告别 Ollama 慢推理!利用 RDK S100 BPU 算力自制 OpenAI API 接口并实战 Chatbox
本文提出了一种基于FastAPI的算力路由中间件,将边缘计算设备RDKS100的BPU硬件加速能力封装为标准化的OpenAI API接口。通过深入优化内存分配策略、设备树调整和性能模式设置,解决了嵌入式环境下的"内存墙"问题。系统采用异步子进程管理和零缓冲技术,实现了高效的流式响应。实验表明,该方案成功将本地BPU算力转化为云端服务能力,使标准客户端能直接调用边缘端的大模型推理
本项目实现了一套基于 FastAPI 的算力路由中间件。其核心逻辑并非简单的终端交互,而是构建了一个符合 OpenAI API 协议规范 的高性能推理后端。通过对底层 BPU 原生进程(xlm_demo)的 I/O 管道进行异步封装与流式转换,实现了将边缘端硬件加速能力向标准化应用接口的平滑映射。
理论:如何实现OpenAI API协议
第一章:硬件底座与“内存墙”的突破
1.1 RDK S100 架构概述
RDK S100 作为具身智能领域的高性能边缘计算节点,其核心竞争力在于集成了 Bernoulli2 架构的 BPU。该 BPU 专门针对神经网络中的矩阵运算进行了硬核优化,能够提供高达 80 TOPS 的 INT8 峰值算力。在部署大语言模型(LLM)时,BPU 的重要性不言而喻:它承担了模型中 99% 以上的张量计算任务。然而,高性能往往伴随着严苛的资源约束,LLM 的推理速度不仅取决于算力,更受限于内存带宽和物理空间的连续性。
1.2 内存分配的“特权陷阱”
在嵌入式 Linux 环境中,内存被划分为“通用内存”与“预留内存(CMA/ION)”两类,这种划分导致了典型的“双重内存”陷阱。
-
通用内存(General RAM):由 Linux 内核动态管理,类似于“公共草坪”。内核、Shell 进程以及常规的 Python 脚本均运行于此。用户通过
free -h查看到的可用空间大多属于此类,可以通过清理缓存(drop_caches)来回收。 -
预留内存(CMA/ION):为了保证 BPU 这种具备 DMA(直接内存访问)能力的硬件能以极高频率访问数据,系统在启动阶段必须强行划定一块“专属车位”。这块空间要求在物理地址上必须是完全连续的。
DeepSeek-R1-1.5B 的 HBM 模型在加载时,底层驱动会进行一次性大额内存申请。若系统默认预留空间不足(如仅 1GB),即使通用内存剩余 6GB,推理引擎也会因无法获得连续的物理页而触发 mKrun error。这种“有房住但不给车位”的现象是边缘端部署大模型最常见的物理屏障。
1.3 设备树(DTB)的手术级调整
为了打破物理配额限制,我们引入了 update_ion_dtb.sh 脚本进行底层配置修改。
-
反编译原理:脚本利用
dtc工具将二进制格式的.dtb(设备树二进制文件)还原为可阅读的.dts文本。设备树是 Linux 内核识别硬件资源的“户口本”,修改它意味着从基因层面重新分配 DDR 内存。 -
内存过户策略:通过选择
bpu_first模式,脚本精准定位到设备树中的ion-pool节点,将原本分配给 CPU 的闲置地址段强制“过户”给 BPU。此操作将 BPU 专属内存上限由 1GB 暴力拉升至 3.75GB,为模型运行提供了充足的物理温床。 -
安全性考量:由于修改 DTB 涉及系统引导的核心,任何语法错误都可能导致 eMMC 无法识别内核从而导致“黑屏”。因此,在修改前建立
.SUPER_SAFE级别的硬副本备份,是确保开发过程具备“后悔药”机制的关键策略。
第二章:推理引擎层:原生 BPU 点火
2.1 抛弃模拟:原生加速的逻辑
在嵌入式开发中,常见的 Ollama 或 llama.cpp 部署模式往往回退到 CPU 模拟指令集。在缺少高性能显卡的支持下,这种模式会导致推理速度呈“挤牙刷”状。为了追求极致的端侧响应,我们必须调用地瓜官方的 OpenExplorer LLM Runtime,实现硬件级的“物理输出”。
2.2 核心组件解析
-
HBM 模型(Horizon Binary Model):这是经过量化工具链处理后的二进制指令模型。它将 DeepSeek 的 FP16 权重压缩为 INT8 格式,虽然损失了极微小的精度,但换取了 4 倍以上的存储节省和数倍的计算加速。
-
xlm_demo:这是一个高度优化的 C++ 执行程序。它不通过软件层模拟计算,而是直接向 BPU 寄存器下达控制指令,指挥硬件电路进行大规模矩阵翻转。
-
动态库环境(HBRT):通过
export LD_LIBRARY_PATH挂载的libhb_dnn.so是系统与芯片沟通的桥梁。它负责将高级的算子逻辑翻译成 BPU 能听懂的底层电信号。
2.3 性能模式开启
通过执行 set_performance_mode.sh,系统会将 CPU 和 BPU 的变频策略锁定在最高频。在 LLM 推理的 Prefill(预填充)阶段,模型需要一次性处理大量 Prompt 内容,最高频锁定能有效避免因内核自动降频导致的推理掉帧和首字延迟(TTFT)过长的问题。
第三章:通信网关层:Python FastAPI 的桥接艺术
3.1 为什么需要“中间人”?
原生 xlm_demo 虽然强大,但其本质是一个封闭的、交互式的控制台程序。它无法直接收发 HTTP 请求,也无法被 Windows 端的前端软件识别。因此,我们需要构建一个 Python “翻译官”,将底层的 C++ 输出包装成现代化的 Web 服务。
3.2 异步子进程管理 (asyncio.subprocess)
在 Python 后端中,我们利用异步子进程技术实现了对 BPU 引擎的精准操控:
-
Stdin 管道模拟:由于该版本 demo 不支持命令行传参,Python 脚本通过标准输入(Stdin)管道,像真人打字一样将
user_prompt喂给进程,并紧跟exit指令确保推理后及时释放资源。 -
Stdout 实时捕获:利用异步读取机制,Python 能够不间断地监听 C++ 进程吐出的每一个字节,这为后续的流式显示奠定了数据基础。
3.3 解决“打字机”效果的关键:stdbuf
Linux 系统为了优化性能,会对进程间的管道传输进行 4KB 大小的缓冲。这意味着如果 DeepSeek 输出的内容不够多,它会“憋”在缓冲区里不出来,导致前端界面卡死。
-
stdbuf 方案:我们引入了
stdbuf -i0 -o0 -e0指令。 -
物理意义:该指令强行将 C 语言标准库的输出模式从“全缓冲”调整为“零缓冲”。这种“催吐”机制使得 BPU 产生的每一个 Token 都能跨越管道,瞬间通过 FastAPI 传向网络,实现了真正的打字机流式效果。
3.4 极致净化过滤逻辑
由于 BPU 进程启动时会伴随大量的驱动加载日志(如 [UCP], [DNN] 等)以及 Demo 自带的欢迎词,直接转发会导致 UI 界面充满乱码。
-
状态机设计:脚本内部维护了一个
is_reply_started的状态。 -
清洗逻辑:在匹配到模型真正的起始符
[Assistant] >>>之前,所有字符均被静默丢弃。同时,脚本会利用正则表达式剥离thinking标签和 ANSI 颜色代码,确保最终呈现在 Chatbox 上的内容符合人类阅读习惯且排版优美。
第四章:网络工程:跨系统互联与安全
4.1 监听配置与局域网拓扑
在 uvicorn.run 中将 host 设置为 0.0.0.0 具有重要的工程意义:它允许 RDK S100 同时在回环网卡(127.0.0.1)和物理网卡(192.168.137.x)上监听。这使得 Windows 宿主机能够通过 USB 或 Wi-Fi 建立的局域网,像访问云端 API 一样访问板载算力。
4.2 网络性能优化
在实际交互中,延迟(Latency)是影响体验的关键。对于嵌入式设备,我们优先建议使用 USB 虚拟网卡进行连接,其稳定性和带宽远超 2.4G Wi-Fi。通过配置静态 IP,可以避免每次重启板子后都需要修改 Chatbox 配置的繁琐过程。
第五章:前端集成:Chatbox 与具身交互
5.1 OpenAI 协议兼容性适配
Chatbox 的强大在于其对 OpenAI 标准协议的完美支持。我们的 Python 脚本通过伪造标准响应体(如 id, object: chat.completion.chunk),让 Chatbox 产生了一种“正在与硅谷云端服务器对话”的错觉,而实际上,所有的思考和计算都发生在你桌面上那块手掌大小的电路板上。
5.2 具身智能的中央处理器
这次实践的成功,标志着 RDK S100 已经具备了作为具身智能设备“中枢神经”的能力:
-
语义理解:DeepSeek 能够将模糊的人类语言解析为结构化的逻辑。
-
任务编排:通过 OpenClaw 这种 Agent 框架,模型输出的指令可以被实时转化为对底层 C++ 驱动的调用。例如,当用户说“帮我拿杯水”,API 会捕获到指令并触发机械臂控制代码执行。
实战:如何开始在chatbox中使用和释放资源?
6.1 在板子本地运行bpu_sever.py
import json
import os
import subprocess
import time
import asyncio
from fastapi import FastAPI, Request
from fastapi.responses import StreamingResponse
import uvicorn
app = FastAPI()
# 核心路径确认
RUNTIME_DIR = "/jinyl_dev/models/OpenExplorer_LLM_0.9.0/runtime"
XLM_BIN = "./bin/xlm_demo"
LIB_PATH = os.path.join(RUNTIME_DIR, "lib")
@app.post("/v1/chat/completions")
async def chat_completions(request: Request):
body = await request.json()
messages = body.get("messages", [])
# 提取 Prompt 并确保它是字符串
last_msg = messages[-1].get("content", "")
user_prompt = "".join([item.get("text", "") for item in last_msg]) if isinstance(last_msg, list) else last_msg
async def generate():
# 1. 物理清理
os.system("sudo pkill -9 xlm_demo > /dev/null 2>&1")
env = os.environ.copy()
env["LD_LIBRARY_PATH"] = f"{LIB_PATH}:{env.get('LD_LIBRARY_PATH', '')}"
# 2. 构造指令(移除不支持的 --prompt)
cmd_args = [
"stdbuf", "-i0", "-o0", "-e0",
XLM_BIN,
"--hbm_path", "/jinyl_dev/models/DeepSeek_R1_Distill_Qwen_1.5B_4096.hbm",
"--tokenizer_dir", os.path.join(RUNTIME_DIR, "config/DeepSeek_R1_Distill_Qwen_1.5B_config"),
"--template_path", os.path.join(RUNTIME_DIR, "config/DeepSeek_R1_Distill_Qwen_1.5B_config/DeepSeek_R1_Distill_Qwen_1.5B.jinja"),
"--model_type", "3"
]
# 3. 启动进程,必须开启 stdin=PIPE 才能喂数据
process = await asyncio.create_subprocess_exec(
cmd_args[0], *cmd_args[1:],
stdin=asyncio.subprocess.PIPE,
stdout=asyncio.subprocess.PIPE,
stderr=asyncio.subprocess.STDOUT,
env=env,
cwd=RUNTIME_DIR
)
# 4. 【关键】模拟人工输入:写入问题并回车,然后输入 exit 确保生成后进程关闭
input_data = f"{user_prompt}\nexit\n"
process.stdin.write(input_data.encode())
await process.stdin.drain()
print(f"🔥Answering the question: {user_prompt[:15]}")
is_reply_started = False
while True:
chunk_bytes = await process.stdout.read(16)
if not chunk_bytes: break
text = chunk_bytes.decode('utf-8', errors='ignore')
# 1. 只有看到 [Assistant] >>> 才开始真正转发给前端
if not is_reply_started:
if "[Assistant] >>>" in text:
is_reply_started = True
# 剥离起始符及其之前的杂质
text = text.split("[Assistant] >>>")[-1]
else:
continue
# 2. 移除模型输出中可能自带的特殊 Token 标签 (如 <|begin_of_sentence|>)
text = text.replace("<|begin▁ofsentence|>", "").replace("<|endofsentence|>", "")
# 3. 拦截性能统计和用户提示符,防止界面污染
if "Performance" in text or "[User]" in text:
break
if is_reply_started and text:
payload = {
"id": f"chat-{int(time.time())}",
"choices": [{"index": 0, "delta": {"content": text}}]
}
yield f"data: {json.dumps(payload)}\n\n"
yield "data: [DONE]\n\n"
return StreamingResponse(generate(), media_type="text/event-stream")
if __name__ == "__main__":
os.system(f"sudo sh {RUNTIME_DIR}/set_permorfance_mode.sh > /dev/null 2>&1")
uvicorn.run(app, host="0.0.0.0", port=8000)6.2进行chatbox端设置
既然你已经成功将 RDK S100 的 BPU 算力通过 FastAPI 封装成了符合 OpenAI 协议规范 的通用 API,那么在 Chatbox(或任何支持 OpenAI 协议的 AI 客户端)端进行配置就变得非常标准化了。
以下是实现 Windows 笔记本端 Chatbox 与 RDK S100 深度交互的详细配置指南:
1. 前置环境确认:网络链路打通
在配置 Chatbox 之前,必须确保 Windows 笔记本能够“看见”板子上的服务。
-
确认 IP 地址:在 RDK S100 终端输入
hostname -I或ip addr,确认板子在局域网(通常是 USB 网络192.168.137.100或 Wi-Fi)中的 IP。 -
物理联通测试:在 Windows 终端(PowerShell 或 CMD)输入:
ping 192.168.137.100//ping自己的电脑主机ip确保有数据包回显。
-
服务可用性测试:确保板子上的
bpu_sever.py正在运行。可以在 Windows 浏览器访问:http://192.168.137.100:8000/v1/models。如果能看到模型列表的 JSON 返回,说明 API 网关已完全开启。
2. Chatbox 详细配置步骤
Chatbox 是目前最流行的开源大模型客户端之一,其核心优势是支持“自定义 API 转发”。
步骤 A:进入设置界面
打开 Chatbox 客户端,点击左下角的 “设置 (Settings)” 图标。
步骤 B:配置模型提供者 (Model Provider)
在“模型提供者”下拉菜单中,虽然我们跑的是本地 BPU,但由于你实现了协议封装,请选择以下两种方式之一:
-
方式一(推荐):选择 “OpenAI”。
-
因为你的 FastAPI 接口路径完全对齐了 OpenAI 规范(
/v1/chat/completions)。
-
-
方式二:选择 “自定义 API (Custom API)”。
步骤 C:关键参数填写
-
API 地址 (Base URL):这是最重要的参数。
-
填写:
http://192.168.137.100:8000/v1 -
注意:末尾的
/v1必须带上,因为 Chatbox 会自动在后面拼接/chat/completions。
-
-
API 密钥 (API Key):
-
虽然你的本地服务器目前没有设置校验逻辑,但 Chatbox 不能为空。
-
填写:随意填写(例如
rdk-s100-bpu或sk-123)。
-
-
模型 ID (Model ID):
-
填写:
deepseek-r1:1.5b(需与你脚本中list_models返回的 ID 保持一致)。
-
步骤 D:开启流式传输 (Streaming)
-
勾选“流式输出 (Stream)”:
-
这是为了匹配你脚本中
StreamingResponse的逻辑。开启后,你可以看到 DeepSeek 的思考过程(<think>标签)像打字机一样逐字跳出,而不是死等进程结束。
-
3. 技术叙述:为什么这样配置就能通?
“Chatbox 并不直接与 RDK S100 的 BPU 驱动程序对话。它发送的是标准的 HTTP POST 请求,包含了一个 JSON 格式的 Prompt。我们的 FastAPI 服务扮演了‘中间协议桥梁’的角色:它截获这个请求,将其解包后通过输入流注入给底层的 C++ 进程(xlm_demo),再将硬件计算出的原始 Token 流封装成 SSE(Server-Sent Events)格式回传给 Chatbox。这种‘协议对齐’的思路,使得任何支持 OpenAI 格式的软件都能瞬间获得 BPU 的硬件加持。”
4. 常见问题排查 (Troubleshooting)
-
连接超时 (Timeout):
-
检查 Windows 防火墙:确保 Windows 没有拦截 8000 端口的入站连接。
-
检查监听 IP:确保 Python 脚本中使用的是
0.0.0.0而不是127.0.0.1。
-
-
报错 404:
-
通常是 Base URL 少写了
/v1。
-
-
回答瞬间结束或 Word Count 为 0:
-
检查板子终端输出,看是否触发了
mKrun error(内存不足)或unknown option报错。
-
6.3 如何实现资源回收
API Server 的优雅终止 (FastAPI):当你想要停止提供 API 服务时,通常在板子终端操作。
-
操作指令:在运行
bpu_sever.py的终端按下Ctrl + C。 -
内核动作:发送
SIGINT信号给 Python 进程。 -
回收逻辑:
-
Python 会停止监听 8000 端口。
-
关键点:你在代码中加入了
os.system("sudo pkill -9 xlm_demo")。虽然这是在启动前做的,但为了极致稳妥,建议在 Python 的退出勾子(Shutdown Hook)中也加入该指令,确保 API 停止时,正在运行的 BPU 进程也被强制杀死。
-
BPU 核心进程与内存回收 (核心步骤)
这是嵌入式开发中最容易被忽视的部分。RDK S100 的 BPU 采用 ION/CMA 预留内存。若程序异常崩溃,BPU 的硬件上下文(Context)可能仍驻留在预留空间中。
强制杀死残留进程
有时 xlm_demo 会由于异常输入进入死循环,导致 CPU/BPU 占用 100%。
# 强制终止所有推理二进制进程
sudo pkill -9 xlm_demo深度释放系统缓存
虽然 BPU 使用预留内存,但推理过程中会有大量的权重文件 IO 操作,这会产生海量的 pagecache。
# 同步磁盘数据并清理缓存 (这是你博客中提到的“强行清场”)
sudo sync && echo 3 | sudo tee /proc/sys/vm/drop_caches检查 ION 内存状态
回收后,建议通过以下指令确认 BPU 领地是否已经归还给系统:
# 查看 CMA/ION 剩余情况
cat /proc/meminfo | grep -i Cma6.4 实际效果演示图
板子终端效果: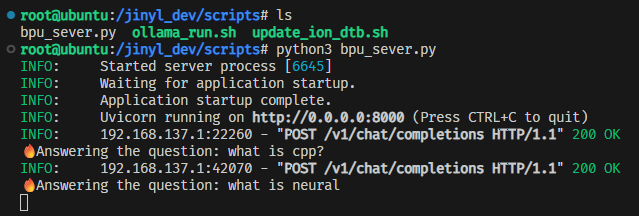
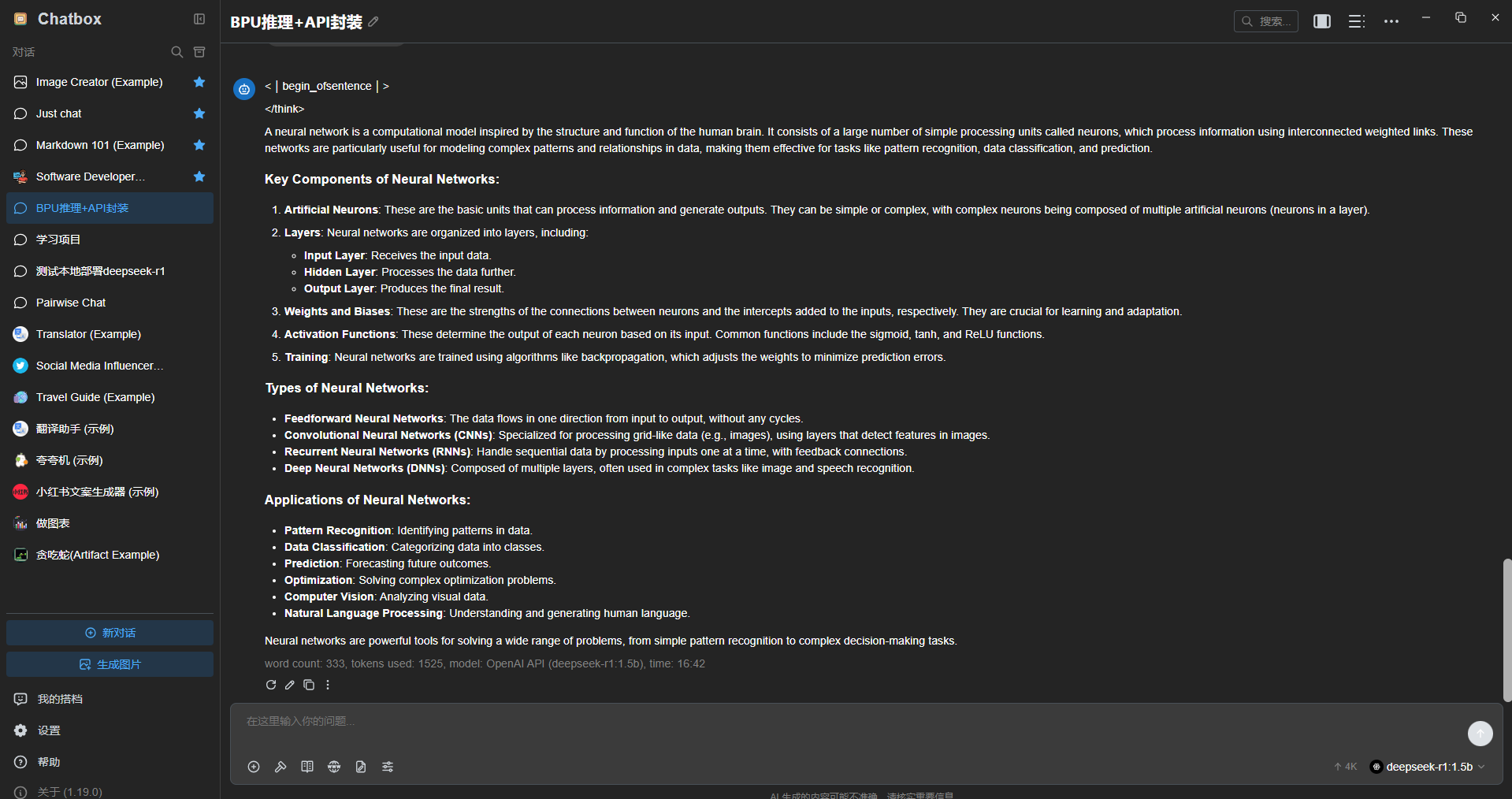
chatbox界面效果:
总结
你现在的配置实际上是把 RDK S100 变成了一个微型云服务商。Windows 上的 Chatbox 只是一个前端展示窗口,真正的“智力”源泉是那块正在疯狂进行矩阵运算的 BPU 芯片。
本期在板子上实现了openai的api封装,使得板子BPU跑的大模型可以通过api和其他应用进行交互了。并且我们实战接入任意端的chatbox进行交互演示。
下一期会讲解如何接入openclaw。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 25
25 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)