【大模型】微调相关记录
微调相关理论知识
聊聊相关理解
什么时候适合微调
1、满足个人独特需求(电子女友)
2、不能公开的私域数据(电影剧组)
3、你希望对其完全负责(医疗顾问)
微调可以做到什么
1、拓展领域知识
2、客制化AI行为(语气、风格、个性)
3、优化特定任务的准确性(医疗、法律)
微调与RAG
工作原理
微调
知识和模型是一体的。
根据上述特性描述,使得获得以下特性:
1、工程更健壮
2、相应速度更快
3、又训练成本
RAG
知识和系统是独立的
根据上述描述,会有以下特性:
1、知识独立更新,更容易进行知识更新
2、会有更多的消耗
适用场景、典型应用
微调
适用场景
1、封闭域
2、知识固定
3、精确度高
4、数据量相对小
典型应用
让法律更智能、通义法睿、华佗GPT II
RAG
适用场景
1、开放域
2、知识动态
3、灵活性强
4、动态更新
典型应用
实时新闻分析、产品说明书查询、商品推荐系统
微调RAG混合增强架构
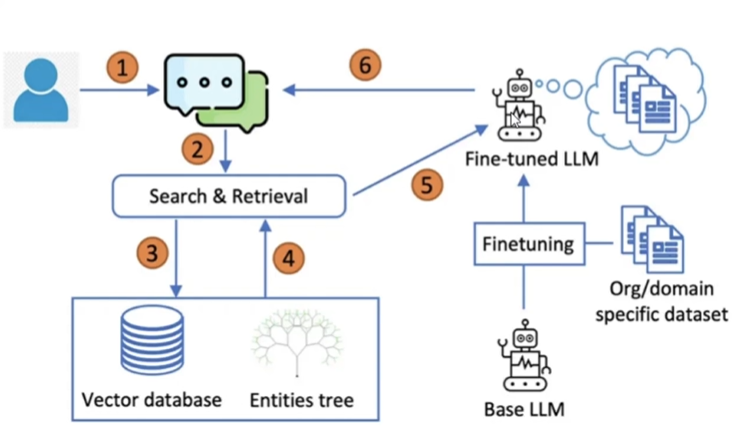
微调的前置工作
选择基座模型
如何选择基座模型
1、确定任务类型(视觉类【Llama3.2Vision、Qwen2.5VL、Deepseek-VL2】、编码类【Qwen Coder 2.5、Deep Seek Code、Code Llama】、医疗类【华佗GPT II、Bio-Medical-Llama-3】)
2、基础模型(base)还是调优模型(instruct)
| 数据量 | 推荐模型 | 核心优势 |
|---|---|---|
| 大于1000行 | 基础模型 | 充分利用数据深度定制 |
| 大于300小于1000高质量 | 基础模型或调优模型 | 保留通用能力->调优特定领域适配->基础 |
| 小于300行 | 调优模型 | 保留通用能力快速适配小规模数据 |
数据质量比数据数量更重要
-
Llama系
1、开源标杆,不可能不被支持,兜底选择
2、全系多语言支持
3、1B,3B,8B,11B,70B,90B,405B
4、训练数据最大(15T)
5、擅长写代码 -
Qwen系
1、最爱中文
2、最强多语言支持(119种)
3、0.5B,1B,3B,7B,14B,32B,72B
4、擅长写代码 -
Phi-3 Phi系
1、会说中文,但爱说英文
2、训练数据10T,英文为主
3、曾经最强“小模型”。现在不太行
4、3.8B,7B,14B
5、Phi-4 14B -
Mistral系
1、爱说欧洲语言,法语、西班牙语等(会中文)
2、学习了很多医疗、法律知识
3、3B,8B,14B,32B、,72B -
Gemini3
1、频繁更新(小步子不断,半年一大更)
2、支持140种语言(4B,12B,27B)
3、1B,4B,12B,27B
4、最长上下文支持(128B)
数据准备
数据获取->数据清洗->质量控制->数据格式化和标准化->数据扩增
数据获取
- 甲方提供
- 生产数据
- 网络提取
- 公开数据集
https://huggingface.co/datasets
https://www.kaggle.com/datasets
https://archive.ics.uci.edu/datasets
https://registry.opendata.aws/https://www.modelscope.cn/datasets
数据清洗
- 脱敏
- 去除HTML标签、URL、特殊字符
- 去除广告、垃圾信息等无关内容iv.删除重复内容
- 确保内容的逻辑性合理性
质量控制
- 人工抽样
- 统计分析
- 小规模测试
数据格式化
- 原始数据
- 指令数据
- 对话数据
- 人类反馈数据
| 数据类型 | 训练类型 | 训练效果 | 典型应用 |
|---|---|---|---|
| 原始数据 | 继续预训练(CPT) | 增加基座模型知识范围 | - |
| 指令数据 | 监督微调(SFT) | 学习具体任务 | 翻译、摘要 |
| 对话数据 | 监督微调(SFT) | 掌握多轮对话逻辑 | 客服、智能助手 |
| 人类反馈数据(RLHF) | 强化学习(RL) | 优化回复质量 | - |
合成数据生成
- 从已有模版扩增数据
- 多样化数据,避免过拟合
- 增强数据,补充细节
如何合成数据?
i. 选择高质量数据作为种子数据集
ii. 设计提示模版
iii. 生成合成数据,查看效果——调整温度(越高越有创意)参数修改提示模版提升种子数据
iv. 清洗验证数据
合成数据注意事项
i. 可以用本地或在线模型生成
ii. 生成模型越大质量越好,通常大于70B
iii. 合成数据需要重新清洗和质量控制
一些数据相关问题
- 微调需要准备多大的数据集?
至少100条,1000条以上更优注意:训练结果高度依赖数据质量,注意清洗,不能凑数质量不够时,可以用合成数据提升质量 - 推理模型如何准备数据集?
基座是推理模型时,答案中需要包含推理过程
基座不是推理模型时,答案中不要包含推理过程’后期通过强化学习增加推理能力 - 我有多个数据集可以多次微调吗?
最好不要。
多次微调可能覆盖之前训练的模型知识,导致性能下降增量微调时,数据集更新时,删除数据会很麻烦建议将数据集合并成一个,一次完成微调
微调训练框架
- pytorch
特点
1.使用命令行执行
2.内置多种微调「配方」(包括全量、LoRA、QloRA)
3.使用配置文件更改微调参数
4.集成Hugging Face 模型和数据集
5.原生pyTorch实现 - Hugging Face Transformers
特点
1.集成 Hugging Face 模型和数据集
2.使用简单的Trainer API
3.支持PEFT
4.内置了一些大模型 - Unsloth
特点
1.是基于pyTorch的优化框架
2.显存占用显著优化(~60%)
3.支持PEFT
4.支持的基座模型丰富
5.有收费版本

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献3条内容
已为社区贡献3条内容

所有评论(0)