多路转接epoll
本文介绍了三种I/O多路复用技术:poll、epoll(LT/ET模式)及其实现原理。poll通过pollfd结构监听文件描述符,解决了select的位图限制但仍有性能瓶颈;epoll采用事件驱动机制,通过红黑树和就绪队列高效管理大量连接,支持水平触发(LT)和边缘触发(ET)模式。文章详细分析了epoll的三个系统调用(create/ctl/wait),比较了LT和ET模式的特点:LT会重复通知
I/O多路转接之poll
poll函数接口
#include <poll.h>
int poll(struct pollfd *fds, nfds_t nfds, int timeout);
// pollfd结构
struct pollfd
{
int fd; /* file descriptor */
short events; /* requested events */
short revents; /* returned events */
};参数说明
• fds是⼀个poll函数监听的结构列表. 每⼀个元素中, 包含了三部分内容: ⽂件描述符, 监听的事件集合, 返回的事件集合.
• nfds表示fds数组的长度.
• timeout表示poll函数的超时时间, 单位是毫秒(ms).
events和revents的取值:
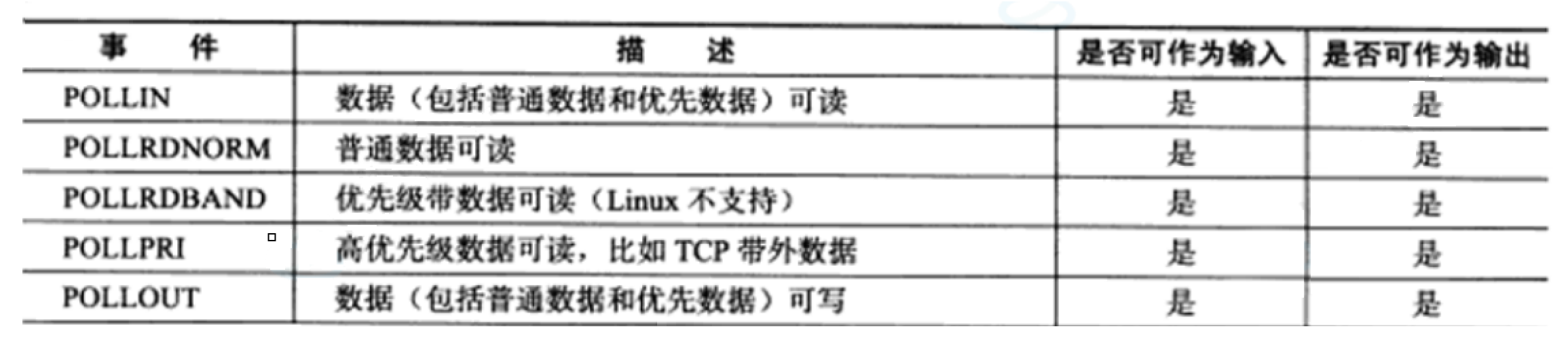

返回结果
• 返回值小于0, 表示出错;
• 返回值等于0, 表示poll函数等待超时;
• 返回值⼤于0, 表示poll由于监听的⽂件描述符就绪⽽返回.
socket就绪条件
同select
poll的优点
不同于select使用三个位图来表示三个fdset的方式,poll使用⼀个pollfd的指针实现.
• pollfd结构包含了要监视的event和发⽣的event,不再使用select“参数-值”传递的方式. 接⼝使用⽐select更方便.
• poll并没有最⼤数量限制 (但是数量过⼤后性能也是会下降).
poll的缺点
poll中监听的⽂件描述符数⽬增多时
• 和select函数⼀样,poll返回后,需要轮询pollfd来获取就绪的描述符.
• 每次调用poll都需要把⼤量的pollfd结构从用⼾态拷⻉到内核中.
• 同时连接的⼤量客⼾端在⼀时刻可能只有很少的处于就绪状态, 因此随着监视的描述符数量的增长, 其效率也会线性下降.
poll示例: 使用poll监控标准输⼊
#include <poll.h>
#include <unistd.h>
#include <stdio.h>
int main()
{
struct pollfd poll_fd;
poll_fd.fd = 0;
poll_fd.events = POLLIN;
for (;;)
{
int ret = poll(&poll_fd, 1, 1000);
if (ret < 0)
{
perror("poll");
continue;
}
if (ret == 0)
{
printf("poll timeout\n");
continue;
}
if (poll_fd.revents == POLLIN)
{
char buf[1024] = {0};
read(0, buf, sizeof(buf) - 1);
printf("stdin:%s", buf);
}
}
}I/O多路转接之epoll
epoll初识
按照man⼿册的说法: 是为处理⼤批量句柄⽽作了改进的poll.
它是在2.5.44内核中被引进的(epoll(4) is a new API introduced in Linux kernel 2.5.44)
它⼏乎具备了之前所说的⼀切优点,被公认为Linux2.6下性能最好的多路I/O就绪通知方法.
epoll的相关系统调用
epoll 有3个相关的系统调用.
epoll_create
int epoll_create(int size); 创建⼀个epoll的句柄.
• ⾃从linux2.6.8之后,size参数是被忽略的.
• 用完之后, 必须调用close()关闭.
epoll_ctl
int epoll_ctl(int epfd, int op, int fd, struct epoll_event *event); epoll的事件注册函数.
• 它不同于select()是在监听事件时告诉内核要监听什么类型的事件, ⽽是在这⾥先注册要监听的事件类型.
• 第⼀个参数是epoll_create()的返回值(epoll的句柄).
• 第⼆个参数表示动作,用三个宏来表示.
• 第三个参数是需要监听的fd.
• 第四个参数是告诉内核需要监听什么事.
第⼆个参数的取值:
•
EPOLL_CTL_ADD:注册新的fd到epfd中;•
EPOLL_CTL_MOD:修改已经注册的fd的监听事件;•
EPOLL_CTL_DEL:从epfd中删除⼀个fd;
struct epoll_event结构如下:
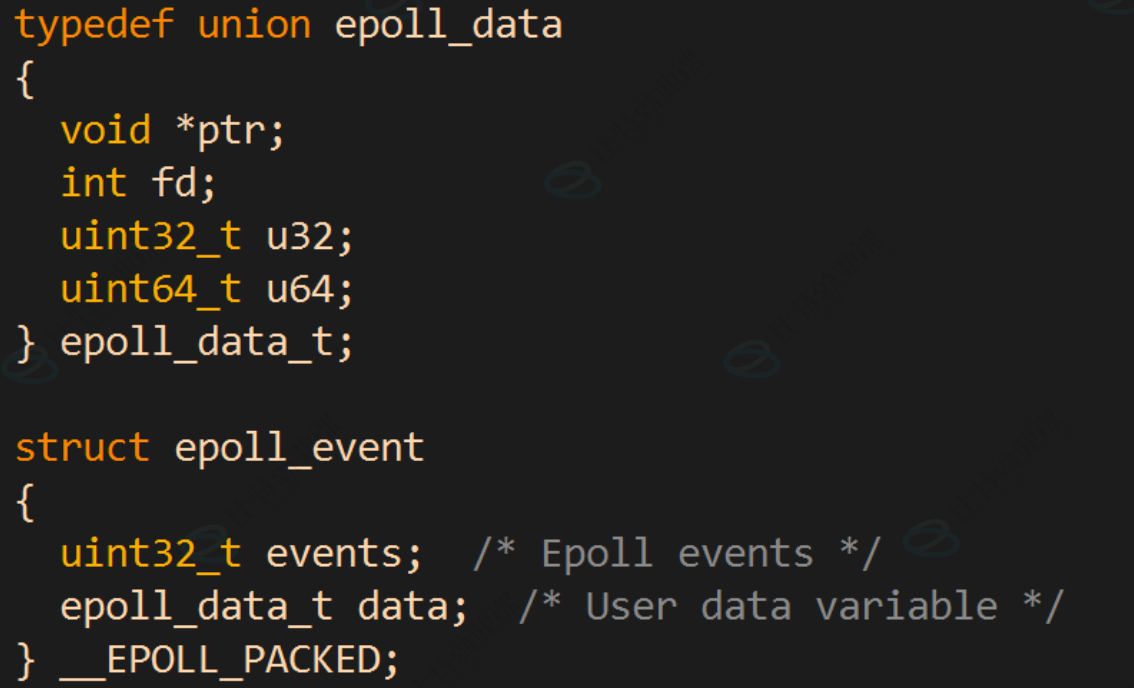
events可以是以下⼏个宏的集合:
• EPOLLIN : 表示对应的⽂件描述符可以读 (包括对端SOCKET正常关闭);
• EPOLLOUT : 表示对应的⽂件描述符可以写;
• EPOLLPRI : 表示对应的⽂件描述符有紧急的数据可读 (这⾥应该表示有带外数据到来);
• EPOLLERR : 表示对应的⽂件描述符发⽣错误;
• EPOLLHUP : 表示对应的⽂件描述符被挂断;
• EPOLLET : 将EPOLL设为边缘触发(Edge Triggered)模式, 这是相对于⽔平触发(Level Triggered)来说的.
• EPOLLONESHOT:只监听⼀次事件, 当监听完这次事件之后, 如果还需要继续监听这个socket的话, 需要再次把这个socket加⼊到EPOLL红⿊树⾥.
epoll_wait
int epoll_wait(int epfd, struct epoll_event * events, int maxevents, int timeout); 收集在epoll监控的事件中已经发送的事件.
• 参数events是分配好的epoll_event结构体数组.
• epoll将会把发⽣的事件赋值到events数组中 (events不可以是空指针,内核只负责把数据复制到这个events数组中,不会去帮助我们在用⼾态中分配内存).
• maxevents告之内核这个events有多⼤,这个 maxevents的值不能⼤于创建epoll_create()时的 size.
• 参数timeout是超时时间 (毫秒,0会⽴即返回,-1是永久阻塞).
• 如果函数调用成功,返回对应I/O上已准备好的⽂件描述符数⽬,如返回0表示已超时, 返回小于0 表示函数失败.
epoll工作原理
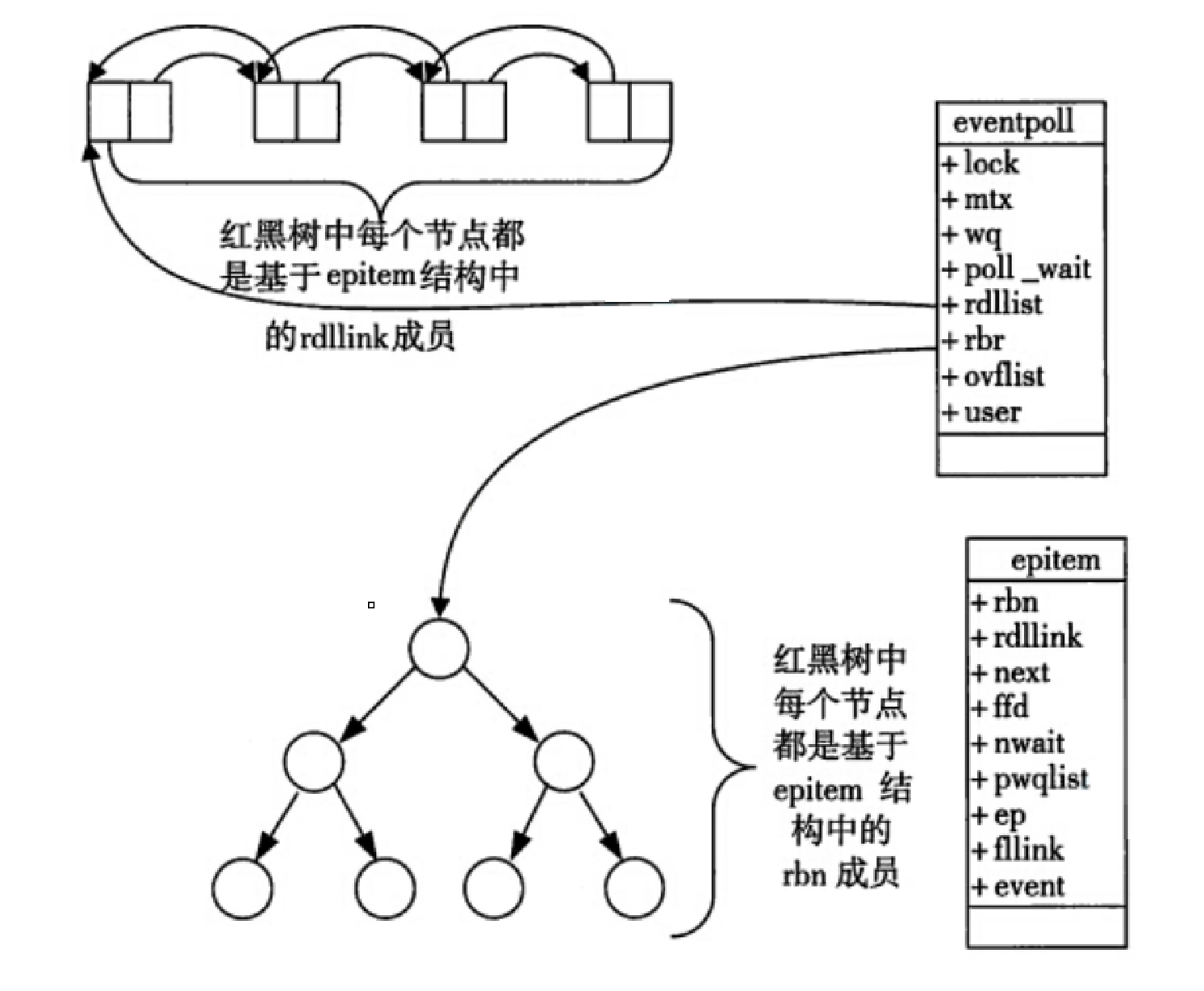
• 当某⼀进程调用epoll_create方法时,Linux内核会创建⼀个eventpoll结构体,这个结构体中有两个成员与epoll的使用方式密切相关.
struct eventpoll
{
....
/*红⿊树的根节点,这颗树中存储着所有添加到epoll中的需要监控的事件*/
struct rb_root rbr;
/*双链表中则存放着将要通过epoll_wait返回给用⼾的满⾜条件的事件*/
struct list_head rdlist;
....
};• 每⼀个epoll对象都有⼀个独⽴的eventpoll结构体,用于存放通过epoll_ctl方法向epoll对象中添加进来的事件.
• 这些事件都会挂载在红⿊树中,如此,重复添加的事件就可以通过红⿊树⽽⾼效的识别出来(红⿊树的插⼊时间效率是lgn,其中n为树的⾼度).
• ⽽所有添加到epoll中的事件都会与设备(⽹卡)驱动程序建⽴回调关系,也就是说,当响应的事件发⽣时会调用这个回调方法.
• 这个回调方法在内核中叫ep_poll_callback,它会将发⽣的事件添加到rdlist双链表中.
• 在epoll中,对于每⼀个事件,都会建⽴⼀个epitem结构体.
struct epitem
{
struct rb_node rbn; // 红⿊树节点
struct list_head rdllink; // 双向链表节点
struct epoll_filefd ffd; // 事件句柄信息
struct eventpoll *ep; // 指向其所属的eventpoll对象
struct epoll_event event; // 期待发⽣的事件类型
}• 当调用epoll_wait检查是否有事件发⽣时,只需要检查eventpoll对象中的rdlist双链表中是否有 epitem元素即可.
• 如果rdlist不为空,则把发⽣的事件复制到用⼾态,同时将事件数量返回给用⼾. 这个操作的时间复杂度是O(1).
总结⼀下, epoll的使用过程就是三部曲:
• 调用epoll_create创建⼀个epoll句柄;
• 调用epoll_ctl, 将要监控的⽂件描述符进⾏注册;
• 调用epoll_wait, 等待⽂件描述符就绪;
epoll的优点(和 select 的缺点对应)
• 接⼝使用方便: 虽然拆分成了三个函数, 但是反⽽使用起来更方便⾼效. 不需要每次循环都设置关注的⽂件描述符, 也做到了输⼊输出参数分离开
• 数据拷⻉轻量: 只在合适的时候调用 EPOLL_CTL_ADD 将⽂件描述符结构拷⻉到内核中, 这个操作并不频繁(⽽select/poll都是每次循环都要进⾏拷⻉)
• 事件回调机制: 避免使用遍历, ⽽是使用回调函数的方式, 将就绪的⽂件描述符结构加⼊到就绪队列中, epoll_wait 返回直接访问就绪队列就知道哪些⽂件描述符就绪. 这个操作时间复杂度O(1). 即使⽂件描述符数⽬很多, 效率也不会受到影响.
• 没有数量限制: ⽂件描述符数⽬⽆上限.
注意!!
⽹上有些博客说, epoll中使用了内存映射机制
• 内存映射机制: 内核直接将就绪队列通过mmap的方式映射到用⼾态. 避免了拷⻉内存这样的额外性能开销.
这种说法是不准确的. 我们定义的struct epoll_event是我们在用⼾空间中分配好的内存. 势必还是需要
将内核的数据拷⻉到这个用⼾空间的内存中的.
请同学们对⽐总结select, poll, epoll之间的优点和缺点(重要, ⾯试中常⻅).
epoll工作方式
你妈喊你吃饭的例⼦
你正在吃鸡, 眼看进⼊了决赛圈, 你妈饭做好了, 喊你吃饭的时候有两种方式:
1. 如果你妈喊你⼀次, 你没动, 那么你妈会继续喊你第⼆次, 第三次...(亲妈, ⽔平触发)
2. 如果你妈喊你⼀次, 你没动, 你妈就不管你了(后妈, 边缘触发) epoll有2种工作方式-⽔平触发(LT)和边缘触发(ET)
假如有这样⼀个例⼦:
• 我们已经把⼀个tcp socket添加到epoll描述符
• 这个时候socket的另⼀端被写⼊了2KB的数据
• 调用epoll_wait,并且它会返回. 说明它已经准备好读取操作
• 然后调用read, 只读取了1KB的数据
• 继续调用epoll_wait......
⽔平触发Level Triggered 工作模式
epoll默认状态下就是LT工作模式.
• 当epoll检测到socket上事件就绪的时候, 可以不⽴刻进⾏处理. 或者只处理⼀部分.
• 如上⾯的例⼦, 由于只读了1K数据, 缓冲区中还剩1K数据, 在第⼆次调用 epoll_wait 时, epoll_wait 仍然会⽴刻返回并通知socket读事件就绪.
• 直到缓冲区上所有的数据都被处理完, epoll_wait 才不会⽴刻返回.
• ⽀持阻塞读写和⾮阻塞读写
边缘触发Edge Triggered工作模式
如果我们在第1步将socket添加到epoll描述符的时候使用了EPOLLET标志, epoll进⼊ET工作模式.
• 当epoll检测到socket上事件就绪时, 必须⽴刻处理.
• 如上⾯的例⼦, 虽然只读了1K的数据, 缓冲区还剩1K的数据, 在第⼆次调用
epoll_wait的时候, epoll_wait 不会再返回了.• 也就是说, ET模式下, ⽂件描述符上的事件就绪后, 只有⼀次处理机会.
• ET的性能⽐LT性能更⾼( epoll_wait 返回的次数少了很多). Nginx默认采用ET模式使用 epoll.
• 只⽀持⾮阻塞的读写
select和poll其实也是工作在LT模式下. epoll既可以⽀持LT, 也可以⽀持ET.
对⽐LT和ET
LT是 epoll 的默认⾏为.
使用 ET 能够减少 epoll 触发的次数. 但是代价就是强逼着程序猿⼀次响应就绪过程中就把所有的数据都处理完.
相当于⼀个⽂件描述符就绪之后, 不会反复被提示就绪, 看起来就⽐ LT 更⾼效⼀些. 但是在 LT 情况下如果也能做到每次就绪的⽂件描述符都⽴刻处理, 不让这个就绪被重复提示的话, 其实性能也是⼀样的.
另⼀方⾯, ET 的代码复杂程度更⾼了.
理解ET模式和⾮阻塞⽂件描述符
使用 ET 模式的 epoll, 需要将⽂件描述设置为⾮阻塞. 这个不是接⼝上的要求, ⽽是 "工程实践" 上的要
求.
假设这样的场景: 服务器接收到⼀个10k的请求, 会向客⼾端返回⼀个应答数据. 如果客⼾端收不到应答,
不会发送第⼆个10k请求.
如果服务端写的代码是阻塞式的read, 并且⼀次只 read 1k 数据的话(read不能保证⼀次就把所有的数
据都读出来, 参考 man ⼿册的说明, 可能被信号打断), 剩下的9k数据就会待在缓冲区中.
此时由于 epoll 是ET模式, 并不会认为⽂件描述符读就绪. epoll_wait 就不会再次返回. 剩下的 9k
数据会⼀直在缓冲区中. 直到下⼀次客⼾端再给服务器写数据. epoll_wait 才能返回
但是问题来了.
• 服务器只读到1k个数据, 要10k读完才会给客⼾端返回响应数据.
• 客⼾端要读到服务器的响应, 才会发送下⼀个请求
• 客⼾端发送了下⼀个请求, epoll_wait 才会返回, 才能去读缓冲区中剩余的数据.
所以, 为了解决上述问题(阻塞read不⼀定能⼀下把完整的请求读完), 于是就可以使用⾮阻塞轮轮询的方
式来读缓冲区, 保证⼀定能把完整的请求都读出来.
⽽如果是LT没这个问题. 只要缓冲区中的数据没读完, 就能够让 epoll_wait 返回⽂件描述符读就绪.
epoll的使用场景
epoll的⾼性能, 是有⼀定的特定场景的. 如果场景选择的不适宜, epoll的性能可能适得其反.
• 对于多连接, 且多连接中只有⼀部分连接⽐较活跃时, ⽐较适合使用epoll.
例如, 典型的⼀个需要处理上万个客⼾端的服务器, 例如各种互联⽹APP的⼊⼝服务器, 这样的服务器就很适合epoll.
如果只是系统内部, 服务器和服务器之间进⾏通信, 只有少数的⼏个连接, 这种情况下用epoll就并不合
适. 具体要根据需求和场景特点来决定使用哪种IO模型.
epoll中的惊群问题
惊群问题有些⾯试官可能会问到. 建议同学们课后⾃⼰查阅资料了解⼀下问题的解决方案.
参考 http://blog.csdn.net/fsmiy/article/details/36873357
epoll示例: epoll服务器(LT模式)
tcp_epoll_server.hpp
///////////////////////////////////////////////////////
// 封装⼀个 Epoll 服务器, 只考虑读就绪的情况
///////////////////////////////////////////////////////
#pragma once
#include <vector>
#include <functional>
#include <sys/epoll.h>
#include "tcp_socket.hpp"
typedef std::function<void(const std::string &, std::string *resp)> Handler;
class Epoll
{
public:
Epoll()
{
epoll_fd_ = epoll_create(10);
}
~Epoll()
{
close(epoll_fd_);
}
bool Add(const TcpSocket &sock) const
{
int fd = sock.GetFd();
printf("[Epoll Add] fd = %d\n", fd);
epoll_event ev;
ev.data.fd = fd;
ev.events = EPOLLIN;
int ret = epoll_ctl(epoll_fd_, EPOLL_CTL_ADD, fd, &ev);
if (ret < 0)
{
perror("epoll_ctl ADD");
return false;
}
return true;
}
bool Del(const TcpSocket &sock) const
{
int fd = sock.GetFd();
printf("[Epoll Del] fd = %d\n", fd);
int ret = epoll_ctl(epoll_fd_, EPOLL_CTL_DEL, fd, NULL);
if (ret < 0)
{
perror("epoll_ctl DEL");
return false;
}
return true;
}
bool Wait(std::vector<TcpSocket> *output) const
{
output->clear();
epoll_event events[1000];
int nfds = epoll_wait(epoll_fd_, events, sizeof(events) / sizeof(events[0]), -1);
if (nfds < 0)
{
perror("epoll_wait");
return false;
}
// [注意!] 此处必须是循环到 nfds, 不能多循环
for (int i = 0; i < nfds; ++i)
{
TcpSocket sock(events[i].data.fd);
output->push_back(sock);
}
return true;
}
private:
int epoll_fd_;
};
class TcpEpollServer
{
public:
TcpEpollServer(const std::string &ip, uint16_t port) : ip_(ip), port_(port)
{
}
bool Start(Handler handler)
{
// 1. 创建 socket
TcpSocket listen_sock;
CHECK_RET(listen_sock.Socket());
// 2. 绑定
CHECK_RET(listen_sock.Bind(ip_, port_));
// 3. 监听
CHECK_RET(listen_sock.Listen(5));
// 4. 创建 Epoll 对象, 并将 listen_sock 加⼊进去
Epoll epoll;
epoll.Add(listen_sock);
// 5. 进⼊事件循环
for (;;)
{
// 6. 进⾏ epoll_wait
std::vector<TcpSocket> output;
if (!epoll.Wait(&output))
{
continue;
}
// 7. 根据就绪的⽂件描述符的种类决定如何处理
for (size_t i = 0; i < output.size(); ++i)
{
if (output[i].GetFd() == listen_sock.GetFd())
{
// 如果是 listen_sock, 就调用 accept
TcpSocket new_sock;
listen_sock.Accept(&new_sock);
epoll.Add(new_sock);
}
else
{
// 如果是 new_sock, 就进⾏⼀次读写
std::string req, resp;
bool ret = output[i].Recv(&req);
if (!ret)
{
// [注意!!] 需要把不用的 socket 关闭
// 先后顺序别搞反. 不过在 epoll 删除的时候其实就已经关闭 socket 了
epoll.Del(output[i]);
output[i].Close();
continue;
}
handler(req, &resp);
output[i].Send(resp);
} // end for
} // end for (;;)
}
return true;
}
private:
std::string ip_;
uint16_t port_;
};dict_server.cc 只需要将 server 对象的类型改成 TcpEpollServer 即可.
epoll示例: epoll服务器(ET模式)
基于 LT 版本稍加修改即可
-
修改 tcp_socket.hpp, 新增⾮阻塞读和⾮阻塞写接口
-
对于 accept 返回的 new_sock 加上 EPOLLET 这样的选项
注意: 此代码暂时未考虑 listen_sock ET 的情况. 如果将 listen_sock 设为 ET, 则需要⾮阻塞轮询的方式 accept. 否则会导致同⼀时刻⼤量的客⼾端同时连接的时候, 只能 accept ⼀次的问题.
tcp_socket.hpp
// 以下代码添加在 TcpSocket 类中
// ⾮阻塞 IO 接⼝
bool SetNoBlock()
{
int fl = fcntl(fd_, F_GETFL);
if (fl < 0)
{
perror("fcntl F_GETFL");
return false;
}
int ret = fcntl(fd_, F_SETFL, fl | O_NONBLOCK);
if (ret < 0)
{
perror("fcntl F_SETFL");
return false;
}
return true;
}
bool RecvNoBlock(std::string *buf) const
{
// 对于⾮阻塞 IO 读数据, 如果 TCP 接受缓冲区为空, 就会返回错误
// 错误码为 EAGAIN 或者 EWOULDBLOCK, 这种情况也是意料之中, 需要重试
// 如果当前读到的数据长度小于尝试读的缓冲区的长度, 就退出循环
// 这种写法其实不算特别严谨(没有考虑粘包问题)
buf->clear();
char tmp[1024 * 10] = {0};
for (;;)
{
ssize_t read_size = recv(fd_, tmp, sizeof(tmp) - 1, 0);
if (read_size < 0)
{
if (errno == EWOULDBLOCK || errno == EAGAIN)
{
continue;
}
perror("recv");
return false;
}
if (read_size == 0)
{
// 对端关闭, 返回 false
return false;
}
tmp[read_size] = '\0';
*buf += tmp;
if (read_size < (ssize_t)sizeof(tmp) - 1)
{
break;
}
}
return true;
}
bool SendNoBlock(const std::string &buf) const
{
// 对于⾮阻塞 IO 的写⼊, 如果 TCP 的发送缓冲区已经满了, 就会出现出错的情况
// 此时的错误号是 EAGAIN 或者 EWOULDBLOCK. 这种情况下不应放弃治疗
// ⽽要进⾏重试
ssize_t cur_pos = 0; // 记录当前写到的位置
ssize_t left_size = buf.size();
for (;;)
{
ssize_t write_size = send(fd_, buf.data() + cur_pos, left_size, 0);
if (write_size < 0)
{
if (errno == EAGAIN || errno == EWOULDBLOCK)
{
// 重试写⼊
continue;
}
return false;
}
cur_pos += write_size;
left_size -= write_size;
// 这个条件说明写完需要的数据了
if (left_size <= 0)
{
break;
}
}
return true;
}tcp_epoll_server.hpp
///////////////////////////////////////////////////////
// 封装⼀个 Epoll ET 服务器
// 修改点:
// 1. 对于 new sock, 加上 EPOLLET 标记
// 2. 修改 TcpSocket ⽀持⾮阻塞读写
// [注意!] listen_sock 如果设置成 ET, 就需要⾮阻塞调用 accept 了
// 稍微⿇烦⼀点, 此处暂时不实现
///////////////////////////////////////////////////////
#pragma once
#include <vector>
#include <functional>
#include <sys/epoll.h>
#include "tcp_socket.hpp"
typedef std::function<void(const std::string &, std::string *resp)> Handler;
class Epoll
{
public:
Epoll()
{
epoll_fd_ = epoll_create(10);
}
~Epoll()
{
close(epoll_fd_);
}
bool Add(const TcpSocket &sock, bool epoll_et = false) const
{
int fd = sock.GetFd();
printf("[Epoll Add] fd = %d\n", fd);
epoll_event ev;
ev.data.fd = fd;
if (epoll_et)
{
ev.events = EPOLLIN | EPOLLET;
}
else
{
ev.events = EPOLLIN;
}
int ret = epoll_ctl(epoll_fd_, EPOLL_CTL_ADD, fd, &ev);
if (ret < 0)
{
perror("epoll_ctl ADD");
return false;
}
return true;
}
bool Del(const TcpSocket &sock) const
{
int fd = sock.GetFd();
printf("[Epoll Del] fd = %d\n", fd);
int ret = epoll_ctl(epoll_fd_, EPOLL_CTL_DEL, fd, NULL);
if (ret < 0)
{
perror("epoll_ctl DEL");
return false;
}
return true;
}
bool Wait(std::vector<TcpSocket> *output) const
{
output->clear();
epoll_event events[1000];
int nfds = epoll_wait(epoll_fd_, events, sizeof(events) / sizeof(events[0]), -1);
if (nfds < 0)
{
perror("epoll_wait");
return false;
}
// [注意!] 此处必须是循环到 nfds, 不能多循环
for (int i = 0; i < nfds; ++i)
{
TcpSocket sock(events[i].data.fd);
output->push_back(sock);
}
return true;
}
private:
int epoll_fd_;
};
class TcpEpollServer
{
public:
TcpEpollServer(const std::string &ip, uint16_t port) : ip_(ip), port_(port)
{
}
bool Start(Handler handler)
{
// 1. 创建 socket
TcpSocket listen_sock;
CHECK_RET(listen_sock.Socket());
// 2. 绑定
CHECK_RET(listen_sock.Bind(ip_, port_));
// 3. 监听
CHECK_RET(listen_sock.Listen(5));
// 4. 创建 Epoll 对象, 并将 listen_sock 加⼊进去
Epoll epoll;
epoll.Add(listen_sock);
// 5. 进⼊事件循环
for (;;)
{
// 6. 进⾏ epoll_wait
std::vector<TcpSocket> output;
if (!epoll.Wait(&output))
{
continue;
}
// 7. 根据就绪的⽂件描述符的种类决定如何处理
for (size_t i = 0; i < output.size(); ++i)
{
if (output[i].GetFd() == listen_sock.GetFd())
{
// 如果是 listen_sock, 就调用 accept
TcpSocket new_sock;
listen_sock.Accept(&new_sock);
epoll.Add(new_sock, true);
}
else
{
// 如果是 new_sock, 就进⾏⼀次读写
std::string req, resp;
bool ret = output[i].RecvNoBlock(&req);
if (!ret)
{
// [注意!!] 需要把不用的 socket 关闭
// 先后顺序别搞反. 不过在 epoll 删除的时候其实就已经关闭 socket 了
epoll.Del(output[i]);
output[i].Close();
continue;
}
handler(req, &resp);
output[i].SendNoBlock(resp);
printf("[client %d] req: %s, resp: %s\n", output[i].GetFd(),
req.c_str(), resp.c_str());
} // end for
} // end for (;;)
}
return true;
}
private:
std::string ip_;
uint16_t port_;
};附录:回调机制
asmlinkage long
sys_epoll_ctl(int epfd, int op, int fd, struct epoll_event __user *event)
{
int error;
struct file *file, *tfile;
struct eventpoll *ep;
struct epitem *epi;
struct epoll_event epds;
... static int ep_insert(struct eventpoll * ep, struct epoll_event * event,
struct file * tfile, int fd)
{
int error, revents, pwake = 0;
unsigned long flags;
struct epitem *epi;
struct ep_pqueue epq;
error = -ENOMEM;
if (!(epi = kmem_cache_alloc(epi_cache, SLAB_KERNEL)))
goto eexit_1;
/* Item initialization follow here ... */
ep_rb_initnode(&epi->rbn);
INIT_LIST_HEAD(&epi->rdllink);
INIT_LIST_HEAD(&epi->fllink);
INIT_LIST_HEAD(&epi->txlink);
INIT_LIST_HEAD(&epi->pwqlist);
epi->ep = ep;
ep_set_ffd(&epi->ffd, tfile, fd);
epi->event = *event;
atomic_set(&epi->usecnt, 1);
epi->nwait = 0;
/* Initialize the poll table using the queue callback */
epq.epi = epi;
init_poll_funcptr(&epq.pt, ep_ptable_queue_proc);
....static void ep_ptable_queue_proc(struct file * file, wait_queue_head_t * whead,
poll_table * pt)
{
struct epitem *epi = ep_item_from_epqueue(pt);
struct eppoll_entry *pwq;
if (epi->nwait >= 0 && (pwq = kmem_cache_alloc(pwq_cache, SLAB_KERNEL)))
{
init_waitqueue_func_entry(&pwq->wait, ep_poll_callback); // 回调机制注册
给等待队列
pwq->whead = whead;
pwq->base = epi;
add_wait_queue(whead, &pwq->wait);
list_add_tail(&pwq->llink, &epi->pwqlist);
epi->nwait++;
}
else
{
/* We have to signal that an error occurred */
epi->nwait = -1;
}
}
static int ep_poll_callback(wait_queue_t * wait, unsigned mode, int sync, void *key)
{
int pwake = 0;
unsigned long flags;
struct epitem *epi = ep_item_from_wait(wait);
struct eventpoll *ep = epi->ep;
DNPRINTK(3, (KERN_INFO "[%p] eventpoll: poll_callback(%p) epi=%p ep=%p\n",
current, epi->ffd.file, epi, ep));
write_lock_irqsave(&ep->lock, flags);
... list_add_tail(&epi->rdllink, &ep->rdllist);
... struct sock
{
/*
* Now struct inet_timewait_sock also uses sock_common, so please just
* don't add nothing before this first member (__sk_common) --acme
*/
struct sock_common __sk_common;
#define sk_family __sk_common.skc_family
#define sk_state __sk_common.skc_state
#define sk_reuse __sk_common.skc_reuse
#define sk_bound_dev_if __sk_common.skc_bound_dev_if
#define sk_node __sk_common.skc_node
#define sk_bind_node __sk_common.skc_bind_node
#define sk_refcnt __sk_common.skc_refcnt
#define sk_hash __sk_common.skc_hash
#define sk_prot __sk_common.skc_prot
unsigned char sk_shutdown : 2,
sk_no_check : 2,
sk_userlocks : 4;
unsigned char sk_protocol;
unsigned short sk_type;
int sk_rcvbuf;
socket_lock_t sk_lock;
wait_queue_head_t *sk_sleep;
struct dst_entry *sk_dst_cache;
struct xfrm_policy *sk_policy[2];
rwlock_t sk_dst_lock;
atomic_t sk_rmem_alloc;
atomic_t sk_wmem_alloc;
atomic_t sk_omem_alloc;
struct sk_buff_head sk_receive_queue;
struct sk_buff_head sk_write_queue;
struct sk_buff_head sk_async_wait_queue;
int sk_wmem_queued;
int sk_forward_alloc;
gfp_t sk_allocation;
int sk_sndbuf;
int sk_route_caps;
int sk_gso_type;
int sk_rcvlowat;
unsigned long sk_flags;
unsigned long sk_lingertime;
/*
* The backlog queue is special, it is always used with
* the per-socket spinlock held and requires low latency
* access. Therefore we special case it's implementation.
*/
struct
{
struct sk_buff *head;
struct sk_buff *tail;
} sk_backlog;
struct sk_buff_head sk_error_queue;
struct proto *sk_prot_creator;
rwlock_t sk_callback_lock;
int sk_err,
sk_err_soft;
unsigned short sk_ack_backlog;
unsigned short sk_max_ack_backlog;
__u32 sk_priority;
struct ucred sk_peercred;
long sk_rcvtimeo;
long sk_sndtimeo;
struct sk_filter *sk_filter;
void *sk_protinfo;
struct timer_list sk_timer;
struct timeval sk_stamp;
struct socket *sk_socket;
void *sk_user_data;
struct page *sk_sndmsg_page;
struct sk_buff *sk_send_head;
__u32 sk_sndmsg_off;
int sk_write_pending;
void *sk_security;
void (*sk_state_change)(struct sock *sk);
void (*sk_data_ready)(struct sock *sk, int bytes); // 读事件就绪函
数... void sock_init_data(struct socket *sock, struct sock *sk)
{
skb_queue_head_init(&sk->sk_receive_queue);
skb_queue_head_init(&sk->sk_write_queue);
skb_queue_head_init(&sk->sk_error_queue);
#ifdef CONFIG_NET_DMA
skb_queue_head_init(&sk->sk_async_wait_queue);
#endif
sk->sk_send_head = NULL;
init_timer(&sk->sk_timer);
sk->sk_allocation = GFP_KERNEL;
sk->sk_rcvbuf = sysctl_rmem_default;
sk->sk_sndbuf = sysctl_wmem_default;
sk->sk_state = TCP_CLOSE;
sk->sk_socket = sock;
sock_set_flag(sk, SOCK_ZAPPED);
if (sock)
{
sk->sk_type = sock->type;
sk->sk_sleep = &sock->wait;
sock->sk = sk;
}
else
sk->sk_sleep = NULL;
rwlock_init(&sk->sk_dst_lock);
rwlock_init(&sk->sk_callback_lock);
lockdep_set_class(&sk->sk_callback_lock,
af_callback_keys + sk->sk_family);
sk->sk_state_change = sock_def_wakeup;
sk->sk_data_ready = sock_def_readable;
sk->sk_write_space = sock_def_write_space;
sk->sk_error_report = sock_def_error_report;
sk->sk_destruct = sock_def_destruct;
... static void sock_def_readable(struct sock * sk, int len)
{
read_lock(&sk->sk_callback_lock);
if (sk->sk_sleep && waitqueue_active(sk->sk_sleep))
wake_up_interruptible(sk->sk_sleep); // 通知所有在等待队列中等待的进程,执⾏
回调
sk_wake_async(sk, 1, POLL_IN);
read_unlock(&sk->sk_callback_lock);
}
#define wake_up_interruptible(x) __wake_up(x, TASK_INTERRUPTIBLE, 1, NULL)
void fastcall __wake_up(wait_queue_head_t * q, unsigned int mode,
int nr_exclusive, void *key)
{
unsigned long flags;
spin_lock_irqsave(&q->lock, flags);
__wake_up_common(q, mode, nr_exclusive, 0, key);
spin_unlock_irqrestore(&q->lock, flags);
}
static void __wake_up_common(wait_queue_head_t * q, unsigned int mode,
int nr_exclusive, int sync, void *key)
{
struct list_head *tmp, *next;
list_for_each_safe(tmp, next, &q->task_list)
{
wait_queue_t *curr = list_entry(tmp, wait_queue_t, task_list);
unsigned flags = curr->flags;
if (curr->func(curr, mode, sync, key) &&
(flags & WQ_FLAG_EXCLUSIVE) && !--nr_exclusive)
break;
}
}
/* Wait structure used by the poll hooks */
struct eppoll_entry
{
/* List header used to link this structure to the "struct epitem" */
struct list_head llink;
/* The "base" pointer is set to the container "struct epitem" */
void *base;
/*
* Wait queue item that will be linked to the target file wait
* queue head.
*/
wait_queue_t wait;
/* The wait queue head that linked the "wait" wait queue item */
wait_queue_head_t *whead;
};
typedef struct __wait_queue wait_queue_t;
typedef int (*wait_queue_func_t)(wait_queue_t *wait, unsigned mode, int sync,
void *key);
int default_wake_function(wait_queue_t * wait, unsigned mode, int sync, void *key);
struct __wait_queue
{
unsigned int flags;
#define WQ_FLAG_EXCLUSIVE 0x01
void *private;
wait_queue_func_t func;
struct list_head task_list;
};
有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 11
11 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)