BitaHub上部署qwen2大模型web app实践
本教程将在上一篇文章的基础上,进一步指导您如何在Bitahub平台上部署大模型Web服务,并实现本地访问。
在实际工作中,我们往往更倾向于拥有一个直观且交互性强的界面来体验大模型。本教程将在上一篇文章的基础上,进一步指导您如何在Bitahub平台上部署大模型Web服务,并实现本地访问。我们将以Qwen-2模型为例,详细阐述这一过程。
总体技术难度:中等
操作环境:windows系统
平台地址:https://www.bitahub.com/
准备工作
代码准备
模型 web代码文件,这里使用的是qwen2.5官方的web app代码。
web.py文件
# Copyright (c) Alibaba Cloud.``#``# This source code is licensed under the license found in the``# LICENSE file in the root directory of this source tree.``"""A simple web interactive chat demo based on gradio."""``from argparse import ArgumentParser``from threading import Thread``import gradio as gr``import torch``from transformers import AutoModelForCausalLM, AutoTokenizer, TextIteratorStreamer``DEFAULT_CKPT_PATH = "/test/qwen2/7b"``def _get_args():` `parser = ArgumentParser(description="Qwen2.5-Instruct web chat demo.")` `parser.add_argument(` `"-c",` `"--checkpoint-path",` `type=str,` `default=DEFAULT_CKPT_PATH,` `help="Checkpoint name or path, default to %(default)r",` `)` `parser.add_argument(` `"--cpu-only", action="store_true", help="Run demo with CPU only"` `)` `parser.add_argument(` `"--share",` `action="store_true",` `default=False,` `help="Create a publicly shareable link for the interface.",` `)` `parser.add_argument(` `"--inbrowser",` `action="store_true",` `default=False,` `help="Automatically launch the interface in a new tab on the default browser.",` `)` `parser.add_argument(` `"--server-port", type=int, default=8000, help="Demo server port."` `)` `parser.add_argument(` `"--server-name", type=str, default="127.0.0.1", help="Demo server name."` `)` `args = parser.parse_args()` `return args``def _load_model_tokenizer(args):` `tokenizer = AutoTokenizer.from_pretrained(` `args.checkpoint_path,` `resume_download=True,` `)` `if args.cpu_only:` `device_map = "cpu"` `else:` `device_map = "auto"` `model = AutoModelForCausalLM.from_pretrained(` `args.checkpoint_path,` `torch_dtype="auto",` `device_map=device_map,` `resume_download=True,` `).eval()` `model.generation_config.max_new_tokens = 2048 # For chat.` `return model, tokenizer``def _chat_stream(model, tokenizer, query, history):` `conversation = []` `for query_h, response_h in history:` `conversation.append({"role": "user", "content": query_h})` `conversation.append({"role": "assistant", "content": response_h})` `conversation.append({"role": "user", "content": query})` `input_text = tokenizer.apply_chat_template(` `conversation,` `add_generation_prompt=True,` `tokenize=False,` `)` `inputs = tokenizer([input_text], return_tensors="pt").to(model.device)` `streamer = TextIteratorStreamer(` `tokenizer=tokenizer, skip_prompt=True, timeout=60.0, skip_special_tokens=True` `)` `generation_kwargs = {` `**inputs,` `"streamer": streamer,` `}` `thread = Thread(target=model.generate, kwargs=generation_kwargs)` `thread.start()` `for new_text in streamer:` `yield new_text``def _gc():` `import gc` `gc.collect()` `if torch.cuda.is_available():` `torch.cuda.empty_cache()``def _launch_demo(args, model, tokenizer):` `def predict(_query, _chatbot, _task_history):` `print(f"User: {_query}")` `_chatbot.append((_query, ""))` `full_response = ""` `response = ""` `for new_text in _chat_stream(model, tokenizer, _query, history=_task_history):` `response += new_text` `_chatbot[-1] = (_query, response)` `yield _chatbot` `full_response = response` `print(f"History: {_task_history}")` `_task_history.append((_query, full_response))` `print(f"Qwen: {full_response}")` `def regenerate(_chatbot, _task_history):` `if not _task_history:` `yield _chatbot` `return` `item = _task_history.pop(-1)` `_chatbot.pop(-1)` `yield from predict(item[0], _chatbot, _task_history)` `def reset_user_input():` `return gr.update(value="")` `def reset_state(_chatbot, _task_history):` `_task_history.clear()` `_chatbot.clear()` `_gc()` `return _chatbot` `with gr.Blocks() as demo:` `gr.Markdown("""\``<p align="center"><img src="https://qianwen-res.oss-accelerate-overseas.aliyuncs.com/assets/logo/qwen2.5_logo.png" style="height: 120px"/><p>""")` `gr.Markdown(` `"""\``<center><font size=3>This WebUI is based on Qwen2.5-Instruct, developed by Alibaba Cloud. \``(本WebUI基于Qwen2.5-Instruct打造,实现聊天机器人功能。)</center>"""` `)` `gr.Markdown("""\``<center><font size=4>``Qwen2.5-7B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-7B-Instruct/summary">🤖 </a> |` `<a href="https://huggingface.co/Qwen/Qwen2.5-7B-Instruct">🤗</a>  |` `Qwen2.5-32B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-32B-Instruct/summary">🤖 </a> |` `<a href="https://huggingface.co/Qwen/Qwen2.5-32B-Instruct">🤗</a>  |` `Qwen2.5-72B-Instruct <a href="https://modelscope.cn/models/qwen/Qwen2.5-72B-Instruct/summary">🤖 </a> |` `<a href="https://huggingface.co/Qwen/Qwen2.5-72B-Instruct">🤗</a>  |` ` <a href="https://github.com/QwenLM/Qwen2.5">Github</a></center>""")` `chatbot = gr.Chatbot(label="Qwen", elem_classes="control-height")` `query = gr.Textbox(lines=2, label="Input")` `task_history = gr.State([])` `with gr.Row():` `empty_btn = gr.Button("🧹 Clear History (清除历史)")` `submit_btn = gr.Button("🚀 Submit (发送)")` `regen_btn = gr.Button("🤔️ Regenerate (重试)")` `submit_btn.click(` `predict, [query, chatbot, task_history], [chatbot], show_progress=True` `)` `submit_btn.click(reset_user_input, [], [query])` `empty_btn.click(` `reset_state, [chatbot, task_history], outputs=[chatbot], show_progress=True` `)` `regen_btn.click(` `regenerate, [chatbot, task_history], [chatbot], show_progress=True` `)` `gr.Markdown("""\``<font size=2>Note: This demo is governed by the original license of Qwen2.5. \``We strongly advise users not to knowingly generate or allow others to knowingly generate harmful content, \``including hate speech, violence, pornography, deception, etc. \``(注:本演示受Qwen2.5的许可协议限制。我们强烈建议,用户不应传播及不应允许他人传播以下内容,\``包括但不限于仇恨言论、暴力、色情、欺诈相关的有害信息。)""")` `demo.queue().launch(` `share=args.share,` `inbrowser=args.inbrowser,` `server_port=args.server_port,` `server_name=args.server_name,` `)``def main():` `args = _get_args()` `model, tokenizer = _load_model_tokenizer(args)` `_launch_demo(args, model, tokenizer)``if __name__ == "__main__":` `main()
新建密钥
在密钥设置里面新建一个密钥
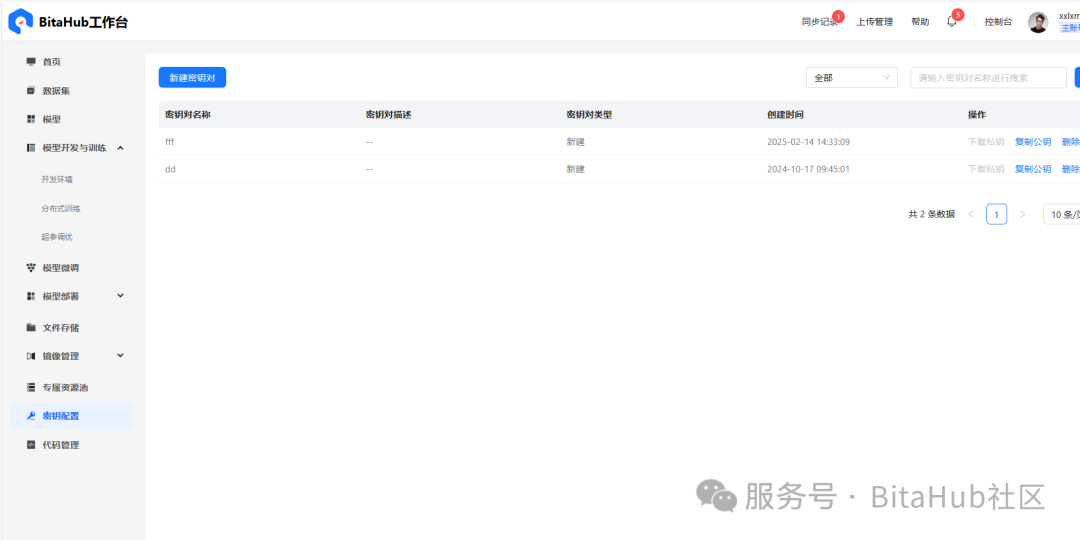
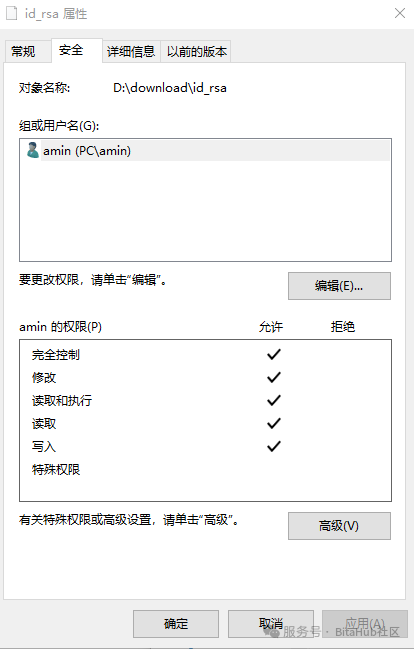
设置好密钥后,下载对应的私有密钥文件。对密钥文件id_rsa设置权限仅当前用户可以访问。
安装nmap软件
这个里面包含了下面需要的ncat文件,下载地址是https://nmap.org/download.html
bitahub平台新建任务
配置参数:绑定qwen2 7b模型和代码
需要设置jupyter(可选)和ssh两种连接方式,ssh连接使用提前设置好的密钥
平台服务部署
模型服务启动
在jupyter里面启动web服务,执行命令如下。
`##安装依赖``pip install gradio``##启动服务``python web.py --checkpoint-path model_path`
当然你也可以使用ssh登录后执行上面的命令
ssh连接
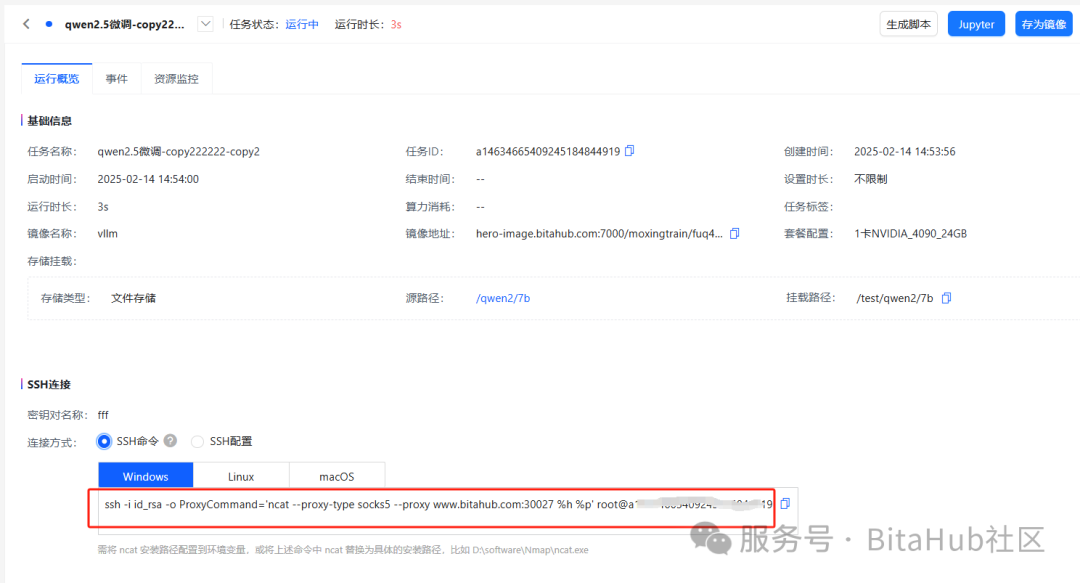
把其中的ssh命令复制出来,这个是连接ssh使用的。
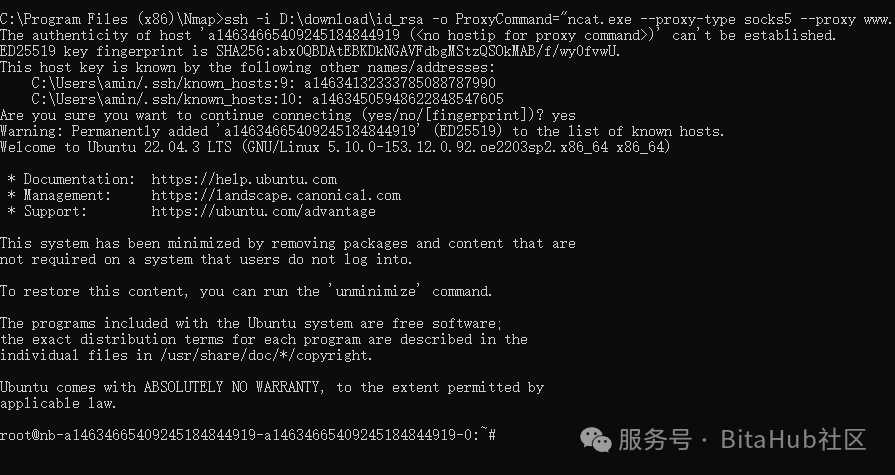
执行ssh隧道代理命令
ssh -i id_rsa -o ProxyCommand="ncat.exe --proxy-type socks5 --proxy www.bitahub.com:30027 %h %p" -L port:localhost:localport root@host
这个里面port是web服务的端口号,localport是本地端口号,host是docker的机器号。
例子:
ssh -i D:\download\id_rsa -o ProxyCommand="ncat.exe --proxy-type socks5 --proxy www.bitahub.com:30027 %h %p" -L 8000:localhost:8000 root@a14634665409245184844919
执行后会登录进去
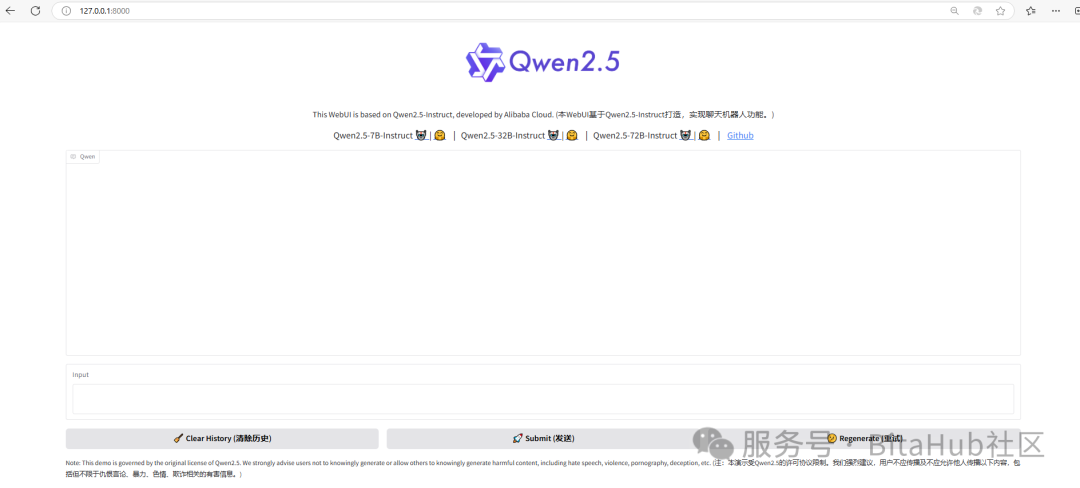
web服务使用
到了这一步测试下成果,在本地浏览器输入http://127.0.0.1:8000即可进入app页面了。
可能遇到问题
Permissions for 'D:\\download\\id_rsa' are too open.``It is required that your private key files are NOT accessible by others.
这个需要修改文件权限。在文件的设置-安全里面改成当前用户的独有权限,删除其他用户权限。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)
三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 21
21 0
0- 0



 已为社区贡献603条内容
已为社区贡献603条内容

所有评论(0)