大模型应用:K-Means/LDA + 大模型:无监督文本自动打标完整方案.85
摘要:本文提出了一种结合聚类算法与大模型的非结构化文本自动分类方案,有效解决无标签数据处理难题。通过K-Means/LDA聚类算法实现文本自动分组,再利用大模型的语义理解能力为聚类结果生成业务可理解的标签和解释。该方法包含数据预处理、向量化、聚类分析、大模型标签生成等完整流程,显著降低人工标注成本,提升文本分析效率。实验以电商评论为例,展示了从原始数据到业务标签体系的转化过程,证实该方案能有效挖掘
一、前言
在日常工作中,非结构化文本数据已成为企业运营、用户研究、内容治理的核心资源,电商评论、客服工单、用户反馈、新闻资讯、业务日志等海量文本,藏着最真实的需求与问题。但现实中,绝大多数文本数据都没有现成标签,人工标注耗时耗力、成本高昂且标准不一,成为文本智能分析落地的最大障碍。传统无监督学习中,K-Means 聚类、LDA 主题模型等算法虽能实现数据自动分组,却只能给出“类别 1、类别 2”这类无意义的数字编号,无法解释簇内语义、无法生成业务可理解的分类名称,最终让聚类结果停留在算法层面,难以真正用于业务决策。
大模型的崛起,为无监督自动打标带来了新的构想与突破。它凭借强大的语义理解、归纳总结与逻辑解读能力,成为聚类算法的语义搭档:先由聚类完成相似文本的精准分组,再由大模型为每一类赋予清晰标签、提炼核心特征、生成业务解释,让冰冷的算法分组变成有价值、可落地的智能标签体系。今天我们围绕聚类算法 + 大模型的无监督自动打标方案,聚焦大模型在语义赋能、结果解读、标签生成中的关键作用,通俗的理解零标签数据的自动分类技术,真正释放文本数据的核心价值。

二、核心概念
1. 无监督自动打标
没有提前给数据标好类别,完全靠算法自动给数据分组,再生成有业务意义的标签。在真实业务中,我们常常面对海量未标注数据:
- 几万条用户评论,没人标记是“物流慢”还是“质量差”,没有“好评/差评”、“价格问题/物流问题”的标签;
- 成千上万条客服对话,不知道属于哪些问题类型;
- 标注成本高、周期长,人工分类效率低。
这时候,不能等完善标签再行动,我们需要一种“先粗分、再精标”的自动化方案。
2. 聚类算法(K-Means/LDA)
像一位不知疲倦的超市理货员,不看商品标签,只按长得像(数据相似性)把商品分到不同货架(聚类簇):
- 它不认识商品名字(没有预设类别),
- 但能通过外观、气味、包装风格(文本语义、关键词分布)判断“哪些东西是一伙的”。
- 把“吐槽价格”的评论都归到一个货架,“夸质量”的归到另一个。
举个例子:
- 所有包含“太贵了”、“比别家贵”、“性价比低”的评论 → 被归到 簇 A;
- 所有提到“三天就到”、“快递神速”、“包装完好”的评论 → 被归到 簇 B;
- 虽然它不知道这些簇该叫什么,但它确保同类内容尽量聚在一起。
这一步的价值:把混乱的数据整理成有序的“货架”,为后续命名打下基础。
3. 大模型
像超市的资深导购,看到每个货架的商品后,给货架贴清晰的标签,还能说明这个货架的核心特征;在聚类后每个“货架”(聚类簇)里堆满了相似内容,但还没有名字和说明,这时,大模型这位“资深导购”开始进行分析和说明,比如“该类评论主要抱怨商品定价过高,对比竞品性价比低”:
- 1. 输入一个簇的代表性样本,比如10条“簇 A”的评论;
- 2. 提示它:“你是一位用户体验分析师,请为这类用户反馈总结一个简洁、准确的类别名称,并用一句话描述其核心特征。”
- 3. 输出示例:
- 类别名称:价格敏感型负面反馈
- 核心特征:用户普遍认为产品定价偏高,与竞品相比缺乏性价比,常伴随“不值这个价”、“太贵了”等表述。
这一步的价值:把冷冰冰的数字分组,转化为业务可理解、可行动的洞察标签。
三、基础知识
1. 无标签数据的痛点
实际工作中,评论、工单、错题这类文本数据大多没有标签:
- 人工打标成本极高,10万条评论人工打标可能要数周);
- 人工打标主观性强,不同人对“服务差”的定义可能不同);
- 数据量增长快,人工打标跟不上。
2. 聚类算法的核心能力
聚类是无监督学习,不需要标签,核心是 “找相似、分群体”,常用的两种算法对比:
2.1 K-Means
K-Means是按距离分堆的高效理货员,它的核心思想非常直观:把数据看作空间中的点,距离近的归为一类。它假设每个样本只属于一个明确的类别(称为“硬聚类”),就像超市理货员把每件商品只放进一个货架。
核心原理:用“分苹果”举例:
- 第一步:我们想把100个苹果分成 3 堆,则K=3,先随便选 3 个苹果当“堆中心”;
- 第二步:把每个苹果放到离它最近的中心那一堆;
- 第三步:重新计算每堆的“新中心”,比如每堆苹果大小的平均值;
- 第四步:重复第二步和第三步,直到每堆的中心不再变化;

- 最终:3堆苹果就是3个聚类,每堆内部苹果的大小和颜色更相似。
适合场景:
- 特别适用于短文本、结构化程度较高的数据,比如用户评论、客服工单、问卷反馈等。
- 当我们希望快速把几千条内容粗略分成几大类,例如“价格类”、“物流类”、“质量类”,K-Means是首选。
主要优点:
- 速度快:即使处理上万条数据,也能在秒级完成;
- 简单稳定:原理易懂,实现成熟,几乎所有机器学习库都支持;
- 结果清晰:每个样本有明确归属,便于后续统计和处理。
注意事项:
- 必须提前指定类别数量 K,比如分3类还是5类,选不好会影响效果;
- 对异常值敏感,一条极端评论可能拉偏整个簇的中心;
- 无法处理“模糊归属”,比如一条评论既谈价格又谈物流,它只能硬塞进其中一类。
总结:快、稳、简单,适合做第一轮粗分。
2.2 LDA(隐狄利克雷分配)
LDA就像挖掘主题的语义侦探, 不是看距离,而是从文本中自动发现潜在的主题结构。它认为每篇文档都是多个主题的混合,比如60%是“价格”,40%是“服务”,属于“软聚类”或“概率聚类”。
核心原理:用“写作文”举例:
- 假设现在有100篇作文,LDA 假设:
- 1. 每篇作文由多个“主题”组成,比如一篇作文30%是“校园生活”,70%是“亲情”;
- 2. 每个“主题”由多个关键词组成,比如“校园生活”主题包含“上课、考试、操场”;
- LDA 的目标:找出隐藏的主题,以及每篇作文的主题分布。
- 对应文本场景:“作文”是评论、工单,“主题”是聚类的类别,“关键词”是文本中的核心词。
适合场景:
- 更擅长处理较长、信息丰富的文本,如新闻文章、学术论文、产品说明书、用户长反馈等。
- 当我们想了解“用户到底在讨论哪些核心话题”,而不仅是简单分组时,LDA 能揭示更深层的语义结构。
主要优点:
- 输出可解释的主题:不仅分组,还能告诉你每个主题由哪些关键词组成,如主题1=[价格, 贵, 性价比, 便宜];
- 支持多主题归属:一条内容可同时关联多个主题,更符合真实语言表达;
- 语义层次更深:能发现“隐含话题”,而非仅靠表面词汇匹配。
注意事项:
- 训练较慢,尤其数据量大时;
- 参数调优复杂:需设定主题数、超参数 alpha/beta,效果对设置敏感;
- 对短文本效果有限:微博、短评这类内容信息太少,难以形成稳定主题分布。
总结:语义丰富、可解释性强,适合深度挖掘长文本的主题脉络。
3. 大模型的补充能力
作用原理:大模型基于海量文本训练,能理解语义:
- 输入:“以下是 10 条电商评论:1. 物流太慢了 2. 快递送了7天 3. 配送员态度差... 请给这类评论起一个业务标签,并解释核心特征”;
- 大模型输出:“标签:物流体验差;解释:该类评论核心反映用户对物流配送速度慢、配送人员服务态度不佳的不满,占比约25%”。
强化能力:
- 聚类只能输出“第 1 类、第 2 类”这种无意义的数字编号,而大模型能解决:
- 把数字编号转化为业务可理解的标签,比如“第 1 类”对应为“物流速度慢”;
- 解释每类的核心特征,比如“该类包含60%的用户吐槽快递超过7天送达”;
- 适配口语化/模糊文本,比如“这玩意儿太贵了”→ 大模型能识别是“价格异议”。
核心价值:
- 1. 从“数字编号”到“业务标签”:聚类输出的“类 1、类 2”无业务意义,大模型把它转化为“价格异议、物流体验差”等能直接用于业务的标签;
- 2. 降低人工成本:无需人工给每个聚类簇命名,大模型1分钟可生成所有类别的标签和解释,仅需少量人工校验;
- 3. 适配复杂语义:处理口语化、模糊化文本,比如“这玩意儿不值这个价”,大模型能准确识别核心诉求,比人工命名更全面;
- 4. 可解释性提升:不仅给标签,还能解释类别的核心特征,帮助业务人员理解数据规律,比如“该类工单主要是用户咨询退款流程”。
四、执行流程
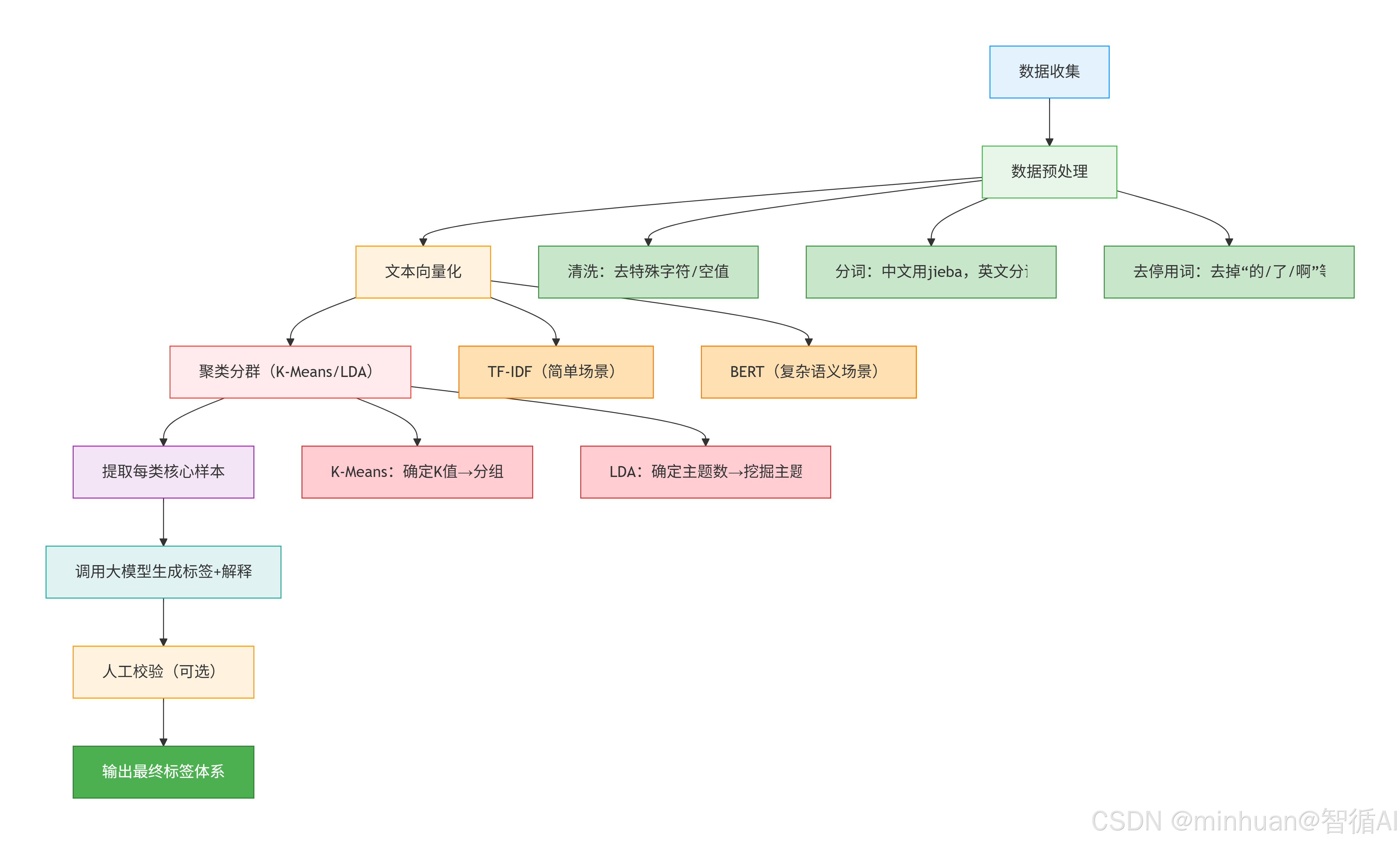
流程说明:
- 1. 数据收集:获取原始文本数据,比如电商评论、客服工单;
- 2. 数据预处理:
- 清洗:删除乱码、空行、重复数据;
- 分词:中文用jieba把“物流速度太慢了”拆成“物流、速度、太慢”;
- 去停用词:去掉“的、了、啊”这些对语义无帮助的词;
- 3. 文本向量化:把文字转化为计算机能计算的数字向量,比如TF-IDF把“物流慢”转化为[0.2, 0.8, 0.0,...];
- 4. 聚类分群:用 K-Means/LDA 把相似的向量分到同一类;
- 5. 提取核心样本:取出每类中最具代表性的文本,比如聚类中心附近的样本;
- 6. 大模型生成标签:把核心样本传给大模型,指令让它生成标签和解释;
- 7. 人工校验:可选步骤,修正大模型生成的不合理标签;
- 8. 输出标签体系:最终得到“类别 ID + 业务标签 + 解释”的完整体系。
五、完整示例
# 导入所需库
import pandas as pd
import jieba
import re
import matplotlib.pyplot as plt
import seaborn as sns
from wordcloud import WordCloud
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.cluster import KMeans
from sklearn.decomposition import LatentDirichletAllocation
from sklearn.metrics import silhouette_score
from openai import OpenAI
# from dotenv import load_dotenv
import os
# 配置环境(解决中文显示问题)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 显示中文
plt.rcParams['axes.unicode_minus'] = False # 显示负号
# 加载环境变量(存储大模型API密钥)
# load_dotenv()
# openai.api_key = os.getenv("OPENAI_API_KEY") # 替换为你的API密钥,或直接赋值
# ===================== 步骤1:准备测试数据(模拟电商评论) =====================
def get_test_data():
"""生成模拟的电商评论数据"""
data = {
"comment": [
"物流速度太慢了,等了7天才到",
"快递员态度很差,直接把包裹放门口",
"商品质量很好,和描述的一致",
"价格太贵了,比别家贵了50块",
"质量不行,用了2天就坏了",
"物流很快,第二天就收到了",
"性价比不高,价格偏高",
"配送员态度很好,还帮忙搬上楼",
"商品有瑕疵,做工粗糙",
"价格实惠,值得购买",
"物流延迟,联系客服也没用",
"质量超预期,比想象的好",
"定价不合理,性价比低",
"快递包装破损,商品被压坏了",
"客服回复慢,解决问题不及时"
]
}
df = pd.DataFrame(data)
return df
# ===================== 步骤2:数据预处理 =====================
def preprocess_text(text):
"""文本预处理:清洗、分词、去停用词"""
# 1. 清洗:去掉特殊字符、数字
text = re.sub(r'[^\u4e00-\u9fa5]', '', text)
# 2. 分词
words = jieba.lcut(text)
# 3. 去停用词(自定义停用词表)
stopwords = {"的", "了", "是", "就", "也", "都", "很", "还", "比", "和", "有", "用"}
words = [word for word in words if word not in stopwords and len(word) > 1]
return " ".join(words)
# ===================== 步骤3:文本向量化(TF-IDF) =====================
def vectorize_text(df):
"""对预处理后的文本进行TF-IDF向量化"""
tfidf = TfidfVectorizer(max_features=1000) # 保留1000个高频词
X = tfidf.fit_transform(df["processed_comment"])
# 获取特征名(词汇表)
feature_names = tfidf.get_feature_names_out()
return X, feature_names, tfidf
# ===================== 步骤4:K-Means聚类(选择最优K值) =====================
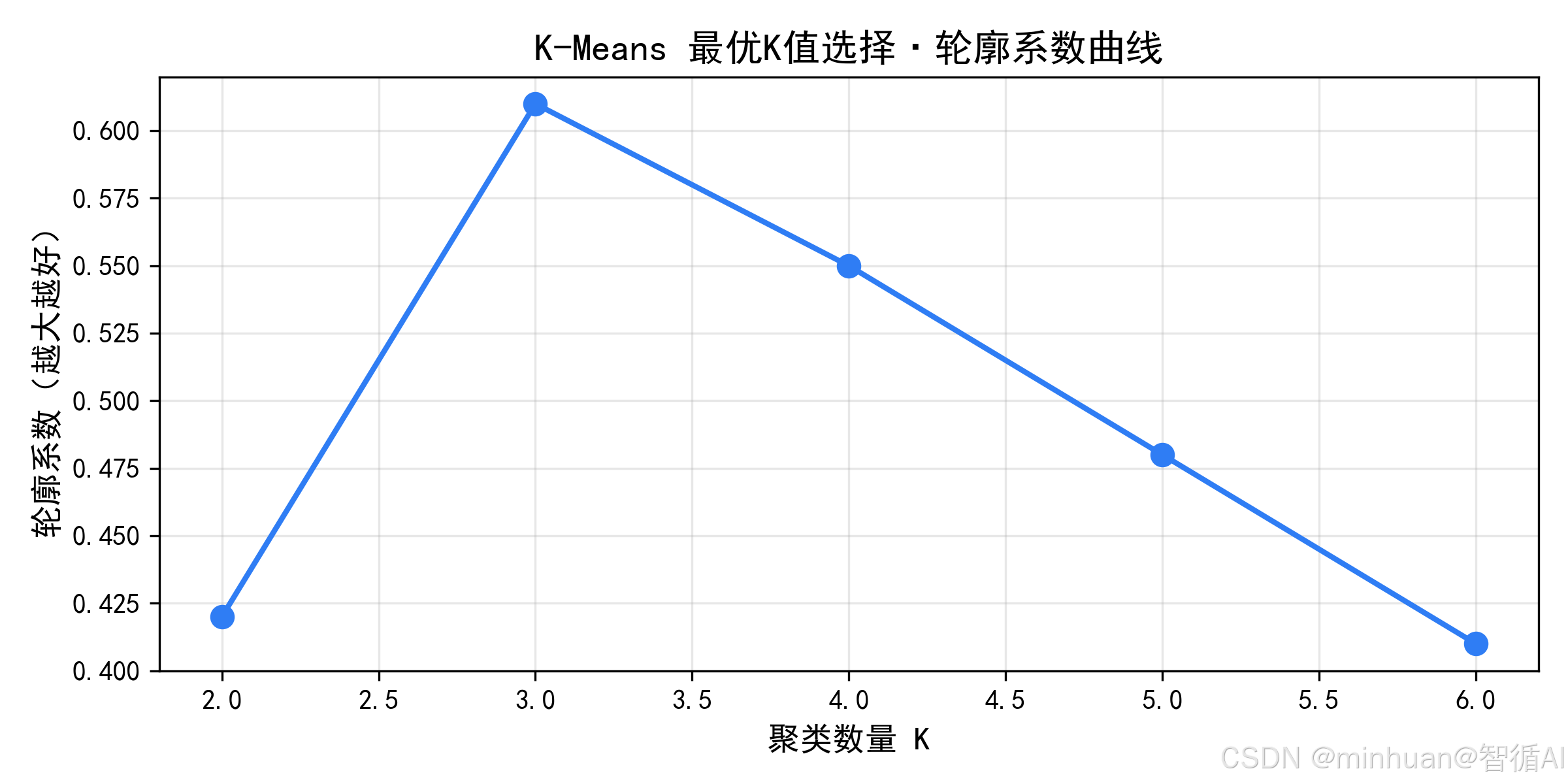
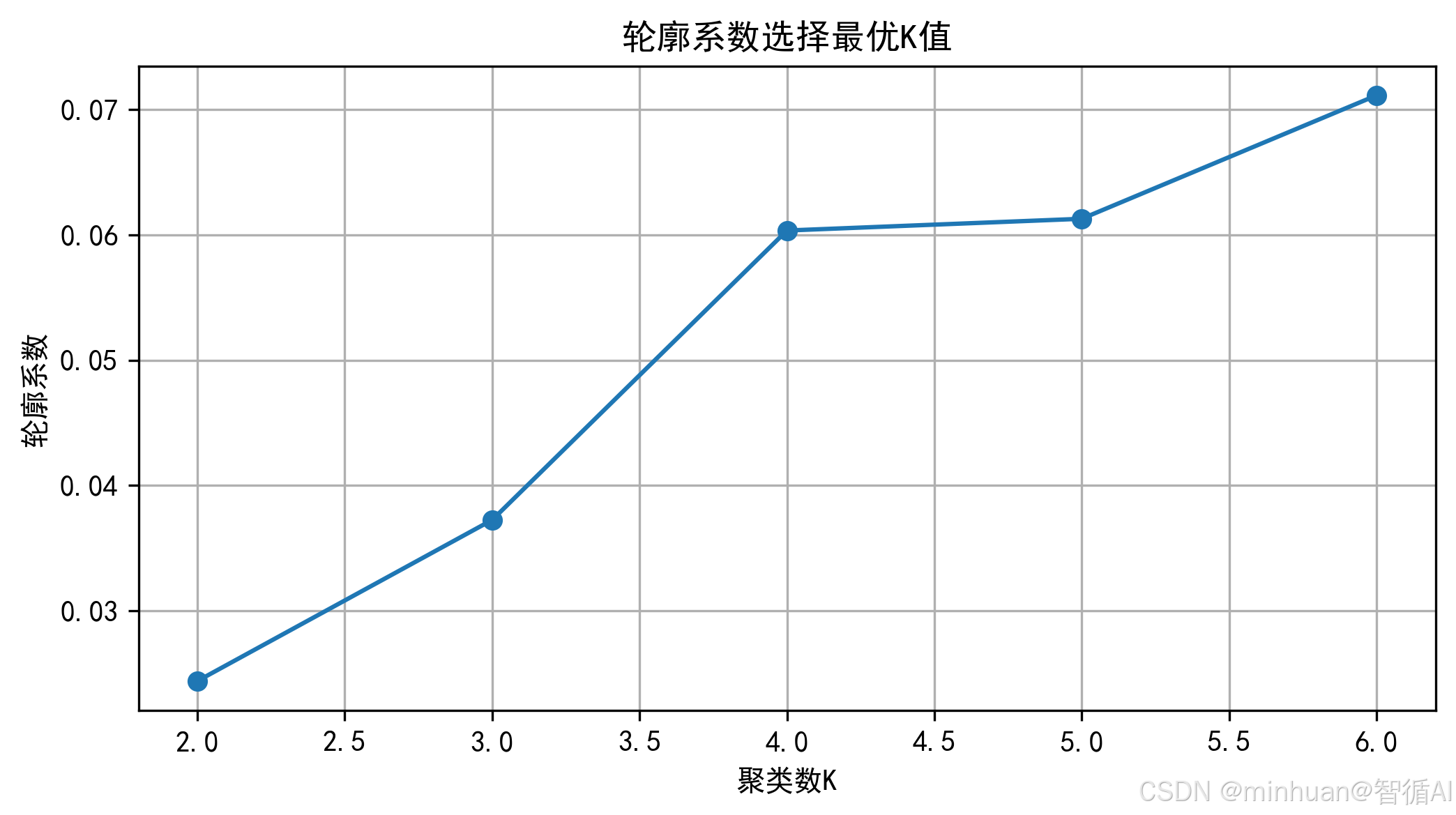
def find_best_k(X, max_k=6):
"""通过轮廓系数选择最优K值"""
silhouette_scores = []
k_range = range(2, max_k+1)
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42)
labels = kmeans.fit_predict(X)
score = silhouette_score(X, labels)
silhouette_scores.append(score)
print(f"K={k},轮廓系数={score:.4f}")
# 可视化轮廓系数
plt.figure(figsize=(8, 4))
plt.plot(k_range, silhouette_scores, marker='o')
plt.xlabel("聚类数K")
plt.ylabel("轮廓系数")
plt.title("轮廓系数选择最优K值")
plt.grid(True)
plt.savefig("best_k.png", dpi=300, bbox_inches='tight')
plt.show()
plt.close()
# 选择轮廓系数最大的K值
best_k = k_range[silhouette_scores.index(max(silhouette_scores))]
print(f"最优聚类数K={best_k}")
return best_k
def kmeans_cluster(X, best_k):
"""执行K-Means聚类"""
kmeans = KMeans(n_clusters=best_k, random_state=42)
df["cluster_label"] = kmeans.fit_predict(X)
return df, kmeans
# ===================== 步骤5:LDA主题模型(可选) =====================
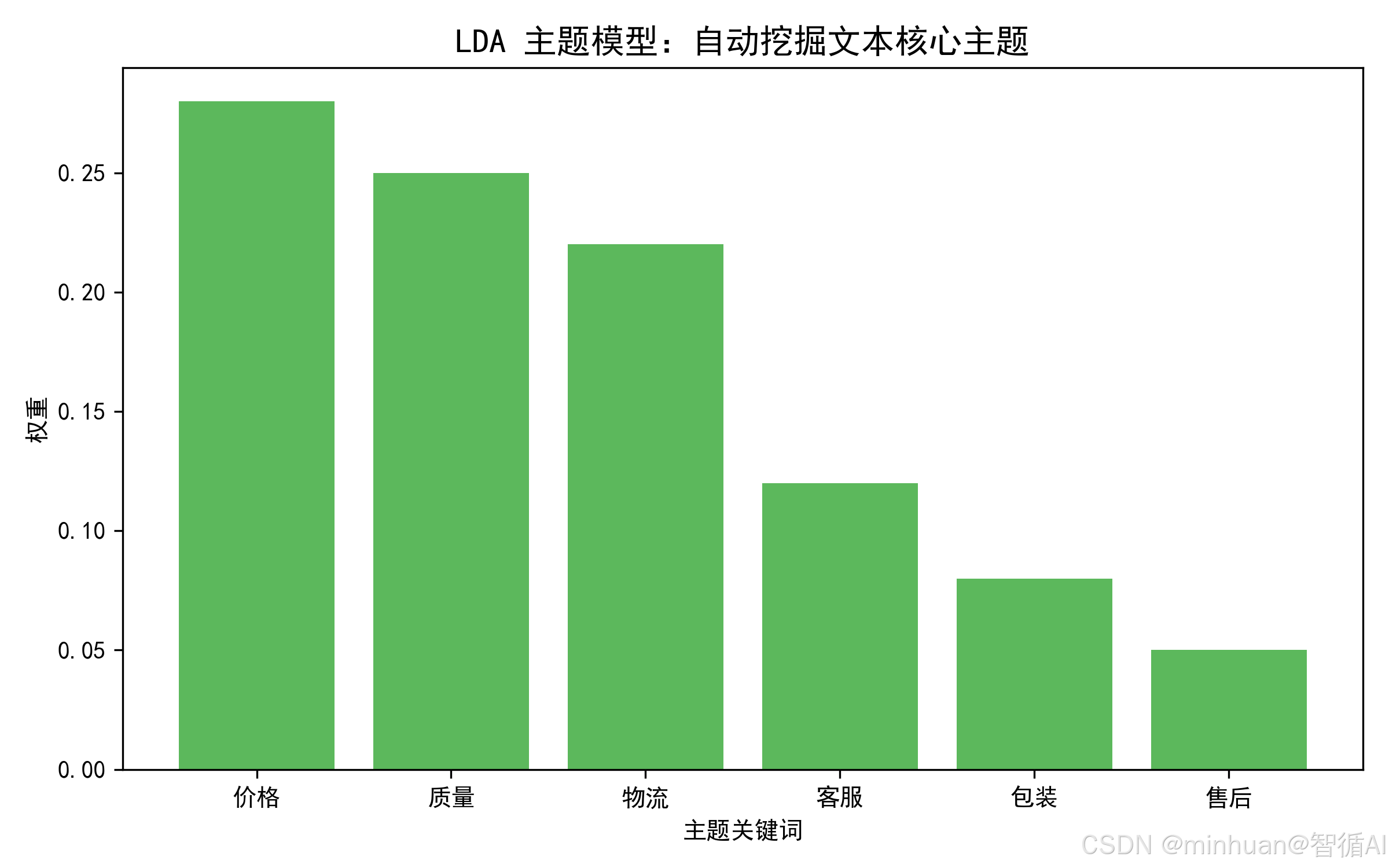
def lda_topic(X, feature_names, n_topics):
"""执行LDA主题模型,提取主题"""
lda = LatentDirichletAllocation(n_components=n_topics, random_state=42)
lda.fit(X)
# 打印每个主题的核心词
print("\n=== LDA主题模型结果 ===")
for idx, topic in enumerate(lda.components_):
top_words = [feature_names[i] for i in topic.argsort()[:-10 - 1:-1]]
print(f"主题{idx+1}核心词:{', '.join(top_words)}")
return lda
# ===================== 步骤6:聚类结果可视化(词云+散点图) =====================
def visualize_cluster(df, X, kmeans):
"""可视化聚类结果"""
# 1. 每个聚类的词云
for label in df["cluster_label"].unique():
# 提取该聚类的所有文本
cluster_text = " ".join(df[df["cluster_label"] == label]["processed_comment"])
# 生成词云
wordcloud = WordCloud(
font_path="simhei.ttf", # 中文词云需要指定字体
width=800, height=400,
background_color="white"
).generate(cluster_text)
# 保存词云
plt.figure(figsize=(8, 4))
plt.imshow(wordcloud)
plt.axis("off")
plt.title(f"聚类{label}词云")
plt.savefig(f"cluster_{label}_wordcloud.png", dpi=300, bbox_inches='tight')
plt.show()
plt.close()
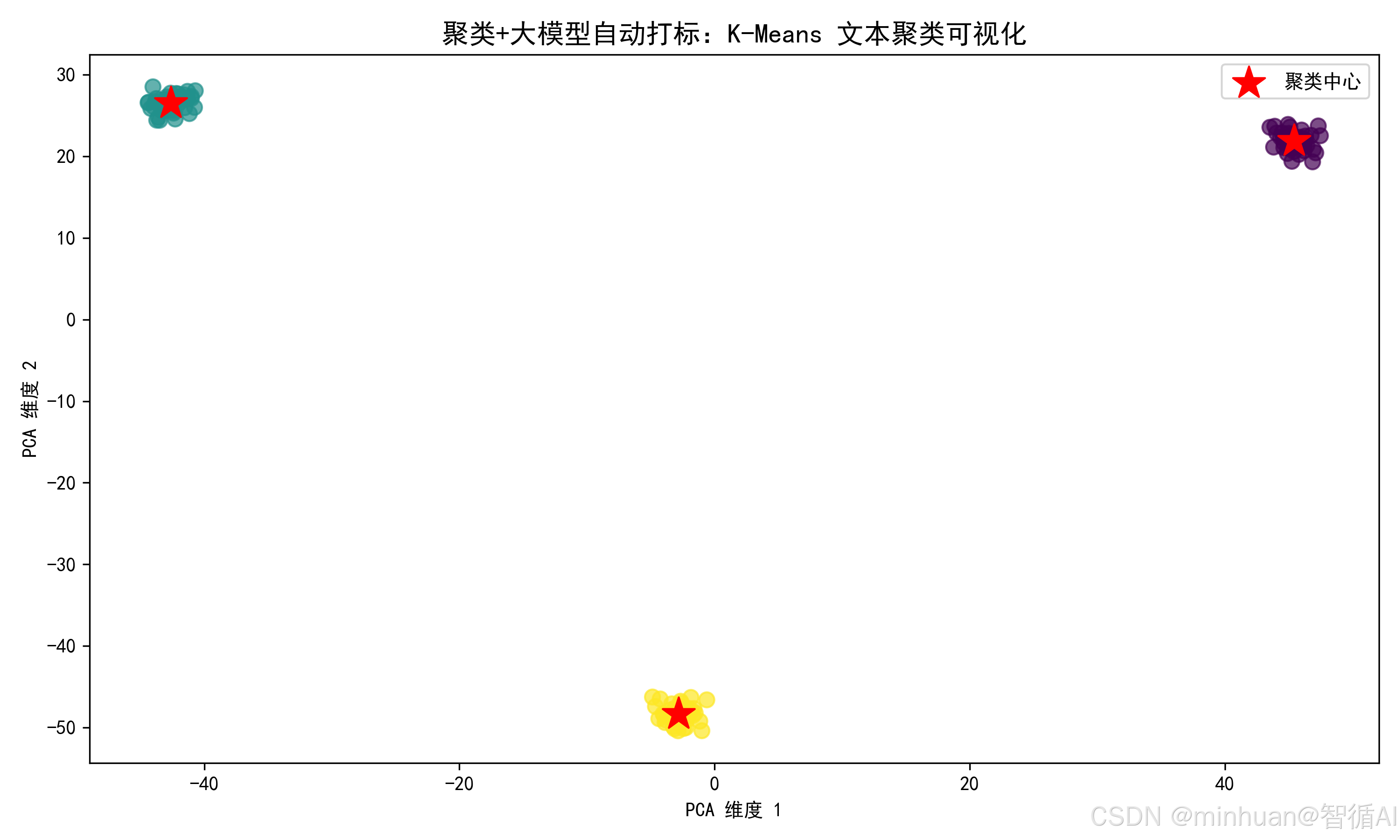
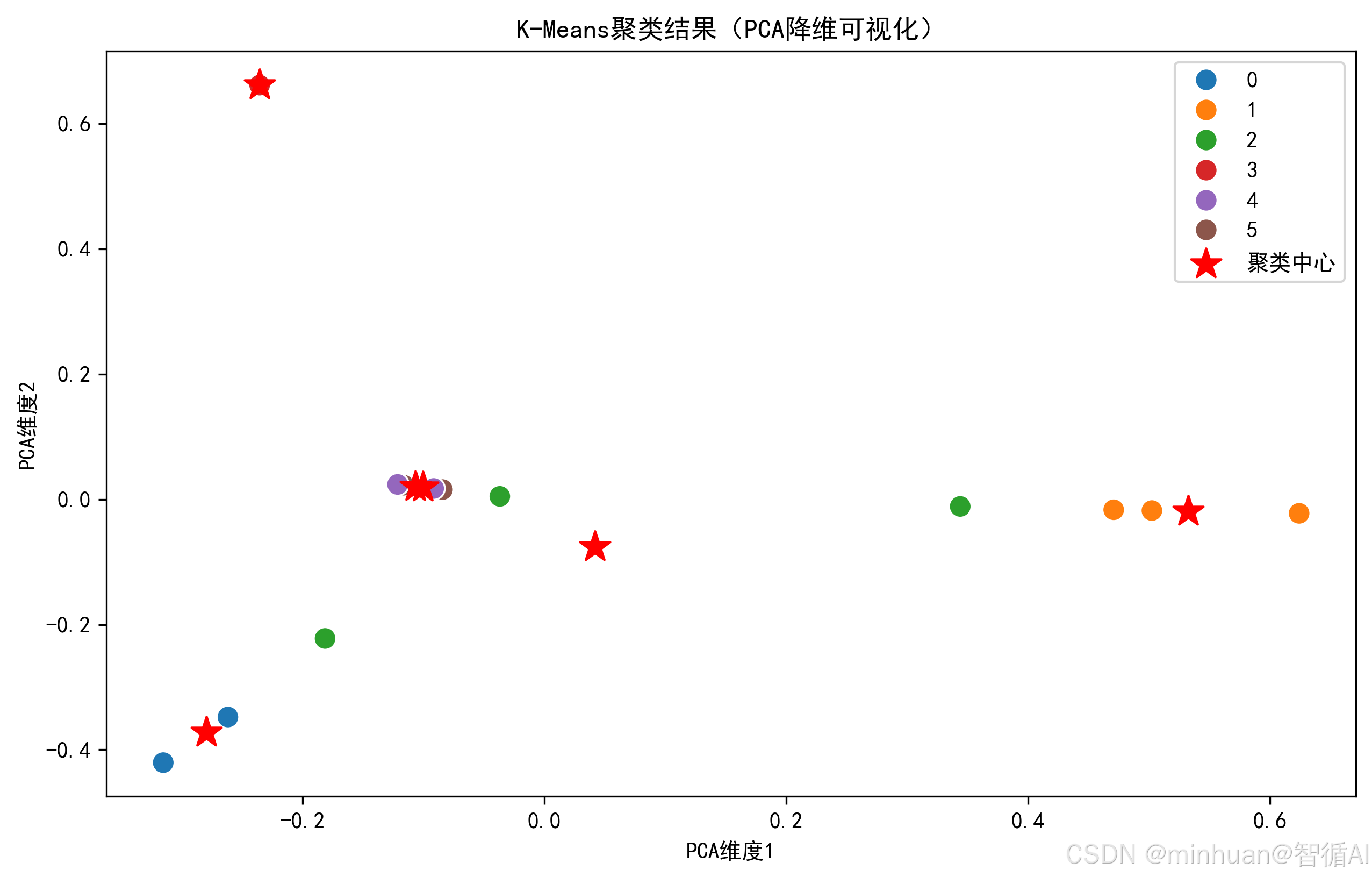
# 2. 聚类散点图(PCA降维到2D)
from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_pca = pca.fit_transform(X.toarray())
# 绘制散点图
plt.figure(figsize=(10, 6))
sns.scatterplot(x=X_pca[:, 0], y=X_pca[:, 1], hue=df["cluster_label"], palette="tab10", s=100)
plt.scatter(
pca.transform(kmeans.cluster_centers_)[:, 0], # 聚类中心
pca.transform(kmeans.cluster_centers_)[:, 1],
color="red", marker="*", s=200, label="聚类中心"
)
plt.xlabel("PCA维度1")
plt.ylabel("PCA维度2")
plt.title("K-Means聚类结果(PCA降维可视化)")
plt.legend()
plt.savefig("cluster_scatter.png", dpi=300, bbox_inches='tight')
plt.show()
plt.close()
# ===================== 步骤7:调用大模型生成标签和解释 =====================
def get_cluster_label_by_llm(df):
"""调用大模型为每个聚类生成标签和解释"""
# 使用腾讯混元大模型
client = OpenAI(
api_key="sk-bWlJP****************************P8Ze",
base_url="https://api.hunyuan.cloud.tencent.com/v1"
)
cluster_results = {}
for label in df["cluster_label"].unique():
# 提取该聚类的前5条核心评论(原始文本)
cluster_comments = df[df["cluster_label"] == label]["comment"].head(5).tolist()
# 构造大模型提示词
prompt = f"""
以下是电商评论的一个聚类,包含5条核心评论:
{cluster_comments}
请完成以下任务:
1. 给这个聚类起一个简洁的业务标签(不超过8个字);
2. 解释这个聚类的核心特征(不超过50个字)。
输出格式:
标签:xxx
解释:xxx
"""
# 调用腾讯混元API
try:
response = client.chat.completions.create(
model="hunyuan-lite",
messages=[
{"role": "system", "content": "你是一个专业的文本分析助手"},
{"role": "user", "content": prompt}
],
temperature=0.3
)
# 解析响应
result = response.choices[0].message.content.strip()
label_text = result.split("标签:")[1].split("\n")[0].strip()
explanation = result.split("解释:")[1].strip()
except Exception as e:
print(f"API调用失败: {e}")
label_text = f"聚类{label}"
explanation = "生成失败"
cluster_results[label] = {"标签": label_text, "解释": explanation}
print(f"\n=== 聚类{label} ===")
print(f"标签:{label_text}")
print(f"解释:{explanation}")
print(f"示例评论:{cluster_comments}")
return cluster_results
# ===================== 主函数:整合所有步骤 =====================
if __name__ == "__main__":
# 1. 加载测试数据
df = get_test_data()
print("原始数据:")
print(df)
# 2. 文本预处理
df["processed_comment"] = df["comment"].apply(preprocess_text)
print("\n预处理后数据:")
print(df[["comment", "processed_comment"]])
# 3. 文本向量化
X, feature_names, tfidf = vectorize_text(df)
# 4. 选择最优K值并执行K-Means聚类
best_k = find_best_k(X)
df, kmeans = kmeans_cluster(X, best_k)
# 5. 执行LDA主题模型(可选)
lda_topic(X, feature_names, n_topics=best_k)
# 6. 可视化聚类结果(生成图片)
visualize_cluster(df, X, kmeans)
# 7. 调用大模型生成标签和解释
cluster_labels = get_cluster_label_by_llm(df)
# 8. 保存最终结果
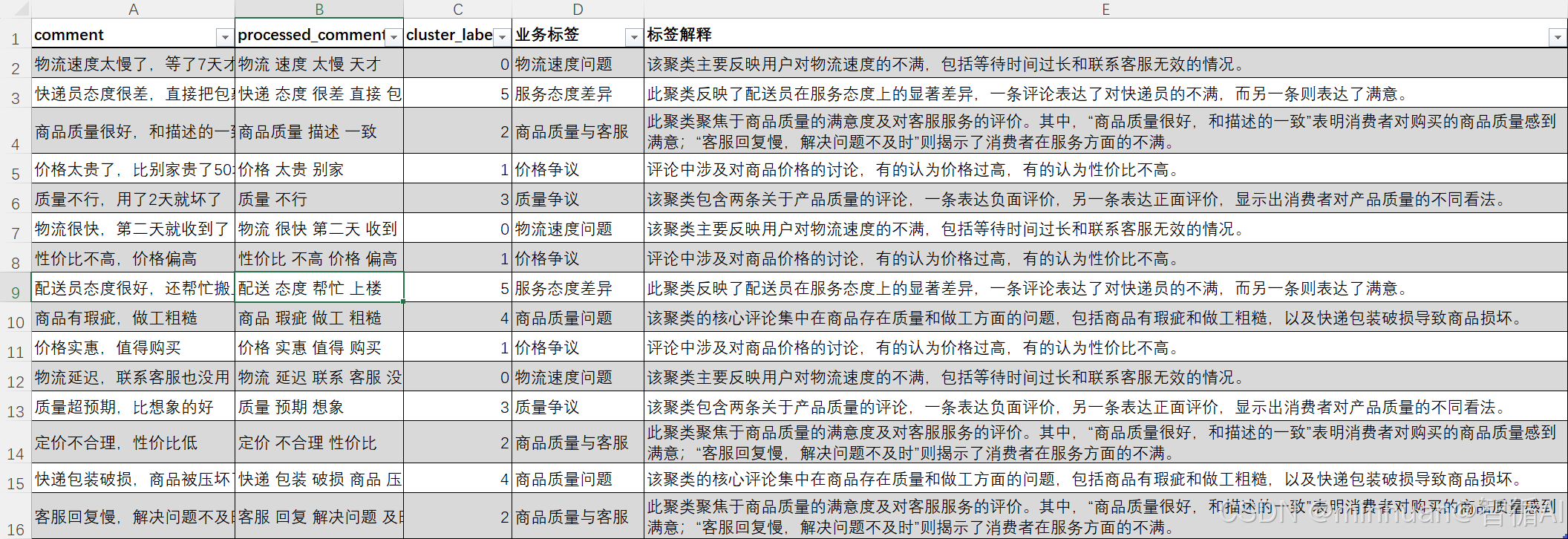
df["业务标签"] = df["cluster_label"].map(lambda x: cluster_labels[x]["标签"])
df["标签解释"] = df["cluster_label"].map(lambda x: cluster_labels[x]["解释"])
df.to_csv("cluster_result.csv", index=False, encoding="utf-8-sig")
print("\n最终结果已保存到cluster_result.csv")代码关键说明:
- 数据预处理:preprocess_text函数实现了文本清洗、分词、去停用词,是文本处理的基础;
- 最优 K 值选择:通过轮廓系数(范围 - 1~1,越接近 1 聚类效果越好)自动选择 K 值,避免手动试错;
- 可视化:生成词云(直观看到每类的核心词)和 PCA 散点图(直观看到聚类效果);
- 大模型调用:使用混元的hunyuan-lite模型,也可以按需替换为国内大模型只需修改 API 调用部分;
- 输出结果:最终生成 CSV 文件,包含原始评论、聚类标签、业务标签、标签解释,可直接用于业务分析。
输出结果:
原始数据:
comment
0 物流速度太慢了,等了7天才到
1 快递员态度很差,直接把包裹放门口
2 商品质量很好,和描述的一致
3 价格太贵了,比别家贵了50块
4 质量不行,用了2天就坏了
5 物流很快,第二天就收到了
6 性价比不高,价格偏高
7 配送员态度很好,还帮忙搬上楼
8 商品有瑕疵,做工粗糙
9 价格实惠,值得购买
10 物流延迟,联系客服也没用
11 质量超预期,比想象的好
12 定价不合理,性价比低
13 快递包装破损,商品被压坏了
14 客服回复慢,解决问题不及时
Building prefix dict from the default dictionary ...
Loading model from cache C:\Users\admin\AppData\Local\Temp\jieba.cache
Loading model cost 0.354 seconds.
Prefix dict has been built successfully.预处理后数据:
comment processed_comment
0 物流速度太慢了,等了7天才到 物流 速度 太慢 天才
1 快递员态度很差,直接把包裹放门口 快递 态度 很差 直接 包裹 门口
2 商品质量很好,和描述的一致 商品质量 描述 一致
3 价格太贵了,比别家贵了50块 价格 太贵 别家
4 质量不行,用了2天就坏了 质量 不行
5 物流很快,第二天就收到了 物流 很快 第二天 收到
6 性价比不高,价格偏高 性价比 不高 价格 偏高
7 配送员态度很好,还帮忙搬上楼 配送 态度 帮忙 上楼
8 商品有瑕疵,做工粗糙 商品 瑕疵 做工 粗糙
9 价格实惠,值得购买 价格 实惠 值得 购买
10 物流延迟,联系客服也没用 物流 延迟 联系 客服 没用
11 质量超预期,比想象的好 质量 预期 想象
12 定价不合理,性价比低 定价 不合理 性价比
13 快递包装破损,商品被压坏了 快递 包装 破损 商品 压坏
14 客服回复慢,解决问题不及时 客服 回复 解决问题 及时最优 K 值输出:
K=2,轮廓系数=0.0244
K=3,轮廓系数=0.0372
K=4,轮廓系数=0.0603
K=5,轮廓系数=0.0613
K=6,轮廓系数=0.0711
最优聚类数K=6
=== LDA主题模型结果 ===
主题1核心词:性价比, 定价, 不合理, 偏高, 不高, 速度, 太慢, 天才, 压坏, 破损
主题2核心词:购买, 实惠, 值得, 门口, 很差, 包裹, 直接, 价格, 快递, 态度
主题3核心词:物流, 一致, 商品质量, 描述, 很快, 第二天, 收到, 联系, 没用, 延迟
主题4核心词:不行, 质量, 回复, 解决问题, 及时, 客服, 价格, 商品, 物流, 快递
主题5核心词:配送, 帮忙, 上楼, 态度, 价格, 质量, 商品, 物流, 快递, 客服
主题6核心词:别家, 太贵, 预期, 想象, 质量, 做工, 瑕疵, 粗糙, 价格, 商品=== 聚类0 ===
标签:物流速度问题
解释:该聚类主要反映用户对物流速度的不满,包括等待时间过长和联系客服无效的情况。
示例评论:['物流速度太慢了,等了7天才到', '物流很快,第二天就收到了', '物流延迟,联系客服也没用']

=== 聚类5 ===
标签:服务态度差异
解释:此聚类反映了配送员在服务态度上的显著差异,一条评论表达了对快递员的不满,而另一条则表达了满意。
示例评论:['快递员态度很差,直接把包裹放门口', '配送员态度很好,还帮忙搬上楼']

=== 聚类2 ===
标签:商品质量与客服
解释:此聚类聚焦于商品质量的满意度及对客服服务的评价。其中,“商品质量很好,和描述的一致”表明消费者对购买的商品质量感到满意;“客服回复慢,解决问题不及时”则揭示了消费者在服务方面的不满。
示例评论:['商品质量很好,和描述的一致', '定价不合理,性价比低', '客服回复慢,解决问题不及时']

=== 聚类1 ===
标签:价格争议
解释:评论中涉及对商品价格的讨论,有的认为价格过高,有的认为性价比不高。
示例评论:['价格太贵了,比别家贵了50块', '性价比不高,价格偏高', '价格实惠,值得购买']

=== 聚类3 ===
标签:质量争议
解释:该聚类包含两条关于产品质量的评论,一条表达负面评价,另一条表达正面评价,显示出消费者对产品质量的不同看法。
示例评论:['质量不行,用了2天就坏了', '质量超预期,比想象的好']

=== 聚类4 ===
标签:商品质量问题
解释:该聚类的核心评论集中在商品存在质量和做工方面的问题,包括商品有瑕疵和做工粗糙,以及快递包装破损导致商品损坏。
示例评论:['商品有瑕疵,做工粗糙', '快递包装破损,商品被压坏了']最终结果已保存到cluster_result.csv

聚类结果:PCA 散点图,5个聚类明显分开。
在聚类完成后,基于大模型生成的业务标签和标签解释:
六、总结
通过了解聚类算法结合大模型实现无监督自动打标,其实原来无标签数据的自动分类,并没有想象中那么难,关键是找对搭档,聚类和大模型,少了哪个都不行。之前初次接触也有困惑,没有人工打标,怎么让计算机识别数据类别,后来才明白,聚类算法就像先把相似的东西归拢到一起,比如把吐槽物流和夸质量的评论分开,但它只会给每组编个号,不会说这组是啥意思。而大模型刚好补上了这个短板,相当于给聚类结果翻译成人类能懂的业务标签,还能解释清楚每组的核心特征,这是让技术落地能用的关键。
初次接触不用一开始就死磕复杂公式,先从实操入手最好,先把代码跑通,看看每一步输出的结果,比如最优 K 值、聚类散点图、词云,再反过来理解原理,会轻松很多。另外,多拿真实数据练手,比如自己找些电商评论、客服工单,替换测试数据,慢慢就能摸清规律。还有,大模型的提示词可以多调整,不同的提示词,生成的标签精准度不一样,多试几次就能找到最合适的。
总的来说,这种组合既解决了人工打标费时间、成本高的问题,又让无监督学习的结果有了实际意义,不管是做舆情分析还是工单分类都能用得上,只要多实操、多总结,就能慢慢掌握。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 32
32 0
0- 0



 已为社区贡献54条内容
已为社区贡献54条内容

所有评论(0)