langcjhang4j框架学习
在AI Servicez中新增方法,在原本的方法类型外封装一层Result类,就可以获得封装后的结果,从中能够获取到RAG引用的源文档、以及Token的消耗情况等。护轨分为两种,一种是输入护轨一种是输出护轨,可以在请求ai前和接收到ai的响应后执行一些额外操作,比如ai前鉴权,调用ai后记录日志。工具调用是ai大模型借助外部工具来完成它做不到的事情,是别人的应用程序执行工具后将返回结果告诉ai,让
AI对话
1.通过配置引入大模型:使用AI对话需要引入AI大模型依赖,这里选择aliyun的大模型
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-community-dashscope-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
引入之后再阿里云百炼平台上获取API-Key
配置好配置文件:
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <You API Key here>
2.通过构造器来自己构建对话模型对象
ChatModel qwenModel = QwenChatModel.builder()
.apiKey("You API key here")
.modelName("qwen-max")
.enableSearch(true)
.temperature(0.7)
.maxTokens(4096)
.stops(List.of("Hello"))
.build();
进行使用:
@Service
@Slf4j
public class AiCodeHelper {
@Resource
private ChatModel qwenChatModel;
public String chat(String message) {
UserMessage userMessage = UserMessage.from(message);
ChatResponse chatResponse = qwenChatModel.chat(userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
}
多模态
多模态是指能够同时处理、理解和生v哼多种不同类型数据的能力,比如文本、图像、挺拼、视频、pdf等。
系统提示词
为了让ai的回答能加贴切用户的需求,所以需要一个系统提示词SystemMeessage来给AI设置能力边界和人格。
第一种使用方式:
我们可以定义好提示词,然后再传输的时候附带上。
private static final String SYSTEM_MESSAGE = """
你是编程领域的小助手,帮助用户解答编程学习和求职面试相关的问题,并给出建议。重点关注 4 个方向:
1. 规划清晰的编程学习路线
2. 提供项目学习建议
3. 给出程序员求职全流程指南(比如简历优化、投递技巧)
4. 分享高频面试题和面试技巧
请用简洁易懂的语言回答,助力用户高效学习与求职。
""";
public String chat(String message) {
SystemMessage systemMessage = SystemMessage.from(SYSTEM_MESSAGE);
UserMessage userMessage = UserMessage.from(message);
ChatResponse chatResponse = qwenChatModel.chat(systemMessage, userMessage);
AiMessage aiMessage = chatResponse.aiMessage();
log.info("AI 输出:" + aiMessage.toString());
return aiMessage.text();
}
第二种使用方式(这种使用要引入aiservice方式):
可以将其放到resources目录下的txt文件中。
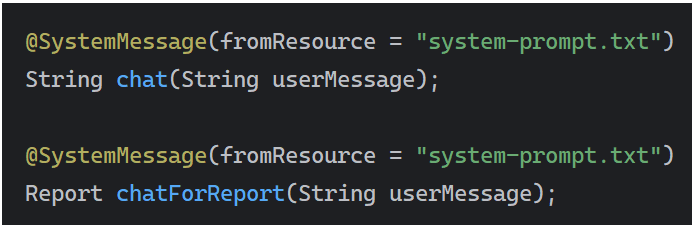
然后在服务调用的接口上配置SystemMessage的注解
AI Service
工厂创建(灵活性高):
先引入依赖:
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j</artifactId>
<version>1.1.0</version>
</dependency>
再创建一个ai服务
public interface AiCodeHelperService {
@SystemMessage("system-prompt.txt")
String chat(String userMessage);
}
编写工厂类来创建ai服务
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
return AiServices.create(AiCodeHelperService.class, qwenChatModel);
}
}
AI Service注入
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-spring-boot-starter</artifactId>
<version>1.1.0-beta7</version>
</dependency>
@AiService
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
}
会话记忆
传统方式:自己实现会话记忆
// 自己实现会话记忆
Map<String, List<Message>> conversationHistory = new HashMap<>();
public String chat(String message, String userId) {
// 获取用户历史记录
List<Message> history = conversationHistory.getOrDefault(userId, new ArrayList<>());
// 添加用户新消息
Message userMessage = new Message("user", message);
history.add(userMessage);
// 构建完整历史上下文
StringBuilder contextBuilder = new StringBuilder();
for (Message msg : history) {
contextBuilder.append(msg.getRole()).append(": ").append(msg.getContent()).append("\n");
}
// 调用 AI API
String response = callAiApi(contextBuilder.toString());
// 保存 AI 回复到历史
Message aiMessage = new Message("assistant", response);
history.add(aiMessage);
conversationHistory.put(userId, history);
return response;
}
在langchain4j中可以使用MessageWindowChaatMemory
@Configuration
public class AiCodeHelperServiceFactory {
@Resource
private ChatModel qwenChatModel;
@Bean
public AiCodeHelperService aiCodeHelperService() {
// 会话记忆
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.build();
return aiCodeHelperService;
}
}
注意:会话记忆是默认保存在内存中的,可以自定义ChatMemoryStore接口的实现类,将消息保存到mysql等其他数据源中
若有多个用户,想让用户之间的消息隔离,可以给对话方法增加memoryld参数和注解,然后传入memoryld即可。
String chat(@MemoryId int memoryId, @UserMessage String userMessage);
然后再构建ai service的是哦胡,通过chatMemoryProvider来指定每个memoryld单独创建会话记忆:
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemoryProvider(memoryId -> MessageWindowChatMemory.withMaxMessages(10))
.build();
结构化输出
结构化输出有三种实现方式:
json schema
prompt + json Mode
利用 Prompt
结构化输出是将大模型返回的文本输出转换为结构化的数据格式,像是json、对象或是复杂的对象列表
prompt:
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
// 学习报告
record Report(String name, List<String> suggestionList){}
若发现AI有时无法生成准确的json,那么可以采用json schema模式,直接在请求中约束LLM的输出格式。这是目前最可靠、精度最高的结构化输出实现。
ResponseFormat responseFormat = ResponseFormat.builder()
.type(JSON)
.jsonSchema(JsonSchema.builder()
.name("Person")
.rootElement(JsonObjectSchema.builder()
.addStringProperty("name")
.addIntegerProperty("age")
.addNumberProperty("height")
.addBooleanProperty("married")
.required("name", "age", "height", "married")
.build())
.build())
.build();
ChatRequest chatRequest = ChatRequest.builder()
.responseFormat(responseFormat)
.messages(userMessage)
.build();
检索增强生成-RAG
极简版rag
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-easy-rag</artifactId>
<version>1.1.0-beta7</version>
</dependency>
// RAG
// 1. 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
// 2. 使用内置的 EmbeddingModel 转换文本为向量,然后存储到自动注入的内存 embeddingStore 中
EmbeddingStoreIngestor.ingest(documents, embeddingStore);
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
// RAG:从内存 embeddingStore 中检索匹配的文本片段
.contentRetriever(EmbeddingStoreContentRetriever.from(embeddingStore))
.build();
标准版RAG:
添加配置
langchain4j:
community:
dashscope:
chat-model:
model-name: qwen-max
api-key: <You API Key here>
embedding-model:
model-name: text-embedding-v4
api-key: <You API Key here>
创建RAG配置类,执行RAG的初始流程并返回一个定制的内容检索器Bean:
/**
* 加载 RAG
*/
@Configuration
public class RagConfig {
@Resource
private EmbeddingModel qwenEmbeddingModel;
@Resource
private EmbeddingStore<TextSegment> embeddingStore;
@Bean
public ContentRetriever contentRetriever() {
// ------ RAG ------
// 1. 加载文档
List<Document> documents = FileSystemDocumentLoader.loadDocuments("src/main/resources/docs");
// 2. 文档切割:将每个文档按每段进行分割,最大 1000 字符,每次重叠最多 200 个字符
DocumentByParagraphSplitter paragraphSplitter = new DocumentByParagraphSplitter(1000, 200);
// 3. 自定义文档加载器
EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder()
.documentSplitter(paragraphSplitter)
// 为了提高搜索质量,为每个 TextSegment 添加文档名称
.textSegmentTransformer(textSegment -> TextSegment.from(
textSegment.metadata().getString("file_name") + "\n" + textSegment.text(),
textSegment.metadata()
))
// 使用指定的向量模型
.embeddingModel(qwenEmbeddingModel)
.embeddingStore(embeddingStore)
.build();
// 加载文档
ingestor.ingest(documents);
// 4. 自定义内容查询器
ContentRetriever contentRetriever = EmbeddingStoreContentRetriever.builder()
.embeddingStore(embeddingStore)
.embeddingModel(qwenEmbeddingModel)
.maxResults(5) // 最多 5 个检索结果
.minScore(0.75) // 过滤掉分数小于 0.75 的结果
.build();
return contentRetriever;
}
}
然后在aiService中绑定内容检索器
@Resource
private ContentRetriever contentRetriever;
@Bean
public AiCodeHelperService aiCodeHelperService() {
// 会话记忆
ChatMemory chatMemory = MessageWindowChatMemory.withMaxMessages(10);
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.build();
return aiCodeHelperService;
}
获取引用原文档
在AI Servicez中新增方法,在原本的方法类型外封装一层Result类,就可以获得封装后的结果,从中能够获取到RAG引用的源文档、以及Token的消耗情况等。
@SystemMessage(fromResource = "system-prompt.txt")
Result<String> chatWithRag(String userMessage);
工具调用-Tools
工具调用是ai大模型借助外部工具来完成它做不到的事情,是别人的应用程序执行工具后将返回结果告诉ai,让其继续工作
例如利用jsoup进行抓取
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.20.1</version>
</dependency>
@Slf4j
public class InterviewQuestionTool {
/**
* 从面试鸭网站获取关键词相关的面试题列表
*
* @param keyword 搜索关键词(如"redis"、"java多线程")
* @return 面试题列表,若失败则返回错误信息
*/
@Tool(name = "interviewQuestionSearch", value = """
Retrieves relevant interview questions from mianshiya.com based on a keyword.
Use this tool when the user asks for interview questions about specific technologies,
programming concepts, or job-related topics. The input should be a clear search term.
"""
)
public String searchInterviewQuestions(@P(value = "the keyword to search") String keyword) {
List<String> questions = new ArrayList<>();
// 构建搜索URL(编码关键词以支持中文)
String encodedKeyword = URLEncoder.encode(keyword, StandardCharsets.UTF_8);
String url = "https://www.mianshiya.com/search/all?searchText=" + encodedKeyword;
// 发送请求并解析页面
Document doc;
try {
doc = Jsoup.connect(url)
.userAgent("Mozilla/5.0")
.timeout(5000)
.get();
} catch (IOException e) {
log.error("get web error", e);
return e.getMessage();
}
// 提取面试题
Elements questionElements = doc.select(".ant-table-cell > a");
questionElements.forEach(el -> questions.add(el.text().trim()));
return String.join("\n", questions);
}
}
要注意认真编写工具和工具参数的描述,这直接决定了ai能否正确的调用工具
绑定工具:
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.build();
模型上下文协议-MCP
就是调用别人的工具
以zhipu的搜索为例
先获取其api-key
然后在mcp.so上搜索其对应的服务
引入依赖:
<!-- https://mvnrepository.com/artifact/dev.langchain4j/langchain4j-mcp -->
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-mcp</artifactId>
<version>1.1.0-beta7</version>
</dependency>
增加api-key的配置:
bigmodel:
api-key: <Your Api Key>
新建mcp.Mcpconfig的配置,根据langchain4j框架的开发方式,初始化和map服务的通讯,并创建McpToolProvider的Bean:
@Configuration
public class McpConfig {
@Value("${bigmodel.api-key}")
private String apiKey;
@Bean
public McpToolProvider mcpToolProvider() {
// 和 MCP 服务通讯
McpTransport transport = new HttpMcpTransport.Builder()
.sseUrl("https://open.bigmodel.cn/api/mcp/web_search/sse?Authorization=" + apiKey)
.logRequests(true) // 开启日志,查看更多信息
.logResponses(true)
.build();
// 创建 MCP 客户端
McpClient mcpClient = new DefaultMcpClient.Builder()
.key("yupiMcpClient")
.transport(transport)
.build();
// 从 MCP 客户端获取工具
McpToolProvider toolProvider = McpToolProvider.builder()
.mcpClients(mcpClient)
.build();
return toolProvider;
}
}
上述方式是通过sse的方式调用MCP。若是npx或uvx本地启动mcp服务,要先暗疮对应的工具,并利用下面的通讯配置建立通讯:
McpTransport transport = new StdioMcpTransport.Builder()
.command(List.of("/usr/bin/npm", "exec", "@modelcontextprotocol/server-everything@0.6.2"))
.logEvents(true) // only if you want to see the traffic in the log
.build();
在aiservice中应用mcp
@Resource
private McpToolProvider mcpToolProvider;
// 构造 AI Service
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(qwenChatModel)
.chatMemory(chatMemory)
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.toolProvider(mcpToolProvider) // MCP 工具调用
.build();
护轨(拦截器):
护轨分为两种,一种是输入护轨一种是输出护轨,可以在请求ai前和接收到ai的响应后执行一些额外操作,比如ai前鉴权,调用ai后记录日志。
创建一个护轨,实现inputGuardrail接口:
/**
* 安全检测输入护轨
*/
public class SafeInputGuardrail implements InputGuardrail {
private static final Set<String> sensitiveWords = Set.of("kill", "evil");
/**
* 检测用户输入是否安全
*/
@Override
public InputGuardrailResult validate(UserMessage userMessage) {
// 获取用户输入并转换为小写以确保大小写不敏感
String inputText = userMessage.singleText().toLowerCase();
// 使用正则表达式分割输入文本为单词
String[] words = inputText.split("\\W+");
// 遍历所有单词,检查是否存在敏感词
for (String word : words) {
if (sensitiveWords.contains(word)) {
return fatal("Sensitive word detected: " + word);
}
}
return success();
}
}
修改ai service,使用输入护轨来检测用户输入内容:
@InputGuardrails({SafeInputGuardrail.class})
public interface AiCodeHelperService {
@SystemMessage(fromResource = "system-prompt.txt")
String chat(String userMessage);
@SystemMessage(fromResource = "system-prompt.txt")
Report chatForReport(String userMessage);
// 学习报告
record Report(String name, List<String> suggestionList) {
}
}
日志和可观测性
日志
日志可以在构造模型的时候指定开启、或者编写springboot配置,支持打印AI请求和响应日志,但不是所有模型都支持。千问就不支持
OpenAiChatModel.builder()
...
.logRequests(true)
.logResponses(true)
.build();
langchain4j.open-ai.chat-model.log-requests = true
langchain4j.open-ai.chat-model.log-responses = true
logging.level.dev.langchain4j = DEBUG
可观测性
可以通过自定义Listener获取ChatModel的调用信息,比较灵活。
新建listener.ChatModelListenerConfig,输出请求、响应、错误信息:
@Configuration
@Slf4j
public class ChatModelListenerConfig {
@Bean
ChatModelListener chatModelListener() {
return new ChatModelListener() {
@Override
public void onRequest(ChatModelRequestContext requestContext) {
log.info("onRequest(): {}", requestContext.chatRequest());
}
@Override
public void onResponse(ChatModelResponseContext responseContext) {
log.info("onResponse(): {}", responseContext.chatResponse());
}
@Override
public void onError(ChatModelErrorContext errorContext) {
log.info("onError(): {}", errorContext.error().getMessage());
}
};
}
}
定义好了,但是只有listener对qwenChatModel不起作用,要手动构造自定义的QwenChatModel。
@Configuration
@ConfigurationProperties(prefix = "langchain4j.community.dashscope.chat-model")
@Data
public class QwenChatModelConfig {
private String modelName;
private String apiKey;
@Resource
private ChatModelListener chatModelListener;
@Bean
public ChatModel myQwenChatModel() {
return QwenChatModel.builder()
.apiKey(apiKey)
.modelName(modelName)
.listeners(List.of(chatModelListener))
.build();
}
}
AI服务化
SSE流式接口开发
1.一种是TokenStream,先让AI对话返回TokenStream,然后创建AI Service时指定流式对话模型
StreamingChatModel:
interface Assistant {
TokenStream chat(String message);
}
StreamingChatModel model = OpenAiStreamingChatModel.builder()
.apiKey(System.getenv("OPENAI_API_KEY"))
.modelName(GPT_4_O_MINI)
.build();
Assistant assistant = AiServices.create(Assistant.class, model);
TokenStream tokenStream = assistant.chat("Tell me a joke");
tokenStream.onPartialResponse((String partialResponse) -> System.out.println(partialResponse))
.onRetrieved((List<Content> contents) -> System.out.println(contents))
.onToolExecuted((ToolExecution toolExecution) -> System.out.println(toolExecution))
.onCompleteResponse((ChatResponse response) -> System.out.println(response))
.onError((Throwable error) -> error.printStackTrace())
.start();
2.利用Flux代替TokenStream
interface Assistant {
Flux<String> chat(String message);
}
引入响应式依赖包
<dependency>
<groupId>dev.langchain4j</groupId>
<artifactId>langchain4j-reactor</artifactId>
<version>1.1.0-beta7</version>
</dependency>
增加流式对话方法
// 流式对话
Flux<String> chatStream(@MemoryId int memoryId, @UserMessage String userMessage);
添加流式模型配置:
langchain4j:
community:
dashscope:
streaming-chat-model:
model-name: qwen-max
api-key: <Your Api Key>
注入流式对话模型:
@Resource
private StreamingChatModel qwenStreamingChatModel;
AiCodeHelperService aiCodeHelperService = AiServices.builder(AiCodeHelperService.class)
.chatModel(myQwenChatModel)
.streamingChatModel(qwenStreamingChatModel)
.chatMemory(chatMemory)
.chatMemoryProvider(memoryId ->
MessageWindowChatMemory.withMaxMessages(10)) // 每个会话独立存储
.contentRetriever(contentRetriever) // RAG 检索增强生成
.tools(new InterviewQuestionTool()) // 工具调用
.toolProvider(mcpToolProvider) // MCP 工具调用
.build();
编写controller接口:
@RestController
@RequestMapping("/ai")
public class AiController {
@Resource
private AiCodeHelperService aiCodeHelperService;
@GetMapping("/chat")
public Flux<ServerSentEvent<String>> chat(int memoryId, String message) {
return aiCodeHelperService.chatStream(memoryId, message)
.map(chunk -> ServerSentEvent.<String>builder()
.data(chunk)
.build());
}
}
增加服务器配置:
server:
port: 8081
servlet:
context-path: /api
利用crul工具测试:
curl -G 'http://localhost:8081/api/ai/chat' \
--data-urlencode 'message=我是程序员鱼皮' \
--data-urlencode 'memoryId=1'
配置跨域:
/**
* 全局跨域配置
*/
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 覆盖所有请求
registry.addMapping("/**")
// 允许发送 Cookie
.allowCredentials(true)
// 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突)
.allowedOriginPatterns("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("*");
}
}
增加服务器配置:
server:
port: 8081
servlet:
context-path: /api
利用crul工具测试:
curl -G 'http://localhost:8081/api/ai/chat' \
--data-urlencode 'message=我是程序员鱼皮' \
--data-urlencode 'memoryId=1'
配置跨域:
/**
* 全局跨域配置
*/
@Configuration
public class CorsConfig implements WebMvcConfigurer {
@Override
public void addCorsMappings(CorsRegistry registry) {
// 覆盖所有请求
registry.addMapping("/**")
// 允许发送 Cookie
.allowCredentials(true)
// 放行哪些域名(必须用 patterns,否则 * 会和 allowCredentials 冲突)
.allowedOriginPatterns("*")
.allowedMethods("GET", "POST", "PUT", "DELETE", "OPTIONS")
.allowedHeaders("*")
.exposedHeaders("*");
}
}

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 18
18 0
0- 0



 已为社区贡献2条内容
已为社区贡献2条内容

所有评论(0)