HTTP和Web服务介绍
HTTP和Web服务介绍
HTTP协议
HTTP的全称是Hypertext transfer protocol,超文本传输协议;https tls/ssl 加密过程;他是构建web应用的基础,虽然开发web应用大部分时候都不用关心http协议细节,但是如果未能正确的使用该协议,可能会带来安全隐患。HTTP协议设定的内容非常多,下面将简单介绍HTTP协议中和安全相关的知识
HTTP协议简介
HTTP协议是一种Client-Server协议,所以只能由客户端单向发起请求,服务端再响应请求。这里的客户端也叫用户代理(User Agent),在大多数情景下是一个浏览器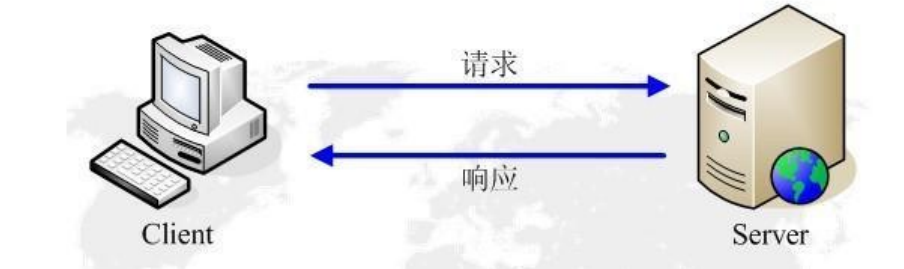
HTTP请求
http通信由请求和响应组成,一个HTTP请求的数据包如下所示。(抓包演示)
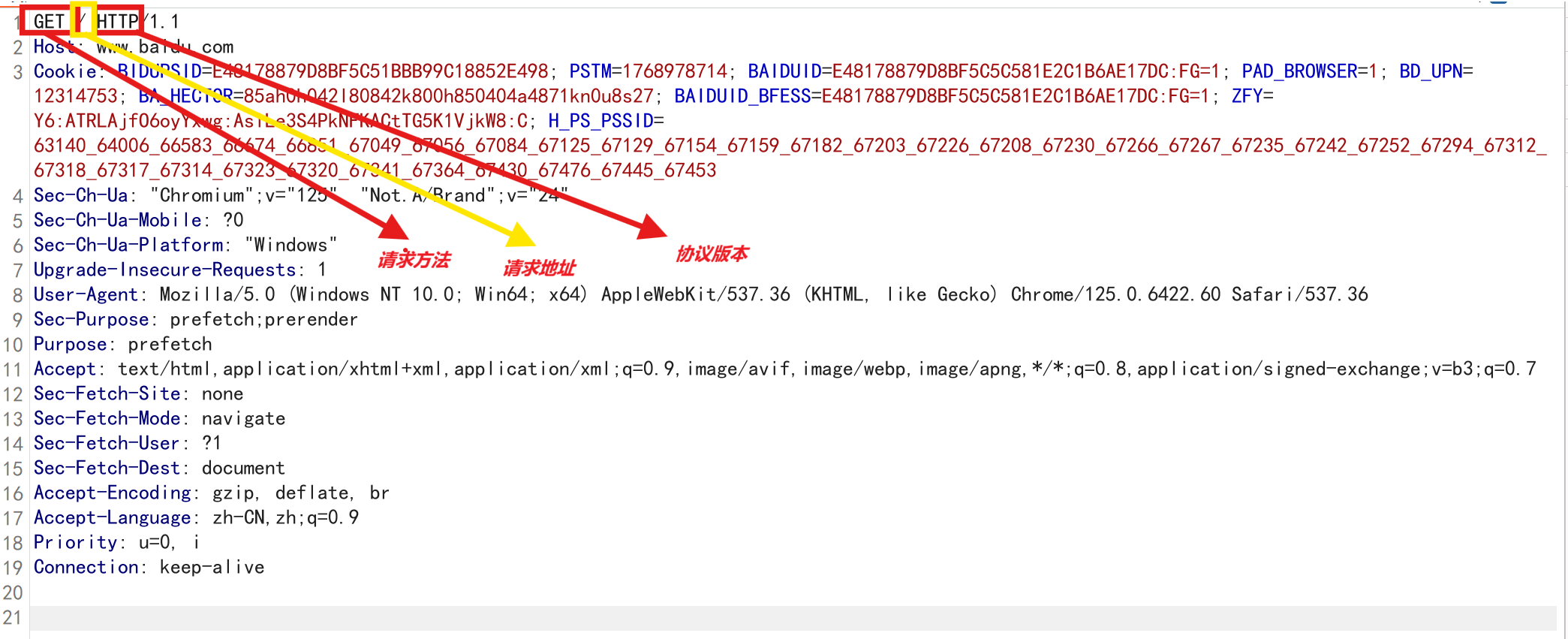
http请求方法
http方法用于指定请求的操作系统,标准的方法如下所示
| 方法 | 用途 |
|---|---|
| OPTIONS | 用于客户端向服务端询问是否支持特定的选项 |
| GET | 向服务端获取URL指定的 |
| HEAD | 和GET方法类似,但是服务端不返回实际内容 |
| POST | 向服务端提交数据 |
| PUT | 向指定的URL存储文件 |
| DELETE | 删除URI指定的服务器上的文件 |
| TRACE | 让服务器回显请求中的内容 |
| CONNECT | 用户在HTTP协议中建立代理隧道 |
web应用中的绝大部分请求使用的是GET和POST方法,通过XMLHttpRequest可以发送HEAD、PUT、DELETE方法的请求。在部分场景下,浏览器会发OPTIONS请求,用于预检。CONNECT请求一般用于HTTP隧道代理场景。
虽然Web应用中的一项功能,使用不同的HTTP方法都能实现,但出于安全考虑,我们要遵循如下基本原则:
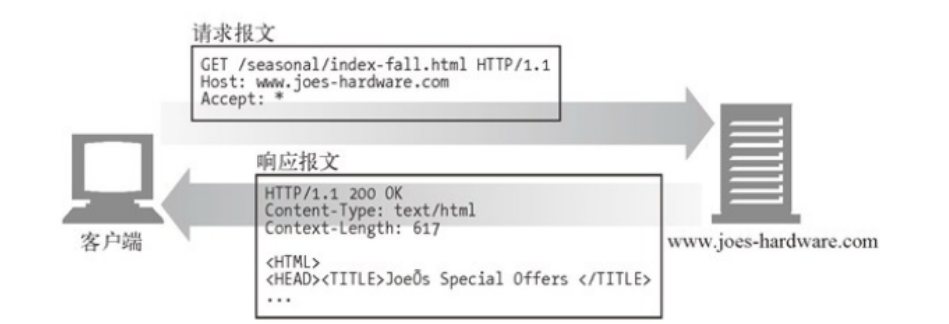
- GET和HEAD方法应当只用于对服务端没有副作用的操作,即对服务端是“只读”的操作,它们被称为安全的方法。如果该操作对服务器端会有副作用,比如增加、删除、更改数据,则应该使用别的HTTP方法。考虑到安全性,对于GET请求,浏览器在刷新页面时不会要求用户确认,而对于有副作用的POST请求,在刷新页面时浏览器会询问用户是否重新发送,避免在服务端产生多余的操作,比如重复交易、重复下单等
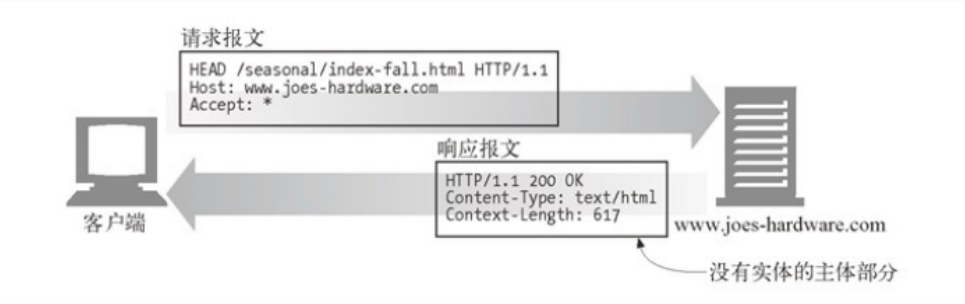
HEAD方法和GET方法的行为很类似,但服务器在响应中只返回首部。不会返回实体的主体部分。这就允许客户端在未获取实际资源的情况下,对资源的首部进行检查。使用HEAD,可以:
-
在不获取资源的情况下了解资源的情况(比如,判断其类型)
-
通过查看响应中的状态码,看看某个对象是否存在
-
通过查看首部,测试资源是否被修改了
服务器开发者必须确保返回首部与GET请求所返回的首部完全相同。遵循HTTP/1.1规范,就必须实现HEAD方法
2.PUT和 DELETE 方法一般用于直接上传和删除文件,大部分 Web 应用不会用到,如果这两种方法被攻击者利用,危害会非常大。因此如无业务需求,应当禁用这些方法。与GET从服务器读取文档相反,PUT方法会向服务器写入文档。有些发布系统允许用户创建Web页面, 并用PUT直接将其安装到Web服务器上去。
3.在 Web 应用中,尽量通过 POST 方法提交敏感数据,而不是通过GET方法提交。POST方法起初是用来向服务器输入数据的。实际上, 通常会用它来支持HTML的表单。表单中填好的数据通常会被送给服务器, 然后由服务器将其发送到它要去的地方(比如, 送到⼀个服务器网关程序中, 然后由这个程序对其进行处理)。
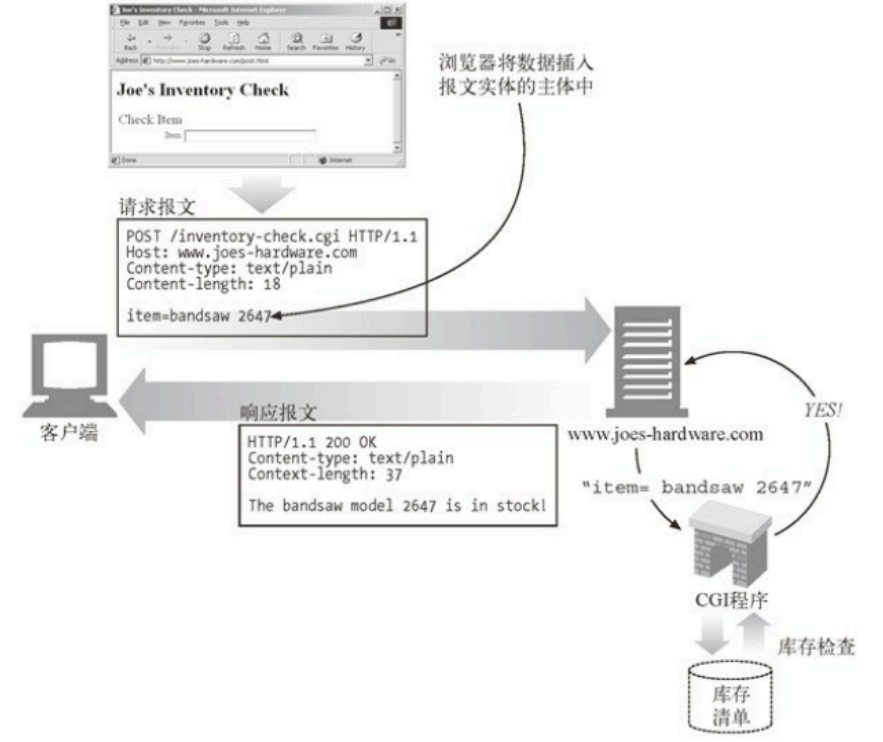
4.在服务端获取请求参数时,应当明确指明是从GET参数还是 POST参数中获取,否则攻击者可将原本设计为⽤POST⽅法提交的操作改⽤GET⽅法提交,以绕过某些只针对POST请求设计的安全策略(如全局 CSRF 防御⽅案。例如,在 PHP中尽量不要从REQUEST中获取请求参数,⽽是明确指定从REQUEST中获取请求参数,⽽是明确指定从REQUEST中获取请求参数,⽽是明确指定从GET 或者$_POST中获取。
5.TRACE ⽅法通常⽤于诊断调试,服务端直接返回请求中的内容,在 XSS 攻击中可⽤它绕过 Cookie的HttpOnly策略,通过 JavaScript代码读取带有 HttpOnly 属性的 Cookie内容⽣产环境的服务器应当禁⽤TRACE⽅法。
客⼾端发起⼀个请求时, 这个请求可能要穿过防⽕墙、代理、⽹关或其他⼀些应⽤程序。每个中间节点都可能会修改原始的HTTP 请求。TRACE⽅法允许客⼾端在最终将请求发送给服务器时, 看看它变成了什么样⼦。TRACE请求会在⽬的服务器端发起⼀个“环回” 诊断。⾏程最后⼀站的服务器会弹回⼀条TRACE响应, 并在响应主体中携带它收到的原始请求报⽂。这样客⼾端就可以查看在所有中间HTTP应⽤程序组成的请求响应链上, 原始报⽂如何被毁坏或修改过。
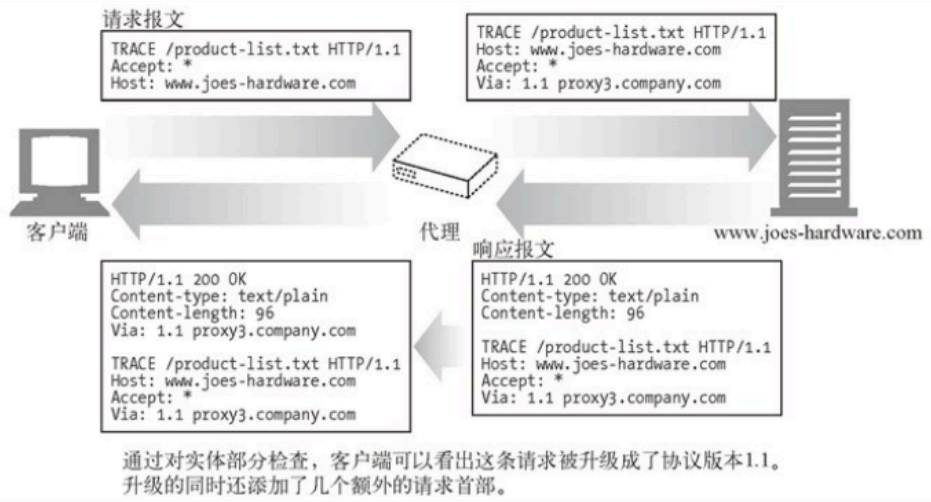
TRACE⽅法主要⽤于诊断,也就是说, ⽤于验证请求是否如愿穿过了请求——响应链。它也是⼀种很好的⼯具,可以⽤来查看代理和其他应⽤程序对⽤⼾请求所产⽣效果。尽管TRACE可以很⽅便地⽤于诊断, 但它确实也有缺点, 它假定中间应⽤程序对各种不同类型请求( 不同的⽅法–GET、HEAD、POST等) 的处理是相同的。很多HTTP应⽤程序会根据⽅法的不同做出不同的事情⼀⽐如, 代理可能会将POST请求直接发送给服务器, ⽽将GET请求发送给另⼀个HITP应⽤程序(⽐如Web缓存)。TRACE并不提供区分这些⽅法的机制。通常, 中间应⽤程序会⾃⾏决定对TRACE请求的处理⽅式。TRACE请求中不能带有实体的主体部分。TRACE响应的实体主体部分包含了响应服务器收到的请求的精确副本。
6.HEAD⽅法和GET ⽅法所消耗的服务端计算资源是⼀样的,只是服务端对 HEAD请求的响应不会包含正⽂,所以⽹络出⽅向的带宽消耗不⼀样。在 DDoS 攻击中,攻击者可能使⽤HEAD⽅法发起攻击,让服务器的⽹络出⽅向带宽不超过告警阙值,对服务器实施应⽤层的DDoS攻击,耗尽服务器的计算资源。
7.CONNECT⽅法⽤于在客⼾端和⽬标地址之间建⽴⼀个 TCP 隧道,这个时候 Web 服务器充当代理服务器,只有初始请求⽤的是 HTTP 协议,后续的所有双向流量都是在 TCP 连接上传输的。所以当 Web 服务器⽀持 CONNECT⽅法时,可⽤于建⽴从外⽹穿透到内⽹的传输隧道。
URI的全称是Uniform Resource Identifier,客⼾⽤其标识该HTTP请求要作⽤到服务器上的资源路径,URI再加上HOST头才是⼀个完整的互联⽹路径,即HOST+URI。但是当浏览器使⽤了正向代理时,这个URI就是完整的⽬标URL。
现代浏览器发出的HTTP 请求,其 HTTP 版本号主要是 1.1和2,更低的HTTP版本多⻅于API调⽤,因为部分应⽤的底层 HTTP 库还未升级。更⾼版本的 HTTP/3虽然已经正式发布但⽬前⽀持它的⽹站不多。
HTTP/1.1⽐HTTP/1.0 多了⼀些新特性。HTTP/1.1⽀持持久连接 (Keep-Alive),即允许复⽤⼀个TCP 连接完成多个HTTP 请求。HTTP/1.1还⽀持管线化 (Pipelining),即在⼀个TCP连接中客⼾端⽆须等待前⼀个请求的响应,就可以发送下⼀个请求,服务端只需要按照请求的顺序逐⼀响应即可。这个特性提升了 Web 应⽤的⽹络性能,但是在 HTTPFlood攻击中,攻击者利⽤这个特性能⼤幅提升攻击效率⼀⼀只需要建⽴少数的 TCP 连接,⽆须等待服务器响应就能在短时间内连续发送⼤量HTTP请求。
http请求首部字段介绍
host头
HTTP/1.1在请求中新增了HOST头用于虚拟主机的场景,即当一个ip地址上运行了多个网站时,web服务器通过HOST头中的域名即可判断要访问的目标网站是哪一个。在一些虚拟主机配置错误的服务器上,如果一个web应用使用任意HOST头都能正常访问,而且Web应用中有没有明确配置网站的域名,而是获取HOST头作为网站域名时,那么该应用就可能获取一个错误的域名。当攻击者通过恶意构造的HOST头访问时,如果应用内部需要获取网站域名用于关键业务逻辑,比如向该域名的网站发送敏感消息,就会将敏感信息发送给恶意域名。如果HOST头的域名会出现在缓存页面中(比如Web应用中使用了编译型模板,并且其中的某些URL是通过这个HOST头拼接生成的),攻击者使用恶意构成的HOST头访问这个网站,可能导致其他用户访问受污染的页面
user-agent头
HTTP请求中的User-Agent头用来指示当前访问者的客户端类型,它的值是客户端指定的,黑客工具通常会伪装成一个正常的浏览器的User-Agent,所以在Web应用中不能基于User-Agent的值来做关键业务逻辑决策。甚至User-Agent头中也可能包含恶意内容,例如攻击者可能向其中插入XSS Payload,以便对后端的日志分析平台实现XSS 盲打
referer头
Referer头指示了当前请求是从哪个URL页面发起的,在旧版本的Flash中这个值可以伪造但是在现代浏览器中不能通过javaScript伪造这个头,所以有些安全防御方案会用这个头校验请求来源。在javaScript中可以通过window.history对象的pushState和replaceState方法修改当前窗口的历史记录,但是仅能够将其修改为当前URL同源所以依赖Referer中的域名做来源校验还是可靠的,但只能信任其域名,而不能信任URL级别的内容
此外,当网页跳转到其他站点,或者加载其他站点资源时,会将当前URL作为Referer传递给其他站点,所以URL中一般不要包含敏感信息,以免信息泄露浏览器发送的 HTTP头的格式都是很标准的,⽽攻击者编写的⾃动化攻击程序通常是⼿⼯构造的 HTTP 头,与标准的 HTTP 头在某些⽅⾯可能会有细微差异,如空格、标点符号、头的个数等。通过这些细微差异,我们可识别出异常的访问者并进⾏处置。另外,使⽤不同浏览器访问同⼀个⻚⾯时,HTTP 头的个数和顺序也会有差异,甚⾄同⼀个浏览器在访问不同类型的资源时,或者在不同的场景中发出的请求,也会有差异 。这些细微的差异被安全产品⽤于鉴别访问者是不是真实⽤⼾。例如请求中的 User-Agent 宣称⾃⼰是 Firefox 浏览器⽽实际的HTTP头不符合Firefox 浏览器的特征,那么访问者可能篡改了 User-Agent,或者它其实是个⾃动化程序
content-type头
Content-Type(MediaType),即是Internet Media Type,互联⽹媒体类型,也叫做MIME类型。在互联⽹中有成百上千种不同的数据类型,HTTP在传输数据对象时会为他们打上称为MIME的数据格式标签,⽤于区分数据类型。最初MIME是⽤于电⼦邮件系统的,后来HTTP也采⽤了这⼀⽅案。
在HTTP协议消息头中,使⽤Content-Type来表⽰请求和响应中的媒体类型信息。它⽤来告诉服务端如何处理请求的数据,以及告诉客⼾端(⼀般是浏览器)如何解析响应的数据,⽐如显⽰图⽚,解析并展⽰html等等。
content-length头
Content-Length⾸部指示出报⽂中实体主体的字节⼤⼩,就是所传的具体内容的⻓度,这个⻓度是所传内容的确切⻓度。
HTTP响应
| 状态码 | 说明 |
|---|---|
| 100-199 | 表示已收到请求,但未完成操作,用于通知客户端 |
| 200-299 | 请求中的操作已成功完成 |
| 300-399 | 告知客户端执行额外的操作,通常用于跳转 |
| 400-499 | 客户端请求有错误 |
| 500-599 | 服务端出错 |
100 Continue 当客户端提交一个包含主体的请求时,将发送这个响应。该响应表示已收到请求消息头,客户端影继续发送主体。请求完成后,再由服务器返回另一个响应
200 OK 本状态码表示已成功提交请求,且响应主体中包含请求结果
201 Created 。PUT请求的响应返回这个状态码,表示请求已成功提交
301 Moved Permanently 本状态码将浏览器永久重定向到另外一个在Location消息头中指定的URL。以后客户端应使用新URL替换原始URL
302 Found 本状态码将浏览器暂时重定向到另外一个在Location消息头中指定的URL。客户端应在随后的请求中恢复使用原始URL
304 Not Modified 本状态码只是浏览器使用缓存中保存的所有请求资源的副本。服务器使用if-Modified-Since与if-None-Match消息头确定客户端是否拥有最新版本的资源
400 Bad Request 本状态码表示客户端提交了一个无效的HTTP请求。当以某种无效的方式修改请求时(例如在URL中插入一个空格符),可能会遇到这个状态码
401 Unauthorized 服务器在许可请求前要求HTTP进行身份验证。www-Authenticate消息头详细说明所支持的身份验证类型
403 Forbidden 本状态码指出,不管是否通过身份验证,禁止任何人访问被请求的资源
404 Not Found 本状态码表示所请求的资源并不存在
405 Method Not Allowed 本状态码表示指定的URL不支持请求中使用的方法。例如,如果试图在不支持PUT方法的地方使用该方法,就会收到本状态码
413 Request Entity Too large 则本状态码表示请求主体过长,服务器无法处理
414 Request URL Too Longo 本状态码表示请求中的URL过长,服务器无法处理
500 Internal Server Erroro 本状态码表示服务器在执行请求时遇到错误。当提交无法预料的输入、在应用程序处理过程中造成无法处理的错误时,通常会收到本状态码。应该仔细检查服务器响应的所有内容,了解与错误性质有关的详情。
503 Service Unavailableo 本状态码表示尽管Web服务器运转正常,并且能够响应请求,但服务器访问的应用程序还是无法做出响应。应该进行核实,是否因为执行了某种行为而造成这个结果
URL地址
- URL的全称为统一资源定位符
- URL链接里,每一条格式正确且符合规范的URL都对应着互联网中一个唯一的资源
- URL的语法规范,是浏览器地址栏的基础,也是用户使用浏览器访问互联网的重要安全指标
Scheme协议名称
Scheme是用来指定使用的传输协议,其中最常见的就是HTTP协议,它也是互联网中应用最广的协议
其他常用的协议还有:
file:用于访问资源位于本地计算机上的文件
ftp:用于访问FTP服务器上的资源
https:通过SSL协议的HTTP访问web服务器资源
mailto:访问资源属于电子邮件地址,通过SMTP协议访问
login:password
访问资源的身份认证
在URL中,身份验证属于可选项,在向服务器申请资源时,在某些情况下,需要指定一个用户名和密码。如果没有身份验证字段,浏览器默认以匿名方式访问资源
address:服务器地址
完整的层级URL必须有一个域名、IPV4或者IPV6地址作为请求服务器的位置。域名不区分大小写,IPV6需要括在方括号中
port:服务器端口
服务器端口是URL中可选内容,在没有指定端口时,会默认去访问协议的标准端口。基本上浏览器支持的协议都会有关联的默认服务接口。不过默认接口可以在URL中进行修改
/path/to/resource:层级文件路径
URL的这部分被称为层级文件路径,这一结构来源自UNIX目录语义,因此保留了对/ ; . / ; . . /的支持
?query_strting:查询字符串
查询字符串是一个非必须的字段,主要负责将一系列非层级格式的任意参数传递给指定的服务器资源
fragment:片段ID
片段ID一般用于指向页面中的某个锚点,将片段ID与预先设置的锚点名称匹配,并滚到相应的位置

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 11
11 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)