triton简介
随着基于 Transformer 架构的大语言模型(LLM)在规模和复杂度上呈指数级增长,算力资源的利用效率已成为制约创新的核心因素。在这一背景下,软件栈的地位日益凸显。OpenAI Triton 作为一个开源的、类 Python 的编程语言及其编译器应运而生。它设计的初衷是让没有 GPU 编程经验的研究人员,也能编写出效率媲美手动调优的硬件内核代码。它能够让开发者无需掌握 CUDA 即可实现接近
作者:昇腾实战派
知识地图链接:Triton Ascend知识地图
一、背景介绍
随着基于 Transformer 架构的大语言模型(LLM)在规模和复杂度上呈指数级增长,算力资源的利用效率已成为制约创新的核心因素。在这一背景下,软件栈的地位日益凸显。OpenAI Triton 作为一个开源的、类 Python 的编程语言及其编译器应运而生 。它设计的初衷是让没有 GPU 编程经验的研究人员,也能编写出效率媲美手动调优的硬件内核代码 。它能够让开发者无需掌握 CUDA 即可实现接近专家水平的性能,特别适合 AI 和高性能计算场景。
二、Triton是什么
2.1 论文介绍
Triton论文:
Triton: An Intermediate Language and Compiler for Tiled Neural Network Computations(论文链接)
从论文标题不难看出,Triton是面向分块神经网络计算的DSL(Domain-specific language,领域专用语言)和编译器。它让开发者可以只关注上层的并行结构,而不需要考虑过多的底层调度细节。
2.2 整体架构
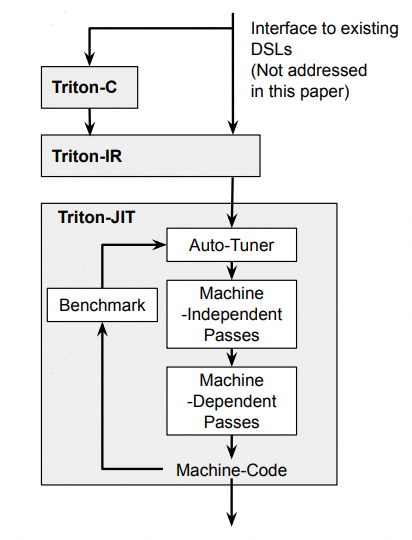
2.2.1 输入
输入来源:
- Triton-C:Triton 提供的类 Python 编程语言。
- Interface to existing DSLs:与现有领域特定语言(DSL)的接口(此部分在原论文中未展开讨论)。
- 中间表示(Triton-IR): 上述输入会被转换为 Triton 的中间代码(IR),用于后续的优化步骤。
2.2.2 核心编译模块:Triton-JIT(即时编译器)
Triton 的核心处理单元,负责将 Triton-IR 优化并转换为机器码,包含 4 个关键组件:
- Machine-Independent Passes(与机器无关的优化步骤): 针对 Triton-IR 做通用优化,比如常量折叠、死代码消除、循环展开等,适用于各类硬件。
- Machine-Dependent Passes(与机器相关的优化步骤): 针对目标硬件的架构特性做优化(比如适配硬件指令集、缓存策略等),让代码更贴合具体硬件的执行能力。
- Auto-Tuner(自动调优器): 结合Benchmark的性能数据,自动调整编译 / 优化参数,以最大化代码性能。
- Benchmark(基准测试组件): 评估生成的机器码的性能表现,将结果反馈给Auto-Tuner,形成 “调优 → \rarr →测试 → \rarr →再调优” 的循环,保证输出代码的高效性。
2.2.3 输出:Machine-Code(机器码)
经过 Triton-JIT 的优化、调优后,最终生成目标硬件可直接执行的机器码,完成从高级语言到可执行代码的转换。
三、Triton的特点
3.1 Triton核心优势
- 简洁性:用 25 行代码即可实现 FP16 矩阵乘法,性能媲美 cuBLAS。
- 可移植性:通过中间表示(IR)抽象硬件细节,支持跨平台部署。
- 开源生态:深度集成于 PyTorch 2.0 的 TorchInductor 编译器,成为自动生成高性能代码的关键组件。
3.2 技术亮点
- 自动优化能力:
- 自动管理共享内存、数据布局转换,减少手动调优需求。
- 支持
@triton.autotune自动选择最优配置(如分块大小、线程数)。
- **关键优化(Pass)**:
- 访存合并优化:提升全局内存访问效率,减少事务数量。
- 归约算子优化:支持 Warp Shuffle 等并行策略,加速求和/最值计算。
- 张量核心优化:针对矩阵乘加(MMA)操作定制分块策略,突破算力瓶颈。
3.3 硬件后端支持
- NVIDIA GPU
- 原生支持 CUDA,优化程度高,覆盖消费级到数据中心级显卡。
- 支持 Tensor Core 特性(如 FP16/BF16 精度),通过自动调优发挥硬件算力。
- AMD GPU
- 自 2023 年 9 月起正式合并 ROCm 后端代码,适配 AMD 平台。
- 通过 Triton 的跨平台能力,减少对 CUDA 兼容工具(如 Hipify)的依赖。
- 华为昇腾 NPU
- 华为昇腾 NPU 对 Triton 的支持,核心是通过triton-ascend 适配层与AscendNPU IR实现从 Python 编程到 NPU 高效执行的全链路能力,覆盖算子开发、编译优化、部署推理。
- 借助 Triton 的类python接口,可快速完成适配 NPU 的算子开发。
- 其它芯片
- 英特尔 XPU:开发者大会提及未来计划支持。
- 国产芯片:如寒武纪等,通过开源项目 FlagTree 编译器(智源研究院主导)扩展 Triton 生态,提供统一中间表示和优化通路。
3.4 Triton vs Cuda vs Ascend C
| Triton | Cuda | Ascend C |
|---|---|---|
| 开源 | 闭源 | 部分开源 |
| 支持Nvidia、Ascend | 仅支持Nvidia | 仅支持Ascend |
| Python | C/C++ | C/C++ |
| 入门难度低,开发周期短 | 入门难度高,开发周期长 | 入门难度高,开发周期长 |
| 优化由程序完成 | 优化由开发者完成 | 优化由开发者完成 |
| 兼顾高性能和灵活性 | 极致性能,低灵活性 | 极致性能,低灵活性 |
3.5 基于分块的编程范式
示例:
在矩阵乘法中,CUDA 和 Triton 的区别如下:
CUDA 编程模型(标量程序,阻塞线程)
#pragma parallel
for(int m = 0; m < M; m++) {
#pragma parallel
for(int n = 0; n < N; n++) {
float acc = 0;
for(int k = 0; k < K; k++)
acc += A[m, k] * B[k, n];
C[m, n] = acc;
}
}
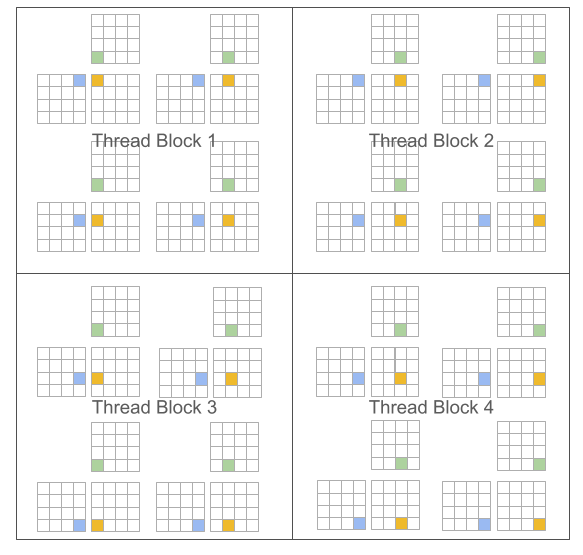
Triton 编程模型 (Blocked Program, Scalar Threads)
// Triton Programming Model
#pragma parallel
for(int m = 0; m < M; m += MB) {
#pragma parallel
for(int n = 0; n < N; n += NB) {
float acc[MB, NB] = 0;
for(int k = 0; k < K; k += KB)
acc += A[m:m+MB, k:k+KB] @ B[k:k+KB, n:n+NB];
C[m:m+MB, n:n+NB] = acc;
}
}
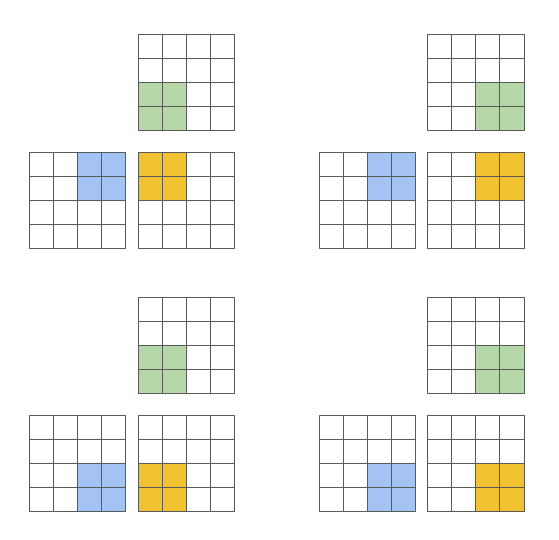
Triton的关键优势在于它产生了块结构化的迭代空间,为程序员在实现稀疏操作时提供了比现有 DSL 更多的灵活性,同时允许编译器针对数据局部性和并行性进行积极优化。
四、参考资料

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)