强化学习+GRPO
每个状态可能做出多个动作,而且每个动作可能到达多个状态,图中的Π称之为策略或决策,P称为状态转移概率,我们将这马尔可夫过程称为。马尔可夫过程由五个基本的元素组成,S表示状态,A表示动作,P表示状态转移概率,γ表示折扣因子,R表示奖励(有时也称回报函数)。简单说:就是智能体在一个状态S下,选择了某个动作A,进入了另外一个状态S’,并获得奖励R的过程。如果(s,a)对应的下个状态s’是唯一的,那么回报
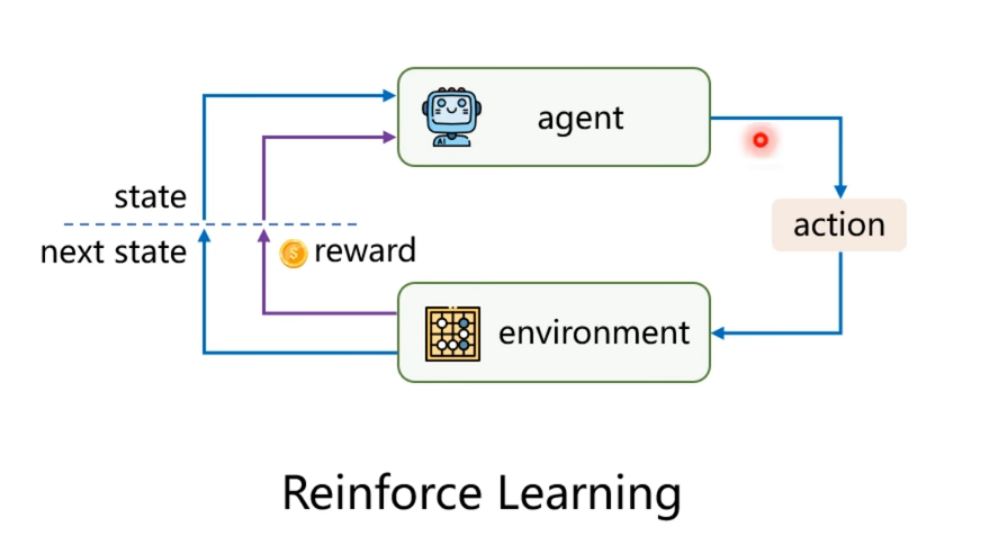
强化学习:
决策框架:马尔可夫决策过程
马可洛夫链描述的是智能体和环境进行互动的过程。简单说:就是智能体在一个状态S下,选择了某个动作A,进入了另外一个状态S’,并获得奖励R的过程。
马尔可夫过程由五个基本的元素组成,S表示状态,A表示动作,P表示状态转移概率,γ表示折扣因子,R表示奖励(有时也称回报函数)。
S: 表示状态集(states),有s∈S,si表示第i步的状态。
A: 表示一组动作(actions),有a∈A,ai表示第i步的动作。
P: 表示状态转移概率。
γ:折扣因子。
R: S×A⟼ℝ ,R是回报函数(reward function)。 有些回报函数状态S的函数,可以简化为R:
S⟼ℝ。如果一组(s,a)转移到了下个状态s’,那么回报函数可记为r(s’|s,
a)。如果(s,a)对应的下个状态s’是唯一的,那么回报函数也可以记为r(s,a)。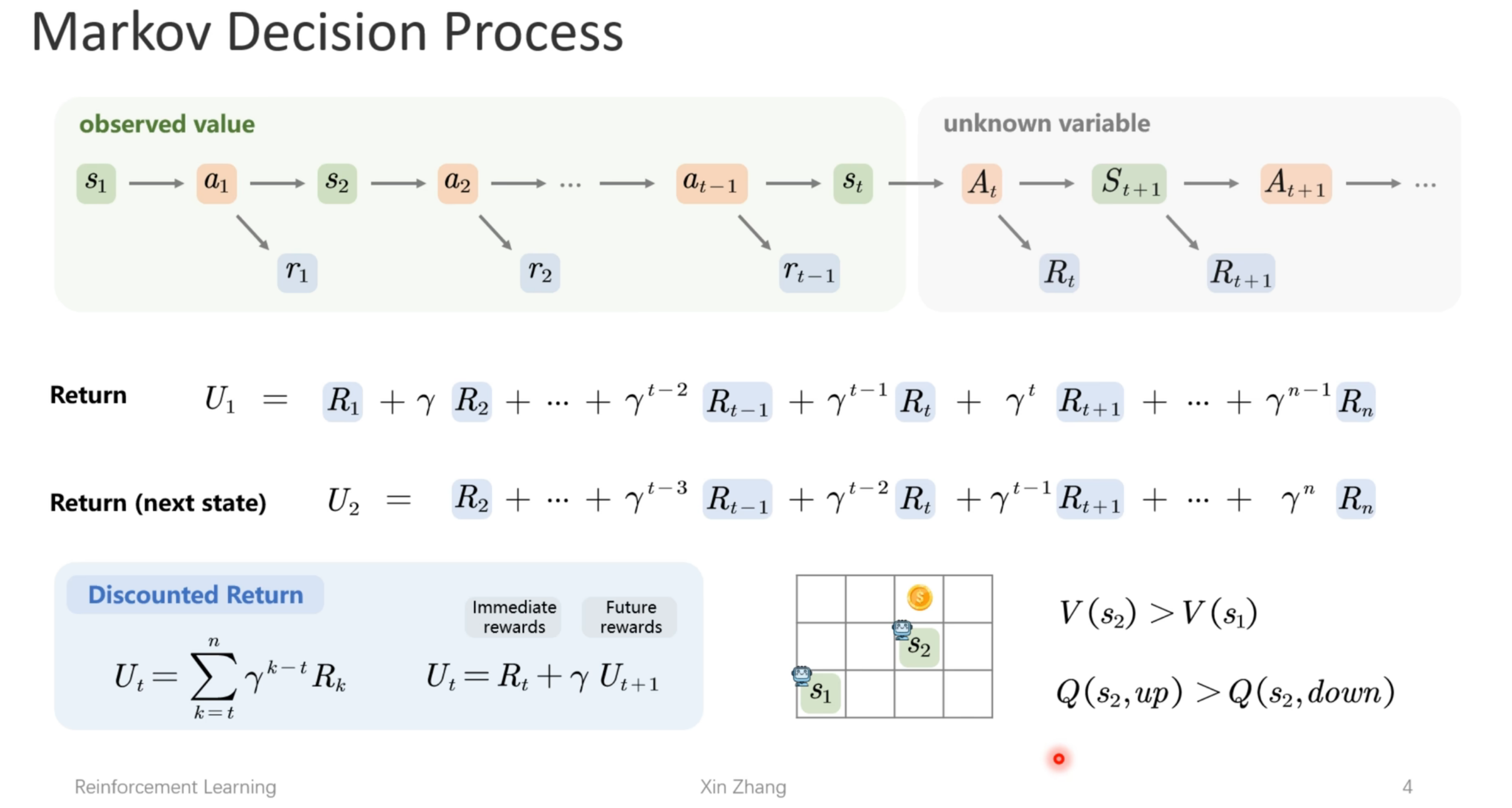
站在当前状态或者称之为初始状态从现在往前看,每个状态可能做出多个动作,而且每个动作可能到达多个状态,图中的Π称之为策略或决策,P称为状态转移概率,我们将这马尔可夫过程称为马尔可夫树。

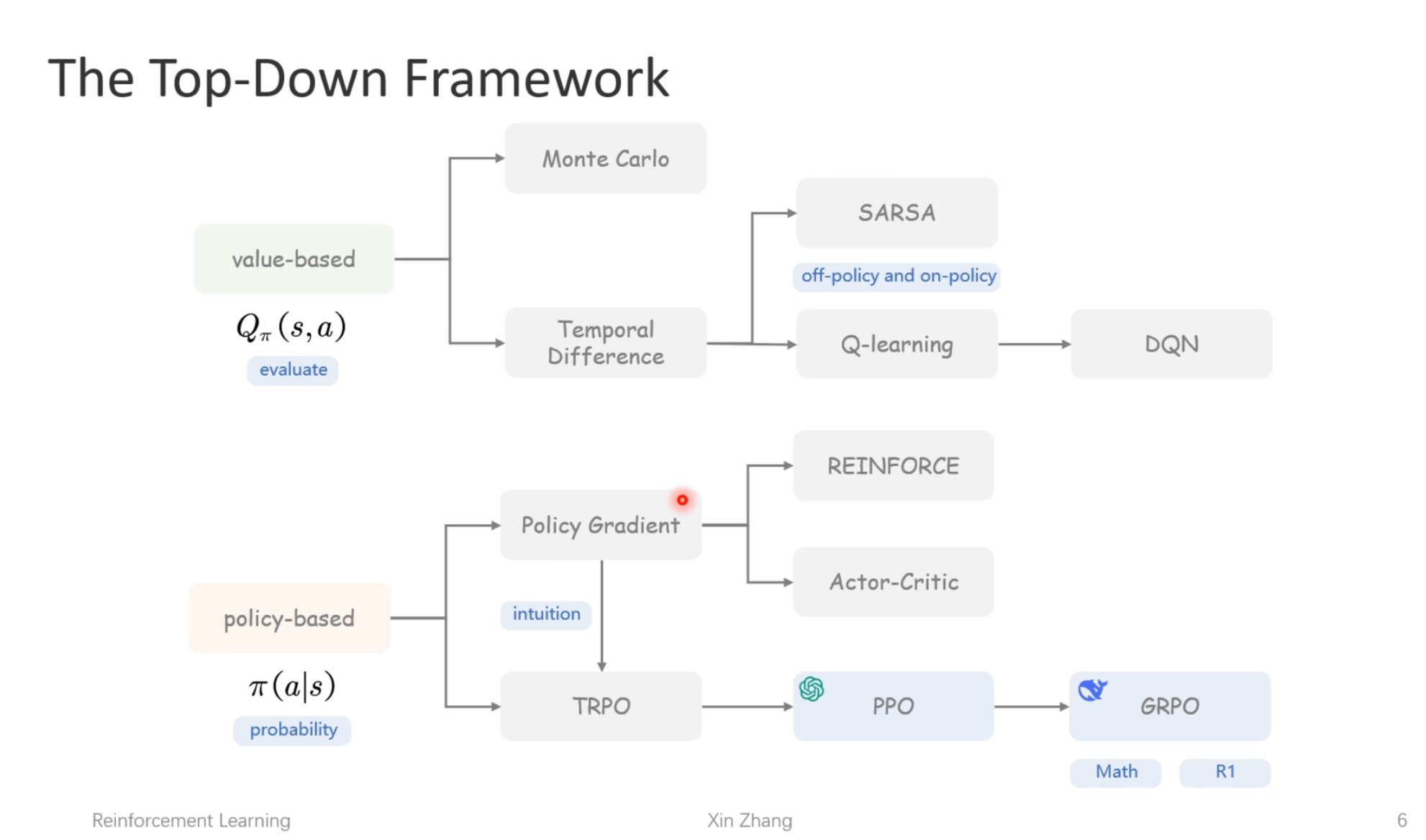
时序差分:

莫特卡罗:方差大
时序差分:
policy based:

让reward大的action被选中概率也大

Policy Gradient Problem:
设置可信域
TRPO:

PPO:

https://verl.readthedocs.io/en/latest/algo/grpo.html
SFT: https://github.com/volcengine/verl/blob/main/verl/trainer/fsdp_sft_trainer.py
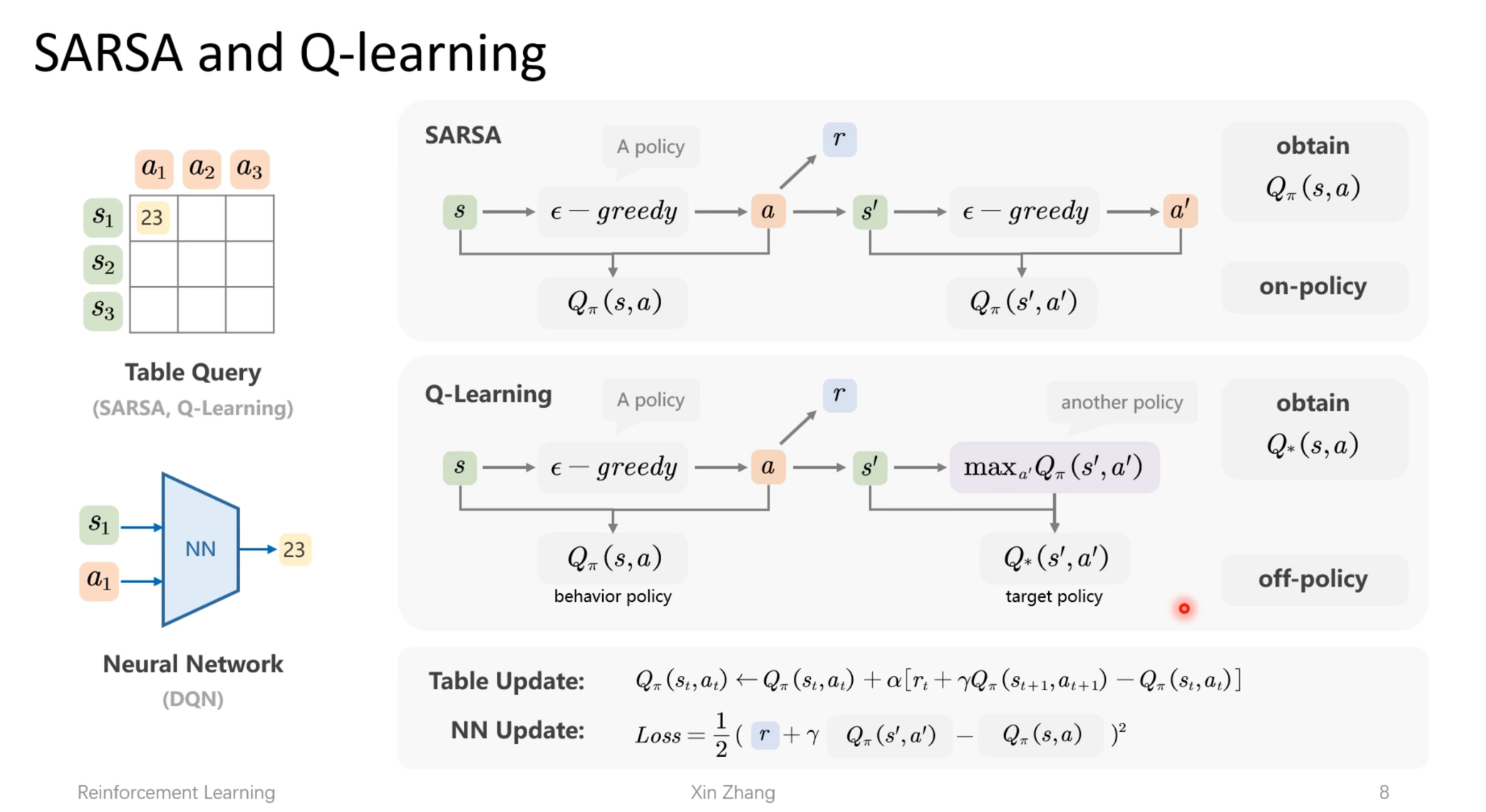
在强化学习中,像 PPO 这样的经典算法依赖于“评价模型”来评估动作的价值,从而指导学习过程。然而,训练这种评价模型可能会耗费大量资源。
GRPO 简化了这一过程,无需单独的批评模型。它的运作方式如下:
-
组抽样:对于给定的问题,模型会生成多个可能的解决方案,形成一个输出“组”。
-
奖励分配:根据每个解决方案的正确性或质量进行评估并分配奖励。
-
基线计算:以小组平均奖励作为基线。
-
策略更新:模型通过将每个解决方案的奖励与组基线进行比较来更新其参数,强化优于平均水平的解决方案并阻止差于平均水平的解决方案。
-
actor_rollout.ref.rollout.n:每个提示,采样 n 次。默认为 1。对于 GRPO,请将其设置为大于 1 的值,以便进行分组采样。 -
data.train_batch_size:用于生成一组采样轨迹/rollouts的提示的全局批量大小。响应/轨迹的数量为data.train_batch_size * actor_rollout.ref.rollout.n -
actor_rollout_ref.actor.ppo_mini_batch_size:采样轨迹集被拆分为多个小批量,每个小批量的 batch_size 等于 ppo_mini_batch_size,用于 PPO 角色更新。ppo_mini_batch_size 是所有工作器都适用的全局大小。 -
actor_rollout_ref.actor.ppo_epochs:针对参与者的一组采样轨迹进行 GRPO 更新的时期数 -
actor_rollout_ref.actor.clip_ratio:GRPO 剪辑范围。默认为 0.2 -
algorithm.adv_estimator:默认为 gae。请将其设置为 grpo -
actor_rollout_ref.actor.loss_agg_mode:默认值为“token-mean”。选项包括“token-mean”、“seq-mean-token-sum”和“seq-mean-token-mean”。原始 GRPO 论文采用样本级损失(seq-mean-token-mean),这在长 CoT 场景下可能不稳定。verl 中提供的所有 GRPO 示例脚本均使用默认配置“token-mean”进行损失聚合。
GRPO 不是在奖励中添加 KL 惩罚,而是通过将训练策略与参考策略之间的 KL 散度直接添加到损失中进行正则化:
-
actor_rollout_ref.actor.use_kl_loss:在 Actor 中使用 KL 损失。使用时,我们不会在奖励函数中应用 KL。默认值为 False。对于 GRPO,请将其设置为 True。 -
actor_rollout_ref.actor.kl_loss_coef:kl损失的系数,默认为0.001。 -
actor_rollout_ref.actor.kl_loss_type:支持 kl(k1)、abs、mse(k2)、low_var_kl(k3) 和 full。在末尾添加“+”(例如“k1+”和“k3+”)将直接应用 k2 进行无偏梯度估计,而无需考虑 kl 值估计

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献5条内容
已为社区贡献5条内容

所有评论(0)