别再手搓RAG了!UBC提出ALMA:让AI自己写代码“设计记忆”
手动设计AI组件的时代正在过去,AI自我进化的时代正在到来。这篇论文证明了,与其让人类绞尽脑汁去猜Agent需要什么样的数据库结构,不如给AI一个代码编辑器,让它在千万次试错中自己找到答案。ALMA的关键启示:用代码作为策略的搜索空间,比调整参数强大得多。没有通用的完美记忆,只有最适合当前任务的记忆。当Agent学会了优化自己的大脑(记忆结构),通向AGI的递归自我改进(Recursive Sel

大模型(LLM)的“金鱼记忆”一直是Agent迈向长程任务的绊脚石。为了解决这个问题,人类工程师发明了各种RAG、向量库和图数据库。但这些真的是最优解吗?来自不列颠哥伦比亚大学(UBC)和Vector Institute的研究者提出了一种全新的框架——ALMA。它不依赖人类设计的记忆模板,而是让AI自己写代码来设计、测试和迭代记忆系统。结果显示,AI设计的记忆系统在多项任务上完爆人类专家的设计。
在通往通用人工智能(AGI)的路上,“记忆(Memory)” 始终是悬在LLM Agent头顶的一把达摩克利斯之剑。
目前的LLM在推理时是无状态的(Stateless),这意味着每次对话结束,它就把学到的经验忘得一干二净。为了让Agent拥有“持续学习”的能力,我们通常会外挂一个记忆模块(比如向量数据库)。
但问题来了:不同的任务需要不同的记忆结构。
- 做客服,需要记住用户的偏好(键值对);
- 玩策略游戏,需要提炼抽象的技能(规则库);
- 探索迷宫,需要构建空间地图(图结构)。
以前,这需要研究员针对每个领域“手搓”记忆架构。而今天我们要介绍的论文 《Learning to Continually Learn via Meta-learning Agentic Memory Designs》 ,提出了一个颠覆性的思路:为什么不让AI自己写代码,设计最适合当前任务的记忆系统呢?
ALMA:让AI成为记忆架构师
这篇论文提出了 ALMA(Automated meta-Learning of Memory designs for Agentic systems),即“Agent系统的自动化元学习记忆设计”。
它的核心理念非常直接:用代码作为搜索空间,通过元学习(Meta-learning)让Agent在试错中进化出最佳的记忆设计。
ALMA的工作流程就像一个经验丰富的“软件架构师”带领一个“测试员”在不断迭代产品:
- 构思与规划(Ideate & Plan): 这里的“架构师”是一个元智能体(Meta Agent),它会分析之前的记忆设计哪里不好,提出改进方案。
- 实现(Implement): Meta Agent直接编写Python代码,实现新的记忆模块(包括数据库结构、检索逻辑、更新逻辑)。
- 评估(Evaluate): 将新设计的记忆模块装载到Agent上,在实际任务中跑一遍,看效果如何。
- 反思与入库(Reflection): 无论成功失败,测试日志都会被存入档案,供Meta Agent下一次设计时参考。
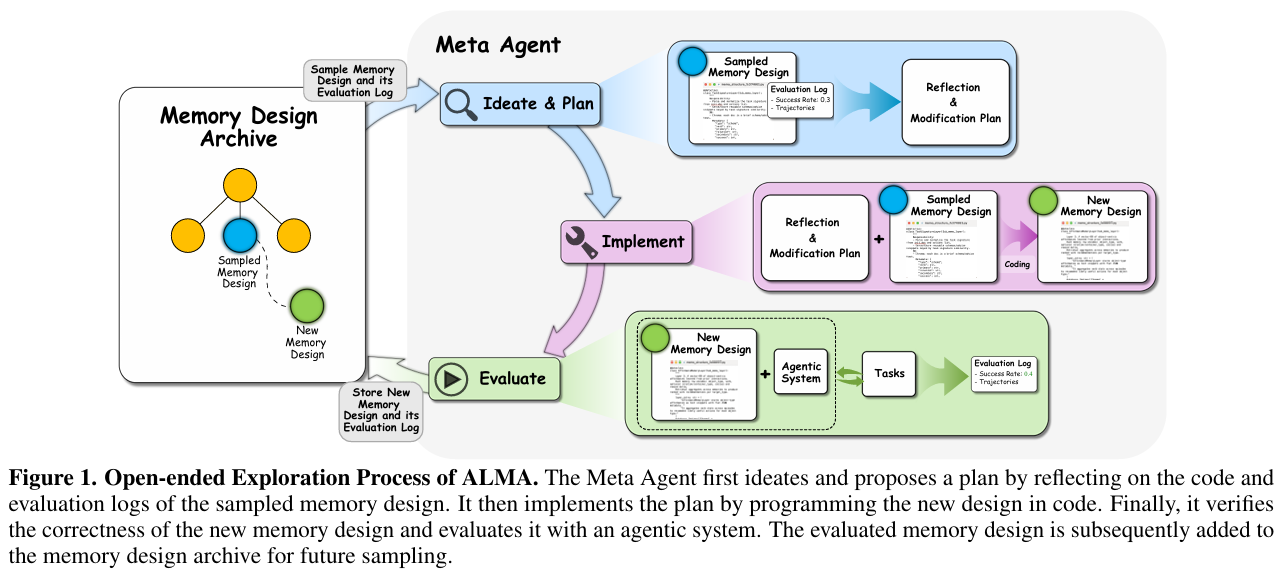
为什么选择“代码”作为记忆?
这是ALMA最精髓的地方。以往的“元学习”通常是在调参(学习率、权重),而ALMA是在写代码。
研究团队认为,代码具有图灵完备性(Turing Completeness),理论上可以表示任何形式的记忆结构——无论是简单的列表,还是复杂的层级图数据库,甚至是带有逻辑判断的规则库。
为了让AI更好地发挥,研究者定义了一个抽象的记忆基类。一个标准的记忆设计 被定义为一个三元组:
M=(U,D,R)\mathcal{M} = (U, D, R)M=(U,D,R)
其中:
- UUU 代表 更新机制(Update):如何从交互历史中提取信息存入记忆?
- DDD 代表 存储结构(Storage):信息以什么形式存在?(如向量库、图、哈希表)
- RRR 代表 检索机制(Retrieval):当新任务来临时,如何找到最相关的经验?
在代码实现中,Meta Agent需要实现两个核心接口:general_update() 和 general_retrieve()。这种高自由度让ALMA能够探索出人类未曾设想的“鬼才”设计。
进化之路:从“很菜”到“SOTA”
ALMA的进化过程是通过开放式探索(Open-Ended Exploration) 完成的。它不是单纯地“卷”分数,而是追求设计的多样性和潜能。
让我们看看在 Baba Is AI(一个规则极其复杂的策略游戏)中,ALMA是如何进化的: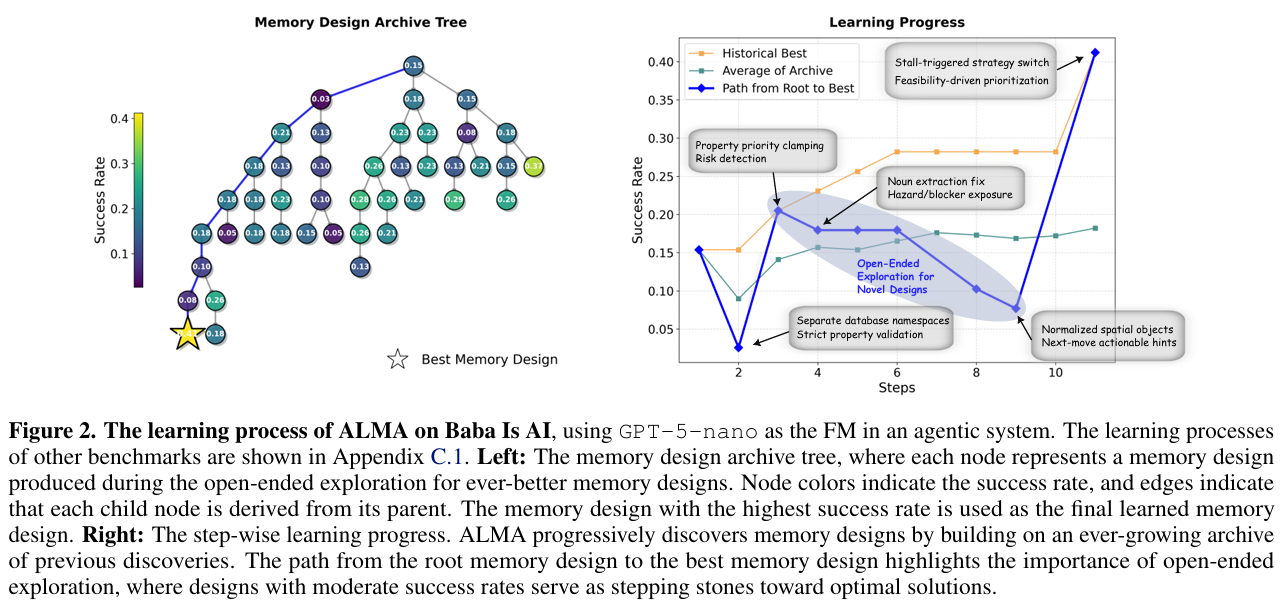
- 初期阶段: AI尝试了一些简单的设计,比如严格的属性验证,但效果一般。
- 中期突破: AI学会了“风险检测(Risk detection)”和“名词提取”,虽然性能提升不明显,但为后续打下了基础。
- 最终形态: AI设计出了包含“策略切换(Strategy switching)”和“可行性优先排序”的高级机制,性能直接起飞。
AI到底设计出了什么?(硬核展示)
最令人兴奋的部分来了。ALMA针对不同领域,设计出了完全不同的记忆架构,其复杂度和合理性令人咋舌。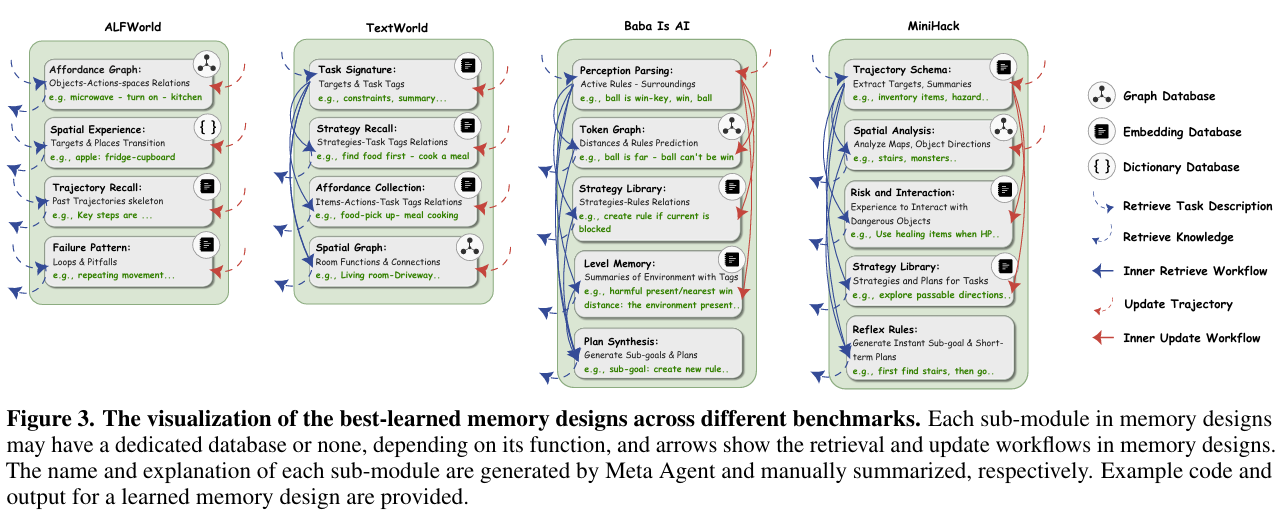
我们可以清晰地看到AI的“因地制宜”能力:
- ALFWorld(家庭机器人任务):
- AI设计了一个 “Affordance Graph(功能图)” 和 “Spatial Graph(空间图)”。
- 它意识到在这个任务里,搞清楚“什么物体在什么房间”以及“微波炉能用来干什么”是最重要的。
- Baba Is AI(逻辑游戏):
- AI构建了 “Rule Prediction(规则预测)” 和 “Level Memory(关卡记忆)”。
- 因为它发现这个游戏的规则是动态变化的,必须记住规则之间的逻辑关系才能赢。
- MiniHack(地牢探险):
- AI设计了 “Risk and Interaction(风险交互模块)”。
- 它专门开辟了一块内存来记录“怎么打怪不会死”和“哪些东西有毒”,非常符合生存游戏的需求。
这些设计并非人类预设,完全是AI为了“活下去”和“拿高分”自己进化出来的。
效果吊打人类专家?
为了验证效果,研究团队在四个高难度基准测试(ALFWorld, TextWorld, Baba Is AI, MiniHack)上进行了对比。对手包括:
- 无记忆(No Memory): 裸奔的LLM。
- Trajectory Retrieval: 经典的RAG,检索相似的历史轨迹。
- Reasoning Bank: 谷歌DeepMind提出的基于推理库的记忆。
- G-Memory: 复杂的层级图记忆。
结果如下: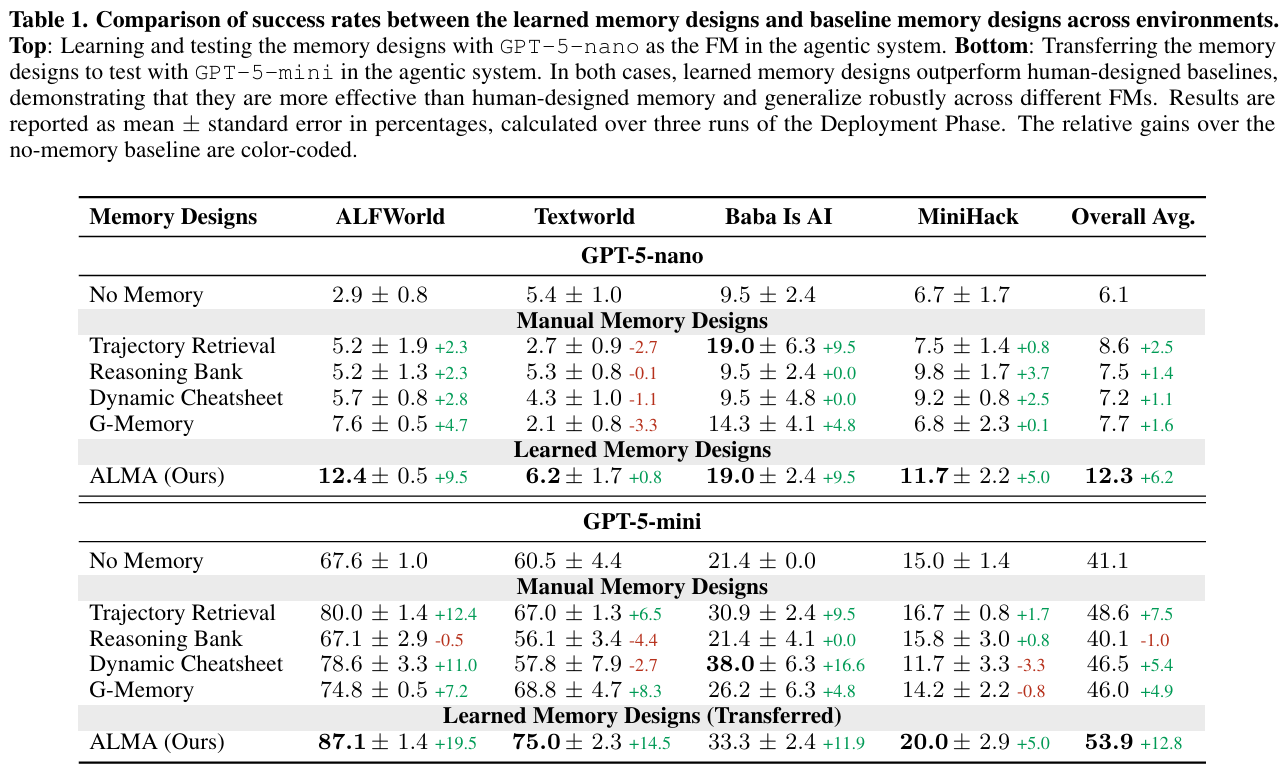
- 全面碾压: ALMA学到的记忆设计在所有测试中均击败了人类设计的SOTA基线。
模型泛化性强: 哪怕是把底层模型从 GPT-5-nano 换成 GPT-5-mini,ALMA设计的记忆系统依然表现出色,性能提升甚至更大(+12.8% vs +6.2%)。
更有趣的是,ALMA不仅更强,还更省钱。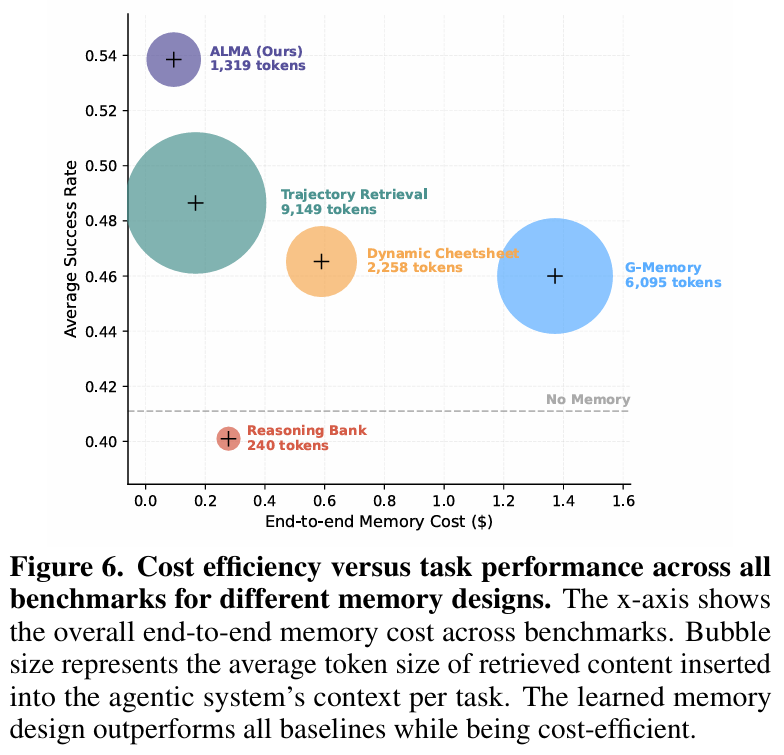
大家可以看到,紫色的ALMA气泡位于左上角——这意味着它用最少的Token(记忆更精简、检索更精准),干了最漂亮的活。相比之下,传统的Trajectory Retrieval(深绿色大圆)虽然有效,但简直就是“Token吞噬兽”。
总结与展望
ALMA的出现揭示了一个深刻的趋势:手动设计AI组件的时代正在过去,AI自我进化的时代正在到来。
这篇论文证明了,与其让人类绞尽脑汁去猜Agent需要什么样的数据库结构,不如给AI一个代码编辑器,让它在千万次试错中自己找到答案。
ALMA的关键启示:
- Code is All You Need: 用代码作为策略的搜索空间,比调整参数强大得多。
- 因地制宜: 没有通用的完美记忆,只有最适合当前任务的记忆。
- 自我改进: 当Agent学会了优化自己的大脑(记忆结构),通向AGI的递归自我改进(Recursive Self-Improvement)之路或许就不远了。
未来,也许我们不再需要手动写RAG的Prompt,只要对Agent说一句:“这个任务很难,你自己写个记忆系统吧。”

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 17
17 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)