刚刚,谷歌 Deep Think「重回巅峰」,OpenAI 首次「抛弃」英伟达
刚刚,谷歌 Deep Think「重回巅峰」,OpenAI 首次「抛弃」英伟达
ARC-AGI-2,84.6%。
这是公认最难的 AI 推理测试,人类平均正确率大概 60%。
谷歌刚刚升级的 Gemini 3 Deep Think,84.6%,断层第一。
第二名 Claude Opus 4.6,68.8%;第三名 GPT-5.2,只有 52.9%。
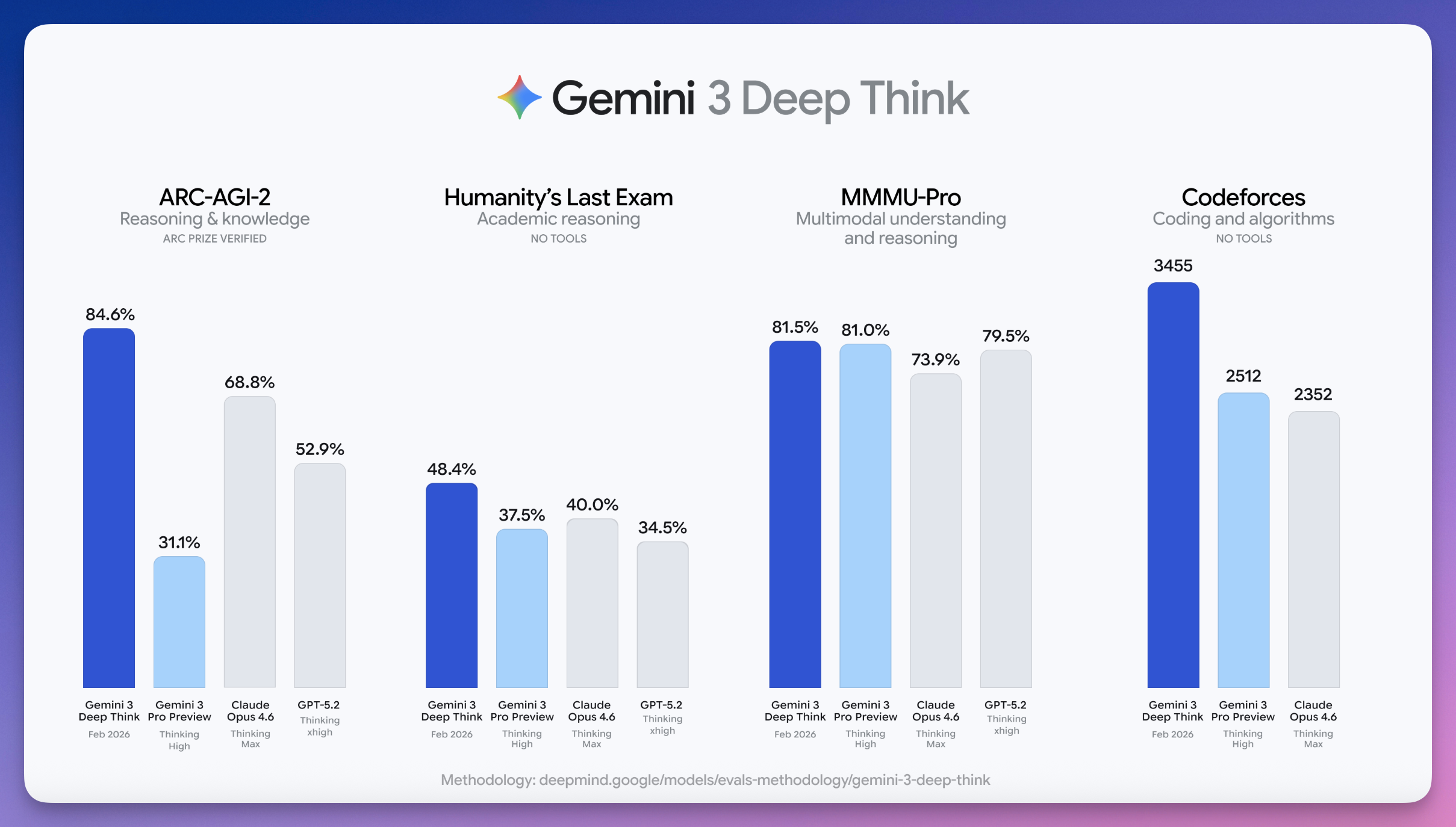
谷歌遥遥领先,重回巅峰。
同一天,OpenAI 把自己的新模型部署在了一颗不是英伟达的芯片上。
历史上第一次。
一个在赌「深度」,一个在赌「速度」。
谷歌的「推理暴力」
Gemini 3 Deep Think 不是一个新模型,是 Gemini 3 的深度推理模式。
去年 12 月初就发布了,这次是升级。
开启 Deep Think 后,模型会花更多的算力去「思考」,用多轮推理、并行假设探索来逼近最优解。
说人话,让模型慢慢想,想清楚再回答。
开头说的 ARC-AGI-2 就是它的成绩单。
这个测试不考你记住了多少知识,考的是你能不能从几个例子里自己归纳出规则。
84.6% 准确率,是 ARC Prize 官方验证的。
而在老版本 ARC-AGI-1 上,Deep Think 直接狂砍 96%。
这个曾经被认为「AI 最难攻克」的基准测试,已经即将被彻底拿下。
其他测试,谷歌也在屠榜。
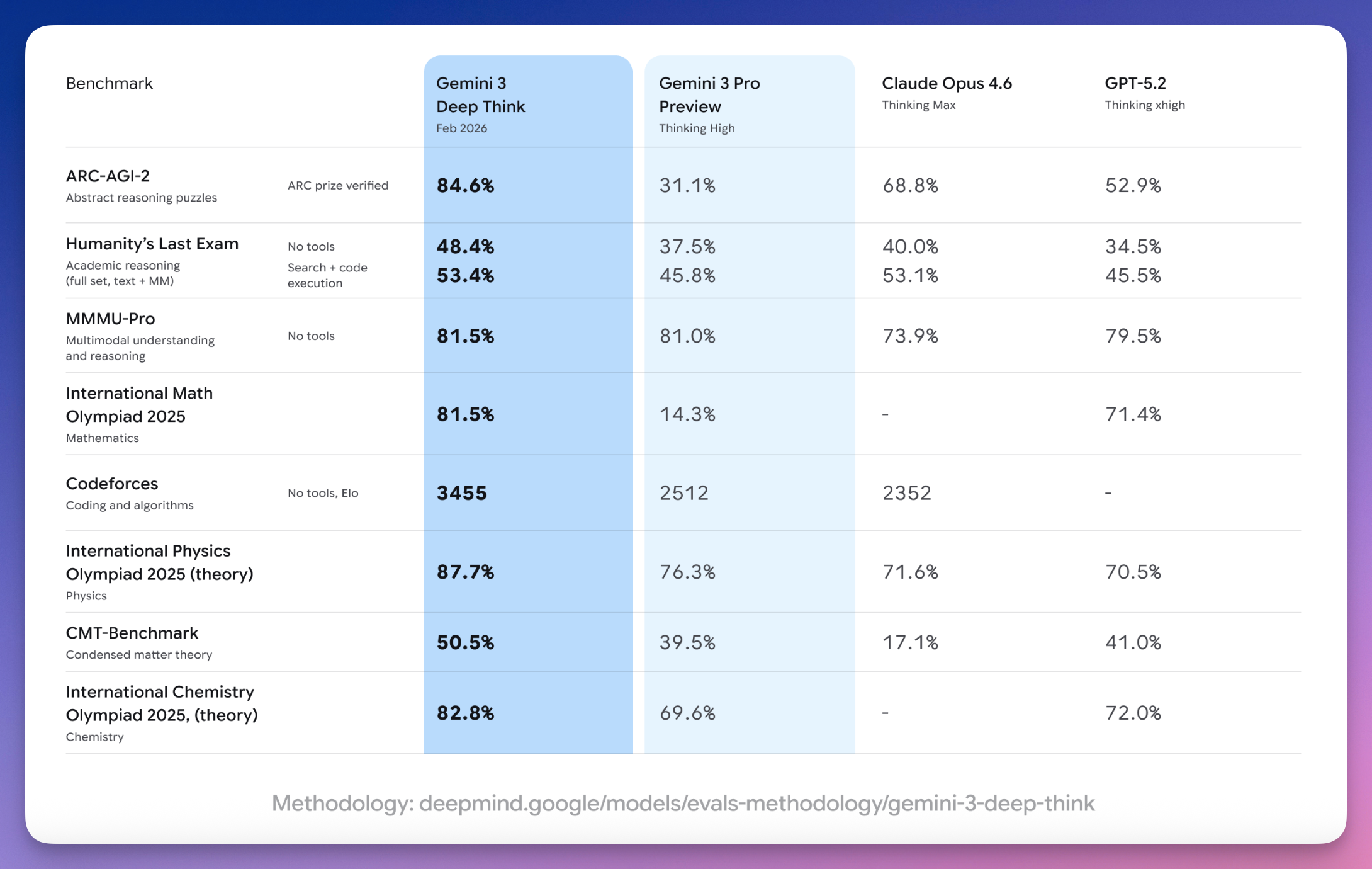
「人类最后一场考试」Humanity's Last Exam,48.4%,不用工具,新纪录。
Codeforces 编程竞赛 Elo 3455,「传奇宗师」(Legendary Grandmaster,Codeforces 最高等级头衔)级别,全球排名第八。
前面只剩了 7 个碳基程序员。
2025 年国际数学奥林匹克金牌,物理奥林匹克金牌,化学奥林匹克金牌。
数学、物理、化学,三科同时拿金牌。
谷歌在博客里讲了一个细节。
罗格斯大学的数学家 Lisa Carbone 用 Deep Think 审核一篇高度专业的数学论文,模型发现了一个微妙的逻辑漏洞。
这个漏洞之前通过了人类同行评审,没人看出来。

在另一个演示中,给 Deep Think 画一张草图,它能分析几何结构,直接生成 3D 打印文件。
从审论文到做 3D 打印,谷歌想说,「Deep Think 不只是刷榜机器。」
划重点,Deep Think 目前仅对 Google AI Ultra 订阅用户开放。
API 也首次开放了早期访问申请。
OpenAI 的「速度焦虑」
在谷歌让模型变聪明的同一天,OpenAI 做了一件完全相反的事。
新模型 GPT‑5.3‑Codex‑Spark,正式发布。
Spark,火花,一闪就亮。
顾名思义,GPT‑5.3‑Codex‑Spark 是 GPT-5.3-Codex 的青春版,专为实时编程设计。
不追求最强推理能力,主打一个「快」。
快到什么程度?
每秒 1000+ token。
带你感受一下来自 OpenAI 官方的对比视频。
(4.gif)
标准版 GPT-5.3-Codex 在 SWE-Bench Pro 上完成一个任务大概要十几分钟。
Codex-Spark 能在几分钟内搞定,准确率则介于 GPT-5.3-Codex 和 GPT-5.1-Codex-mini 之间。
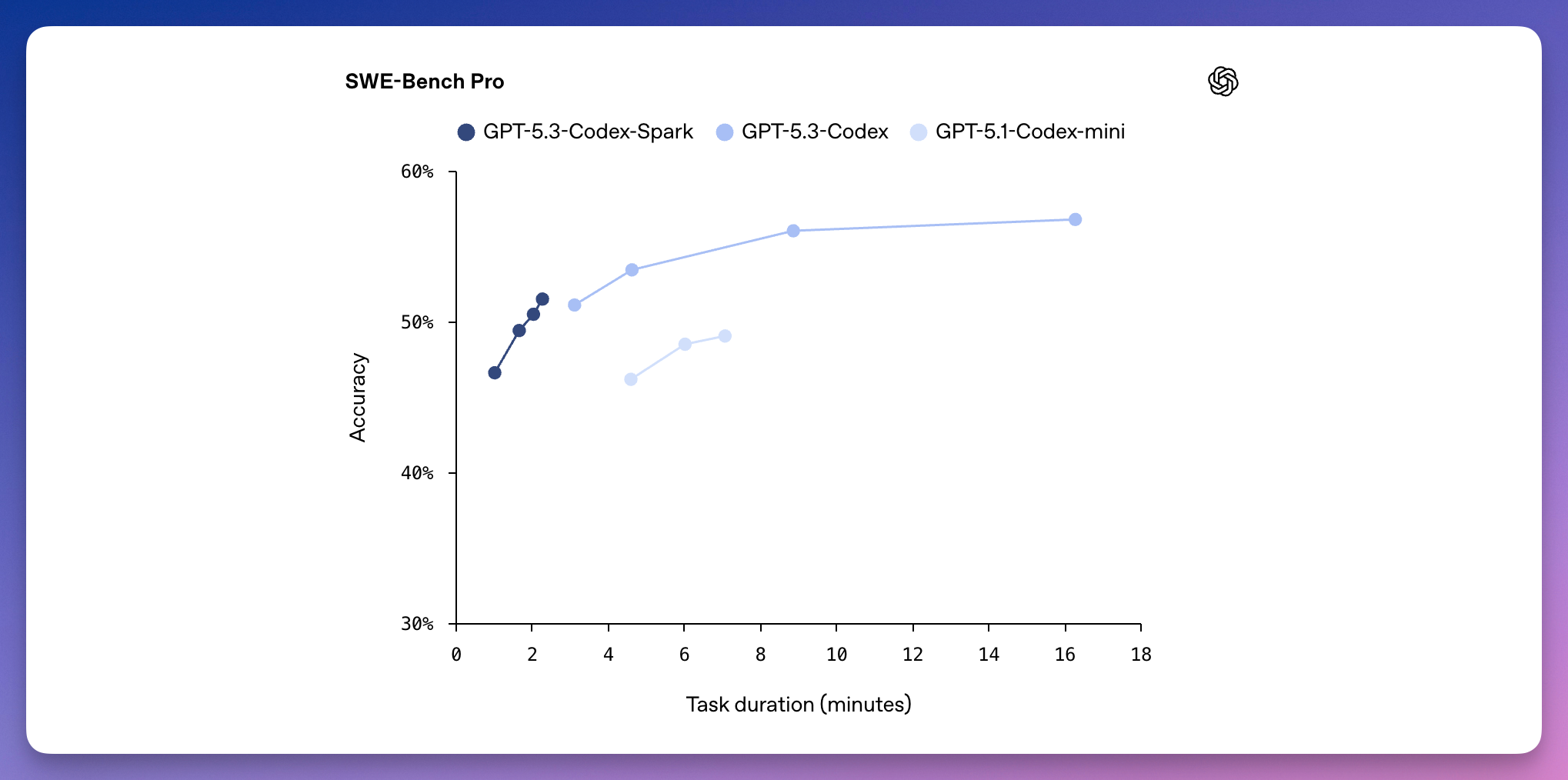
速度快了 15 倍,能力打了折扣。
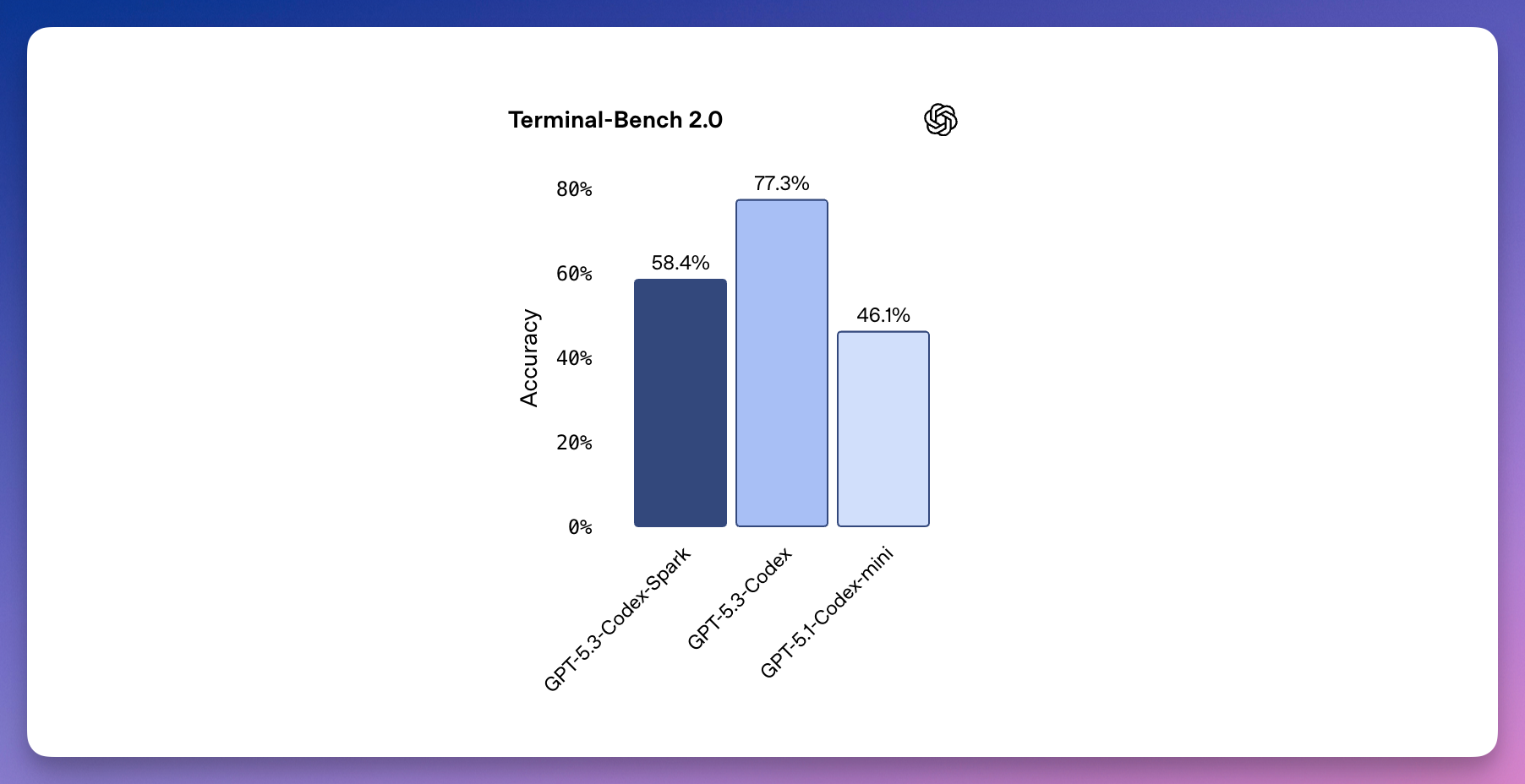
但 Codex-Spark 要解决的就是 AI 编程过程中的「等待」问题。
更有意思的是硬件。
Codex-Spark 跑在 Cerebras 的第三代晶圆级引擎上。
这颗芯片把计算、内存、带宽全塞在一块巨大的晶圆上,消除了传统 GPU 集群之间的数据传输瓶颈。
代价是内存只有 44GB,要知道,英伟达下一代 Rubin 是 288GB。

所以,Cerebras 不是来替代英伟达的,它专门给「对延迟极度敏感」的场景用。
OpenAI 说,GPU 依然是基础,Cerebras 是补充。
除了硬件,OpenAI 还重写了整个推理链。
引入持久化 WebSocket 连接,客户端到服务器的往返开销降了 80%,首 token 响应时间缩短 50%,单 token 处理开销减少 30%。
这些优化不只给 Codex-Spark 用,很快会推广到所有模型。
划重点,普通用户暂时用不了。
目前 Codex-Spark 只对 ChatGPT Pro 用户开放,支持 Codex App、命令行和 VS Code 插件。
128k 上下文,纯文本输入,API 只对少量合作伙伴开放。
把谷歌和 OpenAI 的动作放在一起看,很有意思。
谷歌在解决「怎么更聪明」。
不换硬件,不训练新模型,就在推理阶段多花算力。
同一个 Gemini 3 Pro,给它更多时间去想,分数能从 31.1% 提升到 84.6%。
OpenAI 在解决「怎么更快」。
模型已经够聪明了,但用起来太慢,开发者等不了。
所以签了 100 亿美元的芯片合同,重写推理管线,把延迟压缩到极致。
一个做加法,投入算力换推理深度。
一个做减法,砍掉能力换响应速度。
那么,AI 的下一个瓶颈到底是什么?
谷歌的答案是推理深度。
OpenAI 的答案是速度。
AI 的 2026,好戏还在后头。
我是木易,Top2 + 美国 Top10 CS 硕,现在是 AI 产品经理。
关注「AI信息Gap」,让 AI 成为你的外挂。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献115条内容
已为社区贡献115条内容

所有评论(0)