AI大模型:基于 PaddleNLP+PaddleHub 的 Web 端多格式文本纠错系统(FastAPI+Vue+ElementUI)深度学习 计算机毕业设计(建议收藏)✅
AI大模型:基于 PaddleNLP+PaddleHub 的 Web 端多格式文本纠错系统(FastAPI+Vue+ElementUI)深度学习 计算机毕业设计(建议收藏)✅
·
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立工作室。专注于计算机相关专业项目实战6年之久,选择我们就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2025年计算机专业毕业设计选题汇总(建议收藏)✅
1、项目介绍
技术栈:
python语言、FastAPI、PaddleNLP + PaddleHub、Vue+ ElementUI前端、
基于Paddle的Web端多格式纠错系统,前后端分离式部署,支持文本、文档及图片的多格式智能纠错!
同时支持对修正的错误字进行标记提示和结果的保存。
后端:FastAPI + PaddleNLP + PaddleHub;
前端:Vue+ ElementUI。
2、项目界面
(1)纠错界面
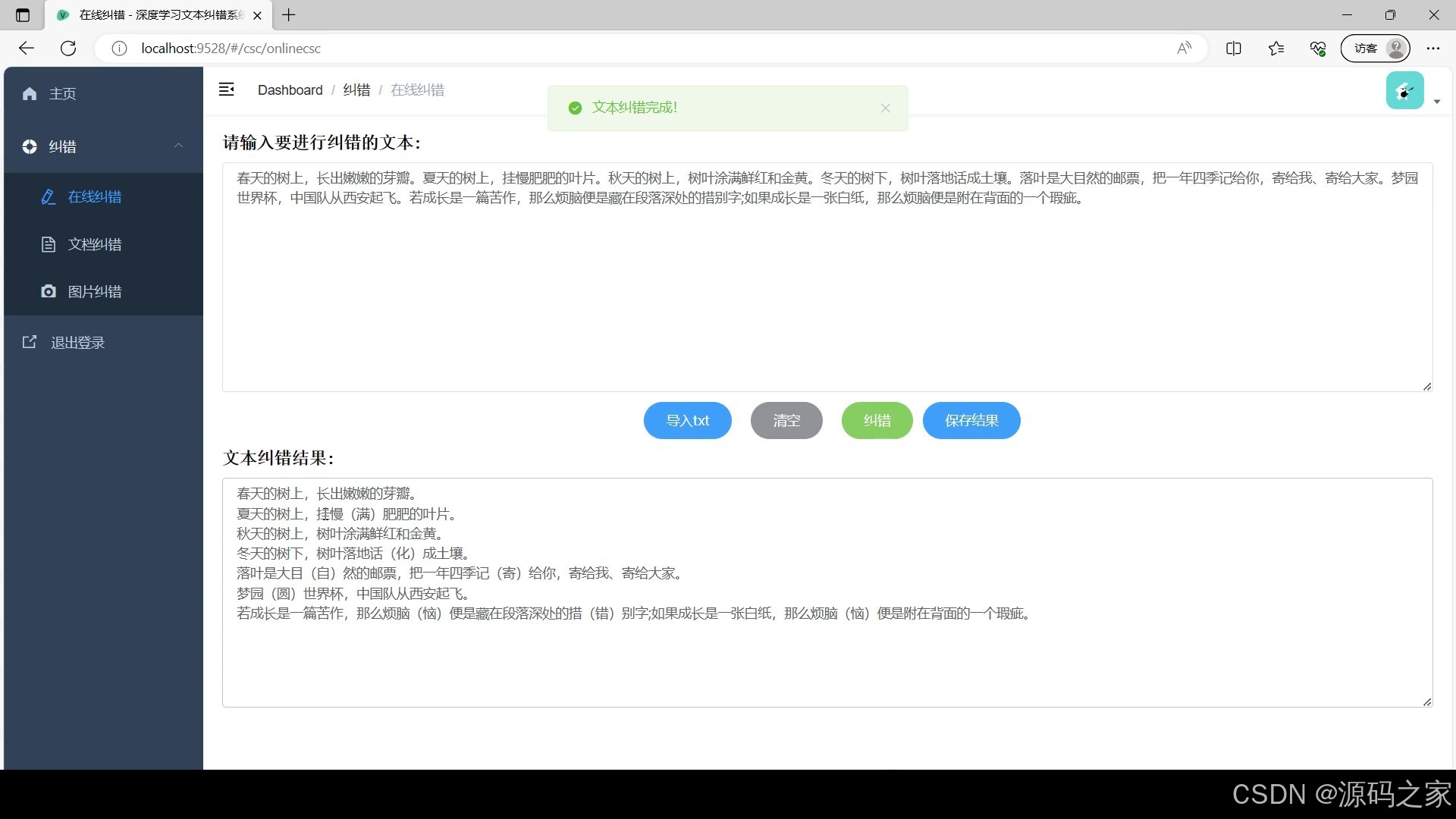
(2)文档纠错
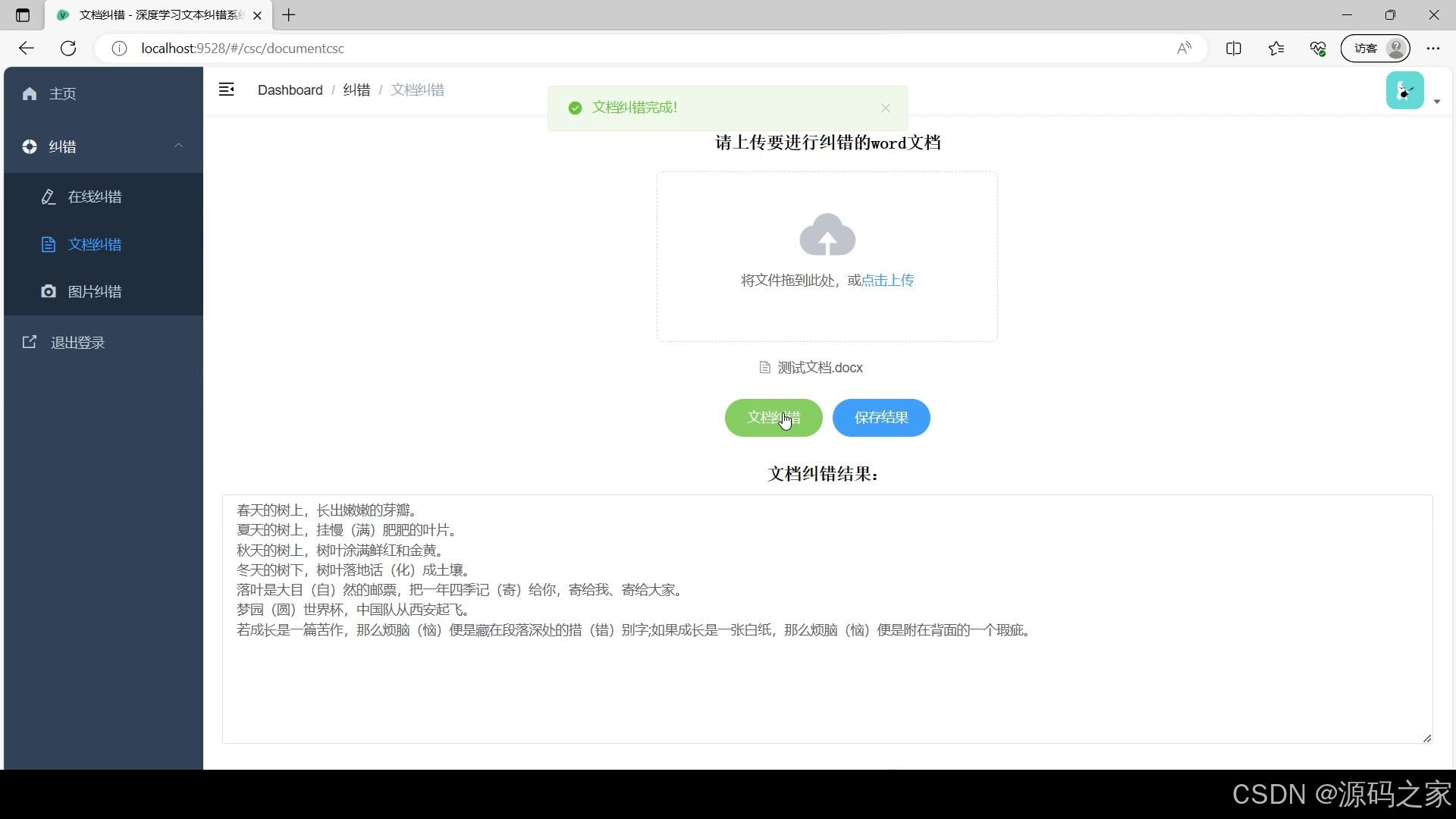
(3)图片纠错
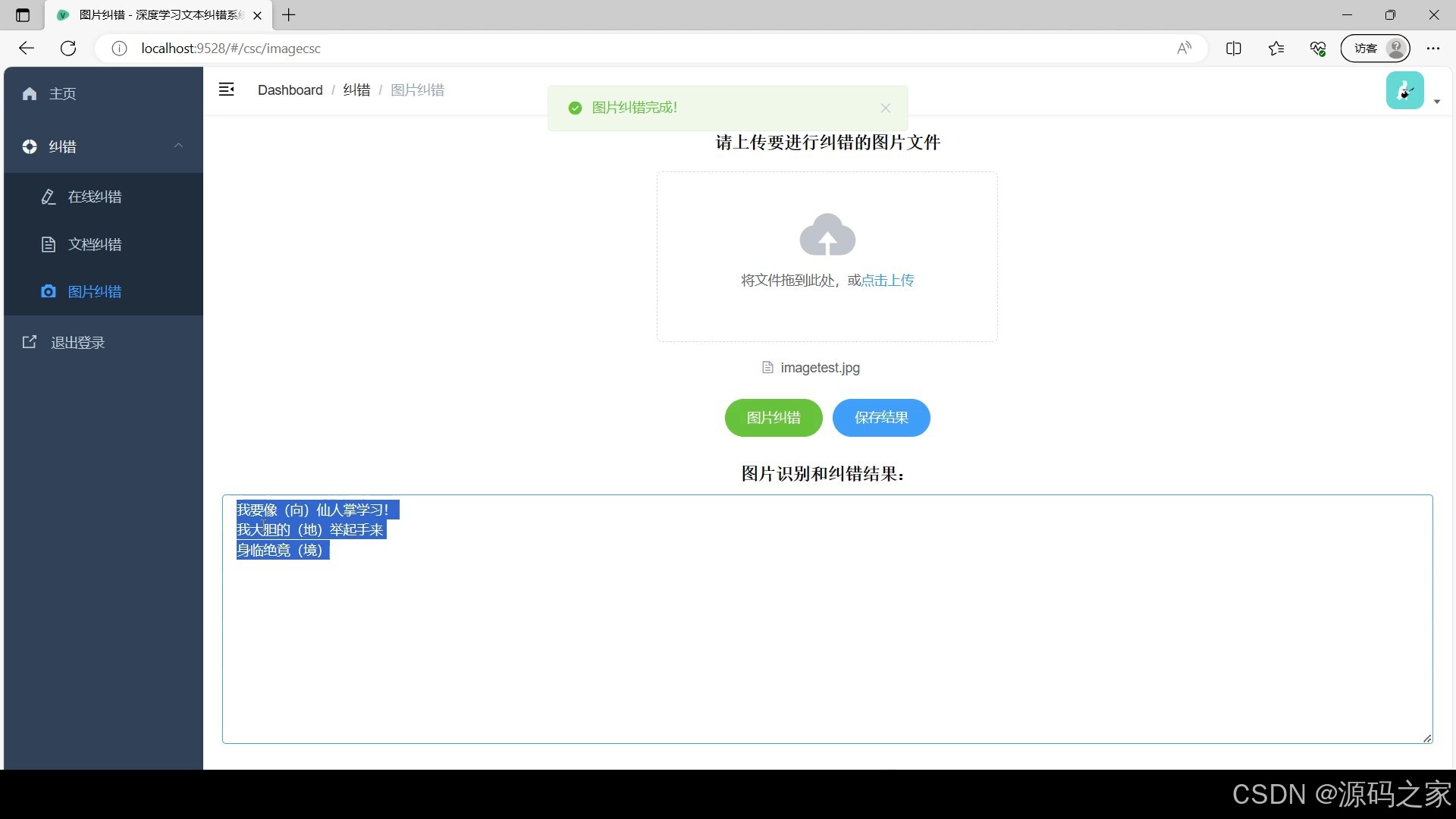
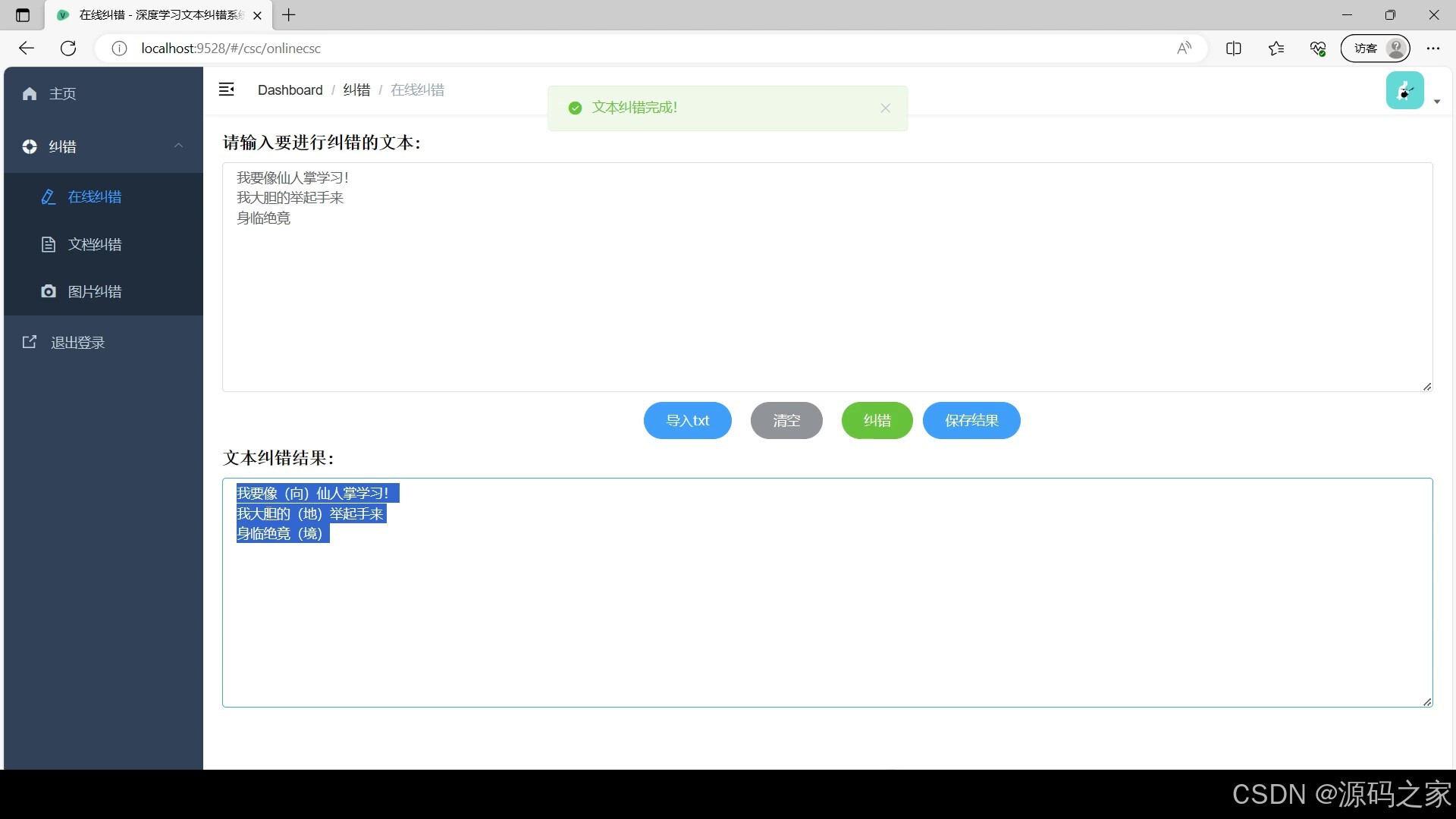
(4)在线纠错
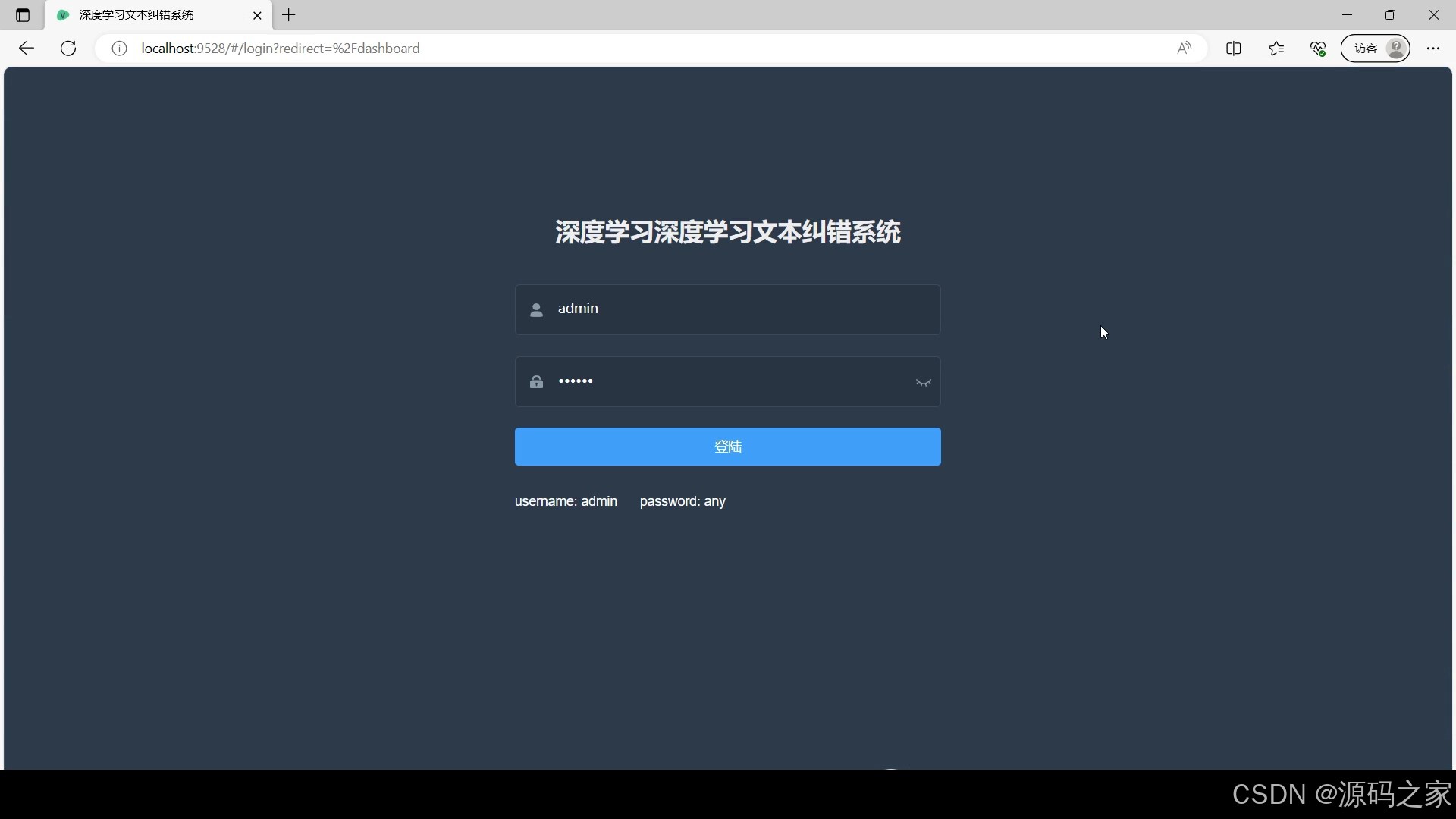
(5)登录界面
3、项目说明
本项目是一款基于 Paddle 生态开发的 Web 端多格式文本智能纠错系统,采用前后端分离部署架构,以 Python 为开发语言,核心整合 PaddleNLP 自然语言处理库、PaddleHub 预训练模型,搭配 FastAPI 高性能后端与 Vue+ElementUI 可视化前端,实现对文本、文档、图片三类格式内容的智能纠错,同时支持错误标记提示与纠错结果保存,可广泛应用于办公文档校对、内容创作审核、教育作业批改、扫描件文字修正等场景,有效解决人工纠错效率低、易遗漏、跨格式处理难的问题,兼具智能化、易用性与实用性。
技术架构上,项目构建 “后端模型推理 - 前端交互 - 多格式适配” 的完整技术体系:后端基于 FastAPI 搭建轻量高效的服务框架,集成 PaddleNLP 与 PaddleHub 双核心 ——PaddleNLP 提供专业文本纠错能力,可精准识别错别字、语法错误、语义不当等问题,生成合理修正建议;PaddleHub 补充图片文字识别(OCR)能力,将图片中的印刷体或手写体文字提取为可编辑文本,打通 “图片 - 文本 - 纠错” 的处理链路;后端通过标准化 API 接口接收前端请求,返回纠错结果、错误位置标记信息及可保存的修正文件。前端采用 Vue+ElementUI 构建直观交互界面,按功能模块划分操作区域,借助 Axios 实现与后端的实时数据通信,同时设计登录权限控制功能,保障用户数据安全与操作隐私。
核心功能覆盖 “多格式纠错 + 错误标记 + 结果管理” 全流程,适配不同使用场景需求:
在线文本纠错:用户在 “在线纠错” 界面直接输入文本内容,点击纠错按钮后,系统快速调用 PaddleNLP 模型分析,在原文中用特殊颜色标记错误位置(如红色标注错别字),右侧同步显示修正后的文本及错误类型说明,用户可直观对比修改前后差异;
文档纠错:支持上传 Word、TXT 等常见格式文档,系统读取文档内容后批量执行纠错,生成包含错误标记的修正版文档,用户可直接下载保存,适用于长篇报告、合同文件等批量校对场景;
图片纠错:针对截图、扫描件等图片格式,先通过 PaddleHub OCR 技术提取文字信息,自动优化文字清晰度与识别准确率,再执行文本纠错流程,解决 “图片文字无法直接修改” 的痛点,适配纸质文档数字化后的纠错需求;
登录与结果管理:用户通过登录界面验证身份后,可查看历史纠错记录,对重要纠错结果进行二次编辑或长期保存,提升数据管理便捷性。
系统界面设计遵循 “简洁直观、功能分区明确” 原则,将文本输入区、纠错结果区、格式选择区清晰划分,即使非技术用户也能快速上手操作。纠错响应速度快,错误标记精准,结果保存格式兼容主流办公软件,充分满足日常办公与专业场景的文本处理需求。整体项目技术栈贴合自然语言处理与 Web 开发趋势,既展现了 Paddle 生态在 NLP 领域的技术优势,又通过多格式支持、人性化交互设计提升实用价值,是兼顾技术深度与用户体验的优质 Web 应用项目。
4、核心代码
from fastapi import FastAPI, HTTPException, UploadFile
from pydantic import BaseModel
from fastapi.middleware.cors import CORSMiddleware
from sutil import cut_sent, replace_char, get_paragraphs_text
import uvicorn
import paddlehub as hub
import cv2
from paddlenlp import Taskflow
import time
print("模型加载预热!")
# OCR文本识别
ocr = hub.Module(name="chinese_ocr_db_crnn_server")
ocr_results = ocr.recognize_text (images=[cv2.imread('./test/imagetest.jpg')])
print("PaddleOCR图片识别结果:")
print(ocr_results)
# 处理识别结果
toCorrectText = []
for i in range(len(ocr_results[0]['data'])):
toCorrectText.append(str(ocr_results[0]['data'][i]['text']))
# PaddleNLP 文本纠错
text_correction = Taskflow("text_correction")
# 纠错结果处理
print("PaddleNLP文本纠错结果:")
for idx, item in enumerate(toCorrectText):
res = text_correction(item)
if (len(res[0]['errors'])) > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
# 如果句子中有多处错字,那么每替换前面一个字,后面的错字索引往后移动3位:即括号+字=3位
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
print(item)
else:
print(item)
# 创建一个 FastAPI「实例」,名字为app
app = FastAPI()
# 设置允许跨域请求,解决跨域问题
app.add_middleware(
CORSMiddleware,
allow_origins=['*'],
allow_credentials=True,
allow_methods=["*"],
allow_headers=["*"],
)
# 定义请求体数据类型:text
class Document(BaseModel):
text: str
# 定义路径操作装饰器:POST方法 + API接口路径
# 文本纠错接口
@app.post("/v1/textCorrect/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def TextErrorCorrection(document: Document):
try:
# 获取要进行纠错的文本内容
text = document.text
# 精细分句处理以更好处理长文本
data = cut_sent(text)
# 进行文本纠错和标记
correctionResult = ''
for idx, item in enumerate(data):
if item != "":
res = text_correction(item)
length = len(res[0]['errors'])
if length > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
# 如果句子中有多处错字,那么每替换前面一个字,后面的错字索引往后移动3位:即括号+字=3位
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
if item is not '':
correctionResult += item;
correctionResult += '\n';
# 接口结果返回
results = {"message": "success", "originalText": document.text, "correctionResults": correctionResult}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail=str("请求失败,服务器端发生异常!异常信息提示:" + str(e)))
# 文档纠错接口
@app.post("/v1/docCorrect/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def DocumentErrorCorrection(file: UploadFile):
# 读取上传的文件
docBytes = file.file.read()
docName = file.filename
# 判断上传文件类型
docType = docName.split(".")[-1]
if docType != "doc" and docType != "docx":
raise HTTPException(status_code=406, detail=str("请求失败,上传文档格式不正确!请上传word文档!"))
try:
# 将上传文件保存到本地,添加时间标记避免重复
now_time = int(time.mktime(time.localtime(time.time())))
docPath = "./test/" + str(now_time) + "_" + docName
fout = open(docPath, 'wb')
fout.write(docBytes)
fout.close()
# 读取要进行文本纠错的word文档内容
docText = get_paragraphs_text(docPath)
# 对word文档内容进行分句处理避免句子过长
docText = cut_sent(docText)
# 进行文本纠错和标记
correctionResult = ""
for idx, item in enumerate(docText):
if item is not '':
res = text_correction(item)
length = len(res[0]['errors'])
if length > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
# 如果句子中有多处错字,那么每替换前面一个字,后面的错字索引往后移动3位:即括号+字=3位
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
if item is not '':
correctionResult += item;
correctionResult += '\n';
# 接口结果返回
results = {"message": "success", "docText": str(docText), "correctionResults": correctionResult}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail=str("请求失败,服务器端发生异常!异常信息提示:" + str(e)))
# 图片纠错接口
@app.post("/v1/imageCorrect/", status_code=200)
# 定义路径操作函数,当接口被访问将调用该函数
async def ImageErrorCorrection(file: UploadFile):
# 读取上传的文件
imgBytes = file.file.read()
imgName = file.filename
# 判断上传文件类型
imgType = imgName.split(".")[-1]
if imgType != "png" and imgType != "jpg" and imgType != "jpeg" :
raise HTTPException(status_code=406, detail=str("请求失败,上传图片格式不正确!请上传jpg或png图片!"))
try:
now_time = int(time.mktime(time.localtime(time.time())))
# 拼接生成随机文件名,注意名称不能包含中文否则后面读取出错
imgPath = "./test/" + str(now_time) + "_image." + imgType
print(imgPath)
fout = open(imgPath, 'wb')
fout.write(imgBytes)
fout.close()
print("文件上传成功!")
# OCR文本识别
ocr_image_results = ocr.recognize_text(images=[cv2.imread(imgPath)])
# 处理图片识别文本结果
toCorrectText = []
for i in range(len(ocr_image_results[0]['data'])):
toCorrectText.append(str(ocr_image_results[0]['data'][i]['text']))
# 进行文本纠错和标记
correctionResult = ""
for idx, item in enumerate(toCorrectText):
if item != "":
res = text_correction(item)
length = len(res[0]['errors'])
if length > 0:
for i, error in enumerate(res[0]['errors']):
if i == 0:
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), res[0]['errors'][i]['position'])
else:
# 如果句子中有多处错字,那么每替换前面一个字,后面的错字索引往后移动3位:即括号+字=3位
p = res[0]['errors'][i]['position'] + i * 3
item = replace_char(item, (list(res[0]['errors'][i]['correction'].keys())[0] + '(' + list(res[0]['errors'][i]['correction'].values())[0] + ')'), p)
if item is not '':
correctionResult += item;
correctionResult += '\n';
# 接口结果返回
results = {"message": "success", "orcResult": str(ocr_image_results[0]), "correctionResults": correctionResult}
return results
# 异常处理
except Exception as e:
print("异常信息:", e)
raise HTTPException(status_code=500, detail=str("请求失败,服务器端发生异常!异常信息提示:" + str(e)))
# 启动创建的实例app,设置启动ip和端口号
uvicorn.run(app, host="127.0.0.1", port=8000)
5、项目获取

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 42
42 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)