件,即使分多次读取也能保证数据被读完。
3. epoll的使用场景
epoll的高性能, 是有一定的特定场景的. 如果场景选择的不适宜, epoll的性能可能适得其反.
- 对于多连接, 且多连接中只有一部分连接比较活跃时, 比较适合使用epoll.
例如, 典型的一个需要处理上万个客户端的服务器, 例如各种互联网APP的入口服务器, 这样的服务器就很适合epoll.
如果只是系统内部, 服务器和服务器之间进行通信, 只有少数的几个连接, 这种情况下用epoll就并不合适. 具体要根据需求和场景特点来决定使用哪种IO模型.
4. Reactor反应堆详解
Reactor 模式是一种事件驱动的编程模式,用于高效地处理并发 I/O 操作。它通过一个或多个事件循环(Event Loop)来监听和处理各种事件(如网络请求、定时器事件等),从而实现高效的并发处理,而无需为每个连接创建一个线程或进程。

4.1 OneThreadOneLoop 多进程方案(修正 + 完善版)
One Thread One Loop(OTOL,单线程单事件循环)是一种基于事件驱动编程的架构设计模式,广泛应用于高性能异步 I/O 框架(如 Netty、libevent 等),核心是为每个线程绑定一个独立的事件循环,结合 I/O 多路复用技术实现高效并发处理。在多进程场景下,OTOL 模式可进一步扩展为 “单进程单事件循环”(One Process One Loop),充分利用多核 CPU 资源,同时规避多线程同步复杂度。
一、核心概念(修正 & 精准定义)
- 事件循环(Event Loop)
- 事件循环是异步 I/O 编程的核心调度单元,负责持续监听各类事件(如 I/O 就绪事件、定时器事件、信号事件等),并按事件类型触发预先注册的回调函数。
- 事件循环本身是单线程 / 单进程的串行执行模型,通过 I/O 多路复用技术(如 Linux 的 epoll、BSD 的 kqueue、Windows 的 IOCP),在单个线程 / 进程内高效管理数千甚至数万个并发 I/O 连接,避免了多线程上下文切换和锁竞争开销。
- 典型执行流程:
等待事件(epoll_wait)→ 处理就绪事件 → 执行回调 → 回到等待阶段,形成闭环。
- One Thread/Process One Loop 核心设计
- 基础形态(单线程):每个线程独立运行一个事件循环,循环内完成 “事件监听 - 回调执行” 的全流程,线程间无共享状态,避免多线程同步问题。
- 多进程扩展形态:每个进程独立运行一个事件循环(本质是 OTOL 的进程级实现),进程间通过操作系统隔离资源,天然避免竞争,同时利用多核 CPU 提升整体并发能力。
二、多进程扩展 OTOL 的核心要点(修正 & 补充)
基于单 Reactor(单事件循环)的服务端扩展为多进程 OTOL 方案时,核心需遵循以下原则:
-
单 Reactor 是多进程扩展的基础:
只要完成健壮的单 Reactor(单事件循环)实现(如基于 epoll 的 Reactor 模式),扩展多进程仅需在启动阶段 fork 子进程,每个子进程独立运行一个 Reactor 实例即可,核心逻辑无需大幅修改。
-
进程间 fd / 连接严格隔离,避免重复:
- 父进程创建监听 fd 后,通过
fork将监听 fd 继承给所有子进程,子进程均监听该 fd,但操作系统会通过 “惊群效应优化”(如 epoll 的 EPOLLEXCLUSIVE 标志)保证只有一个子进程被唤醒处理新连接; - 每个子进程 accept 新连接后,生成的客户端 fd 仅归当前进程所有,其他进程不可见;
- 进程间不共享任何 fd 和连接状态,fd 的生命周期(创建、注册、读写、关闭)完全由所属进程的 Reactor 管理,从根本上避免 fd 重复、资源竞争问题。
- 父进程创建监听 fd 后,通过
-
每个 Reactor 独立管理 fd 全生命周期,无 IO 穿插 / 乱序:
- 每个进程的 Reactor 实例独立负责自身监听 fd、客户端 fd 的注册、事件监听、读写回调和关闭操作,全程在本进程内串行执行;
- 由于进程隔离,不同 Reactor 的 IO 操作无穿插,数据读写不会出现乱序、竞争等问题,无需跨进程同步(如锁、信号量),保证 IO 处理的有序性和可靠性。
三、补充:多进程 OTOL 的优势(修正未提及的核心价值)
- 多核利用率:相比单进程 OTOL 仅利用单核 CPU,多进程 OTOL 可将不同 Reactor 分布在不同 CPU 核心,充分发挥多核性能;
- 故障隔离:单个进程异常崩溃不会影响其他进程,提升服务整体可用性;
- 简化编程:相比多线程 OTOL,多进程无需处理线程间同步(如互斥锁、条件变量),降低编程复杂度,避免死锁、数据竞争等问题。
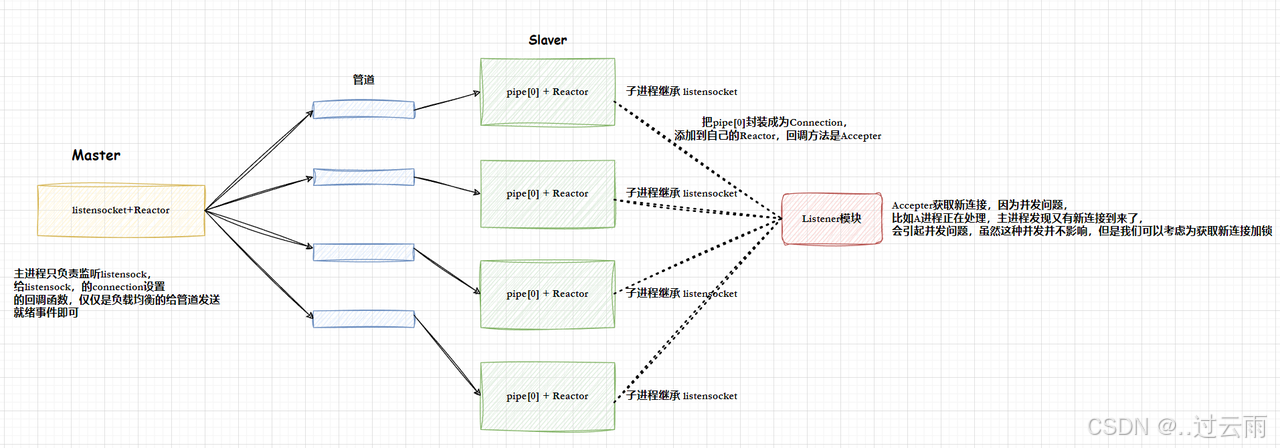
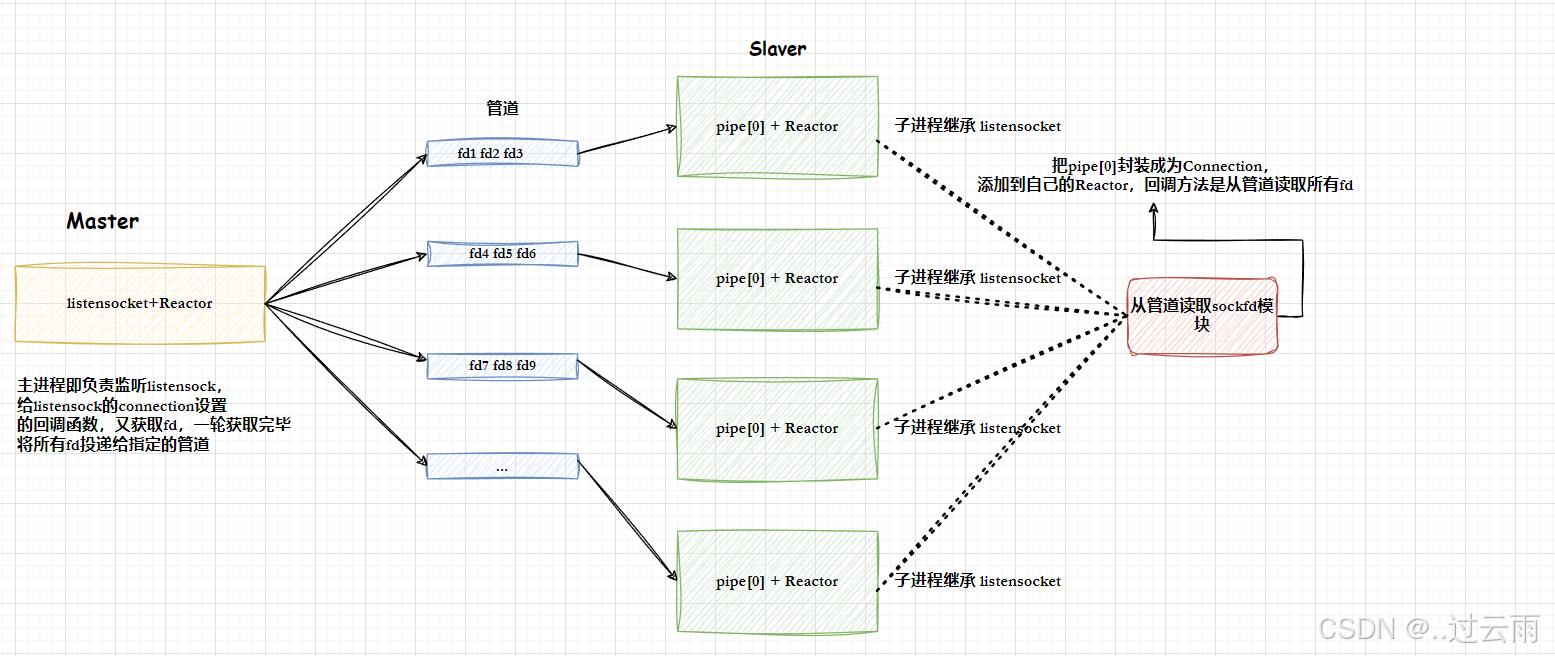
4.2 OneThreadOneLoop多线程方案1
🥇 另外:
多线程是可以共享文件fd的,如果我们把工作职责变一下(其实就是修改一下connection的回调方法),让master线程,检测并且直接accepter到新的连接fd列表,然后通过管道传递给每一个子进程,每个子进程拿到sockfd,直接添加到自己的Reactor中,进行IO处理就可以,这样做会更简单。
这样,读取管道内容,按照4字节读取,自动序列和反序列化。
如果不想使用管道,可以又其他做法。
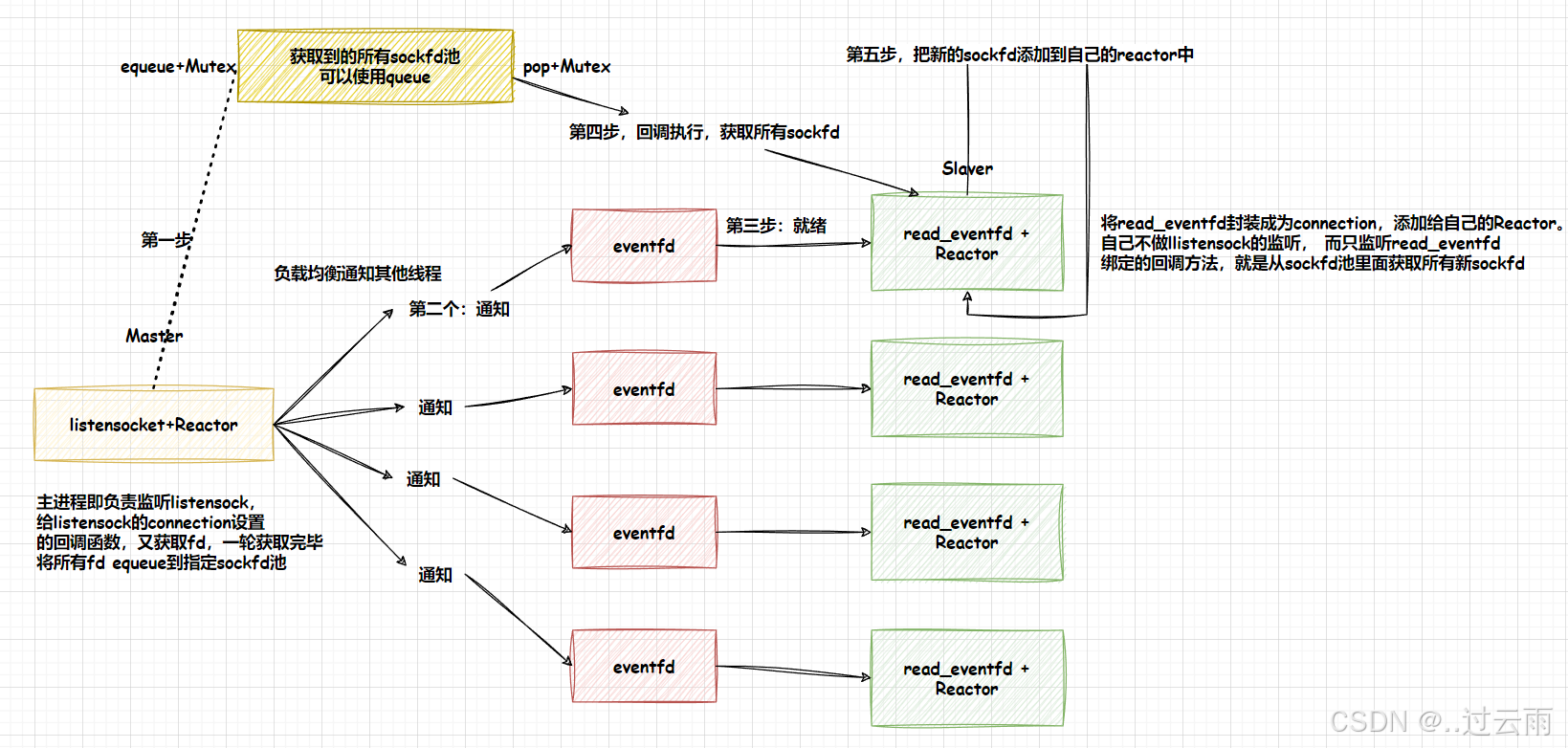
4.3 Eventfd 事件驱动(修正 + 完善版)
一、核心定位与替代价值
在事件驱动架构中,若不想使用管道作为事件通知的载体,可选择 eventfd 作为轻量级替代方案。
⚠️ 核心前提:事件驱动模型依赖 I/O 多路转接机制(如 epoll/poll/select),而多路转接的核心是对文件描述符(fd)的监听,这也是管道能作为事件驱动载体的根本原因;eventfd 本质是内核提供的、基于文件描述符的事件通知机制,完全适配多路转接的核心要求。
二、eventfd 基础特性
- 核心本质:
eventfd是 Linux 内核提供的轻量级事件通知机制,以文件描述符为操作入口,可直接整合到 epoll/poll/select 等 I/O 多路复用框架中。 - 核心数据结构:内核为每个
eventfd实例维护一个无符号 64 位计数器(初始值可指定):write操作:向计数器中累加数值(支持原子性追加);read操作:读取并修改计数器值(具体行为由工作模式决定)。
- 关键创建标志(补充说明):
EFD_CLOEXEC:创建eventfd时设置该标志,可确保文件描述符在调用exec()执行新程序时被自动关闭,避免无关进程继承无效 fd;EFD_NONBLOCK:非阻塞模式(建议必设),避免read/write操作因计数器状态阻塞;EFD_SEMAPHORE:信号量语义标志,决定read操作的计数器修改规则(详见工作模式)。
三、eventfd 核心特点(修正 & 精准化)
- 极低开销:内核仅需维护一个 64 位计数器,无复杂数据结构,创建和管理的内核开销远低于管道 / 套接字;
- 天然支持多路复用:
eventfd的 fd 可直接注册到 epoll/poll/select 中,当计数器非零时触发读事件,完美适配事件驱动模型; - 操作原子性:计数器的读写操作均为原子操作,无需额外加锁,适配高并发场景下的事件通知;
- 灵活的通知模式:支持一对一、一对多、多对多的事件通知(如多个进程 / 线程向同一个
eventfd写入,多个监听者感知事件),而非仅局限于点对点通信; - 高效性(对比管道):
- 避免管道的双向数据拷贝(管道需用户态 - 内核态 - 用户态拷贝),
eventfd仅操作内核计数器; - 无管道的 “空读 / 空写” 问题,事件触发逻辑更清晰,内核层面的调度开销更小。
- 避免管道的双向数据拷贝(管道需用户态 - 内核态 - 用户态拷贝),
四、eventfd 工作模式(修正 & 补充逻辑)
eventfd 的核心行为差异由 EFD_SEMAPHORE 标志决定,两种模式均仅影响 read 操作:
- 普通模式(默认,不设置 EFD_SEMAPHORE):
- 写入:向计数器累加任意 64 位无符号值;
- 读取:一次性读取并清空计数器的全部值(返回当前计数值,随后计数器置 0);
- 若计数器为 0 且未设
EFD_NONBLOCK,read会阻塞;设为非阻塞则直接返回-1并置errno=EAGAIN。
- 信号量模式(设置 EFD_SEMAPHORE):
- 写入:同普通模式,向计数器累加数值;
- 读取:每次仅从计数器中减 1(返回值固定为 1),计数器值同步减 1;
- 若计数器为 0,
read行为同普通模式(阻塞 / 非阻塞);该模式适配 “事件计数型” 通知(如每读取一次处理一个事件)。
五、注意事项(修正 & 补充实操建议)
- 用途限制:
eventfd仅用于 “事件发生的通知”,无法传递具体的消息内容(如字符串、结构体),需搭配其他方式(如共享内存)传递数据; - 非阻塞模式必设:生产环境建议始终设置
EFD_NONBLOCK,避免read/write因计数器状态阻塞,导致事件循环卡断; - 信号量语义场景:仅当需要 “按事件个数逐个处理”(如任务队列通知)时,才设置
EFD_SEMAPHORE,普通事件通知(如 “有任务待处理”)用默认模式即可; - 资源管理:
eventfd属于内核资源,使用完毕后必须调用close()关闭 fd,否则会导致 fd 泄漏; - 多路复用最佳实践:高并发场景下,
eventfd需结合 epoll(推荐 EPOLLET 边缘触发)使用,可最大化事件通知的效率,避免频繁轮询。
4.4 OneThreadOneLoop多线程方案2
5. Reactor反应堆模式(示例)
【免费】Linux网络-Reactor反应堆资源-CSDN下载
- main函数
- 开启日志,定义端口号
- 使用共享智能指针实例化
Cal网络计算器类对象cal,该类封装了加减乘除取模的核心计算逻辑;- 使用共享智能指针实例化
Protocol协议类对象protocol,构造时传入一个 lambda 计算函数:该函数接收Request类型的请求对象,调用cal的计算方法得到Response响应对象并返回;- 使用共享智能指针实例化
Connection基类类型的Listener派生类对象conn(Listener专用于监听并接收新连接);为conn调用RegisterHandler函数注册业务处理回调 lambda 函数:
- 该 lambda 函数捕获外部的
protocol对象,入参为客户端请求数据缓冲区inbuffer;- 函数内部通过
while循环持续调用protocol的Decode方法从inbuffer中解析完整的请求包:若解析失败(无完整包)则退出循环,解析成功则调用protocol的Execute方法执行计算并生成带协议头的响应数据;- 循环结束后汇总所有响应数据并返回;
- 使用独占智能指针实例化
Reactor反应堆核心对象R,负责事件驱动的 IO 管理;- 将
Listener类型的conn对象传入R->AddConnection方法,完成监听连接的注册(包括 epoll 内核事件注册、连接归属关系绑定、连接管理表维护);- 调用
R->Loop()启动反应堆事件循环,程序进入阻塞等待并处理 IO 事件的状态。
- R->AddConnection函数:添加连接、
AddConnection函数用于将Connection类型的连接对象(如Listener/Channel)纳入 Reactor 管理体系,核心流程:
- 校验:检查待添加连接的文件描述符(fd)是否已存在于 Reactor 的连接管理表中,若已存在则打印警告并返回,避免重复注册;
- 内核事件注册:从连接对象中获取其关心的事件(如
Listener的 EPOLLIN|EPOLLET),调用 epoll 接口将该 fd 与对应事件注册到 epoll 内核实例中;- 绑定归属关系:设置连接对象的回指指针,指向当前 Reactor 实例,便于连接后续操作 epoll / 管理连接;
- 连接管理:将连接对象存入 Reactor 的连接管理表(fd 为键,连接对象为值),完成连接的统一管理。
- Reactor.hpp中的Loop函数
Loop函数是 Reactor 的核心事件循环入口,负责持续监听并派发 IO 事件,核心流程:
- 前置校验:检查 Reactor 的连接管理表是否为空,若无任何连接则直接退出;若有连接则将运行状态标识
_isrunning置为 true,启动程序;- 主循环(持续至
_isrunning为 false):
- 打印连接状态:调用
PrintConnection()函数,遍历连接管理表并打印当前所有被管理的 fd,用于调试 / 状态可视化;- 等待事件:调用
LoopOnce()函数(内部封装 epoll_wait),传入超时时间(默认阻塞)等待 epoll 内核返回就绪事件,返回值n为就绪事件的数量;- 事件派发:调用
Dispatcher(int n)函数,以n为依据遍历所有就绪事件:
- 解析每个就绪事件的 fd 和事件类型(EPOLLIN/EPOLLOUT),并统一处理异常事件(将 EPOLLERR/EPOLLHUP 转化为 EPOLLIN|EPOLLOUT);
- 若为读事件(EPOLLIN):找到 fd 对应的连接对象,调用其
Recver()方法处理读事件(如Listener接收新连接、Channel读取客户端数据);- 若为写事件(EPOLLOUT):找到 fd 对应的连接对象,调用其
Sender()方法处理写事件(如Channel发送响应数据);- 循环结束:当
_isrunning置为 false 时退出循环,将运行状态标识重置为 false,结束事件循环。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 27
27 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)