OpAgent:登顶WebArena的多模态Web Agent
本文介绍了蚂蚁集团全模态代码算法团队自研的多模态Web智能体OpAgent。为应对真实Web环境的非结构化复杂性、时序不稳定性与交互隐式逻辑等挑战,我们提出了一套结合了多任务微调、在线强化学习与模块化协作的综合解决方案。OpAgent通过层次化多任务微调(MT-SFT)构建具备规划、行动和定位能力的视觉语言模型(VLM)基座;继而,在自建的在线交互环境中,利用创新的混合奖励机制进行在线强化学习(Online RL),有效缓解了离线训练带来的分布偏移问题;最后,通过一个包含规划器、定位器、反思器和总结器的模块化智能体架构,实现对复杂长时程任务的鲁棒执行与自我修正。在权威Web智能体评测基准WebArena上,OpAgent以71.6%的成功率于2026年1月取得了榜单第一的SOTA成绩。
- GitHub: https://github.com/codefuse-ai/OpAgent
- Hugging Face: https://huggingface.co/codefuse-ai/OpAgent
- ModelScope: https://modelscope.cn/models/codefuse-ai/OpAgent-32B
- Technical Report: https://github.com/codefuse-ai/OpAgent/blob/main/technical_report/OpAgent.pdf
一、背景与挑战
自主Web智能体旨在模拟人类在图形用户界面(GUI)上执行任务,其在自动化测试、数据采集、智能助理等领域具有广阔应用前景。然而,相较于PC或移动端环境,Web环境呈现出独特的挑战:
- 非结构化复杂性:网页的DOM树结构庞大且充满噪声,传统基于HTML或DOM解析的方法难以有效提取关键信息,容易被冗余内容干扰。
- 时序不稳定性:网页内容是动态的,异步加载、实时更新和临时性元素(如弹窗)使得环境状态频繁变化。依赖静态离线数据集训练的模型在部署于真实动态环境时,会面临严重的分布偏移(Distributional Shift)问题。
- 交互的隐式逻辑:许多Web交互(如悬停触发菜单)依赖实时的视觉反馈来确认操作的成功与否,这种闭环交互逻辑是离线学习范式无法有效建模的。
为应对上述挑战,我们设计并实现了OpAgent框架,其核心在于从依赖静态数据向与真实环境动态交互的范式转变。
二、OpAgent技术框架
OpAgent的整体设计遵循一个分阶段的优化路径:首先通过多任务监督微调(MT-SFT)为模型注入基础的Web交互能力,然后通过在线强化学习(Online RL)在真实环境中对策略进行迭代优化,最终在推理阶段利用模块化智能体架构(Agentic Architecture)执行复杂任务。
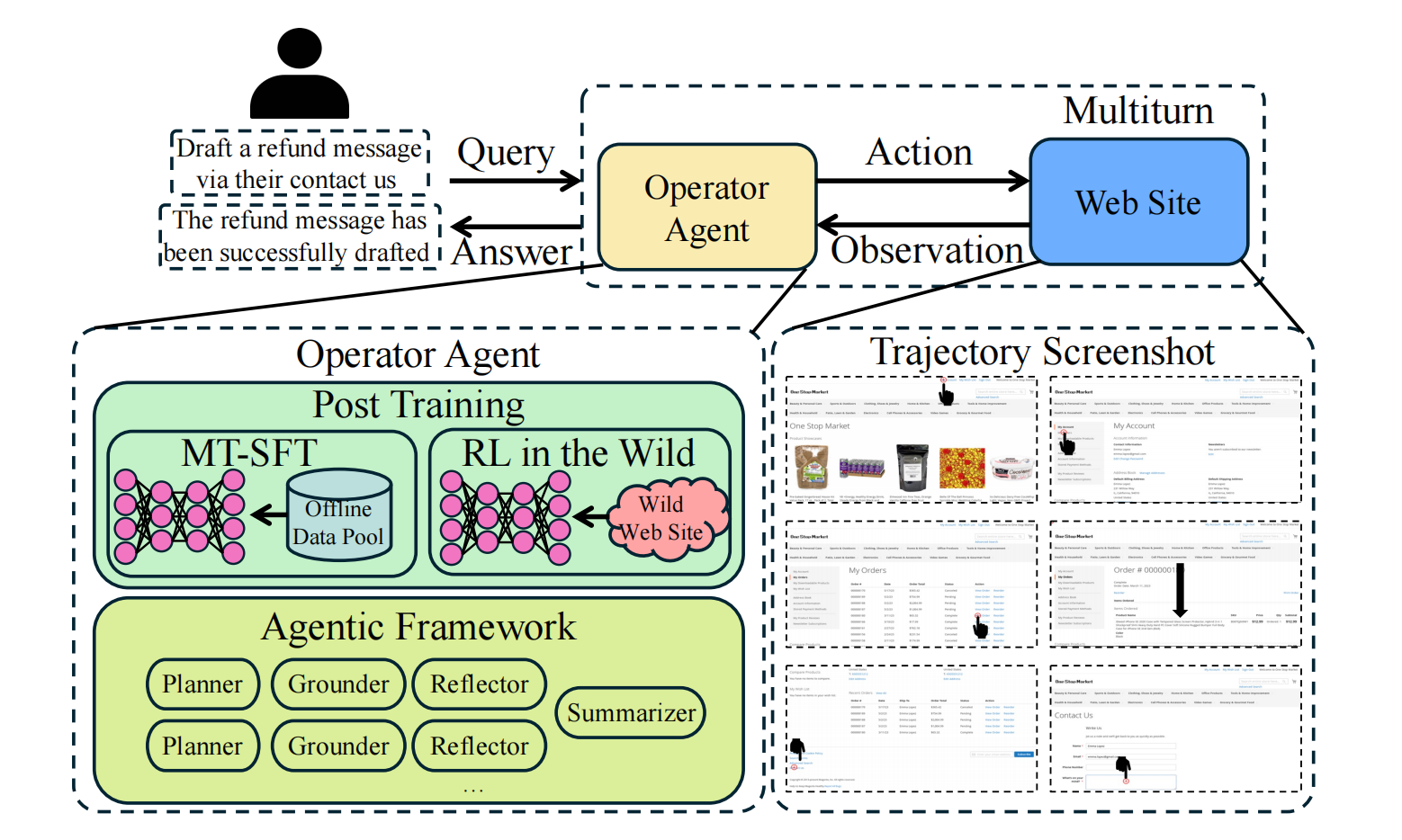
2.1 层次化多任务微调 (Hierarchical Multi-Task Fine-tuning)
为构建一个强大的视觉语言模型(VLM)基座,我们首先摒弃了对脆弱的HTML文本解析的依赖,转而让模型直接从视觉截图(Screenshot)中感知和理解页面布局。我们将Web智能体的基础能力分解为三个维度:
- 规划 (Planning):预测交互行为将导致的页面状态变迁。
- 行动 (Acting):基于当前页面状态,决策下一步所需执行的操作。
- 定位 (Grounding):在视觉上精确定位执行操作的UI元素坐标。
我们整合了包括Mind2Web、Aguvis、UGround在内的多个领域数据集,分别对上述三种能力进行训练。为解决不同数据集样本量级差异巨大(例如,百万级 vs. 千级)可能导致的梯度主导问题,我们引入了基于有效样本数 (Effective Number of Samples) 的加权策略,动态调整各任务在训练中的损失权重,确保模型在所有基础能力上得到均衡发展。
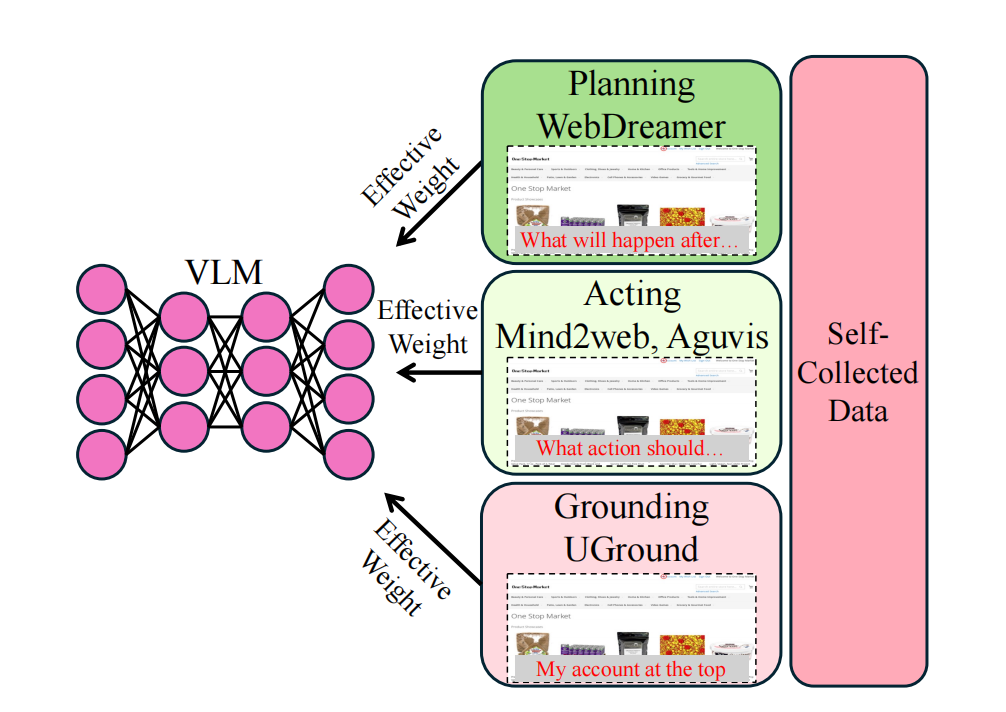
2.2 真实环境在线强化学习 (Online Agentic RL in the Wild)
在线学习是解决分布偏移问题的关键。为此,我们构建了一套支持在真实Web环境中进行大规模在线强化学习的系统。
1. 四层RL基础设施:该系统分为决策层、执行层、基础设施层和环境层。VLM代理在决策层生成动作,通过Playwright引擎在执行层被解析并分发至分布式浏览器集群,与环境层中的真实网站(包括自部署的WebArena环境)进行交互,最终将包含截图和DOM的观测数据反馈回决策层,形成一个完整的闭环交互与数据采集流程。
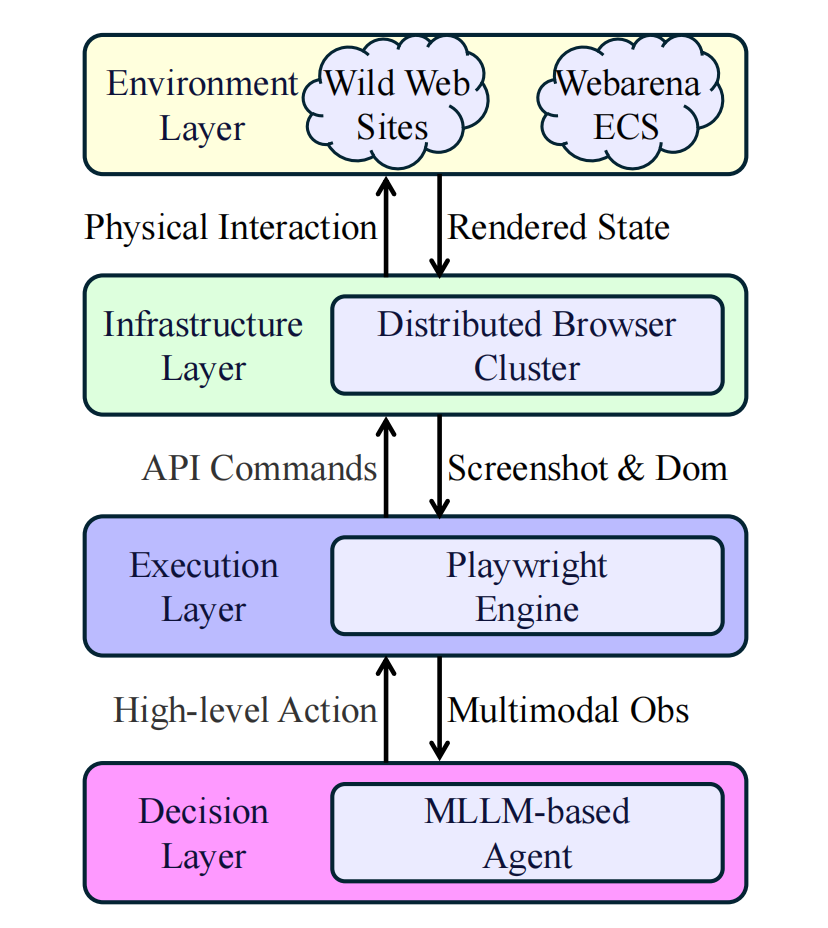
2. 混合奖励机制 (Hybrid Reward Mechanism):在没有真值(Ground-truth)轨迹的真实环境中,如何为智能体的探索行为提供有效监督信号至关重要。我们设计了一种混合奖励机制:
- 基于规则的决策树 (RDT) 进行过程监督:为智能体的每一步提供即时反馈。该机制通过一系列规则判断动作的有效性,如是否产生页面视觉变化、是否点击在可交互元素上等,对无效或冗余的动作给予惩罚。
- 基于VLM的WebJudge进行结果评估:在一条轨迹(trajectory)结束后,引入一个强大的VLM评估器WebJudge,从任务完成度、动作有效性和路径效率三个维度对整个轨迹进行综合评分,作为最终的稀疏奖励信号。
这种结合了稠密过程奖励和稀疏结果奖励的机制,为模型在真实环境中的策略优化提供了稳定且全面的监督。
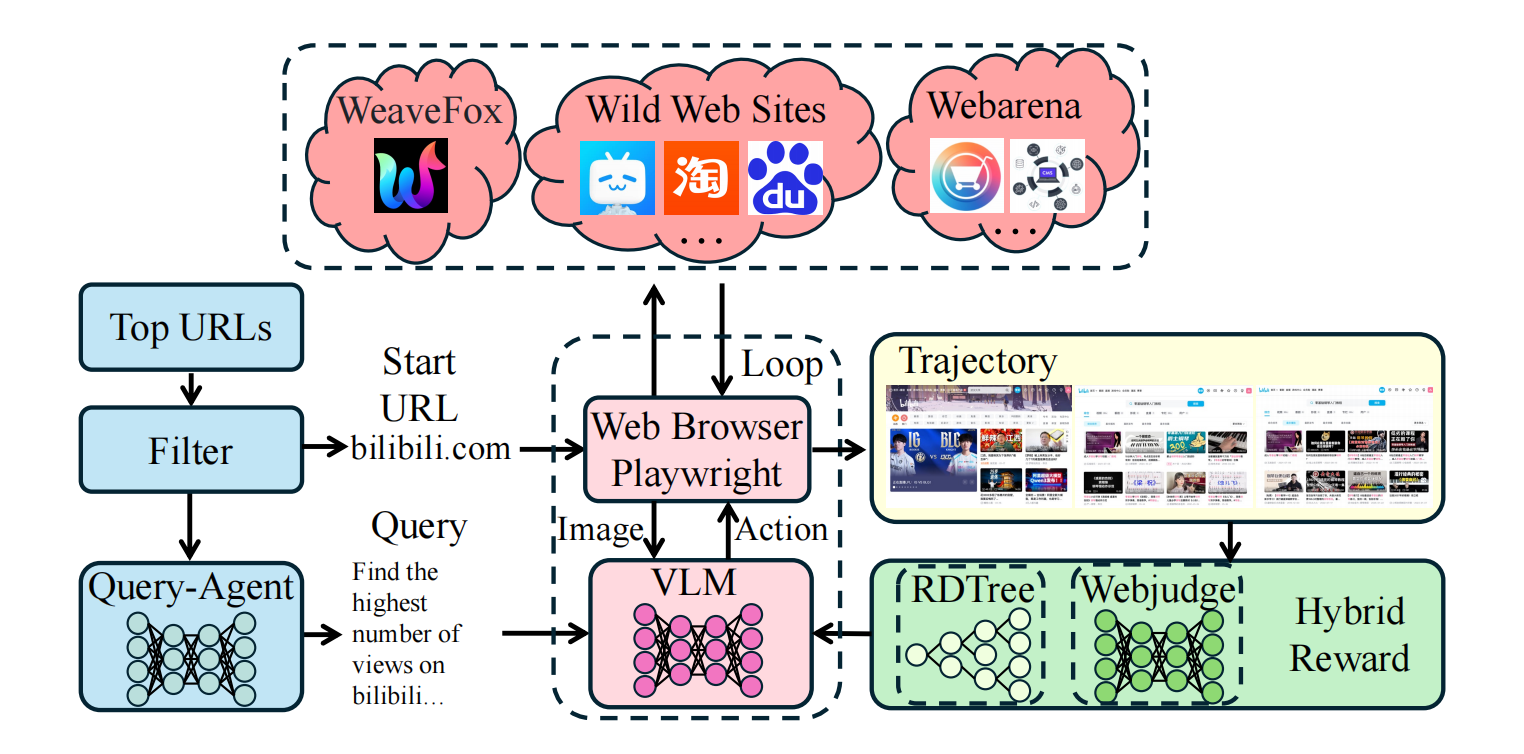
2.3 Operator Agentic 模块化智能体架构
对于长时程、多步骤的复杂任务,单一模型的决策能力有限。我们因此设计了一个包含四个专业角色的模块化协作架构,以提升任务执行的鲁棒性和成功率。
|
模块 |
核心职责 |
主要输出 |
|
Planner (规划器) |
任务分解与策略制定 |
语义化的步骤指令 |
|
Grounder (定位器) |
将语义指令映射到UI坐标 |
标准化的工具调用(Tool Call) |
|
Reflector (反思器) |
验证动作效果,监控任务进展 |
反思信号与中间笔记 |
|
Summarizer (总结器) |
综合轨迹信息,生成最终答案 |
整合后的最终答案 |
该架构通过一个“规划-执行-反思”的迭代循环运作:Planner根据全局目标和当前状态生成高层指令,Grounder将其翻译为具体动作并执行,Reflector在动作后评估状态变化并判断是否需要重新规划。这种机制实现了有效的错误检测与自我修正。

三、实验与结果
我们在多个基准上对OpAgent框架的各组件进行了充分评估。
单模型性能:
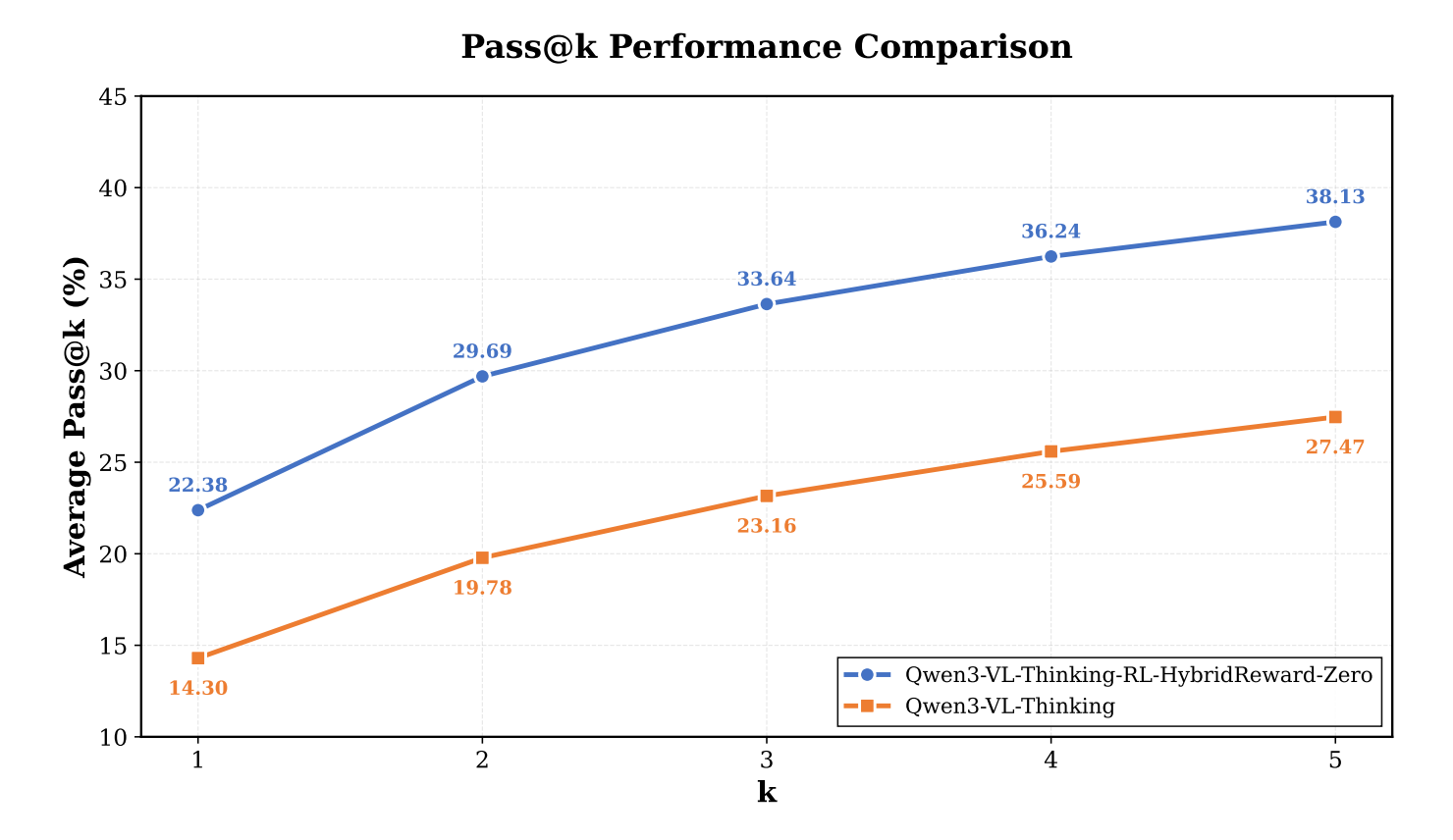
经过在线RL优化的单模型(Qwen3-VL-32B-Thinking + RL-HybridReward-Zero)在WebArena上取得了38.1%的成功率(Pass@5),显著超越了原始基线模型(27.4%)以及其他采用类似Test-Time Training (TTT) 策略的方法。
Pass@K分析:
对比RL优化前后的模型在不同Pass@K下的表现,可以看到随着尝试次数K的增加,RL优化后模型的性能优势愈发明显,Pass@5的绝对提升达到10.66%。这表明在线强化学习显著增强了模型决策的鲁棒性。
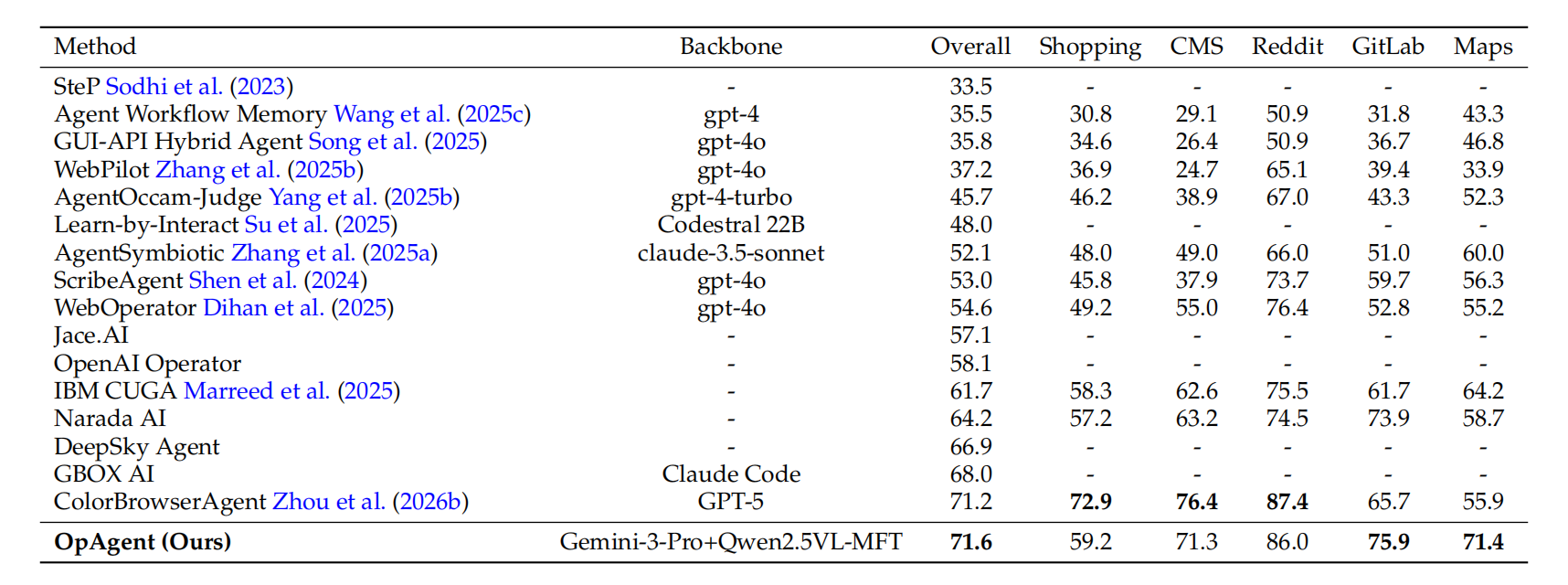
Agentic Architecture性能:
最终,集成了所有优化的OpAgent整体框架(使用Gemini-3-Pro作为部分模块后端,Qwen2.5-VL-MFT作为Grounder),在WebArena上达到了71.6%的成功率,刷新了该基准的SOTA记录,并登顶排行榜。
四、总结与展望
本文介绍了蚂蚁全模态代码算法团队在Web智能体方向的最新研究成果OpAgent。通过在多任务微调、真实环境在线强化学习以及模块化智能体架构等方面的探索,我们显著提升了Web智能体在复杂动态环境中的任务执行能力,并在WebArena基准上取得了SOTA性能。
当前工作在实现高性能的同时,仍一定程度上依赖于精细的提示工程和多智能体的复杂编排。未来的研究方向将包括提升单模型内在的探索与泛化能力,以期减少对复杂框架的依赖,实现更加通用和高效的自主智能体。
关于我们
我们是蚂蚁集团智能平台工程的全模态代码算法团队。团队成立3年以来,在 ACL、EMNLP、ICLR、NeurIPS、ICML 等顶级会议发表论文20余篇,两次获得蚂蚁技术最高奖 T-Star,1次蚂蚁集团最高奖 SuperMA,我们研发的CodeFuse 项目连续两年蝉联学术开源先锋项目。
团队常年招聘研究型实习生,有志于 NLP、大模型、多模态、图神经网络的同学欢迎联系 hyu.hugo@antgroup.com,期待与你一起,探索AI的无限可能!🌟
如果您想更快地获取到最新信息,欢迎加入我们的微信群。

企业用户如有需求,加入群聊时还可私聊“CodeFuse服务助手”联系解决方案专家~

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 18
18 0
0- 0



 已为社区贡献4条内容
已为社区贡献4条内容

所有评论(0)