嵌入式AI:TinyML为什么会存在,因为云端AI并不总是最优解
【摘要】课程《AI+嵌入式:让单片机学会思考》引发对TinyML价值的讨论。针对"为何不用云端AI"的质疑,文章从三个维度阐述TinyML的不可替代性:1)高可靠性:在弱网环境下保持基础功能运行;2)快速响应:本地推理实现确定性的低延迟;3)数据筛选:避免高频连续流数据的全量上传成本。TinyML特别适用于网络不稳定、要求实时响应或需处理大量原始数据的场景,如工业控制、安全监测
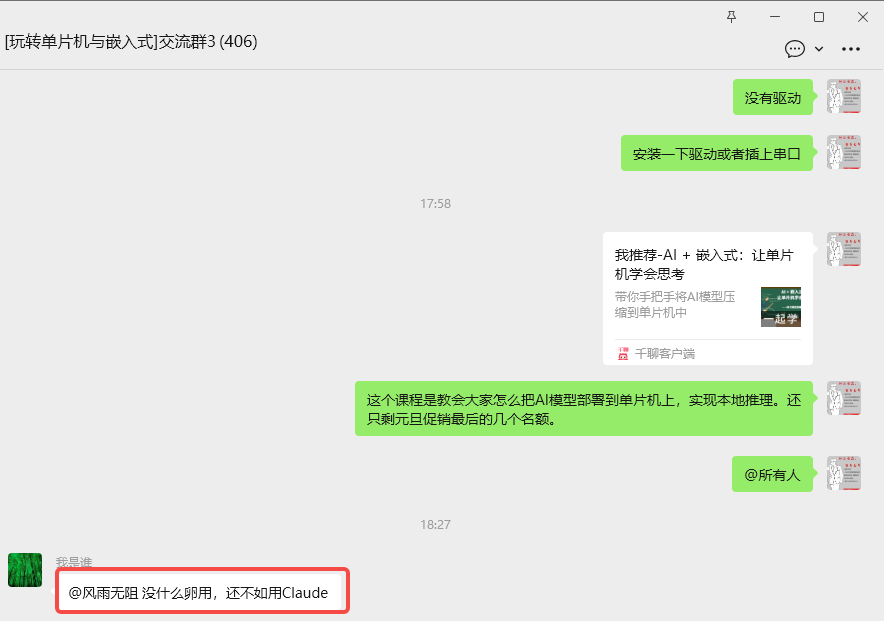
我的课程【AI+嵌入式:让单片机学会思考】,受到了越来越多同学的关注和学习报名,也顺便引来了越来越多的质疑:
“把数据发到服务器,让云端算完再把结果下发,不就行了吗?云端算力又大又方便。”。
甚至有一些是怀疑TinyML的价值,比如下面这位群友的回复:“没什么卵用,还不用用Claude”
今天只围绕一个点讲清楚:已经有了足够强大的云端AI了,TinyML为什么会存在。
先说结论:云端并不总是最佳答案,所以TinyML才会出现并快速普及。
下面我列举一些使用TInyML而不是使用云端AI的几种场景。
一:TInyML的高可靠性 VS 网络不稳定,连接质量不可控

我们应该已经比较清楚了,云端AI的数据流是下面这样:
传感器/设备采集 → 上行网络 → 云端推理/训练 → 下发结果/控制指令。
从上面的流程可以看出,主要依赖网络的位置有两个点:
-
数据上行:设备采集的数据发送到网络。
-
命令下行:网络计算后将推理结果或控制指令下发给设备
当上面的上行/下行的链路中出现不稳定的时候,系统就会出现很大问题。
-
可用性下降:设备明明采集到了异常,但上行失败、云端没收到,到云端的报警丢了。
-
体验变差:同样的动作,有时很快,有时延迟很大,行为不可预测。
所以,TinyML 的思路是:先在设备端完成基础判断与触发,即使上云不稳定,设备也能完成最基本的保护、告警、记录;
等待网络稳定或者需要时(如定时)再把“事件”或“摘要信息”上传。
二:TInyML的快速响应 VS 运算AI的延时
针对一些特定的场景,要的不是“计算量足够大”,而是“响应更确定”

我们都知道云端的算力很强大,但云端推理的“快”并不等于系统响应快”。因为整个数据处理的链路中还要叠加网络往返时间、排队、重传等不确定因素(我相信做过网络通信的同学们应该清楚这点)。
对一些场景来说,这种延时以及不确定性就是不可接受,例如:
-
保护类控制:电机过载、卡死、异常振动,需要立即做保护动作。
-
安全类告警:异常声学/振动窗口很短,错过就难以复现。
-
交互类体验:唤醒词、手势等,如果响应时间波动明显,用户会直观感到“迟钝”。
TinyML 把推理放在本地,最大的价值之一就是:把“采集→判断→动作”的闭环变短,并且让时延可控、可复现。
三:TInyML的高价值事件 VS 运算AI的大数据量
我们做过嵌入式项目的,应该比较清楚:很多嵌入式数据不是“偶尔一条”,而是连续高速采样。比如振动、音频、电流波形、加速度等。这类数据的共性是:真正有用的往往是少数异常片段,但如果你选择全量上传,成本会非常高。
举个工程上常见、也容易算清楚的例子(只算三轴加速度):
-
采样率:6 kHz
-
三轴,每轴 16-bit(2 字节)
-
每秒数据量:6000 × 3 × 2 = 36000 字节 ≈ 36 KB/s
-
每天数据量:36 KB/s × 86400 ≈ 3.1 GB/天(单台设备)
如果是一批设备同时在线,带宽、存储、云端处理、运维成本会快速累积。最终你会发现:云端不是不能做,而是“把所有原始数据都送上去再处理”性价比很低。
TinyML 更常用的做法是:设备端直接做好筛选和推理
正常时只做轻量推理或特征统计;检测到疑似异常时,上传“事件时间戳 + 置信度 + 特征摘要”,必要时再上传短片段原始数据。
四:什么时候应该优先考虑 TinyML?
如果你的项目满足下面任意一条,TinyML 往往值得优先评估:
-
网络质量或可用性不可保证(弱网、断网、覆盖差、出海等)
-
必须低延迟且时延要稳定(控制、保护、交互类)
-
原始数据是高频连续流(振动、音频、波形等),全量上云成本高
-
系统必须在云端不可用时仍能完成核心功能

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 16
16 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)