别让“卡间不同步”毁掉训练:深度解析 DDP/NCCL 调试的完整避坑指南
本文针对PyTorch DDP(NCCL后端)多卡训练中的“卡间不同步”问题,提供了一套系统化的调试方案。通过四层排错模型(基础设施→通信链路→代码逻辑→容错监控),定位常见死锁根因,包括网络配置错误、数据采样不一致、梯度累积步数错位等。重点推荐三类工具: NCCL环境变量(如NCCL_DEBUG=INFO)实时监控通信状态; 显式设备绑定与数据对齐策略,避免进程间显存地址冲突; Fail-Fas
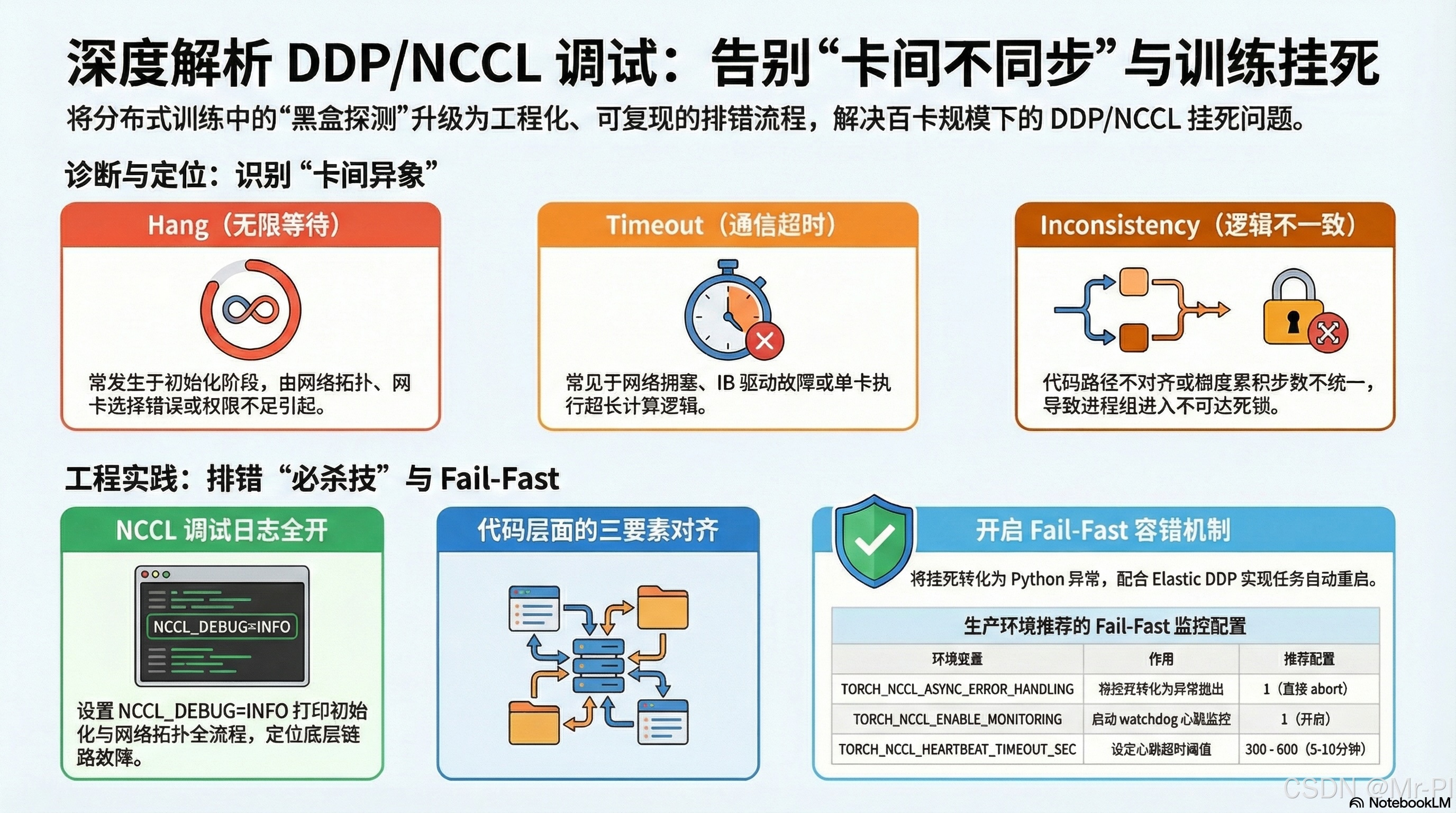
别让“卡间不同步”毁掉训练:深度解析 DDP/NCCL 调试的完整避坑指南
目标读者:使用 PyTorch DDP(NCCL 后端)进行多卡 / 百卡大模型训练的研发与运维工程师
核心价值:把"黑盒探测"升级为 工程化、可复现 的排错流程,覆盖 网络 → 硬件 → 驱动 → 代码 四层面的常见失效点
适用版本:PyTorch ≥ 2.x · NCCL ≥ 2.19 · CUDA ≥ 12.x · torchrun / Elastic Launch
1️⃣ 引言:从"幽灵"到可定位
深夜启动的百卡大模型任务,第二天只看到 GPU Util 100%,却没有任何 loss 变化——这往往是 某一次集体通信(All‑Reduce / Barrier)失配 导致的 卡间 deadlock。
典型症状:
• Rank 0 仍在前进,其他 Rank 卡在同步点
• 程序没有报错,GPU 利用率居高不下
• 日志里只出现 NCCL Timeout 或watchdog aborted
传统的"重启大法"与"盲目重装驱动"往往只能掩饰根因。本文提供一套 从底层通信到代码实现 的排错手册,让每一次挂死都能在 几分钟内定位。
2️⃣ 全局视角:排错分层架构
下面用 Mermaid 图展示分布式训练排错的 四层模型,自底向上逐层收敛:
3️⃣ 核心痛点:三类"卡间异象"
| 症状 | 产生阶段 | 典型根因 |
|---|---|---|
| 🔴 Hang(无限等待) | dist.init_process_group() 或首次 NCCL 集体调用 |
网络拓扑错误、网卡选择错误、NCCL 初始化权限不足、forkserver 未设置 |
| 🟡 | NCCL_NET_GDR_LEVEL |
控制 GPU‑Direct‑RDMA 等级(0/1/2) |
NCCL_ALGO / NCCL_PROTO |
手动指定集体算法(Ring/Tree)和协议(Simple/LL) | 排查算法层面的不兼容 |
NCCL_P2P_DISABLE=1 |
关闭 NVLink / PCIe P2P 通路(用于硬件拓扑异常)【21†L528-L533】 | 确认是否是 P2P 失效 |
NCCL_IB_DISABLE=1 |
完全禁用 InfiniBand,转为 TCP/IP | 验证 IB 驱动是否是根因 |
NCCL_NSOCKETS、NCCL_SOCKET_NTHREADS |
调整 socket 并发线程数,提升 100 G 网络下的吞吐 | 大规模跨机房时的性能微调 |
实验思路:先全开(默认),若仍挂死 → 逐一禁用(先
NCCL_IB_DISABLE,再NCCL_P2P_DISABLE),观察日志中是否仍出现NET子系统的报错。
3.3 通过 nccl-tests 验证底层链路
# 所有节点均执行
git clone <https://github.com/NVIDIA/nccl-tests.git> && cd nccl-tests
make -j$(nproc)
mpirun -np $WORLD_SIZE ./build/all_reduce_perf -b 8 -e 512M -f 2
成功的基准输出(带宽 > 30 GB/s)说明 NCCL 通信层面 正常;若出现 Transport failed,则可依据上述变量继续排查。
4️⃣ 必杀技 Ⅱ — Rank 绑定 & 代码对齐细节
4.1 GPU 设备显式绑定
torch.cuda.set_device(local_rank) # 必须在任何 NCCL 调用前执行【18†L626-L630】
为什么:未绑定时 NCCL 默认使用 进程 0 的 GPU,导致跨进程的地址不匹配,引发 hang。
4.2 DistributedSampler 与数据对齐
sampler = torch.utils.data.distributed.DistributedSampler(
dataset, drop_last=True) # 确保每个 Rank 采样数相同【25†L45-L48】
- drop_last=True:当
len(dataset) % (world_size * batch_size) != 0时,自动丢弃尾部样本,防止某些 Rank 在 epoch 结束 前提前退出。 - set_epoch 必须在每轮训练 创建 DataLoader 迭代器之前 调用(确保跨 epoch shuffle 同步)【25†L50-L55】。
4.3 防止步数不一致
| 常见陷阱 | 对策 |
|---|---|
if/continue 导致某 Rank 跳过 loss.backward() |
所有涉及 All‑Reduce 的代码块必须 在同一 collective 前后出现相同次数。 |
| 梯度累积(gradient accumulation)步数不对齐 | 在 optimizer.step() 前确保 所有 rank 完成相同次数的 loss.backward(),可用 assert torch.cuda.is_available() 或自行计数。 |
amp / torch.autocast 与 torch.cuda.amp.GradScaler 步数不匹配 |
在 scaler.step() 与 optimizer.zero_grad() 前统一 torch.distributed.barrier(),防止某 Rank 提前进入下一轮。 |
| 某 Rank 因 OOM 提前退出 | 建议在 torch.cuda.OutOfMemoryError 捕获后 手动 dist.destroy_process_group() 并让所有进程统一退出,避免“假忙”。 |
5️⃣ 必杀技 Ⅲ — Fail‑Fast 机制让挂死可感知
| 环境变量 | 默认 | 作用 | 何时开启 |
|---|---|---|---|
TORCH_NCCL_ASYNC_ERROR_HANDLING |
3(仅记录) | 将 NCCL 内部挂死转化为 Python 异常;1 直接 abort 通信器并退出进程【9†L89-L95】 |
生产环境强烈建议开启 |
TORCH_NCCL_ENABLE_MONITORING |
0 | 启动 watchdog 心跳线程,检测到 无心跳 超过 TORCH_NCCL_HEARTBEAT_TIMEOUT_SEC 时 abort 进程【9†L121-L127】 |
|
TORCH_NCCL_HEARTBEAT_TIMEOUT_SEC |
30 s | 心跳超时时间阈值;建议根据最长单次计算(如 Validation)设定 300 s 或 600 s【9†L128-L136】 | |
TORCH_NCCL_DUMP_ON_TIMEOUT |
0 | 超时自动 dump 调试信息(需配合 TORCH_NCCL_TRACE_BUFFER_SIZE>0) |
|
TORCH_NCCL_TRACE_BUFFER_SIZE |
0 | 控制记录 NCCL 事件的环形缓冲区大小;>0 可与 DUMP_ON_TIMEOUT 共同使用 |
|
TORCH_NCCL_DESYNC_DEBUG |
0 | 开启 Desync Debug,在 All‑Reduce 时打印出 “culprit rank”【9†L111-L115】 |
实战配置(单卡/多卡均适用):
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
export TORCH_NCCL_ENABLE_MONITORING=1
export TORCH_NCCL_HEARTBEAT_TIMEOUT_SEC=300 # 5 min,仅当单轮训练最长 <5 min 时使用
export TORCH_NCCL_DUMP_ON_TIMEOUT=1
export TORCH_NCCL_TRACE_BUFFER_SIZE=1024 # 记录最近 1024 条 NCCL 事件
5.1 与 Elastic DDP 结合
使用 torchrun / torch.distributed.elastic 时,以上变量会让 异常抛出 并触发 任务自动重启,显著提升集群资源利用率。
6️⃣ 工程实践:全链路排错 Checklist(最新)
| 类别 | 核心检查项 | 备注 |
|---|---|---|
| 基础设施 | ✅ nvidia-smi、nvcc --version 一致(驱动 ≈ CUDA)✅ 所有节点 NCCL 2.x 版本相同( nccl-tests 能跑通)✅ NCCL_SOCKET_IFNAME 正确指向物理网卡✅ TORCH_NCCL_ASYNC_ERROR_HANDLING=1 已打开 |
驱动/CUDA 不匹配是多数跨机挂死的根源 |
| 网络/拓扑 | ✅ NCCL_DEBUG_SUBSYS 包含 NET、GRAPH✅ 如使用 InfiniBand,检查 NCCL_IB_HCA 与 NCCL_NET_GDR_LEVEL✅ 用 nccl-tests 验证跨机器带宽 |
若报 NET 子系统错误,先 NCCL_SOCKET_IFNAME / NCCL_IB_DISABLE |
| 设备绑定 | ✅ torch.cuda.set_device(local_rank)(每个进程唯一)✅ CUDA_VISIBLE_DEVICES 与 local_rank 对齐(容器/K8s) |
参考官方文档警告 |
| 数据对齐 | ✅ DistributedSampler(drop_last=True) 或自行确保 len(dataset) % (world_size*batch_size) == 0【25†L45-L48】✅ sampler.set_epoch(epoch) 每 epoch 前调用【25†L50-L55】 |
|
| 梯度/累积一致性 | ✅ 所有 loss.backward()、optimizer.step() 在同一 for 循环里出现相同次数✅ 如使用 GradScaler,确保 scaler.step() 与 zero_grad() 同步✅ 如有条件分支( if/continue),保证每个 rank 都走到相同的 collective |
防止 “梯度不同步” |
| Fail‑Fast | ✅ TORCH_NCCL_ASYNC_ERROR_HANDLING=1✅ TORCH_NCCL_ENABLE_MONITORING=1 + 合适的 HEARTBEAT_TIMEOUT_SEC✅ TORCH_NCCL_DUMP_ON_TIMEOUT=1 & TRACE_BUFFER_SIZE>0 |
让卡死瞬间抛异常,方便自动化重启 |
| 日志与审计 | ✅ NCCL_DEBUG=INFO + NCCL_DEBUG_FILE=/tmp/nccl_${RANK}.log✅ torch.distributed.barrier() 在 checkpoint 前后同步 |
便于事后回溯 |
7️⃣ 一键套用:Debug 与 Prod 环境 Bash 模板
说明:下方变量均已 兼容多机多卡,请在
torchrun启动脚本前 source。
7.1 DEBUG 档(定位根因)
# 基础通信日志
export NCCL_DEBUG=INFO
export NCCL_DEBUG_SUBSYS=INIT,NET,GRAPH,COLL
# 指定网卡(根据实际网卡名)
export NCCL_SOCKET_IFNAME=eth0
# 强制绑定 GPU(容器内需配合 CUDA_VISIBLE_DEVICES)
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# Fail‑fast 监控
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
export TORCH_NCCL_ENABLE_MONITORING=1
export TORCH_NCCL_HEARTBEAT_TIMEOUT_SEC=300
export TORCH_NCCL_DUMP_ON_TIMEOUT=1
export TORCH_NCCL_TRACE_BUFFER_SIZE=2048
# 细粒度调优(临时实验)
# export NCCL_ALGO=Ring
# export NCCL_PROTO=LL
# export NCCL_IB_DISABLE=1
# export NCCL_P2P_DISABLE=1
# 将每个 Rank 的 NCCL 日志写入独立文件,便于对比
export NCCL_DEBUG_FILE=/tmp/nccl_${RANK}.log
7.2 PROD 档(高可用、轻日志)
export NCCL_DEBUG=WARN
export NCCL_SOCKET_IFNAME=eth0
export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7
# 保留 Fail‑fast,心跳放宽到 10 min(容纳长 Validation)
export TORCH_NCCL_ASYNC_ERROR_HANDLING=1
export TORCH_NCCL_ENABLE_MONITORING=1
export TORCH_NCCL_HEARTBEAT_TIMEOUT_SEC=600
# 只记录异常日志,避免磁盘占满
export NCCL_DEBUG_FILE=/tmp/nccl_${RANK}.log
Tip:在 K8s 环境中,
NCCL_SOCKET_IFNAME与NCCL_IB_HCA常配合NCCL_IB_DISABLE=1使用,防止容器内部的虚拟网卡干扰。
8️⃣ 结语:把“玄学调试”变成“工程确定性”
- 底层:通过 NCCL 环境变量 + nccl‑tests 让通信链路透明化。
- 进程层:显式 GPU 绑定、Barrier / set_device、DistributedSampler 保证 步数对齐。
- 容错层:开启 TORCH_NCCL_ASYNC_ERROR_HANDLING、监控线程 与 Elastic DDP,让挂死自动 Fail‑Fast 并 自动重启。
只要把 Checklist 与 Bash 模板 融入每日的启动脚本,绝大多数 “卡间不同步” 的幽灵都能在 工程层面 被捕获、定位、消除,而不需要深夜盯着卡死的 GPU 炸裂日志。
📢 互动思考
在你的分布式训练生涯中,哪一次因为 环境微差(如 IB 驱动版本不统一、drop_last 失配)导致的挂死让你印象最深?欢迎在评论区分享你的实战经验与避坑技巧。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 27
27 0
0- 0



 已为社区贡献15条内容
已为社区贡献15条内容

所有评论(0)