AIAgent应用开发——大模型理论基础与应用(二)
本文系统介绍了大语言模型的训练过程与技术要点。训练分为三个阶段:预训练阶段通过自监督学习构建语言知识库;监督微调阶段让模型掌握具体任务;强化学习阶段通过人类反馈优化模型行为。关键技术包括数据预处理、Transformer架构设计、分布式训练等。文章还分析了模型存在的理解缺失、知识时效性等局限,并展望了多模态、持续学习等发展方向。全文从技术实现到应用挑战,全面剖析了大语言模型的训练机理与演进趋势。
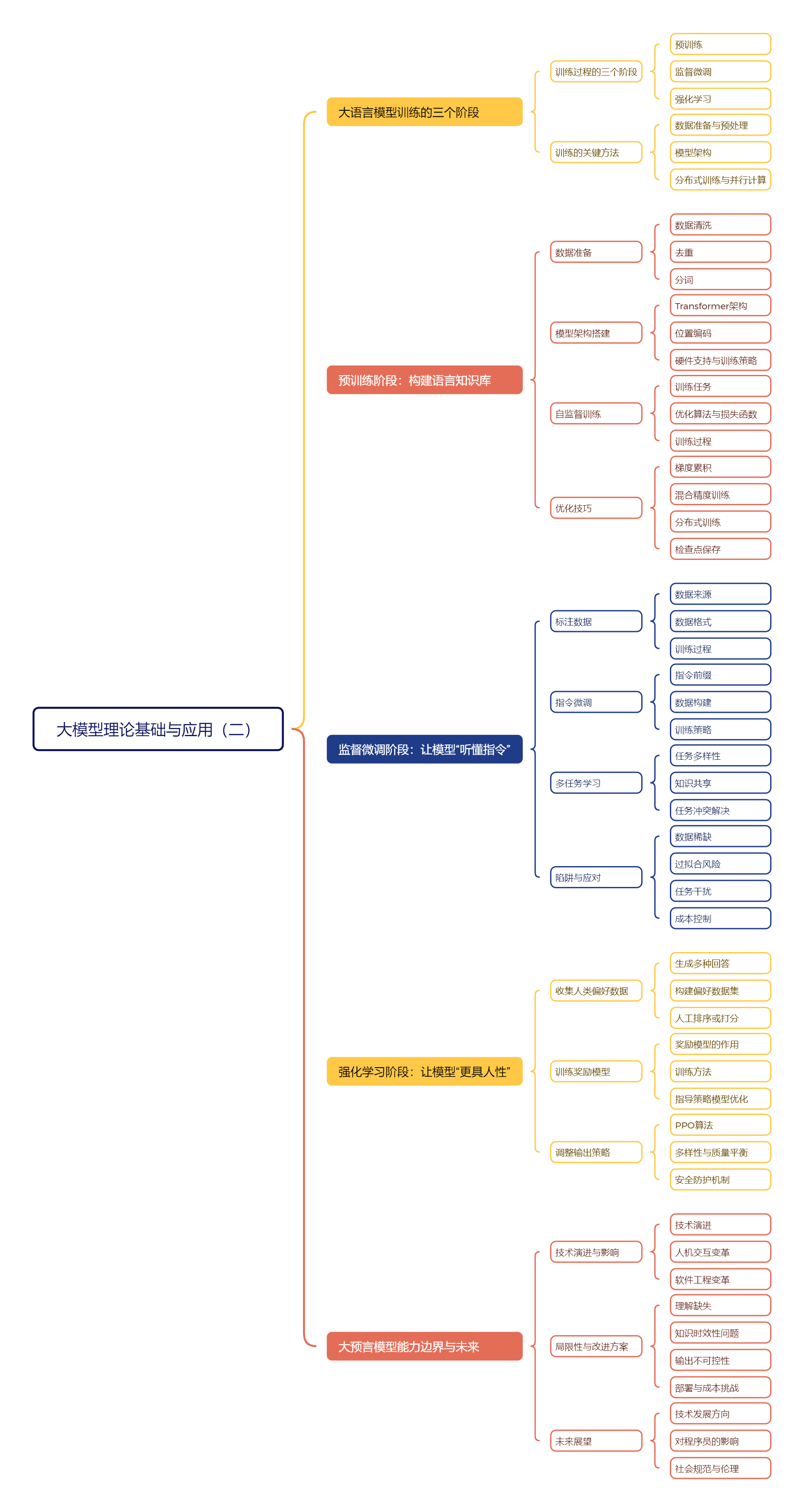
一、大语言模型训练的三个阶段
1、训练过程的三个阶段
【预训练】预训练是模型从头开始“自学语言”,通过无监督方式吸收语言知识,为后续训练打下基础。
【监督微调】监督微调让模型接受“技能训练”掌握具体任务如问答、翻译等,提升其在特定领域的应用能力。
【强化学习】强化学习通过人类反馈进一步微调模型行为,使其更符合人类用户喜好与社会规范,提升交互自然度。
2、训练的关键方法
【数据准备与预处理】数据是模型训练的基础,需经过清洗、去重、分词、数据增强和伦理审查等步骤,确保数据质量与多样性。
【模型架构】设计Transformer?架构是目前最常用的模型架构,其自注意力机制使模型能聚焦关键部分,理解语义结构。
【分布式训练与并行计算】大模型训练需多张GPU协同工作,采用模型并行、数据并行等策略,提高训练效率。
二、预训练阶段:构建语言知识库
1、数据准备
【数据清洗】去除无用内容、过滤低质量文本,确保数据的纯净性。
【去重】删除重复或高度相似的内容,让模型学习更多不同表达方式。
【分词】将句子拆分成小单位,方便模型理解和处理,词表大小需根据任务动态调整。
英文分词==》BPE分词;中文分词:WordPiece jiebaI;
词表:包含了模型能够识别的所有基本单元(token)
2、模型架构搭建
【Transformer架构】由多个Transformer层堆叠而成,自注意力机制是其核心,能建立词语间远距离联系。
【位置编码】位置编码帮助模型理解序列信息,有静态正余弦位置编码和可学习位置嵌入两种方式。
【硬件支持与训练策略】不同规模模型对硬件要求不同,训川练时需采用科学的参数初始化方法和学习率预热衰减等技巧。
3、自监督训练
【训练任务】常见任务有掩码语言建模和自回归语言建模,通过这些任务模型能自动发现语言规律。
【优化算法与损失函数】使用Adam优化算法和交叉熵损失函数,训练过程中需防止过拟合,提升模型泛化能力。
【训练过程】模型通过不断调整参数,逐步提升对语言的理解和生成能力,为后续阶段提供支撑。
4、优化技巧
【梯度累积】解决显存容量限制问题,先计算梯度再统一更新参数。
【混合精度训练】结合不同精度数据格式,加快训练速度并减少显存占用。
【分布式训练】包括数据并行、模型并行、流水线并行和张量并行等策略,提高训练效率。
【检查点保存】定期保存模型状态,防止训练中断后需从头开始。
三、监督微调阶段:让模型“听懂指令”
1、标注数据
【数据来源】来自开源数据集、众包平台、企业内部标注团队等,确保数据质量高。
【数据格式】通常为输入-输出对,如问答对、翻译对、对话样本等,帮助模型学习特定任务。
【训练过程】通过监督学习最小化模型输出与正确答案之间的差距,提升模型在具体任务上的表现。
2、指令微调
【指令前缀】在训练数据中加入指令前缀,引导模型明确任务目标,提升交互可控性和可解释性。
【数据构建】通过人工标注、开放数据集自动生成数据等方式构建指令响应对,确保数据质量。
【训练策略】采用提示填充、多任务指令微调等技术,提升模型在多样化任务中的执行能力。
3、多任务学习
任务多样性==》让模型同时学习多种任务,如问答、翻译、写作等,提升其迁移能力。
知识共享==》模型在学习过程中共享底层特征表示,利用共通知识提升各任务表现。
任务冲突解决==》通过技巧调整模型在不同任务间的表现,确保兼顾各任务要求。
4、陷阱与应对
【数据稀缺】采用跨领域迁移学习、自监督学习和弱监督学习等技术,解决专业领域数据不足问题。
【过拟合风险】引入数据多样性、采用早停法等策略,防止模型在训练集上过度拟合。
【任务干扰】通过多任务学习,平衡不同任务间的关系,避免模型“顾此失彼”。
【成本控制】采用精细化模型压缩技术,降低计算和存储成本。
四、强化学习阶段:让模型“更具人性”
1、收集人类偏好数据
【生成多种回答】让模型针对同一条输入指令输出多个风格各异的回答。
【构建偏好数据集】将评审结果汇总,形成包含“输入指令+多个回答+人类排序或打分”的偏好样本。
【人工排序或打分】由人类评审员对回答进行比较、排序或打分,综合考虑多个因素。
2、训练奖励模型
【奖励模型的作用】奖励模型对大模型的输出结果进行打分,评价其是否符合人类偏好。
【训练方法】常用“两两排序”方法,让模型学会在两个回答之间分辨优劣。
【指导策略模型优化】策略模型根据奖励模型的评分反馈不断优化,生成更符合人类偏好的回答。
3、调整输出策略
【PPO算法】使用PPO算法让大模型的输出结果获得更高奖励分数,同时避免过度优化。
【多样性与质量平衡】引入温度调节机制,控制大模型输出的随机性,提升生成结果的丰富性。
【安全防护机制】加入安全防护机制,如负向奖励、内容过滤、价值观嵌入等,确保输出结果安全无害。
五、大预言模型能力边界与未来
1、技术演进与影响
【技术演进】大语言模型的发展体现了工程、算法、数据与计算力的集体突破。
【人机交互变革】改变了人机交互方式,用户可直接用自然语言表达意图,提升用户体验。
【软件工程变革】重塑软件工程开发流程,程序员可借助A辅助工具提高开发效率。
2、局限性与改进方案
【理解缺失】模型基于语料模式进行预测,并非真正“理解”语言,在复杂场景下可能出错。
【知识时效性问题】模型知识基于训练时的数据快照,无法自动更新,需通过检索增强或微调补充。
【输出不可控性】输出具有随机性,可能生成不当内容,需引入约束机制避免滥用风险。
【部署与成本挑战】推理需大量算力支持,限制了其在边缘设备或实时系统中的应用。
3、未来展望
【技术发展方向】支持多语言、多模态输入输出,实现持续学习和知识更新,构建更可控、可信、安全的AI架构。
【对程序员的影响】掌握AI模型原理与应用成为未来技术人员的核心竞争力,需理解其机制并融入业务场景。
【社会规范与伦理】重视模型在伦理和社会层面的影响,确保技术造福人类,推动其在关键领域安全落地。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 7
7 0
0- 0



 已为社区贡献11条内容
已为社区贡献11条内容

所有评论(0)