PaddleX本地安装教程
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。下面主要是官方文档,源地址:PaddleX 文档官方文档:开始使用_飞桨-源于产业实践的开源深度学习平台PaddlePaddle3.3安装,cuda12.6二、PaddleX安装注意:若您使用PaddleX的应用场
PaddleX 3.0 是基于飞桨框架构建的低代码开发工具,它集成了众多开箱即用的预训练模型,可以实现模型从训练到推理的全流程开发,支持国内外多款主流硬件,助力AI 开发者进行产业实践。
下面主要是官方文档,源地址:PaddleX 文档
一、安装飞桨 PaddlePaddle
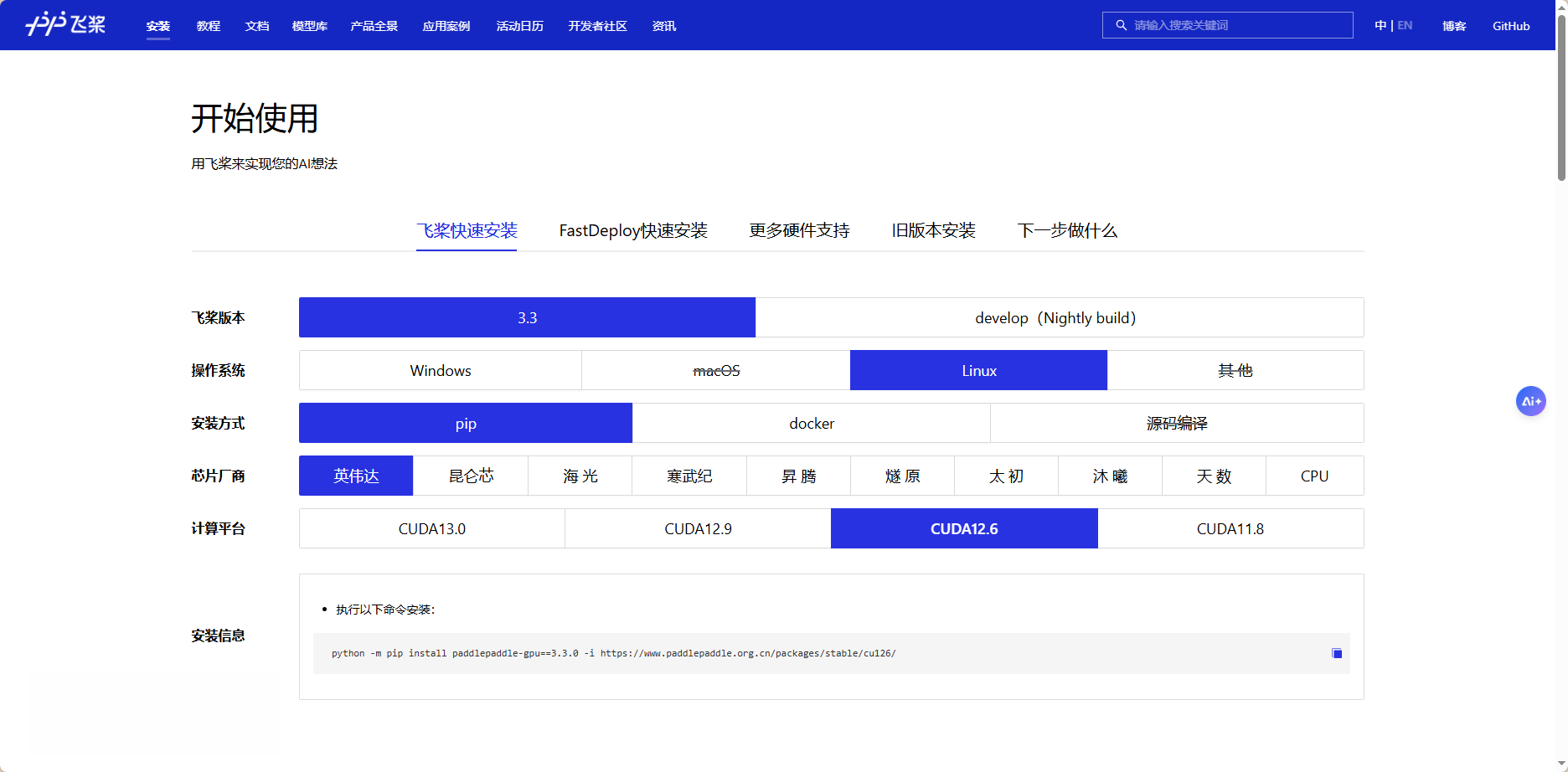
PaddlePaddle3.3安装,cuda12.6
python -m pip install paddlepaddle-gpu==3.3.0 -i https://www.paddlepaddle.org.cn/packages/stable/cu126/二、PaddleX安装
注意:
在安装 PaddleX 之前,请确保您已具备基本的 Python 运行环境(注:目前支持 Python 3.8 至 Python 3.12)。PaddleX 3.0-rc1 版本依赖的 PaddlePaddle 版本为 3.0.0以上版本。
1. 快速安装
欢迎您使用飞桨低代码开发工具PaddleX,在我们正式开始本地安装之前,请首先明确您的开发需求,并根据您的需求选择合适的安装模式。 PaddleX为您提供了两种安装模式:Wheel包安装和插件安装,下面分别对其应用场景进行介绍:
1.1 Wheel包安装模式
若您使用PaddleX的应用场景为模型推理与集成 ,那么推荐您使用更便捷、更轻量的Wheel包安装模式。
快速安装轻量级的Wheel包之后,您即可基于PaddleX支持的所有模型进行推理,并能直接集成进您的项目中。
您可直接执行如下指令快速安装PaddleX的Wheel包:
# 仅安装必须依赖(可以在之后按需安装可选依赖)
pip install paddlex通过如下方式可以安装所需的可选依赖:
安装 PaddleX “基础功能”需要的全部依赖:
pip install "paddlex[base]"仅安装某项功能所需依赖:
pip install "paddlex[ocr]"1.2 插件安装模式
若您使用PaddleX的应用场景为二次开发 (例如重新训练模型、微调模型、自定义模型结构、自定义推理代码等),那么推荐您使用功能更加强大的插件安装模式。
安装您需要的PaddleX插件之后,您不仅同样能够对插件支持的模型进行推理与集成,还可以对其进行模型训练等二次开发更高级的操作。
PaddleX支持的模型训练相关插件如下,请您根据开发需求,确定所需的一个或多个插件名称:
👉 插件和产线对应关系(点击展开)
| 模型产线 | 模块 | 对应插件 |
|---|---|---|
| 通用图像分类 | 图像分类 | PaddleClas |
| 通用目标检测 | 目标检测 | PaddleDetection |
| 通用语义分割 | 语义分割 | PaddleSeg |
| 通用实例分割 | 实例分割 | PaddleDetection |
| 通用OCR | 文档图像方向分类 文本图像矫正 文本检测 文本行方向分类 文本识别 |
PaddleOCRPaddleClas |
| 通用表格识别 | 版面区域检测 表格结构识别 文本检测 文本识别 |
PaddleOCRPaddleDetection |
| 文档场景信息抽取v3 | 表格结构识别 版面区域检测 文本检测 文本识别 印章文本检测 文本图像矫正 文档图像方向分类 |
PaddleOCRPaddleDetectionPaddleClas |
| 时序预测 | 时序预测模块 | PaddleTS |
| 时序异常检测 | 时序异常检测模块 | PaddleTS |
| 时序分类 | 时序分类模块 | PaddleTS |
| 通用多标签分类 | 图像多标签分类 | PaddleClas |
| 小目标检测 | 小目标检测 | PaddleDetection |
| 图像异常检测 | 无监督异常检测 | PaddleSeg |
若您需要安装的插件为PaddleXXX,可以直接执行如下指令快速安装PaddleX的对应插件:
git clone https://github.com/PaddlePaddle/PaddleX.git
cd PaddleX
pip install -e .
paddlex --install PaddleXXX # 例如PaddleOCR❗ 注:采用这种安装方式后,是可编辑模式安装,当前项目的代码更改,都会直接作用到已经安装的 PaddleX Wheel 包。
如果上述安装方式可以安装成功,则可以跳过接下来的步骤。
若您使用Linux操作系统,请参考2. Linux安装PaddleX详细教程。其他操作系统的安装方式,敬请期待。
2.2 自定义方式安装PaddleX
2.2.1 获取 PaddleX 源码
接下来,请使用以下命令从 GitHub 获取 PaddleX 最新源码:
git clone https://github.com/PaddlePaddle/PaddleX.git如果访问 GitHub 网速较慢,可以从 Gitee 下载,命令如下:
git clone https://gitee.com/paddlepaddle/PaddleX.git2.2.2 安装PaddleX
获取 PaddleX 最新源码之后,您可以选择Wheel包安装模式或插件安装模式。
若您选择Wheel包安装模式,请执行以下命令:
cd PaddleX
# 安装 PaddleX whl
# -e:以可编辑模式安装,当前项目的代码更改,都会直接作用到已经安装的 PaddleX Wheel
pip install -e ".[base]"若您选择插件安装模式,并且您需要的插件名称为 PaddleXXX(可以有多个),请执行以下命令:
cd PaddleX
# 安装 PaddleX whl
# -e:以可编辑模式安装,当前项目的代码更改,都会直接作用到已经安装的 PaddleX Wheel
pip install -e ".[base]"
# 安装 PaddleX 插件
paddlex --install PaddleXXX例如,您需要安装PaddleOCR、PaddleClas插件,则需要执行如下命令安装插件:
# 安装 PaddleOCR、PaddleClas 插件
paddlex --install PaddleOCR PaddleClas若您需要安装全部插件,则无需填写具体插件名称,只需执行如下命令:
# 安装 PaddleX 全部插件
paddlex --install插件的默认克隆源为 github.com,同时也支持 gitee.com 克隆源,您可以通过--platform 指定克隆源。
例如,您需要使用 gitee.com 克隆源安装全部PaddleX插件,只需执行如下命令:
# 安装 PaddleX 插件
paddlex --install --platform gitee.com安装完成后,将会有如下提示:
All packages are installed.更多硬件环境的PaddleX安装请参考PaddleX多硬件使用指南
2.3 选择性安装依赖
PaddleX 的功能丰富,而不同的功能需要的依赖也不尽相同。将 PaddleX 中不需要安装插件即可使用的功能归类为“基础功能”。PaddleX 官方 Docker 镜像预置了基础功能所需的全部依赖;使用上文介绍的 pip install "...[base]" 的安装方式也将安装基础功能需要的所有依赖。如果您只专注于 PaddleX 的某一项功能,且希望保持安装的依赖的体积尽可能小,可以通过指定“依赖组”的方式,选择性地安装依赖:
# 以仅安装 OCR 类基础功能为例
# 安装预编译的 wheel 包
pip install "paddlex[ocr]"
# 从源码安装
pip install -e ".[ocr]"
# 也可以同时指定多个依赖组
pip install -e ".[ocr,cv]"PaddleX 目前提供如下依赖组:
| 依赖组名称 | 对应的功能 |
|---|---|
base |
PaddleX 的所有基础功能。 |
cv |
CV 产线的基础功能。 |
multimodal |
多模态产线的基础功能。 |
ie |
信息抽取产线的基础功能。 |
ocr |
OCR 类产线的基础功能。 |
speech |
语音产线的基础功能。 |
ts |
时序产线的基础功能。 |
video |
视频产线的基础功能。 |
trans |
翻译产线的基础功能。 |
genai-client |
生成式 AI 客户端功能。安装此依赖组等效于安装 PaddleX 生成式 AI 客户端插件;也可以通过 PaddleX CLI 安装生成式 AI 客户端插件。 |
genai-sglang-server |
SGLang 服务器功能。安装此依赖组等效于安装 PaddleX SGLang 服务器插件;也可以通过 PaddleX CLI 安装SGLang 服务器插件。 |
genai-vllm-server |
vLLM 服务器功能。安装此依赖组等效于安装 PaddleX vLLM 服务器插件;也可以通过 PaddleX CLI 安装 vLLM 服务器插件。 |
serving |
服务化部署功能。安装此依赖组等效于安装 PaddleX 服务化部署插件;也可以通过 PaddleX CLI 安装服务化部署插件。 |
paddle2onnx |
Paddle2ONNX 功能。安装此依赖组等效于安装 PaddleX Paddle2ONNX 插件;也可以通过 PaddleX CLI 安装 Paddle2ONNX 插件。 |
每一条产线属于且仅属于一个依赖组;在各产线的使用文档中可以了解产线属于哪一依赖组。对于单功能模块,安装任意包含该模块的产线对应的依赖组后即可使用相关的基础功能。
2.4 PaddleX 对飞桨框架的依赖
PaddleX 的绝大部分功能依赖飞桨框架,因此,在大多数情况下,您需要在使用 PaddleX 前参考 飞桨PaddlePaddle本地安装教程 安装飞桨框架。不过,对于以下几种情形,不必安装飞桨框架也可以使用相应的功能:
- 使用 PaddleX
genai-vllm-server或genai-sglang-server插件提供的能力部署模型推理服务。 - 使用 PaddleX
genai-client插件调用生成式 AI 推理服务。
三、报错
3.1、git版本报错
error: subprocess-exited-with-error
× Getting requirements to build editable did not run successfully.
│ exit code: 1...
...
LookupError: setuptools-scm was unable to detect version for /mnt/.../PaddleX-release-3.5
下载的 PaddleX 是 GitHub 压缩包,没有 .git 目录,导致 setuptools_scm 无法自动读取版本号,安装失败。
方案 1:手动指定版本号
直接在安装命令前加一个环境变量,告诉它版本号:
SETUPTOOLS_SCM_PRETEND_VERSION=3.5.0 pip install -e .
这是最快、最稳的解决办法,不需要改文件。
方案 2:降级 setuptools
新版本 setuptools_scm 校验太严格,降级即可:
pip install setuptools==69.0.3 wheel==0.42.0
pip install -e .
方案 3:用 git clone 下载源码
你现在的目录没有 .git,所以报错,重新克隆:
# 先退出当前目录
cd ..
# 克隆完整带git的源码
git clone https://github.com/PaddlePaddle/PaddleX.git -b release/3.5
# 进入目录安装
cd PaddleX
pip install -e .
3.2、目录缺失
FileNotFoundError: [Errno 2] No such file or directory: '/xxx/lib/python3.12/site-packages/paddlex/repo_manager/repos'
问题:
## 问题分析
这个错误是因为 repo_parent_dir 目录不存在导致的。
错误堆栈分析:
1. 在 repo.py:430 RepositoryGroupGetter.get() 方法中,当 force=True 时调用了 self.remove()
2. remove() 方法遍历所有 repos 并调用每个 repo 的 remove() 方法
3. 在 repo.py:190 的 Repository.remove() 方法中:
```
def remove(self):
"""remove"""
with switch_working_dir(self.
repo_parent_dir):
remove_repo_using_rm
(self.name)
```
4. switch_working_dir 函数在 utils.py:144 尝试 os.chdir(new_wd) ,但 new_wd (即 repo_parent_dir )不存在,所以抛出 FileNotFoundError
根本原因:
repo_parent_dir 指向的是 /conda环境/lib/python3.12/site-packages/paddlex/repo_manager/repos ,但这个目录不存在。
可能的情况:
1. 这是第一次安装,repos 目录还没有被创建(通常由 download() 方法创建)
2. 之前的安装/下载过程中断,导致目录没有正确创建
3. 目录被手动删除或清理了
## 解决方案
你需要手动创建这个目录,或者修改代码使其在目录不存在时自动创建。
download() 方法会在 repo.py:182 使用 os.makedirs(self.repo_parent_dir, exist_ok=True) 创建目录,但 remove() 方法没有检查目录是否存在。
## 快速修复方法
### 方法 :手动创建目录(最快)
在终端执行:
mkdir -p conda环境路径/lib/python3.12/
site-packages/paddlex/repo_manager/
repos
3.3、CUDA环境问题
错误信息: ValueError: Not found CUDA runtime, please use export CUDA_HOME=XXX to specific it. 表明:
1. 你的系统上没有安装 CUDA
2. 物理机CUDA 已安装但conda环境找不到变量 CUDA_HOME3. conda环境中没cuda-toolkit
解决:
conda安装 cudatoolkit 和 cudnn
conda install -c nvidia cuda-toolkit=12.6 cudnn 设置让 conda 环境内的 CUDA 优先于系统
安装 cudatoolkit 后,nvcc、cudnn.h、libcudart.so 等都已存在于 $CONDA_PREFIX 中。接下来需要确保编译脚本找到的是它们,而非系统 /usr/local/cuda。
1. 清理之前手动设置的环境变量
打开终端,先删除可能存在的旧设置(仅当前会话):
unset CPLUS_INCLUDE_PATH
unset C_INCLUDE_PATH
unset LD_LIBRARY_PATH如果你把它们写入了激活脚本,也请编辑删除:
rm -f $CONDA_PREFIX/etc/conda/activate.d/env_vars.sh # 如果有的话2. 让 conda 环境自动设置正确的路径
conda 在激活环境时会自动将 $CONDA_PREFIX/bin 加入 PATH 最前面,这样 nvcc 就会优先使用 conda 内的版本。
但头文件和库文件的搜索路径需要额外处理,好在 conda 的 cudatoolkit 包通常会自动设置以下环境变量(通过 etc/conda/activate.d/ 脚本),你可以检查是否存在:
ls $CONDA_PREFIX/etc/conda/activate.d/如果有类似 cudatoolkit.sh 的文件,那它已经帮你设好了 CPATH、LIBRARY_PATH、LD_LIBRARY_PATH 等。如果没有(有时旧版包不包含),你可以手动创建激活脚本:
# 创建激活脚本目录
mkdir -p $CONDA_PREFIX/etc/conda/activate.d
# 写入激活脚本(关键:将 pip 安装的 cuDNN 库路径放在 LD_LIBRARY_PATH 最前面)
cat << 'EOF' > $CONDA_PREFIX/etc/conda/activate.d/cuda_env.sh
#!/bin/sh
# 编译时头文件路径(来自 conda 安装的 cudnn 开发包)
export CFLAGS="-I${CONDA_PREFIX}/include $CFLAGS"
export CPPFLAGS="-I${CONDA_PREFIX}/include $CPPFLAGS"
export C_INCLUDE_PATH="${CONDA_PREFIX}/include:${C_INCLUDE_PATH}"
export CPLUS_INCLUDE_PATH="${CONDA_PREFIX}/include:${CPLUS_INCLUDE_PATH}"
# 链接时库路径(用于编译)
export LIBRARY_PATH="${CONDA_PREFIX}/lib:${CONDA_PREFIX}/lib/stubs:${LIBRARY_PATH}"
# 运行时库路径:优先使用 pip 安装的 cuDNN 9.5.1(与 Paddle 匹配),再使用 conda 的 lib
export LD_LIBRARY_PATH="${CONDA_PREFIX}/lib/python3.12/site-packages/nvidia/cudnn/lib:${CONDA_PREFIX}/lib:${CONDA_PREFIX}/lib/stubs:${LD_LIBRARY_PATH}"
export CUDA_HOME="${CONDA_PREFIX}"
EOF同时创建停用脚本(清理这些变量,以免影响其他环境):
mkdir -p $CONDA_PREFIX/etc/conda/deactivate.d
cat << 'EOF' > $CONDA_PREFIX/etc/conda/deactivate.d/cuda_env.sh
#!/bin/sh
unset CFLAGS
unset CPPFLAGS
unset C_INCLUDE_PATH
unset CPLUS_INCLUDE_PATH
unset LIBRARY_PATH
unset LD_LIBRARY_PATH
unset CUDA_HOME
EOF注意:
LIBRARY_PATH和LD_LIBRARY_PATH中的lib/stubs是为了解决某些库的 stub 链接问题,没有可去掉。
3. 重新激活环境使配置生效
conda deactivate
conda activate paddle_gpu # 换成你的环境名4. 验证:确认所有 CUDA 工具都来自 conda
which nvcc # 应显示 $CONDA_PREFIX/bin/nvcc
nvcc --version # 应显示对应的 CUDA 版本
echo $CUDA_HOME # 应等于 $CONDA_PREFIX
find $CONDA_PREFIX/include -name cudnn.h # 应有输出
find $CONDA_PREFIX/lib -name "libcudart*" # 应有输出如果 which nvcc 仍是 /usr/local/cuda/bin/nvcc,说明 PATH 中系统路径优先级更高,可以手动调整:
export PATH=$CONDA_PREFIX/bin:$PATH(上面的激活脚本并没有修改 PATH,因为 conda 默认管理 PATH,但若你的系统配置干扰,可临时这样处理)
重新运行编译(以 PaddleDetection 自定义算子为例)
现在环境已经自包含,直接执行原来的编译命令即可:
# 确保在正确的 conda 环境内
conda activate paddle_gpu
# 进入你要编译的项目目录,或者运行 paddlex 安装命令
paddlex ... # 你的原始命令编译过程中观察是否还出现 cudnn.h: 没有那个文件或目录 之类的错误。若一切正常,所有 .cu 文件会顺利通过。
库版本不匹配
ModuleNotFoundError: No module named 'pkg_resources'
因为 setuptools 版本过高(≥82)移除了 pkg_resources 模块。
执行以下命令即可修复:
pip install 'setuptools<82'之后重新运行训练命令。如果还有其他缺失(如 visualdl),也一并补上:
pip install visualdl
opencv-python版本要求<=4.6.0
paddledet 0.0.0 requires opencv-python<=4.6.0, which is not installed. paddle3d 0.0.0 requires opencv-python<=4.6.0.66, which is not installed. paddle3d 0.0.0 requires opencv-python-headless<=4.6.0.66, which is not installed.
-
第一步:彻底清理 OpenCV
执行以下命令,卸载所有可能与 OpenCV 冲突的包,为干净的安装扫清障碍。pip uninstall opencv-python opencv-contrib-python opencv-python-headless -y -
第二步:安装正确的 OpenCV 版本
清理后,我推荐你先尝试安装对 PaddleX 整体兼容性较好的opencv-python 4.5.5.64。pip install opencv-python==4.5.5.64如果这个版本仍然报
cv2.dnn.DictValue错误,说明依赖间的冲突仍然存在。这时可以改用paddle3d所需的4.6.0.66版本。但在重新安装前,务必再次执行第1步中的清理命令。pip install opencv-python==4.6.0.66
-
第三步:重启内核并验证
安装完成后,请完全关闭并重启你的 Python 终端或 Jupyter Kernel。这是确保新配置生效的关键一步。
重启后,你可以在 Python 环境中运行以下代码来验证:import cv2 print(cv2.__version__) # 检查有问题的属性是否存在 from cv2.dnn import DictValue print("OpenCV 导入成功,DictValue 属性正常")如果看到打印出的 OpenCV 版本和 “导入成功” 的信息,就说明修复成功了,可以重新开始训练。
TypeError: only 0-dimensional arrays can be converted to Python scalars
这个错误是 PaddleOCR 代码中的一个 bug,与 NumPy 版本无关(即使在旧版 NumPy 中也会出现)。np.random.choice(axis, size=1) 返回的是一个形状为 (1,) 的一维数组,而 int() 无法直接转换数组,需要取出第一个元素。
步骤 1:打开文件
vim PaddleX-release-3.5/paddlex/repo_manager/repos/PaddleOCR/ppocr/data/imaug/random_crop_data.py
或使用你喜欢的编辑器。
步骤 2:找到第 73 行附近
该行内容应该是:
xx = int(np.random.choice(axis, size=1))
步骤 3:修改为以下两种方式之一(推荐第一种)
方式一(更简洁):
xx = np.random.choice(axis) # 直接返回标量,不需要 int()方式二(保留 int 转换):
xx = int(np.random.choice(axis, size=1)[0])常见问题排查
-
找不到
cudnn.h-
确认
cudnn已安装:conda list cudnn -
检查
$CONDA_PREFIX/include下有cudnn.h
-
-
链接错误 / 找不到
-lcudart-
确认
libcudart.so在$CONDA_PREFIX/lib中 -
检查
LIBRARY_PATH和LD_LIBRARY_PATH是否包含该路径
-
-
编译时仍调用系统 nvcc
-
运行
which nvcc确认 -
如果不对,临时
export PATH=$CONDA_PREFIX/bin:$PATH
-
-
运行时找不到动态库
-
添加
$CONDA_PREFIX/lib到LD_LIBRARY_PATH(激活脚本已做)
-

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 26
26 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)