嵌入式AI:STM32F103运行TinyML,正弦波模型的性能分析!
从下面图片可以看出,Flash和RAM的实际占用大小如下:Flash 实际占用 = text + data = 156812 + 108 =156920 字节(≈153.24 KB)RAM 实际占用 = data + bss = 108 + 5128 =5236 字节(≈5.11 KB)在STM32F103运行正弦波模型这件事,证明了下面两点。
今天,计划再花一些时间深入的讲解一下,为什么像STM32F103这类“低端”的MCU也能跑起来AI模型。本文中主要从三个方面进行介绍:
-
模型为什么能在 STM32F103 上跑起来?
-
跑起来占了多少资源?
-
跑起来到底快不快?
关于运行结果对不对,相信从上面的视频中大家会有所感受,不是本文要讨论的范畴。
后面我会再准备一篇文章重点讲解从数据采集、到模型设计、到模型裁剪等一系列内容讲解如何提高运行精度。
首先看实际模型运行时打印的效果:
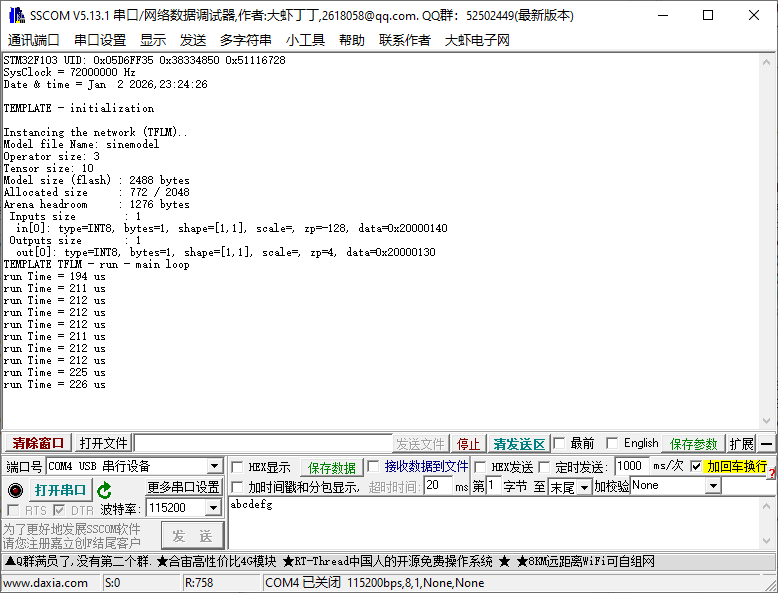
基于上面图片中显示出来的参数,引出来我们需要关注的几个重要参数,这些参数决定了设计的模型能否正确并且高效的运行在MCU中。

1.硬件信息以及实现的功能
-
芯片型号:STM32F103RCT6
-
系统时钟:72M
-
芯片Flash:256KB
-
芯片RAM:48KB
TInyML的Helloworld的Demo实现的功能见视频所示。其中包括了下面的几个功能。包含的模块以及功能如下:
-
串口:通过UART1将数据发送给上位机工具;
-
LED:通过LED状态切换,证明程序正在运行
-
定时器:TIM2,用于计数,计算模型推理所需要的时间。
2.模型相关参数:
2.1、模型名字(Model file Name: sinemodel)
模型名称这个参数是在从.tflite格式的文件,转换为MCU可识别的数组的时候自行产生的。(可以加入我的课程,来学习如何将模型部署到MCU上)
这个参数看似没用,但是在多模型场景下使用或者在需要对模型升级的时候,是比较有用的,它可以用来区分不同的模型版本或者区分不同的任务模型。
这个参数只是一个字符串的形式存在于MCU中。
将模型的数据存储到MCU的指定位置,就可以看做是程序的一部分,在遇到需要进行更新或升级的时候,可以参考OTA升级的流程,对模型文件进行更新。
在我的课程中,会专门介绍如何通过OTA升级模型文件。
2.2、Operator size:3
Operator size参数对应的是,模型计算图中需要执行的算子节点数量。下面图片是使用netron打开的模型文件,从模型文件中可以看出,可以看到我的模型是三层 FullyConnected算子组成。
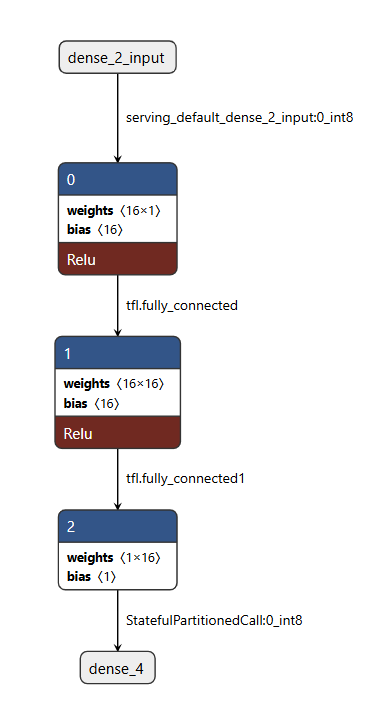
在实际使用过程中:
算子越多,解释器调度步骤越多,通常推理耗时越长;
算子越多、类型越复杂,你需要链接进固件的算子内核代码也越多,Flash 占用会上升。
现在我们在使用的sinemode的算子只有三层。
2.3、Tensor size: 10
tensor是张量对象数量。张量在这里不是“一个数组”这么简单,而是“数组 + 元信息(数据类型、形状、量化参数、数据指针等)”。
这 10 个张量通常包含输入、输出、每一层的中间激活、权重、偏置以及必要的常量张量。
张量数量增多往往意味着图更复杂,Arena 规划更复杂,对调试与内存预算都不利,但它不是决定 RAM 占用的唯一因素,真正决定 Arena 峰值的是“中间激活的峰值体积 + 算子的临时缓冲需求”。
2.4、Model size (flash) : 2488 bytes
Model size是模型文件本体(TFLite flatbuffer)在 Flash 中占用的大小。它是最直观的“模型是否放得下”的指标之一。
对 STM32F103 这种只有 256KB Flash 的芯片而言,模型本体往往只是 Flash 占用的一部分,另一大部分是 TFLM 运行库与算子内核代码,以及我们的业务代码、驱动代码、日志代码。模型大小会被参数量、权重类型(int8/float32)、是否包含额外 metadata 等影响。
(如果想要本Demo的工程,可以私信我)
在我们的这个例子中,之所以只有 2.4KB,是因为参数量很小且权重是 int8/量化形式。
2.5、Allocated size: 772 / 2048、Arena headroom: 1276 bytes ,
Arena headroom: 1276 bytes ,其中2048 是我们程序中给 Tensor Arena 预留的总 RAM的大小,772 是 TFLM 在 AllocateTensors() 后实际占用的 RAM,headroom 是剩余空间。
在这里我们可以理解为:我们为推理划了一块“专用内存池”,TFLM 把所有推理过程中需要反复读写的中间数据都放在这里。Arena 不够,模型直接跑不起来;headroom 太小,模型稍微迭代就容易溢出。因为我们现在的模型足够小,网络也小,所以占用只有 772B;
3.性能介绍:
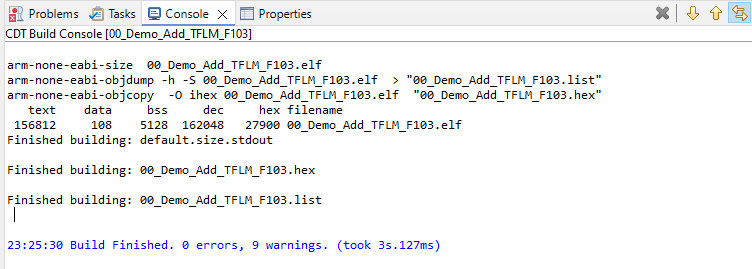
3.1、Flash和RAM占用
从下面图片可以看出,Flash和RAM的实际占用大小如下:
-
Flash 实际占用 = text + data = 156812 + 108 = 156920 字节(≈153.24 KB)
-
RAM 实际占用 = data + bss = 108 + 5128 = 5236 字节(≈5.11 KB)
3.2、模型推理用时
为了计算推理我们使用了TIM2的计数功能。配置如下
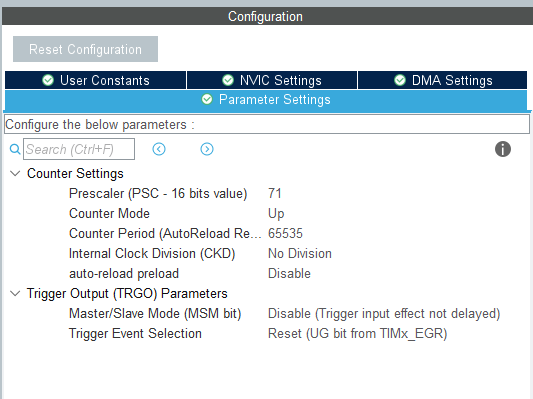
计算推理用时的代码如下:
do
{
__HAL_TIM_SET_COUNTER(&htim2, 0);
/**
* 1.记录程序开始时的计数值
*/
start_tick = __HAL_TIM_GET_COUNTER(&htim2);
/**
* 2.开始执行推理和计算
*/
res = acquire_and_process_data(in_data);
if (res == 0)
{
if (tflm_c_invoke(model_hdl) != kTfLiteOk) //调用推理
{
res = -1;
}
}
if (res == 0)
{
res = post_process(out_data);
/**
* 3.记录推理结束时候的计数
*/
end_tick = __HAL_TIM_GET_COUNTER(&htim2);
/**
* 4.计算运行的时间
*/
run_time_us = end_tick - start_tick;
printf("run Time = %d us\r\n", run_time_us);
}
/**
* 5.输出给串口,通过曲线对比理论计算值和推理计算的数值
*/
#if 1
int16_t sin_i = (int16_t)(y_ref * 1000.0f) + 1000;
int16_t out_i = (int16_t)(y_pred * 1000.0f) + 1000;
uint8_t ucsendBuf[11] = {0x7E,0x08,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x7F};
ucsendBuf[2] = (uint8_t)(sin_i & 0x00FF);
ucsendBuf[3] = (uint8_t)((sin_i & 0xFF00) >> 8);
ucsendBuf[4] = (uint8_t)(out_i & 0x00FF);
ucsendBuf[5] = (uint8_t)((out_i & 0xFF00) >> 8);
HAL_UART_Transmit(&huart1, (uint8_t *)ucsendBuf, 11, HAL_MAX_DELAY);
#endif
HAL_Delay(200);
}
while (res==0);通过上面代码计算,可以发现实际数学计算和推理占用的时间约为:220us

4.总结:
在STM32F103运行正弦波模型这件事,证明了下面两点。
1.在资源并不宽裕的 MCU 上,AI 模型不仅能跑,而且能把“模型体积、RAM 占用、输入输出量化参数、初始化与稳态推理耗时”这些关键指标全部量化出来,让部署从“演示能跑”变成“工程可控、可复现、可迭代”。
2.真正决定能不能把模型做得更快、更稳、更省资源的,并不是换一块更贵的芯片,而是我们是否掌握从数据量化对接、Tensor Arena 内存预算,到算子选择与执行链路优化、性能测量与瓶颈定位的完整方法。
跟我系统学习,你不仅能把模型稳定部署到 MCU 上,还能进一步把推理耗时压下来、把内存余量做出来、把精度与性能的权衡讲清楚,最终做到“能上产品、能持续迭代”。
5.欢迎来了解真正属于嵌入式工程师的实战课程:

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 12
12 0
0- 0



 已为社区贡献10条内容
已为社区贡献10条内容

所有评论(0)