通用4D世界模型NeoVerse面世:单目视频秒变4D大片,推理提速8倍
来自中科院自动化所(CASIA)与CreateAI的研究团队联合发布了最新的通用4D世界模型——NeoVerse。该模型彻底打破了以往4D建模对专业多视角数据或复杂位姿预处理的依赖,通过学习互联网上100万条“野外”单目视频,实现了从视频重建到高保真生成的跨越式进化。
导读: 想象一下,只需要一段普通手机拍摄的单目视频,AI就能瞬间为你构建出一个可交互、可编辑、可全视角观看的4D世界。
近日,来自中科院自动化所(CASIA)与CreateAI的研究团队联合发布了最新的通用4D世界模型——NeoVerse。该模型彻底打破了以往4D建模对专业多视角数据或复杂位姿预处理的依赖,通过学习互联网上100万条“野外”单目视频,实现了从视频重建到高保真生成的跨越式进化。
一、论文概述
论文名称:NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
项目地址:https://neoverse-4d.github.io/
论文链接:https://www.lab4ai.cn/paper/detail/reproductionPaper?utm_source=csdn_neoverse&id=b0ed5cd25f0249c187a6bcfefae16673

NeoVerse 的思路是把这件事做成一条可规模化的训练范式,让模型能够利用海量野外视频持续变强。
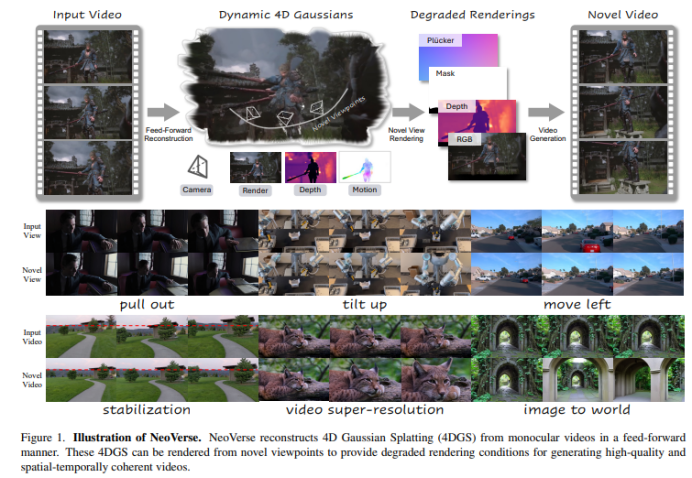
论文在 图 1 给出清晰的流程:先前向重建动态 4D 高斯表示(4DGS),再从新视角渲染得到低质量的退化渲染,将其作为条件输入生成模型;训练时以原视频作为目标,使生成模型学会从低质量新视角渲染生成高质量的新视角结果。
二、为什么需要 NeoVerse
4D 世界模型是融合3D 空间维度(长、宽、高)与 1D 时间维度的场景建模技术,核心是对动态场景进行时空一体化表征,既还原三维空间结构,又捕捉时间维度的运动变化,实现对真实世界的动态数字化复刻。
为什么之前的 4D 世界模型很难利用到海量野外视频?论文认为有两大原因:
-
数据可扩展性有限:不少工作依赖难采集的多机位动态数据,导致泛化与能力上限被数据类型锁死。
-
训练可扩展性有限:另一类方法需要繁重的离线预处理(例如离线深度、离线重建、额外 3D 检测等),这会导致计算负担重、训练方案僵化。
NeoVerse 的核心思路就是针对这两点“对症下药”:把整条从重建到生成的训练pipeline设计为可扩展、可端到端的形式,使模型能够直接利用“廉价且多样”的野外单目视频持续学习,而不是被数据形态或离线流程拖住。
三、核心技术
总体框架
如果只靠生成模型直接从单目视频“脑补”新视角,为什么容易漂、闪、细节虚?
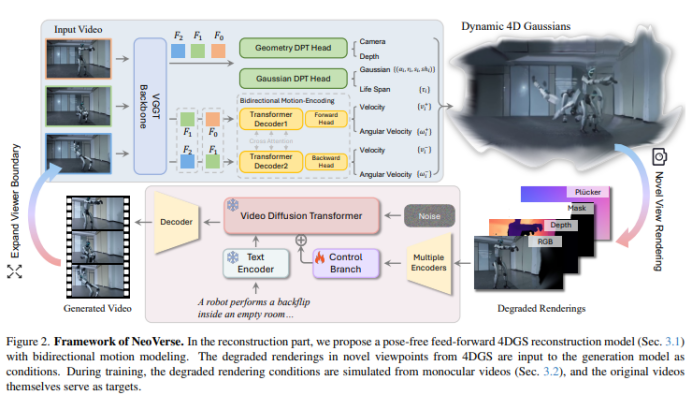
NeoVerse 的策略是把任务拆成两步:先用重建端给出一个几何上自洽的动态世界骨架(4DGS),再用生成端把“骨架渲染出来但有缺陷的画面”提升成高质量视频。
图 2 讲的就是这条链路:重建端是 pose-free、feed-forward 的 4DGS 重建;生成端把 4DGS 在新视角渲染得到的 degraded renderings(退化渲染)作为条件输入扩散模型;训练时用“退化条件→原视频帧”为监督对,使模型学会从低质量渲染生成高质量结果。
为什么要“双向运动建模”
很多人会直觉认为:动态重建只要“逐帧估”就行。但单目视频里最难的是时间一致性:既要让物体在 t→t+1 连贯,也要让它在 t→t−1 同样合理,否则中间帧插值会抖、会错位。
论文解释得很明确:他们显式区分 t→t+1 与 t→t−1 的瞬时运动,用双向预测来服务“时间插值”(而不只是为了多一个分支)。 公式 (1) 表明,把帧特征沿时间切成两段,分别做一次 Cross-Attention,得到前向 motion feature和后向 motion feature,分别刻画“往前一帧怎么动”和“往后一帧怎么动”。
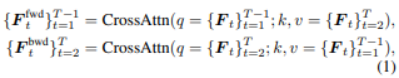
公式 (2) 表明,每个高斯点不只是“位置/旋转/尺度/颜色”这种静态属性,还带着双向线速度
$$v_i^+,\ v_i^-$$,双向角速度$$w_i^+,\ w_i^- $$,以及一个生命周期$$\tau_i$$。这意味着:模型不仅知道“点在哪里”,还知道“它往前/往后会怎么走”,并且知道“这个点在时间上该持续多久”。
![]()
训练为什么能更快
这里的关键不是“少算几帧”,而是:少算的同时还要保证时序正确。论文里说得很清楚:长视频若逐帧在线重建会成为训练瓶颈,所以只取 K 个关键帧做重建输入,但渲染覆盖全部 N 帧,因为渲染比网络计算高效。
那非关键帧怎么来?公式 (3)(4)(5) 的意义是:用双向速度/角速度把关键帧的高斯“平移/旋转”到任意时间戳(默认短时间内运动近似线性)。
尤其公式 (5) 里的$$\tau_i$$很重要:它控制 opacity 的衰减,让高斯点在时间上自然淡入淡出,避免某些点突然出现/消失造成闪烁;论文中同时解释了 $$\tau_i-1$$时衰减几乎没有,否则,$$\tau_i$$ 衰减迅速。
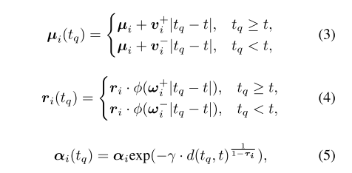
没有多视角真值,训练对从哪来?
单目视频没有多视角 GT,生成模型凭什么学会“把新视角渲染变好”?
生成模型需要学习“从低质量新视角渲染到高质量新视角”的映射,因此必须构造这种训练对;多视角数据好办,但野外单目视频就得自己模拟退化。
图 3 画的三类退化不是随便挑的,它们基本对应单目重建/渲染最常见的错误形态:
遮挡缺失(图 3 - a):用深度判断从新轨迹看哪些高斯不可见,直接裁剪掉再渲染回原视角,得到“该缺的地方缺掉”的遮挡退化。
飞点与畸变(图 3 - b、c):先在新轨迹渲染深度并做平均滤波,再按滤波深度调整高斯中心;渲染回原视角会出现边缘飞点,滤波核更大还能模拟更宽的畸变。
这一步的价值在于:它让模型见过“野外单目重建真实会出现的坏条件”,训练就不再依赖昂贵的多机位数据,从而更可规模化。

生成端为什么“既听镜头指挥、又能修伪影”
要让扩散模型真正“听懂镜头轨迹”,仅有 RGB 远远不够。论文把条件做成多模态:RGB、Depth、由 opacity 二值化的 Mask(指示空洞区域),并额外计算 Plücker embedding 来显式提供 3D 相机运动信息。
然后引入一个控制分支来注入这些条件,并且训练时只训练控制分支、冻结原视频生成模型——这样做一方面为了训练效率,另一方面让整个方案能接入更强的蒸馏/LoRA 加速生成。
四、实验与应用
重建效果
先明确一点:这里的重建指标其实在回答同一个问题——你从视频里还原出来的 3D/4D 世界,渲染回去像不像、稳不稳、有没有“假细节”。
PSNR/SSIM 越高,通常表示画面更接近真实、结构更一致;LPIPS 越低,表示从“人眼感知”角度更接近真实,更少“看起来不对劲”的伪影。
如表 1(静态),与 VRNeRF 与 Scannet++相比,论文的 PSNR/SSIM 更高、LPIPS 更低,说明它不仅更清晰,也更“像真”。
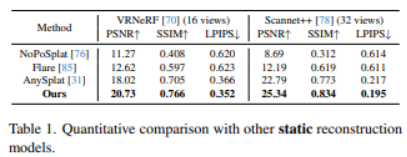
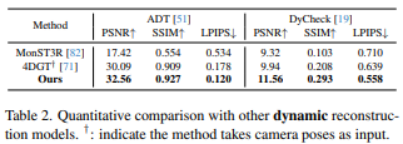
如表 2(动态),动态场景对重建更具挑战:场景中存在物体运动与频繁遮挡,模型不仅要还原几何结构,还要保证时间上的连续一致,因此更容易出现伪影或指标下降。但在 ADT 与 DyCheck 两个动态数据集上,NeoVerse 仍取得了表中最优结果。更关键的是,表注中 † 标明部分对比方法需要额外输入相机位姿,而 NeoVerse 在 pose-free(无需位姿输入) 的设定下依然优于这些“输入条件更强”的基线,从而凸显其方案在真实野外单目视频场景中的竞争力。
生成效果
一个现实痛点是:镜头一大幅移动,新视角生成要么轨迹飘,要么画质糊/闪。论文中提到:相关工作通常存在“生成质量 vs 轨迹可控性”的权衡。
图 4就是权衡的直观证据:Trajectory Crafter 更像“重建驱动”,轨迹可控性好,但生成质量更差;ReCamMaster 更像“纯生成”,画质好但轨迹控制不精确;NeoVerse 试图两者兼得,实现了更好的生成质量,黄色框标出其他方法的伪影/问题区域。

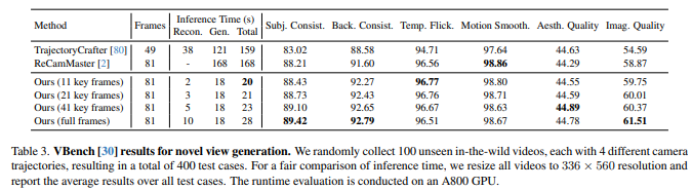
表 3(VBench)则把“好看不好看、稳不稳”量化了:包括主观一致性、背景一致性、时间闪烁、运动平滑等维度,并且很有用的一点是——把推理时间拆成 Reconstruction / Generation / Total。生成端时间基本稳定在 18s,而关键帧越多,重建端耗时越长;这使得“质量 vs 速度”可以通过关键帧数直接调节。
哪些设计真的在贡献效果
表 4(消融)不是简单“去掉模块看掉点”,它在回答两件事:
双向运动建模有没有必要? 去掉它(w/o Bidirectional Motion)性能下降,论文还明确解释了做法:跳过 公式(1) 直接从帧特征预测 motion,会带来掉点,从而证明 motion 建模机制有效。
正则有没有必要? 去掉 regularization 会更差,论文解释这是为了防止模型学“透明高斯走捷径”。
纯重建(Reconstruction part) vs 全流程(w/ Generation),后者在 DyCheck 上从 11.56 提升到 14.59(PSNR),说明“生成阶段不是锦上添花,而是在系统层面显著拉升最终质量”。
图 7表明:如果不训练模拟退化样本,生成模型会“相信条件里的几何伪影”,导致 ghosting 或模糊;加入退化模拟后,模型学会抑制伪影,并在遮挡/扭曲区域“补出更真实的细节”。
下游应用
因为 NeoVerse 有一个“随时间变化的 4D 表示”,所以它不仅能渲染,还能做空间与时间上的操作。
3D tracking(图 9):用预测的 3D flow 在相邻帧之间关联最近的高斯点,从而实现 3D 跟踪可视化。
Video editing(图 10):因为生成端有二值 mask 条件 + 文本条件,所以可以在分割模型辅助下做视频编辑,示例是“白车改红车”“茶壶变透明”。
Video stabilization / super-resolution(图 1):稳定的核心是“平滑预测相机轨迹”;超分的核心是“4D 高斯渲染分辨率可灵活提高,再用生成端出更高分辨率视频”。
它为什么更“像能做成产品”的路线?
NeoVerse 不只是提出一个结构,而是把“数据—训练—评测”按可规模化路线补齐了,这也是它能在大镜头运动下同时做到“轨迹可控 + 画质稳定”的重要前提。
五、结论
三点启发
-
“单目+大规模”可行的关键不在网络多大,而在训练对怎么造:在线退化模拟把“无 GT”的问题变成“可监督”。
-
时间一致性要服务“插值与效率”:双向运动不仅是精度点,更直接支撑“稀疏关键帧重建 + 全帧渲染”的训练提速策略。
-
生成模型不一定要全量重训:用控制分支注入多模态条件,冻结主干,效率与可迁移性更好。
论文明确写了局限:NeoVerse 要求数据具备正确的底层 3D 信息,因此不适用于 2D 卡通等缺乏 3D 几何线索的数据;此外作者也承认 1M片段 仍不算“特别大”,未来希望继续扩数据。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 18
18 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)