DeepSeek 被骂上热搜,GPT-4o 含泪毕业,字节智谱「杀疯了」!| AI Weekly 2.9-2.15
有人被骂惨,有人被送走,有人杀疯了,有人融了 300 亿美元。这周 AI 圈发生的事,一篇文章根本装不下。
📢 本周 AI 快讯 | 1 分钟速览🚀
1️⃣ 🧊 DeepSeek 灰度测试百万 Token 上下文 :悄悄将上下文窗口从 128K 拉到 1M,疑似 V4 压力测试,但因情感模块精简导致「变冷淡」冲上热搜,用户反应激烈。
2️⃣ 🎬 字节发布 Seedance 2.0 :支持文字、图片、音频、视频四模态同时输入,单条指令可生成多镜头连贯叙事片段,《黑神话:悟空》制作人冯骥称其为「地表最强视频生成模型」。
3️⃣ 🔥 字节发布 豆包 2.0 系列 :旗舰版 Pro 在 HLE 拿下 54.2 分登顶,数学编程均获金牌,API 价格比 GPT-5.2 和 Gemini 3 Pro 低约一个数量级,豆包日活已破 1 亿。
4️⃣ 💻 智谱开源 GLM-5 :744B 总参数,编程基准 SWE-bench-Verified 得分 77.8,开源最高,曾以匿名代号「Pony Alpha」登顶 OpenRouter 热度榜,港股盘中涨超 22%。
5️⃣ ⚡ MiniMax 发布 M2.5 :SWE-Bench Verified 80.2%,编程能力对标 Claude Opus 4.6,激活参数仅 10B,推理成本低至同级 1/10 到 1/20,港股一度涨超 35%。
6️⃣ 🚀 OpenAI 发布 Codex-Spark :首款非英伟达模型,运行在 Cerebras WSE-3 上,推理速度超每秒 1000 token,约为常规编程模型的 15 倍,仅向 Pro 用户开放。
7️⃣ 📑 ChatGPT 深度研究升级至 GPT-5.2 :新增全屏报告查看器,支持导出 PDF/Word/Markdown,可限定搜索特定网站,研究过程中支持实时查看进度并随时补充指令。
8️⃣ 💳 OpenAI 推出信用点数计费 :1000 点售价 40 美元,Codex 和 Sora 通用,触达速率限制后自动扣费,但社区反映实际消耗远超预期。
9️⃣ 👋 OpenAI 下架 GPT-4o 等 6 款旧模型 :所有对话默认切换至 GPT-5.2,曾因用户抗议恢复的 GPT-4o 这次正式告别,有用户称「感觉像失去了一个朋友」。
1️⃣0️⃣ 🧠 谷歌升级 Gemini 3 Deep Think :HLE 无工具得分 48.4%,ARC-AGI-2 达 84.6%,已协助研究者解决 18 个此前未解问题并推翻一个 2015 年数学猜想。
1️⃣1️⃣ 💰 Anthropic 完成 300 亿美元 G 轮融资 :投后估值 3800 亿美元,半年接近翻倍,年化收入达 140 亿美元,Claude Code 年化收入超 25 亿美元,IPO 准备已启动。
01|DeepSeek 灰度更新百万 Token 上下文,却因「变冷淡」登上热搜
2 月 11 日,DeepSeek 悄悄推送灰度更新,上下文窗口从 128K Token 直接拉到 1M,可一次性处理近百万字文本,被视为即将发布的 V4 版本的压力测试。但用户最先注意到的不是性能提升,而是「人设崩塌」。2 月 12 日,「DeepSeek 被指变冷淡了」冲上热搜,大量用户反映新版不再使用自定义昵称,统一改称「用户」;深度思考模式下的角色心理描写消失,取而代之的是短句诗化表达和居高临下的说教口吻,被吐槽「登味十足」。
当前版本类似极速模式,为适配百万级上下文处理而精简了情感交互模块,属于「牺牲质量换速度」的过渡方案。DeepSeek 回应称并非刻意变冷淡,而是出于效率考虑减少了语气词和表情修饰,同时增强「边界感」。但用户反应激烈,有人尝试安装旧版,有人转向竞品,甚至自发联名要求恢复共情功能。SimilarWeb 数据显示 DeepSeek 今年 1 月全球访问量 2.98 亿次,较去年 12 月的 3.29 亿下滑约 9%。V4 正式版预计 2 月中旬发布,届时情感模块权重能否回调,将直接影响用户留存。
02|字节「Seedance 2.0」正式发布,被评「地表最强视频模型」
2 月 12 日,字节跳动正式发布 Seedance 2.0 视频生成模型,此前已于 2 月 7 日小范围内测。模型采用双分支扩散变换器架构,支持文字、图片、音频、视频四种模态同时输入(最多 9 张图 + 3 段视频 + 3 段音频),最核心的突破是单条指令即可生成包含多镜头切换的连贯叙事片段,角色面部、服饰和光影在不同镜头间保持高度一致。视频生成同步产出匹配的音效和配乐,支持口型同步和情绪匹配。

《黑神话:悟空》制作人冯骥称其为「当前地表最强的视频生成模型」,The Information、CNBC 等海外媒体密集报道,YouTube 上对比测评视频大量涌现,普遍认为 Seedance 2.0 在运镜自主规划、物理动作模拟和音画同步上已超越 Sora 2 和 Veo 3.1。不过模型上线后因真人形象滥用风险引发争议,字节紧急限制了真人人脸作为参考素材的功能,需通过活体认证才能生成数字分身。目前已在即梦和豆包平台上线。
03|字节发布「豆包 2.0」,HLE 登顶且 API 价格低一个数量级
2 月 14 日,字节跳动发布 豆包 2.0(Doubao-Seed-2.0)系列,包含 Pro、Lite、Mini 和 Code 四款模型。旗舰版 Pro 对标 GPT-5.2 与 Gemini 3 Pro,在 HLE(人类最后一场考试)上拿到 54.2 分,为目前公开最高;数学和编程同样强势,IMO、CMO 和 ICPC 均获金牌成绩,Putnam Bench 超过 Gemini 3 Pro。知识储备上 SuperGPQA 超过 GPT-5.2,HealthBench 排名第一。多模态视觉理解在多数基准达到 SOTA,EgoTempo 动态场景测试超越人类水平。
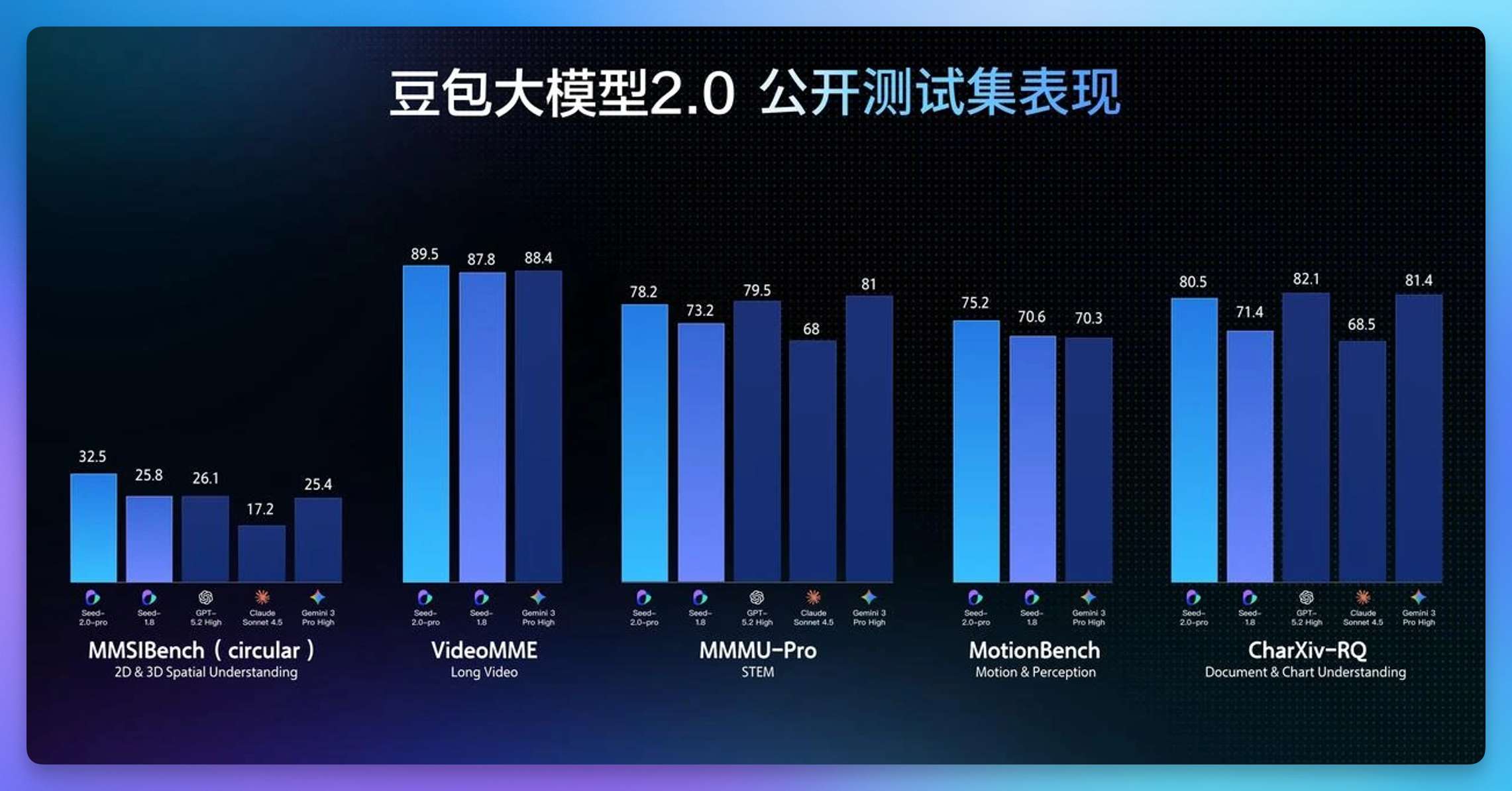
Pro 版 32k 以内输入 3.2 元/百万 tokens,输出 16 元/百万 tokens,官方称比 GPT-5.2 和 Gemini 3 Pro 低约一个数量级。Lite 版综合性能超过上一代主力豆包 1.8,输入价格仅 0.6 元/百万 tokens。豆包 App 用户切换到「专家」模式即可体验 Pro 版,Code 版则已接入 AI 编程工具 TRAE,火山引擎同步开放全系列 API。豆包日活已破 1 亿,火山引擎日均 Token 调用量超 30 万亿,这次 2.0 的发布节奏紧跟 Seedance 2.0 视频模型和 Seedream 5.0 图像模型,字节在春节档集中释放了一轮密集的模型攻势。
04|智谱开源「GLM-5」登顶开源编程榜,股价盘中涨超 22% 再创新高
2 月 11 日,智谱发布新一代旗舰模型 GLM-5 并同步开源(MIT License)。总参数 744B,激活参数 40B,均为上一代 GLM-4.7 的两倍,预训练数据从 23T 增至 28.5T tokens。编程基准 SWE-bench-Verified 得分 77.8,Terminal Bench 2.0 得分 56.2,均为开源模型最高,超过 Gemini 3 Pro,体感逼近 Claude Opus 4.5。此前以「Pony Alpha」代号匿名上线 OpenRouter,上线首日处理 40 亿 token、20.6 万次请求,登顶热度榜后才揭晓身份。
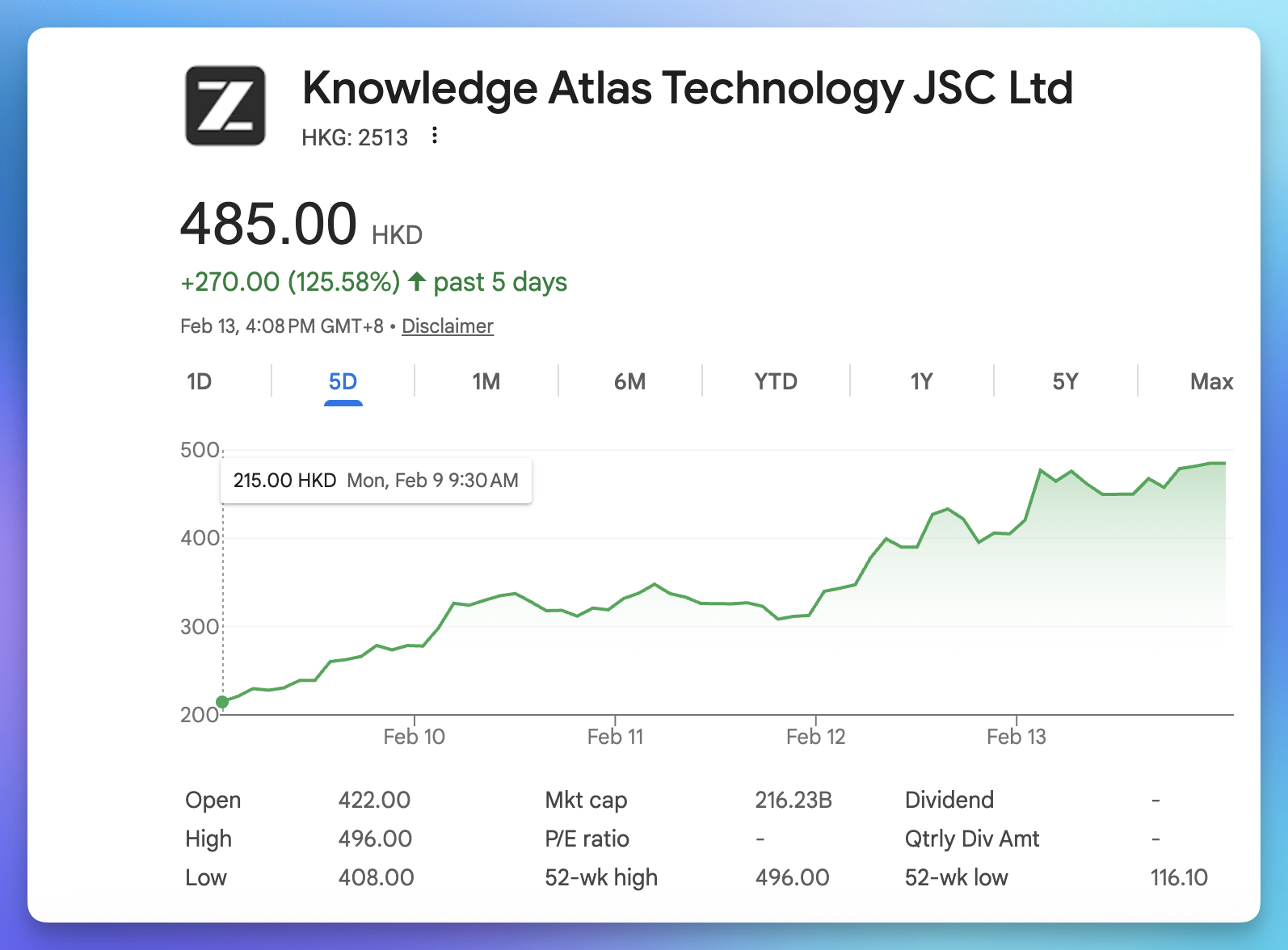
GLM-5 采用 MoE 架构搭配 DeepSeek 稀疏注意力机制降低部署成本,并构建了异步强化学习框架「Slime」,让模型通过完成长程项目而非单题训练来学习工程能力。同步推出的 Z Code 工具支持自然语言拆解任务、多智能体并发完成编码到提交的全流程,甚至可以用手机远程指挥桌面端 Agent。模型可部署在华为、摩尔线程、寒武纪等国产芯片上。不过智谱坦言算力极度紧张,GLM Coding Plan 同日宣布涨价 30% 起。资本市场反应迅速,2 月 13 日智谱港股盘中涨超 22%,触及 492 港元再创上市新高,总市值突破 2100 亿港元。
05|MiniMax 发布「M2.5」,对标 Claude 编程能力,成本仅为同级 1/10
2 月 12 日,MiniMax 上线旗舰编程模型 M2.5,定位为首个 Agent 场景原生设计的生产级模型。SWE-Bench Verified 得分 80.2%,Multi-SWE-Bench 51.3% 排名第一,BrowseComp 76.3%,编程能力对标 Claude Opus 4.6。在 Droid 脚手架上通过率 79.7% 超过 Opus 4.6 的 78.9%。模型采用 MoE 架构,总参数 2300 亿但激活仅 10B,是第一梯队中参数规模最小的旗舰,推理吞吐达 100 TPS,约为 Opus 4.6 的 3 倍,完成 SWE-Bench 任务比上代 M2.1 快 37%。
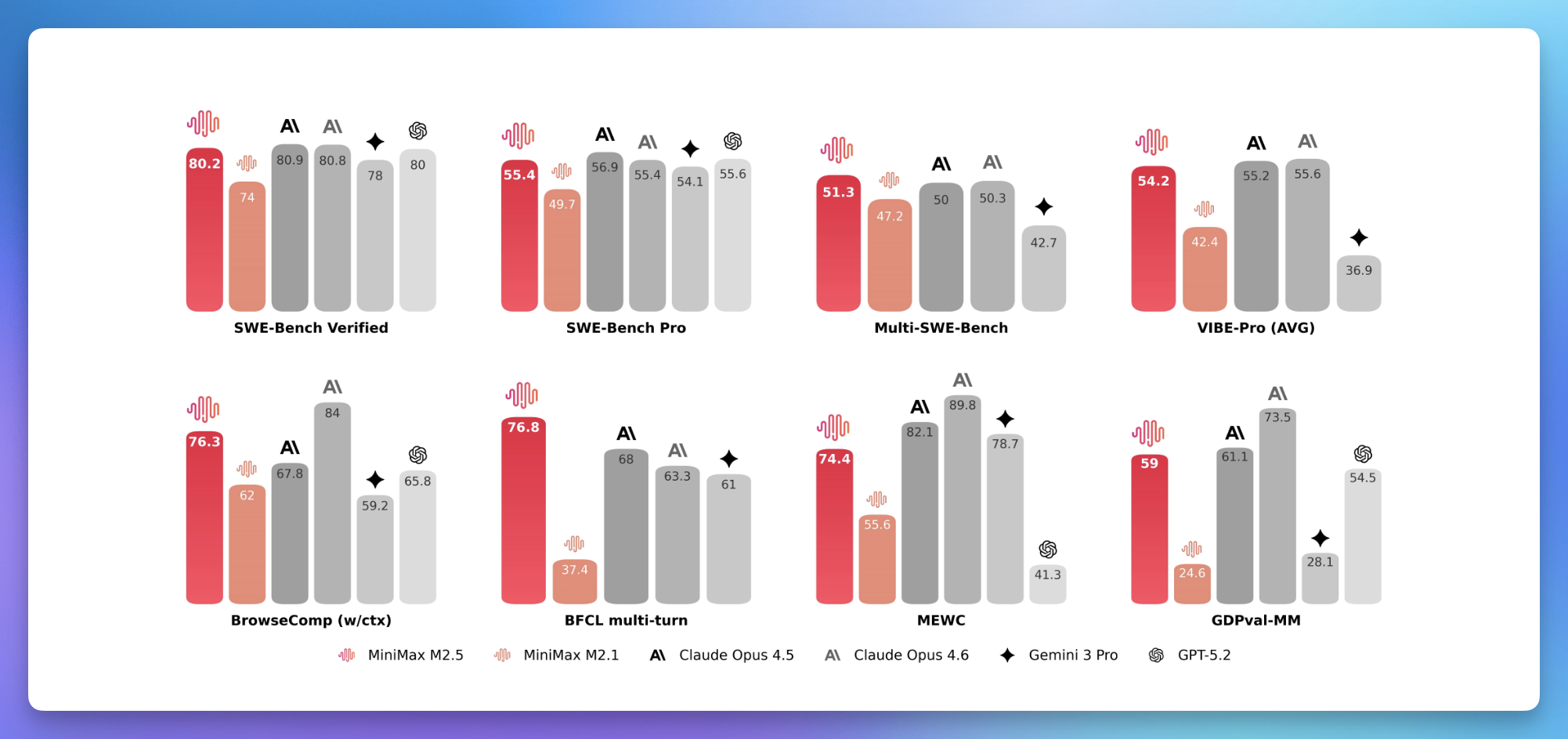
成本是最大卖点。100 TPS 模式下连续工作一小时仅 1 美元,50 TPS 模式更低至 0.3 美元,官方称仅为同级别模型的 1/10 到 1/20。MiniMax 内部已有 30% 的任务由 M2.5 自主完成,编程场景中新提交代码的 80% 由模型生成。模型权重已在 HuggingFace 开源(MIT License),消息公布后 MiniMax 港股一度涨超 35%,近五日累计涨幅约 35%。同一天智谱 GLM-5 和 DeepSeek 灰度更新也在刷屏,春节前国产模型集中放了一波大招。
06|OpenAI 首款非英伟达模型「Codex-Spark」发布,每秒 1000 token
2 月 12 日,OpenAI 发布 GPT-5.3-Codex-Spark 研究预览版,这是 GPT-5.3-Codex 的轻量版本,专为实时编程设计,也是 OpenAI 首款不运行在英伟达硬件上的生产模型。它跑在 Cerebras 晶圆级引擎 WSE-3 上,推理速度超过每秒 1000 token,是常规 AI 编程模型 65-70 token/s 的约 15 倍。配合 WebSocket 持久连接等管线优化,每次请求往返开销降低 80%,首 token 延迟缩短 50%。

性能上 Codex-Spark 介于 GPT-5.3-Codex 和 GPT-5.1-Codex-Mini 之间,在 SWE-Bench Pro 上接近完整版水平,但 Terminal-Bench 2.0(58.4% vs 77.3%)差距明显,复杂多步任务仍需大模型接手。目前仅向 ChatGPT Pro 用户(200 美元/月)开放,支持 Codex App、CLI 和 VS Code 插件,128k 上下文,纯文本。OpenAI 1 月宣布与 Cerebras 签下超 100 亿美元的多年合作协议,计划分阶段接入 750 兆瓦算力,Codex-Spark 是首个落地成果。GPU 仍是训练和通用推理的主力,Cerebras 定位为低延迟推理的补充层,两者可在单一工作负载中混合使用。
07|ChatGPT「深度研究」升级至 GPT-5.2,新增全屏报告查看器和指定网站搜索
2 月 11 日,OpenAI 对 ChatGPT 深度研究功能进行全面升级,底层模型从此前的 o3/o4-mini 切换至 GPT-5.2。最直观的变化是新增全屏报告查看器,左侧目录可跳转章节,右侧面板展示引用来源,报告支持导出为 PDF、Word 和 Markdown。每份报告还自动附带「方法论」章节,解释 AI 的推理路径和信源优先级。
用户现在可以在提示词中限定搜索特定网站或域名(如 PubMed、arXiv),还能接入 Google Drive 等已连接应用作为可信信源。研究过程中支持实时查看进度,随时中断并补充新指令或追加信源,不再是「发出去就只能等」。目前 Plus 和 Pro 用户已可使用,Go 和免费用户将在数日内跟进。
08|OpenAI 为 Codex 和 Sora 推出「信用点数」,40 美元 1000 点
2 月 13 日,OpenAI 发布技术博客详解其新计费引擎。核心变化是引入信用点数(credits)作为订阅额度的延伸,用户触达速率限制后系统自动从点数余额扣费,无需切换计划或等待重置。1000 点售价 40 美元,有效期 12 个月,Codex 和 Sora 通用。按官方费率卡换算,GPT-5.2 Thinking 每条消息消耗 10 点,Pro 模式 50 点,Agent 任务 30 点,40 美元大约够用 100 次 Thinking 或 33 次 Agent。

不过社区反馈并不全是好评。有开发者反映 8 次 Codex 查询就烧光了 40 美元额度加上整周的订阅配额,实际消耗远超预期。Sora 端同样存在变数,视频时长和分辨率不同,单条消耗差异悬殊。OpenAI 将这套混合计费系统定位为未来更多产品的基础架构,但对用户来说,透明度和可预测性仍是痛点。
09|OpenAI 一口气「下架」6 款旧模型,「GPT-4o」正式告别 ChatGPT
2 月 13 日,OpenAI 从 ChatGPT 中移除 GPT-4o、GPT-4.1、GPT-4.1 mini、o4-mini 以及此前已宣布退役的 GPT-5 Instant 和 Thinking 版本,所有对话默认切换至 GPT-5.2。API 端暂不受影响,企业和教育版用户的自定义 GPT 中 GPT-4o 保留至 4 月 3 日。

GPT-4o 的退役颇为波折。去年 8 月 GPT-5 上线时 OpenAI 曾直接下架 GPT-4o,用户因留恋其「温暖对话风格」强烈抗议,迫使公司数天内恢复。但 GPT-4o 同时也是多起用户自残和 AI 依赖诉讼的焦点,至今仍是 OpenAI 旗下谄媚度评分最高的模型。OpenAI 称目前日活用户中仅 0.1% 还在用 GPT-4o,但以 8 亿周活跃用户的基数算,这仍意味着约 80 万人。社交媒体上已有用户表示「感觉像失去了一个朋友」。
10|谷歌升级「Deep Think」推理模式,HLE、ARC-AGI-2 均创新高
2 月 12 日,谷歌发布 Gemini 3 Deep Think 重大升级,定位为面向科学、研究与工程的专用推理模式。HLE(人类的最后考试)无工具得分 48.4%,ARC-AGI-2 达 84.6%(经 ARC Prize 基金会验证),Codeforces Elo 3455 达到「传奇宗师」级别,2025 年国际数学、物理和化学奥赛笔试部分均为金牌水平,理论物理 CMT-Benchmark 得分 50.5%。与此前 Deep Think 版本更注重竞赛刷分不同,这次升级强调实际科研场景的落地能力。

罗格斯大学数学家 Lisa Carbone 用 Deep Think 审阅一篇关于引力与量子力学交叉领域的论文,模型发现了一个人类同行评审未能察觉的逻辑缺陷;杜克大学 Wang Lab 用它优化半导体晶体生长工艺,成功设计出超过 100 微米薄膜的制备方案。谷歌还披露,Deep Think 进阶版本与研究者合作解决了 18 个此前未解的研究问题,并推翻了一个 2015 年的数学猜想。目前面向 Google AI Ultra 订阅用户开放,首次通过 Gemini API 向研究者和企业提供早期访问。
11|Anthropic 完成 300 亿美元 G 轮融资,估值半年翻倍至 3800 亿美元
2 月 12 日,Anthropic 宣布完成 300 亿美元 G 轮融资,投后估值 3800 亿美元,较去年 9 月 F 轮的 1830 亿美元接近翻倍。新加坡主权基金 GIC 和对冲基金 Coatue 领投,微软(最高 50 亿)和英伟达(最高 100 亿)的此前战略投资也并入本轮,红杉、黑石、高盛、摩根士丹利、淡马锡等悉数跟投。这是科技史上最大单轮私募融资之一,仅次于 OpenAI 去年的 400 亿美元。
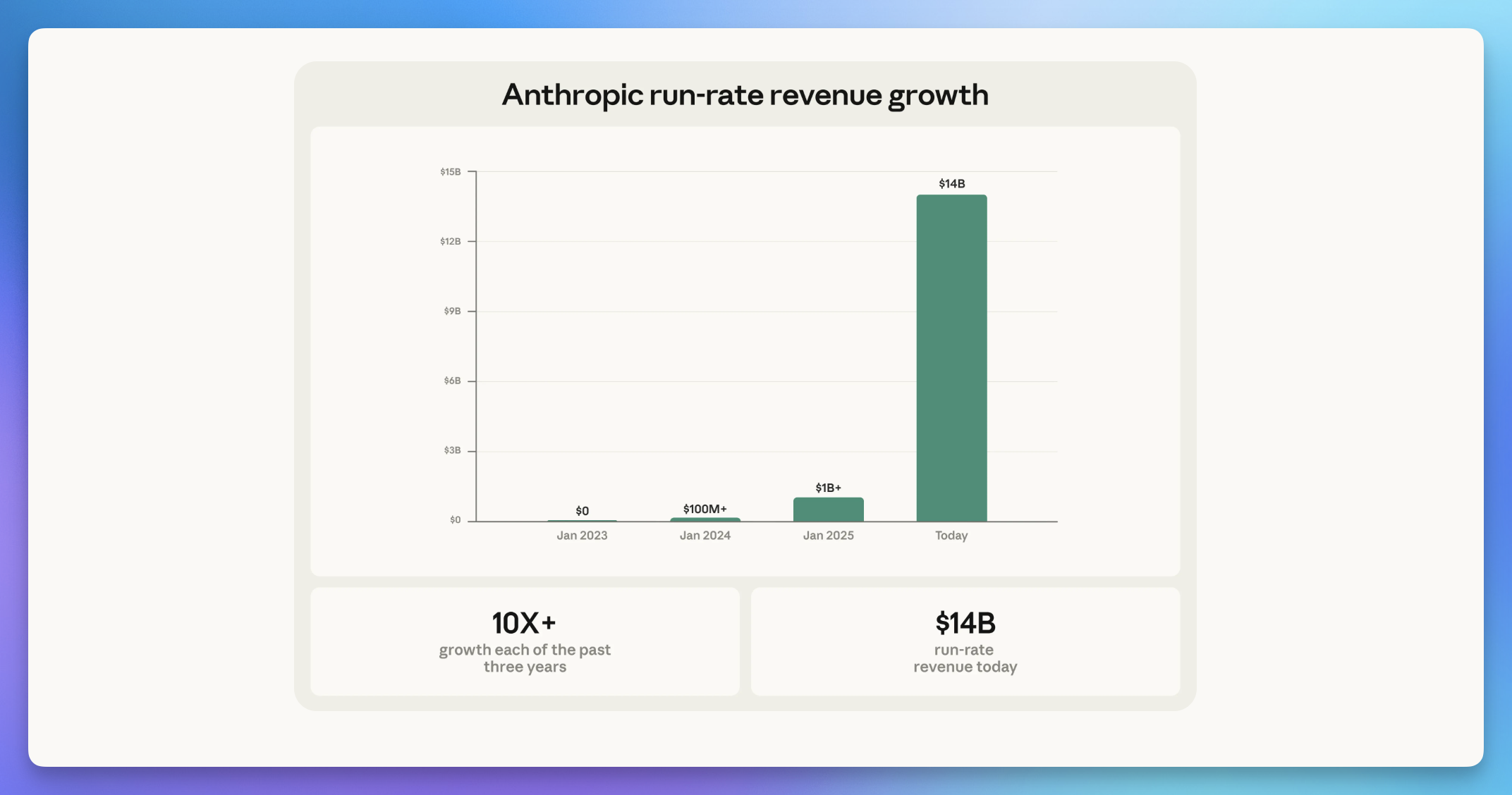
支撑高估值的是一组企业级数据。Anthropic 年化收入已达 140 亿美元,连续三年翻倍;《财富》世界十强企业中 8 家是 Claude 客户,年消费超百万美元的客户突破 500 家。Claude Code 尤其亮眼,年化收入超 25 亿美元,今年以来翻了一倍多,企业订阅用户数量增长 4 倍。每月活跃用户产生 211 美元收入,而 OpenAI 的每周活跃用户仅带来 25 美元。英国《金融时报》透露 Anthropic 已聘请律所启动 IPO 准备,最早可能今年上市。与 OpenAI 8000 亿美元估值的正面竞争之外,两家公司的路径分化越来越清晰,一个走 C 端订阅规模,一个走 B 端企业深耕。
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 13
13 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)