【AI大模型前沿】Tencent-HY-MT1.5:腾讯混元开源的多语言翻译模型
Tencent-HY-MT1.5是腾讯混元开源的翻译模型,包含两个版本:Tencent-HY-MT1.5-1.8B和Tencent-HY-MT1.5-7B。该模型支持33种国际语言互译及5种民汉/方言翻译,覆盖多种小语种。1.8B版本经过量化处理,仅需1GB内存即可在手机等消费级设备上实现端侧离线实时翻译,处理速度快;7B版本面向高性能场景,翻译准确率高,有效减少译文中夹带注释和语种混杂的情况。
系列篇章💥
目录
前言
在当今全球化加速的时代,语言之间的交流与协作变得愈发频繁。腾讯混元开源的Tencent-HY-MT1.5翻译模型,凭借其卓越的多语言翻译能力,为跨语言交流提供了强大的技术支持,极大地推动了信息的流通与共享。
一、项目概述
Tencent-HY-MT1.5是腾讯混元开源的翻译模型,包含两个版本:Tencent-HY-MT1.5-1.8B和Tencent-HY-MT1.5-7B。该模型支持33种国际语言互译及5种民汉/方言翻译,覆盖多种小语种。1.8B版本经过量化处理,仅需1GB内存即可在手机等消费级设备上实现端侧离线实时翻译,处理速度快;7B版本面向高性能场景,翻译准确率高,有效减少译文中夹带注释和语种混杂的情况。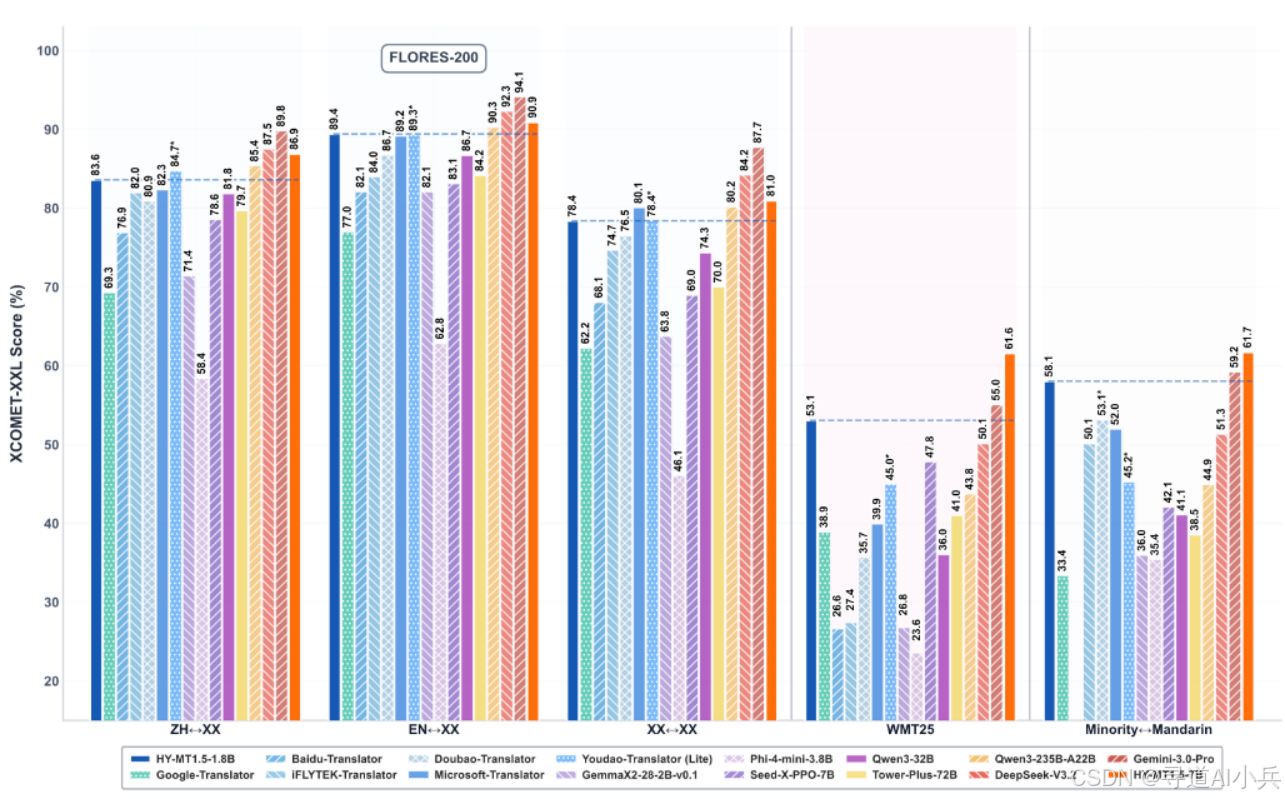
二、核心功能
(一)多语言支持
Tencent-HY-MT1.5涵盖33个语种的互译以及5种民汉/方言,除常见的中、英、日语等,还包括捷克语、马拉地语、爱沙尼亚语、冰岛语等小语种。
(二)端侧部署能力
HY-MT1.5-1.8B经过量化处理,仅需1GB内存即可在手机等消费级设备上实现离线实时翻译,处理50个tokens的平均耗时仅0.18秒,远快于主流商用翻译API的0.4秒。
(三)翻译质量高
HY-MT1.5-1.8B在FLORES-200等权威测试集中,效果达到Gemini-3.0-Pro等超大尺寸闭源模型的90分位水平,全面超越中等尺寸开源模型。
(四)实用性增强
支持术语库自定义、上下文长文本理解以及带格式文本翻译,用户可导入专业术语表,模型能基于前文语境优化后续翻译,并保留原始排版格式。
三、技术揭秘
(一)On-Policy Distillation策略
1.8B模型采用了On-Policy Distillation(大尺寸模型蒸馏)策略,由7B大模型作为教师实时引导训练,避免小模型死记硬背标准答案,通过纠正在预测序列分布时的偏移,让小模型从错误中学习,显著提升了小模型的泛化能力和翻译质量。
(二)术语库自定义
用户可针对不同行业与专业场景构建专属术语对照表,导入术语库后,模型在翻译过程中会优先采纳用户定义的标准术语,确保关键术语的准确性和一致性。
(三)上下文翻译
模型具备长文本与对话上下文理解能力,可基于前文语境持续优化后续翻译结果,适用于会议记录、访谈内容、小说章节、技术文档等长篇内容的翻译。
(四)带格式翻译
模型能保持翻译前后的格式信息不变,适用于网页、文档等结构化内容的翻译。
四、性能表现
(一)性能对比
在常用的中外互译和英外互译测试集Flores200、WMT25以及民汉语言的测试集中,Tencent-HY-MT1.5-1.8B全面超越Qwen3-32B等中等尺寸开源模型和主流商用翻译API,达到Qwen3-235B-A22B等大尺寸闭源模型的90分位水平。
(二)响应速度
在翻译质量与响应效率上,HY-MT1.5-1.8B模型在FLORES-200质量评估中取得了约78%的分数,同时平均响应时间仅为0.18秒,超越主流商用翻译API。
(三)量化实验
对于HY-MT1.5-1.8B模型,测试了两种量化策略(Int4和FP8),并采用GPTQ算法进行后训练量化(PTQ),以最小化误差。量化后的模型在不同翻译任务上的表现接近原始模型,其中FP8量化在保持准确性方面表现优异。
五、应用场景
(一)移动设备翻译
Tencent-HY-MT1.5-1.8B经过量化处理,仅需1GB内存即可在手机等消费级设备上实现端侧离线实时翻译,适用于移动设备上的即时翻译需求,如旅行中的语言交流、即时通讯中的跨语言对话等。
(二)高性能翻译服务
Tencent-HY-MT1.5-7B面向高性能场景,适合部署在云端,为需要高翻译质量的企业级应用提供服务,如跨国企业的文档翻译、专业领域的技术文档翻译等。
(三)多语言内容创作
支持33种国际语言互译及5种民汉/方言翻译,能满足内容创作者在多语言环境下的创作需求,如多语言视频字幕制作、跨语言文学创作等。
(四)专业术语翻译
支持术语库自定义,用户可导入专业术语表,模型在翻译过程中会优先采纳用户定义的标准术语,适用于专业领域的翻译需求,如医学、法律、科技等行业的翻译。
(五)长文本翻译
具备长文本与对话上下文理解能力,能基于前文语境持续优化后续翻译结果,适用于会议记录、访谈内容、小说章节、技术文档等长篇内容的翻译。
(六)格式化内容翻译
能保持翻译前后的格式信息不变,适用于网页、文档等结构化内容的翻译,确保翻译后的格式与原文一致。
六、快速使用
(一)prompt模板示例
1、中外互译prompt模板
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:
{source_text}
2、外外互译prompt模板
Translate the following segment into {target_language}, without additional explanation.
{source_text}
3、术语干预模板
参考下面的翻译:
{source_term} 翻译成 {target_term}
将以下文本翻译为{target_language},注意只需要输出翻译后的结果,不要额外解释:
{source_text}
4、上下文翻译模板
{context}
参考上面的信息,把下面的文本翻译成{target_language},注意不需要翻译上文,也不要额外解释:
{source_text}
5、带格式翻译模板
将以下<source></source>之间的文本翻译为中文,注意只需要输出翻译后的结果,不要额外解释,原文中的<sn></sn>标签表示标签内文本包含格式信息,需要在译文中相应的位置尽量保留该标签。输出格式为:<target>str</target>
<source>{src_text_with_format}</source>
(二)transformers推理
1、安装依赖
pip install transformers==4.56.0
2、推理示例
from transformers import AutoModelForCausalLM, AutoTokenizer
import os
model_name_or_path = "tencent/HY-MT1.5-1.8B"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, device_map="auto") # You may want to use bfloat16 and/or move to GPU here
messages = [
{"role": "user", "content": "Translate the following segment into Chinese, without additional explanation.\n\nIt’s on the house."},
]
tokenized_chat = tokenizer.apply_chat_template(
messages,
tokenize=True,
add_generation_prompt=False,
return_tensors="pt"
)
outputs = model.generate(tokenized_chat.to(model.device), max_new_tokens=2048)
output_text = tokenizer.decode(outputs[0])
官方推荐使用以下参数集进行推理。请注意,该模型没有默认的 system_prompt。
{
"top_k": 20,
"top_p": 0.6,
"repetition_penalty": 1.05,
"temperature": 0.7
}
(三)vLLM推理
1、安装依赖
pip install git+https://github.com/huggingface/transformers@4970b23cedaf745f963779b4eae68da281e8c6ca
# 以tencent/Hunyuan-7B-Instruct为例,提前准备获取模型地址
export MODEL_PATH=PATH_TO_MODEL
2、推理示例
import os
from typing import List, Optional
from vllm import LLM, SamplingParams
from vllm.inputs import PromptType
from transformers import AutoTokenizer
model_path=os.environ.get('MODEL_PATH')
tokenizer = AutoTokenizer.from_pretrained(model_path, trust_remote_code=True)
llm = LLM(model=model_path,
tokenizer=model_path,
trust_remote_code=True,
dtype='bfloat16',
tensor_parallel_size=4,
gpu_memory_utilization=0.9)
sampling_params = SamplingParams(
temperature=0.7, top_p=0.8, max_tokens=4096, top_k=20, repetition_penalty=1.05)
messages = [
{
"role": "system",
"content": "You are a helpful assistant.",
},
{"role": "user", "content": "Write a short summary of the benefits of regular exercise"},
]
tokenized_chat = tokenizer.apply_chat_template(messages, tokenize=True, add_generation_prompt=True, return_tensors="pt")
dummy_inputs: List[PromptType] = [{
"prompt_token_ids": batch
} for batch in tokenized_chat.numpy().tolist()]
outputs = llm.generate(dummy_inputs, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
其他更多部署详情请查看官网地址:https://github.com/Tencent-Hunyuan/HY-MT/blob/main/README_CN.md
七、结语
Tencent-HY-MT1.5凭借其强大的多语言翻译能力、高效的端侧部署性能以及卓越的翻译质量,为跨语言交流和多语言内容创作提供了有力的工具。无论是在移动设备上的即时翻译,还是在云端的高性能翻译服务,亦或是专业领域的术语翻译和长文本翻译,Tencent-HY-MT1.5都能满足用户的不同需求。其开源的特性也使得开发者可以自由地使用和改进模型,为推动人工智能翻译技术的发展贡献自己的力量。
项目地址
- GitHub仓库:https://github.com/Tencent-Hunyuan/HY-MT
- Hugging Face模型库:https://huggingface.co/collections/tencent/hy-mt15

🎯🔖更多专栏系列文章:AI大模型提示工程完全指南、AI大模型探索之路(零基础入门)、AI大模型预训练微调进阶、AI大模型开源精选实践、AI大模型RAG应用探索实践🔥🔥🔥 其他专栏可以查看博客主页📑
😎 作者介绍:资深程序老猿,从业10年+、互联网系统架构师,目前专注于AIGC的探索(CSDN博客之星|AIGC领域优质创作者)
📖专属社群:欢迎关注【小兵的AI视界】公众号或扫描下方👇二维码,回复‘入群’ 即刻上车,获取邀请链接。
💘领取三大专属福利:1️⃣免费赠送AI+编程📚500本,2️⃣AI技术教程副业资料1套,3️⃣DeepSeek资料教程1套🔥(限前500人)
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我们,一起携手同行AI的探索之旅,开启智能时代的大门!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 18
18 0
0- 0



 已为社区贡献49条内容
已为社区贡献49条内容

所有评论(0)