AI大模型:python手写汉字识别系统 汉字检测识别 卷积神经网络 CNN算法 OpenCV 计算机视觉 毕业设计(建议收藏)✅
AI大模型:python手写汉字识别系统 汉字检测识别 卷积神经网络 CNN算法 OpenCV 计算机视觉 毕业设计(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
Python语言、pyqt界面、卷积神经网络CNN算法、OpenCV、pyTorch、matplotlib、scikit-learn
1、手写汉字后,点击识别汉字,矩形框显示识别结果
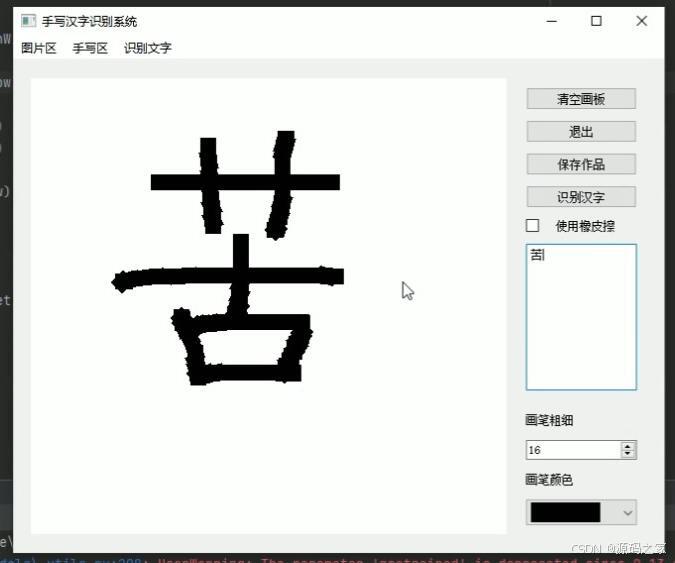
2、手写汉字后,可以清空画板、使用橡皮擦、选择画笔粗细、画笔颜色等等
2、项目界面
(1)手写汉字后,点击识别汉字,矩形框显示识别结果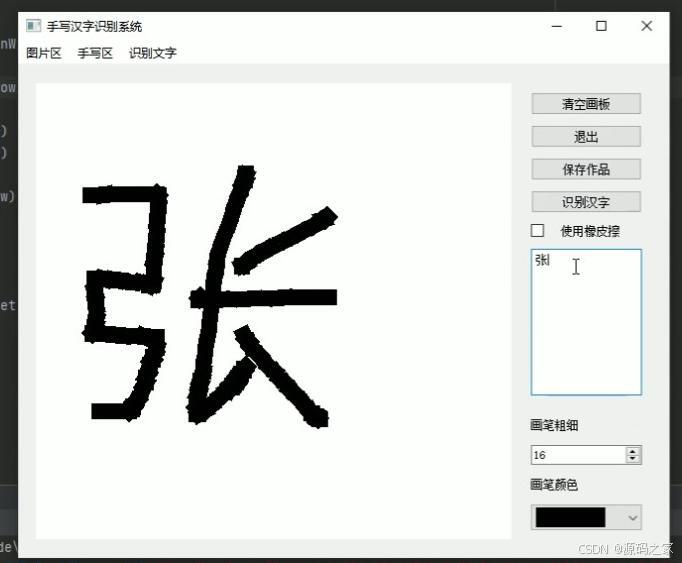
(1)手写汉字后,点击识别汉字,矩形框显示识别结果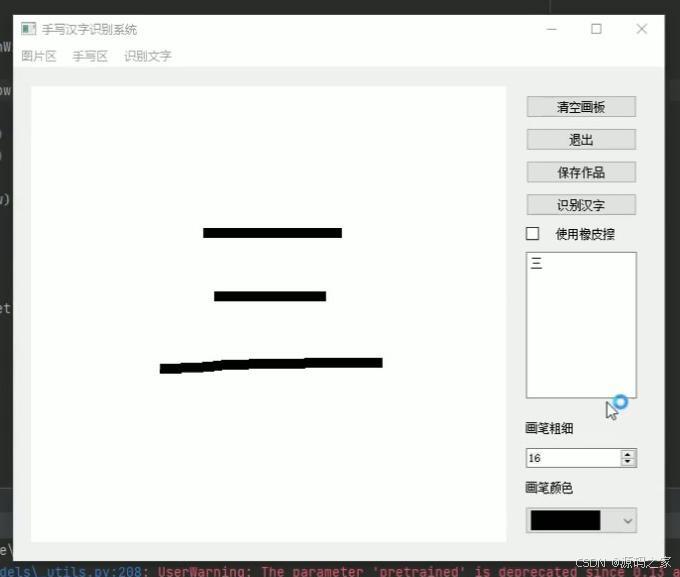
(1)手写汉字后,点击识别汉字,矩形框显示识别结果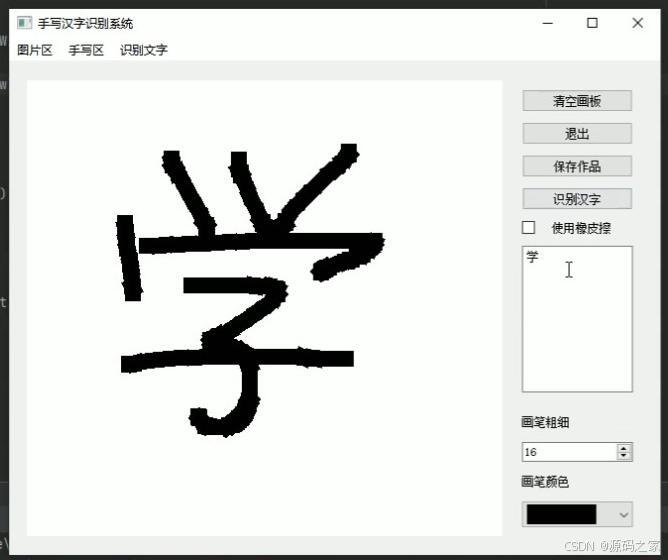
(4)上传文字图片后,点击灰度化、平滑、二值化、识别,即可显示识别的结果
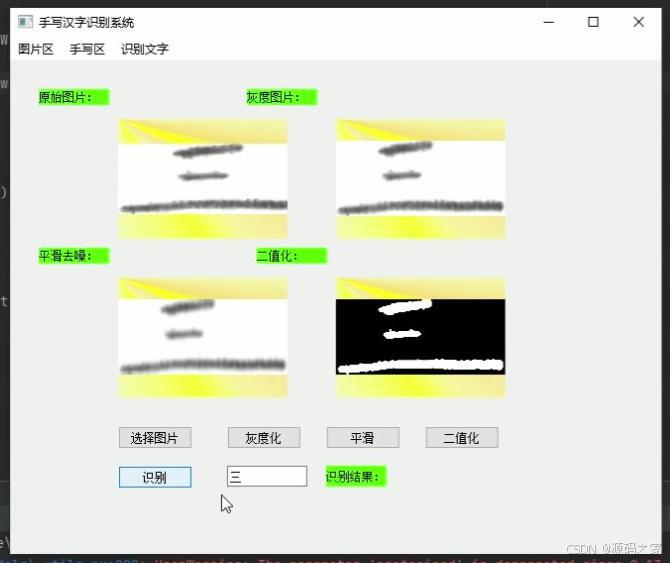
(5)上传文字图片后,点击灰度化、平滑、二值化、识别,即可显示识别的结果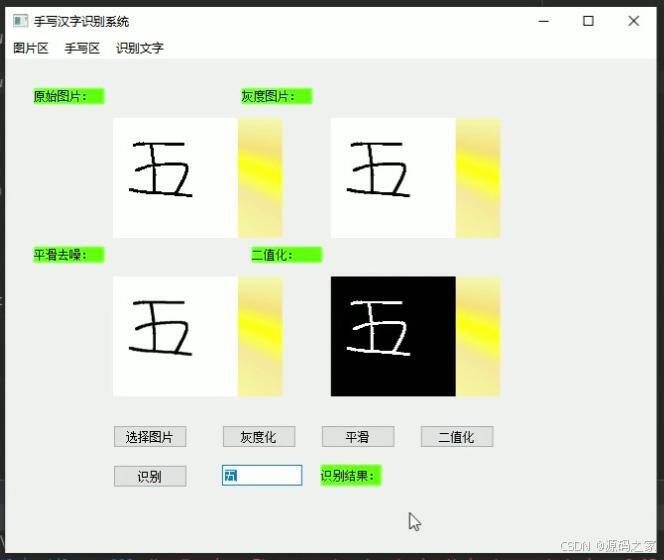
(6)手写汉字后,可以清空画板、使用橡皮擦、选择画笔粗细、画笔颜色等等
(7)识别文字模块:选择图片后,右侧矩形框显示识别结果
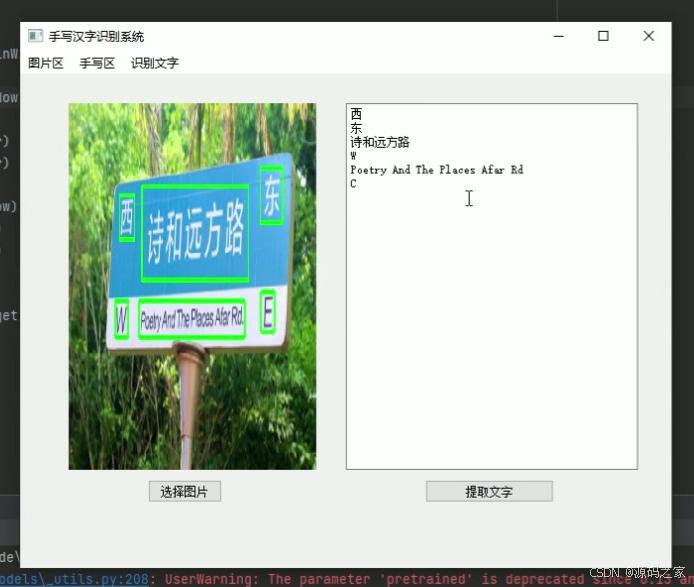
(8)识别文字模块:选择图片后,右侧矩形框显示识别结果
3、项目说明
本项目是面向汉字识别与深度学习应用开发的手写汉字识别系统,以 Python 为开发语言,核心集成 PyQt 可视化界面、卷积神经网络(CNN)算法、OpenCV 图像处理技术,搭配 PyTorch 深度学习框架、matplotlib 可视化库与 scikit-learn 辅助工具,构建 “手写绘制识别 + 图片导入识别” 双模式汉字识别平台,可应用于汉字学习辅助、手写笔记数字化、文档识别录入等场景,解决传统手写汉字人工识别效率低、数字化难的问题,兼具交互灵活性与识别准确性。
技术架构上,项目形成 “交互输入 - 图像处理 - 模型推理 - 结果展示” 的完整体系:PyQt 搭建直观交互界面,支持手写绘制、画笔参数调节(粗细 / 颜色)、橡皮擦与清空操作,满足用户个性化手写需求;OpenCV 负责图像预处理,对上传的文字图片执行灰度化、平滑去噪、二值化操作,优化图像质量以提升识别精度;CNN 算法作为核心识别模型,依托 PyTorch 框架训练优化,能深度提取汉字笔画、结构特征,实现手写与预处理后图片中汉字的精准识别;matplotlib 与 scikit-learn 辅助数据处理与结果可视化,确保识别流程稳定高效。
核心功能覆盖 “手写交互 - 图片处理 - 精准识别” 全场景:手写识别模式下,用户可在 PyQt 画板上手写汉字,点击 “识别” 后系统通过 CNN 模型推理,以矩形框标注识别结果,同时支持画笔粗细 / 颜色调整、橡皮擦修改、一键清空画板,操作灵活便捷;图片识别模式下,用户上传文字图片后,依次执行灰度化(降低色彩干扰)、平滑(去除噪声)、二值化(突出文字轮廓)预处理,再触发识别功能,系统快速输出汉字识别结果,适用于印刷体或手写体图片的批量识别需求。
系统界面布局清晰,功能分区明确(手写区、参数调节区、结果展示区),即使非技术用户也能快速上手。识别过程响应迅速,预处理步骤可直观观察图像变化,帮助用户理解识别原理。项目融合深度学习、图像处理与 GUI 开发技术,既展现了扎实的技术整合能力,又为汉字识别场景提供实用解决方案,是兼顾学习研究与实际应用的优质开发项目。
4、核心代码
import torch
from torchvision import models
import torch.nn as nn
import cv2
import numpy as np
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 加载resnet18模型
net = models.resnet18(pretrained=False)
# 修改第一层卷积层
net.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# 修改模型最后一层
net.fc = nn.Linear(in_features=512, out_features=1311, bias=True)
# 加载模型参数,参数反序列化为python dict
stadic = torch.load('logs/Epoch53-Loss0.0415_.pth') # 使用训练得到的模型参数
# 加载模型参数,加载训练好的参数
ne = net.load_state_dict(stadic)
# 将网络部署到设备上
net = net.to(device)
# model.eval() 负责改变batchnorm、dropout的工作方式,如在eval()模式下,dropout是不工作的
# eval()会把模型中的每个module的self.training设置为False
net.eval()
# 读取标签,一行一行读取
labs = open('characters.txt', 'r', encoding='utf-8').readlines()
# 预测函数,返回图片文字
def pre(src):
# 灰度化
# cv2.cvtColor(p1,p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
# cv2.COLOR_BGR2GRAY:灰度图像
img = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
# 进行二值化
# 选取全局阈值,将整幅图像分成二值图像。如果像素值大于阈值,则为其分配之歌值(可以是白色),否则为其分配另一个值
# 第一个是灰度图 第二个是给图像分类进行的阈值 第三个是最大值 小于0的赋值0,大于0的赋值255
# 就可以用第四个参数THRESH_OTSU,它对一幅双峰图像自动根据其直方图计算出合适的阈值
_, img = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)
img = 255 - img
# 缩放图像宽高到64
img = cv2.resize(img, (64, 64))
# 添加一个维度,并归一化
img = np.expand_dims(img, axis=0)/255
img = np.expand_dims(img, axis=0).astype('float32')
# 创建图片的张量
# 读取图片成numpy array的范围是[0,255]是uint8
# 而转成tensor的范围就是[0,1.0], 是float
img = torch.from_numpy(img)
# 将张量数据部署到设备上
img = img.to(device)
# 获取输出
# model(img):前向传播,就说是给网络输入一个样本向量,该样本向量的各元素,经过各隐藏层的逐级加权求和+非线性激活,最终由输出层输出一个预测向量的过程
# detach(): 阻断反传,直接输出预测结果
# cpu():将数据移至CPU中,返回值是tensor
# numpy():将tensor变量转为返回值为numpy,返回值为numpy.array()
# 为什么要把tensor转为numpy:因为tensor是专门为GPU加速设计的矩阵,而numpy却不行,其实就相当于一个为GPU设计的数据结构。
out = net(img).cpu().detach().numpy()
# 返回最大概率值的索引
out = np.argmax(out[0], axis=-1)
img= labs[out].strip()
return img
# 返回标签
if __name__ == '__main__':
img_path = lines[item].strip().split()[0] # item表示第几行
img_lab = lines[item].strip().split()[1] # 表示这一行图片的标签
img = cv2.imread(img_path)
path = 'train/00020/109472.png'
src = cv2.imread(path)
# 得到最大概率标签
label = pre(src)
# 返回标签对应图片
out = labs[label].strip()
print(out)
import torch
from torchvision import models
import torch.nn as nn
import cv2
import numpy as np
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
# 加载resnet18模型
net = models.resnet18(pretrained=False)
# 修改第一层卷积层
net.conv1 = nn.Conv2d(1, 64, kernel_size=(7, 7), stride=(2, 2), padding=(3, 3), bias=False)
# 修改模型最后一层
net.fc = nn.Linear(in_features=512, out_features=1311, bias=True)
# 加载模型参数,参数反序列化为python dict
stadic = torch.load('logs_handwrite/Epoch25-Loss0.0217_.pth') # 使用训练得到的模型参数
# 加载模型参数,加载训练好的参数
ne = net.load_state_dict(stadic)
# 将网络部署到设备上
net = net.to(device)
# model.eval() 负责改变batchnorm、dropout的工作方式,如在eval()模式下,dropout是不工作的
# eval()会把模型中的每个module的self.training设置为False
net.eval()
# 读取标签,一行一行读取
labs = open('handwrite.txt', 'r', encoding='utf-8').readlines()
# 预测函数
def pre_handwrite(src):
# 灰度化
# cv2.cvtColor(p1,p2) 是颜色空间转换函数,p1是需要转换的图片,p2是转换成何种格式。
# cv2.COLOR_BGR2GRAY:灰度图像
img = cv2.cvtColor(src, cv2.COLOR_BGR2GRAY)
# 进行二值化
# 选取全局阈值,将整幅图像分成二值图像。如果像素值大于阈值,则为其分配之歌值(可以是白色),否则为其分配另一个值
# 第一个是灰度图 第二个是给图像分类进行的阈值 第三个是最大值 小于0的赋值0,大于0的赋值255
# 就可以用第四个参数THRESH_OTSU,它对一幅双峰图像自动根据其直方图计算出合适的阈值
_, img = cv2.threshold(img, 0, 255, cv2.THRESH_OTSU)
img = 255 - img
# 缩放图像宽高到64
img = cv2.resize(img, (64, 64))
# 添加一个维度,并归一化
img = np.expand_dims(img, axis=0)/255
img = np.expand_dims(img, axis=0).astype('float32')
# 创建图片的张量
# 读取图片成numpy array的范围是[0,255]是uint8
# 而转成tensor的范围就是[0,1.0], 是float
img = torch.from_numpy(img)
# 将张量数据部署到设备上
img = img.to(device)
# 获取输出
# model(img):前向传播,就说是给网络输入一个样本向量,该样本向量的各元素,经过各隐藏层的逐级加权求和+非线性激活,最终由输出层输出一个预测向量的过程
# detach(): 阻断反传,直接输出预测结果
# cpu():将数据移至CPU中,返回值是tensor
# numpy():将tensor变量转为返回值为numpy,返回值为numpy.array()
# 为什么要把tensor转为numpy:因为tensor是专门为GPU加速设计的矩阵,而numpy却不行,其实就相当于一个为GPU设计的数据结构。
out = net(img).cpu().detach().numpy()
# 返回最大概率值的索引
out = np.argmax(out[0], axis=-1)
img = labs[out].strip()
return img
if __name__ == '__main__':
path = '1.png'
src = cv2.imread(path)
label = pre_handwrite(src)
# 最大概率值对应的字符串
out = labs[label].strip()
print(out)
5、项目获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 30
30 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)