AI | 论文-前端代码生成 | UI2Code:A Visual Language Model Test-time Scalable Interactive UI-to-Code Gen 25.11
高级 UI 编码能力的9B参数 的 VLM交互式UI 到 代码生成的范式。
UI2Code:A Visual Language Model Test-time Scalable Interactive UI-to-Code Generation
UI2代码:一种用于测试时可扩展交互式 UI 到代码生成的可视化语言模型
论文链接 代码仓库 在线阅读论文 模型地址 模型,基于GLM-4.1V-9B-Base

摘要:
结论
高级 UI 编码能力的 9B参数 的 VLM
交互式UI 到 代码生成的范式



主要贡献:
- 提出新范式,交互式 UI 到代码
- 集成 UI2Code
- 提出 基础编码虚拟学习模型(VLM)的训练方案,预训练、微调、强化学习,并采用新的奖励机制。


结果:
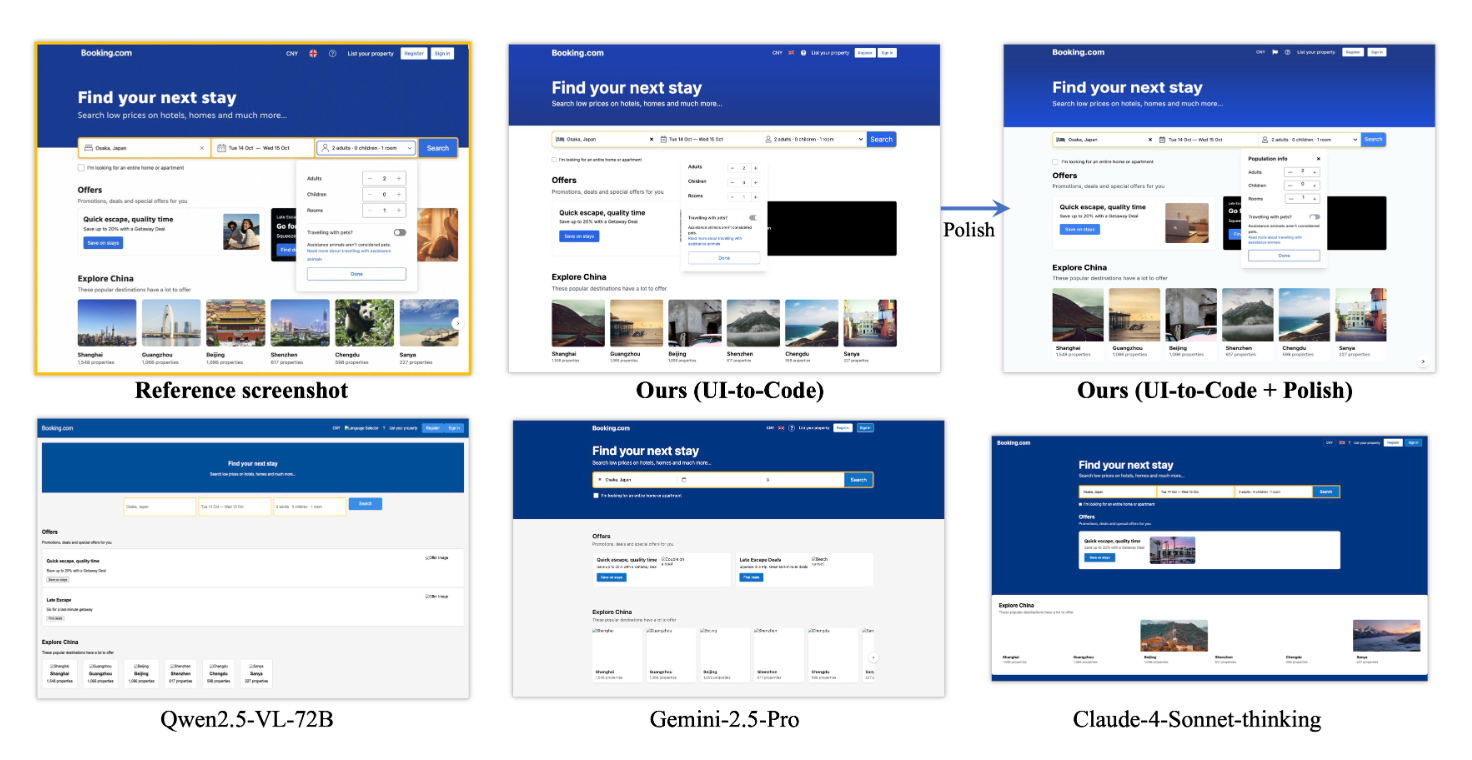
问题:





二、文献综述/相关工作
1. 基准测试:
- Design2Code:真实网页构建
- Web2Code:改善管道,但依赖LLM合成的HTML
- WebGen-Bench:涵盖功能网站生成,自动化代理
2. 数据集:
WebSight
Web2Code
WebCode2M
CommonCrawl


三、方法
1. 新范式的提出: 交互式 UI 到代码生成
①UI 到代码 ②UI 优化 ③ 用户界面编辑
特点:重新定义为 一个 迭代的交互式过程
范式的组成部分:① UI→代码;②三个输入(ui图像、初始代码、渲染输出) 优化 草稿代码,反复迭代;③界面修改,用户驱动



2. 多阶段训练
挑战:UI风格、数据问题


三阶段训练:预训练,SFT,RL
真实网页进行预训练,清理后的数据集上 微调,并添加功能,强化学习让其适应复杂真实世界分布。
预训练&数据集的获取:
用URL作为种子进行爬取,标签白名单筛选和冗余去除,将 UI块与 DOM 元素对齐 并控制序列长度。。




深度推理格式的 监督微调 SFT 阶段:
模型输出结构:`<think>{think_content}</think><answer>{answer_content}</answer>`
采用先进的 LLM【1】生成多样化、复杂且结构良好的单页 HTML 文件作为答案,并 反向构建查询,来验证正确性。
鲁棒性,特定任务的数据构建策略,用 多个虚拟线性模型(VLM)(我们的模型、GLM-4.5V 和 Claude-4-Sonnet)来多样化渲染 输入,通过VLM的结果来推到推理轨迹。
界面编辑,通过启发式规则+人工检查 来筛选候选对象。
逆向高质量删除对 → 组件添加的难题。
共构建了 8w 的样本


强化学习
RL优点:优化视觉相似度,接近人类判断;用截图训练,避免噪声。
做法:用 GRPO 共同训练
奖励设计:采用 GLM-4.5V 做验证工具
难点:界面优化量化问题
解决方法:基线验证评分;比较函数comp_score,联合评估值;循环比较法。





四、实验
实验结果:
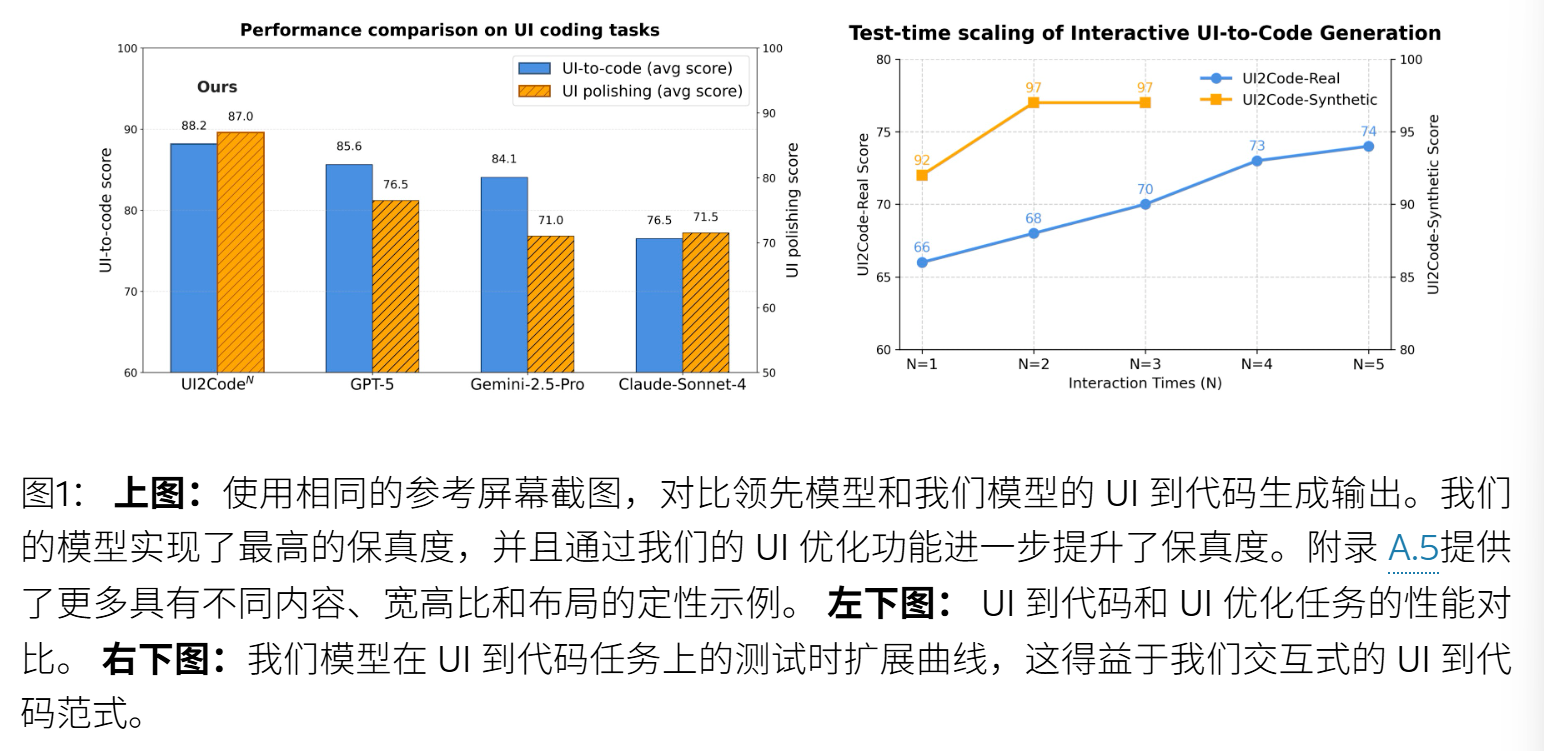
评估设置:1. 基准测试、2. 评估指标:
1. 基准测试:构建了UI2Code-Real基准测试,含115 个真实网页
UI优化:构建了 UIPolish-bench基准测试(含100个合成网页+100个真实网页)
具体见 附录 A.4
2. 评估方法: CLIP 的相似性→语义对齐
VLM评分,保真度&可用性
奖励优先级:VLM > CLIP
UI 优化的方法:



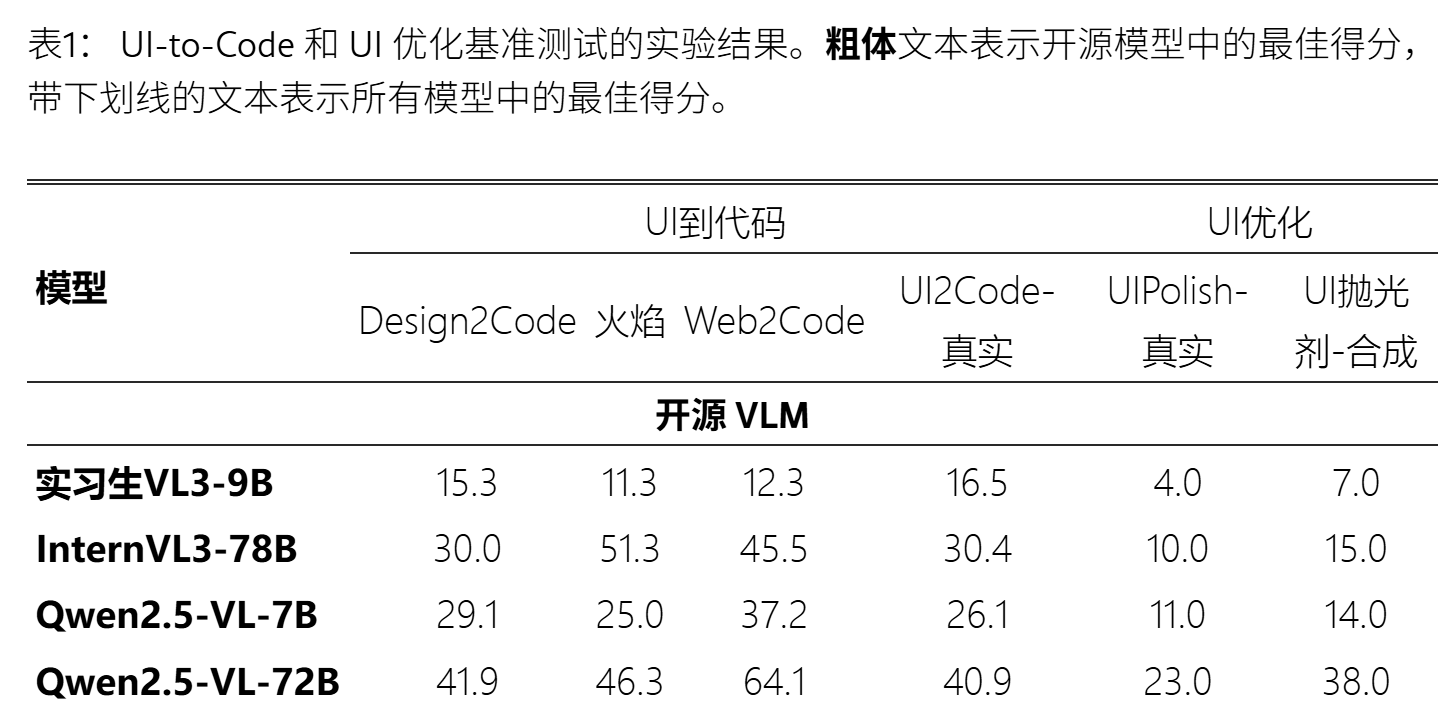
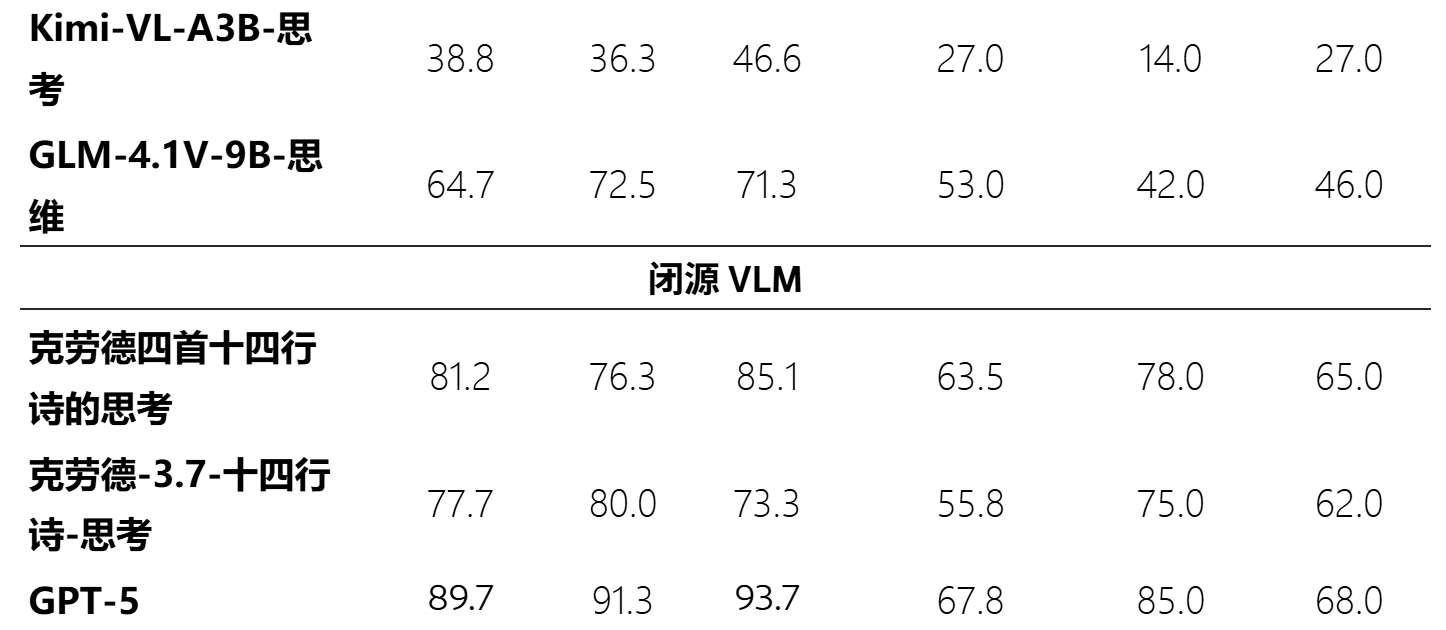
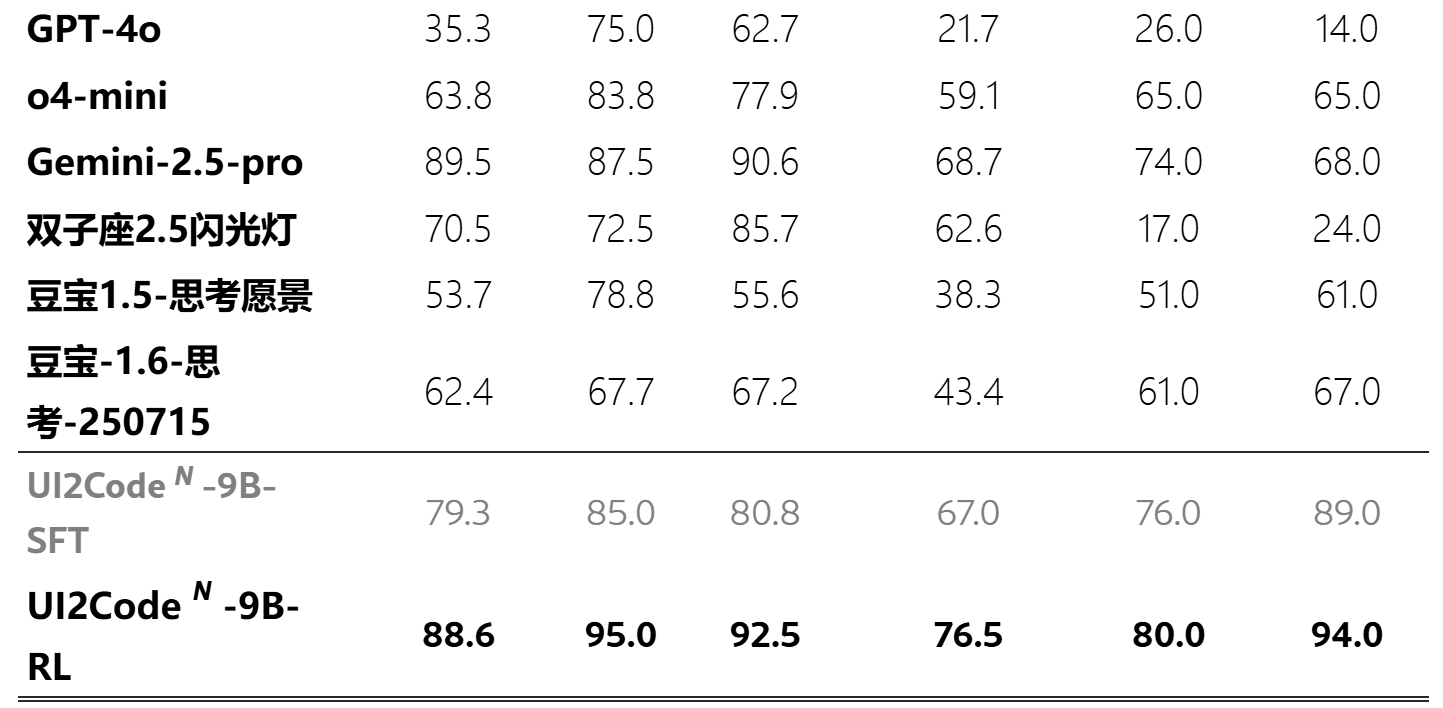
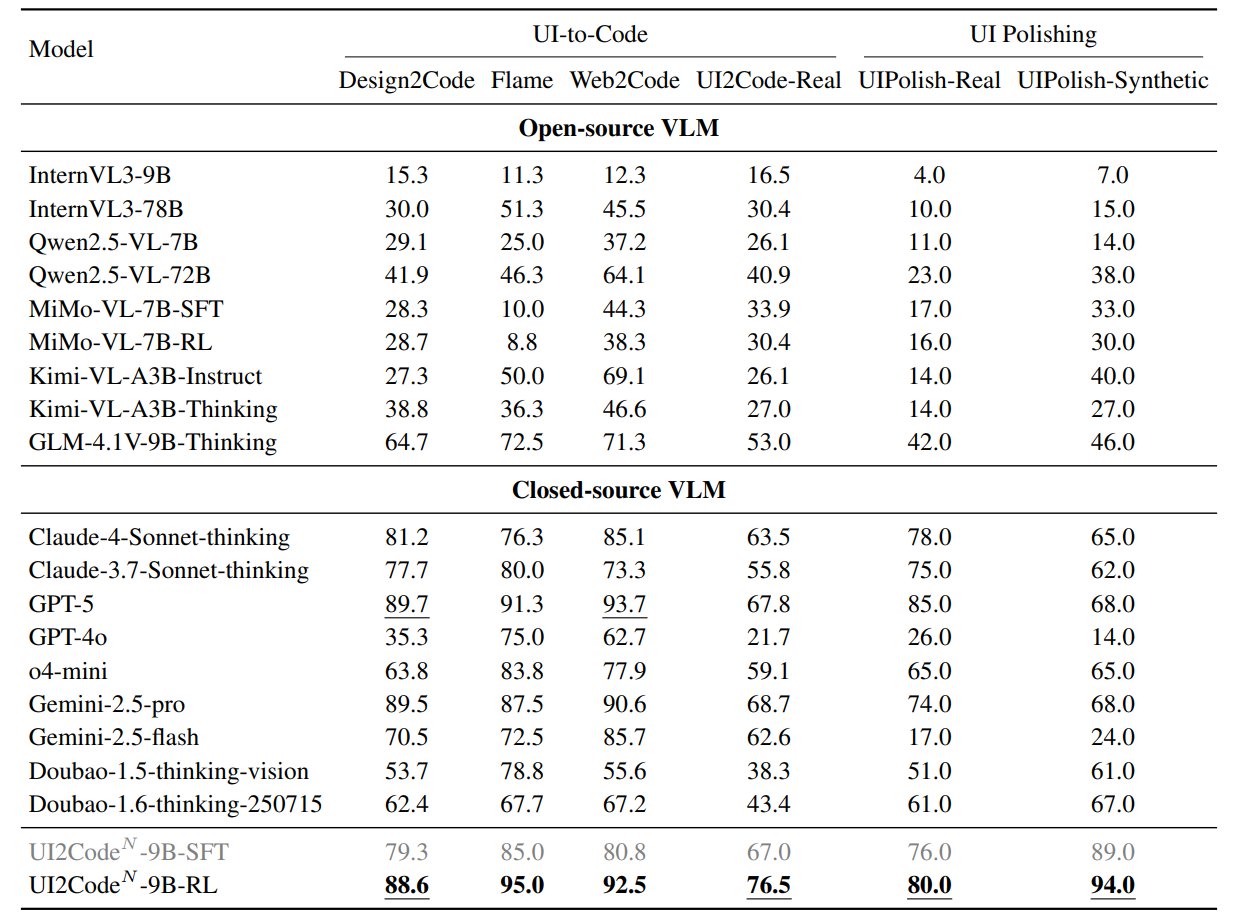
主要结果:见表一
实验(两种UI编码):UI-Code生成、UI优化
UI2Code-9B-SFT 和 UI2Code-9B-RL
公开基准测试:Design2Code、Flame 和 Web2Code
真实世界基准测试: UI2Code-Real
结果:开源 VLM, 在 UI 优化方面的性能 不好。
本文的RL模型,真实网页测试中 达到80%;合成网页测试中 达94%。【超越开源模型】
与闭源模型性能相当。
→验证:交互式范式+多阶段训练 → 增强UI-to-Code的能力+用户界面优化能力
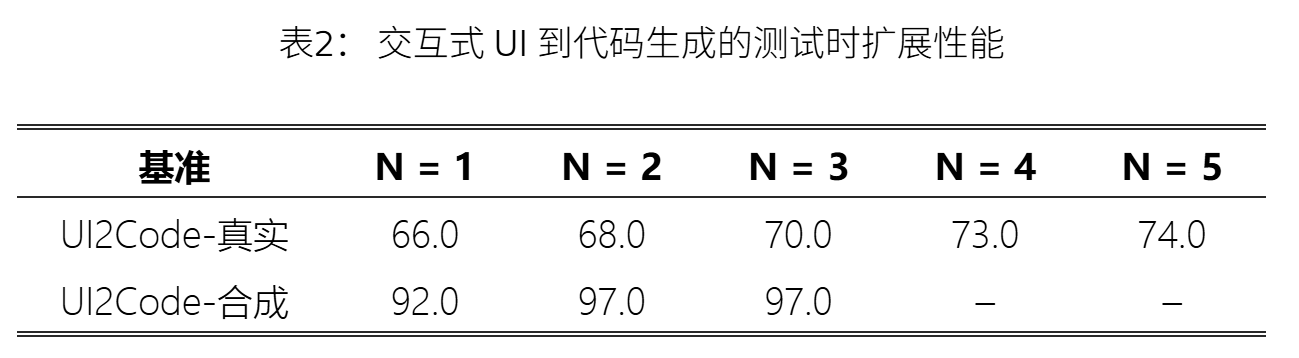
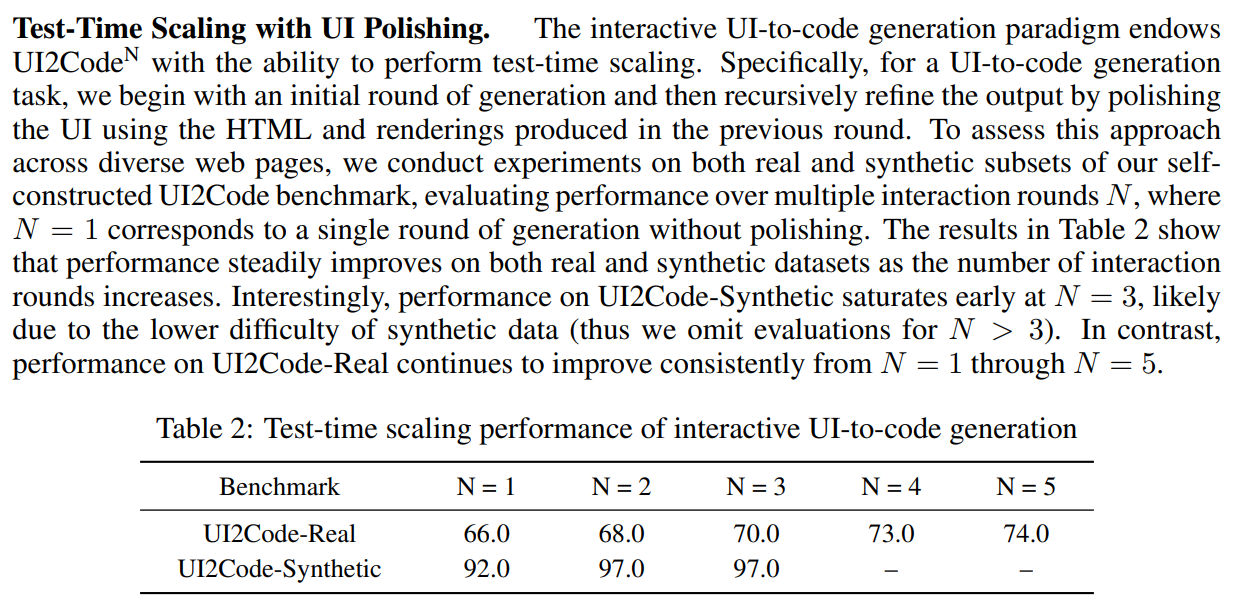
测试时扩展 及 用户界面优化:
交互轮数增加,性能提升。
性能提升在早期就饱和,N=3 合成数据难度较低。



消融研究:① 奖励设计的影响 ② 真实网页在RL阶段的影响
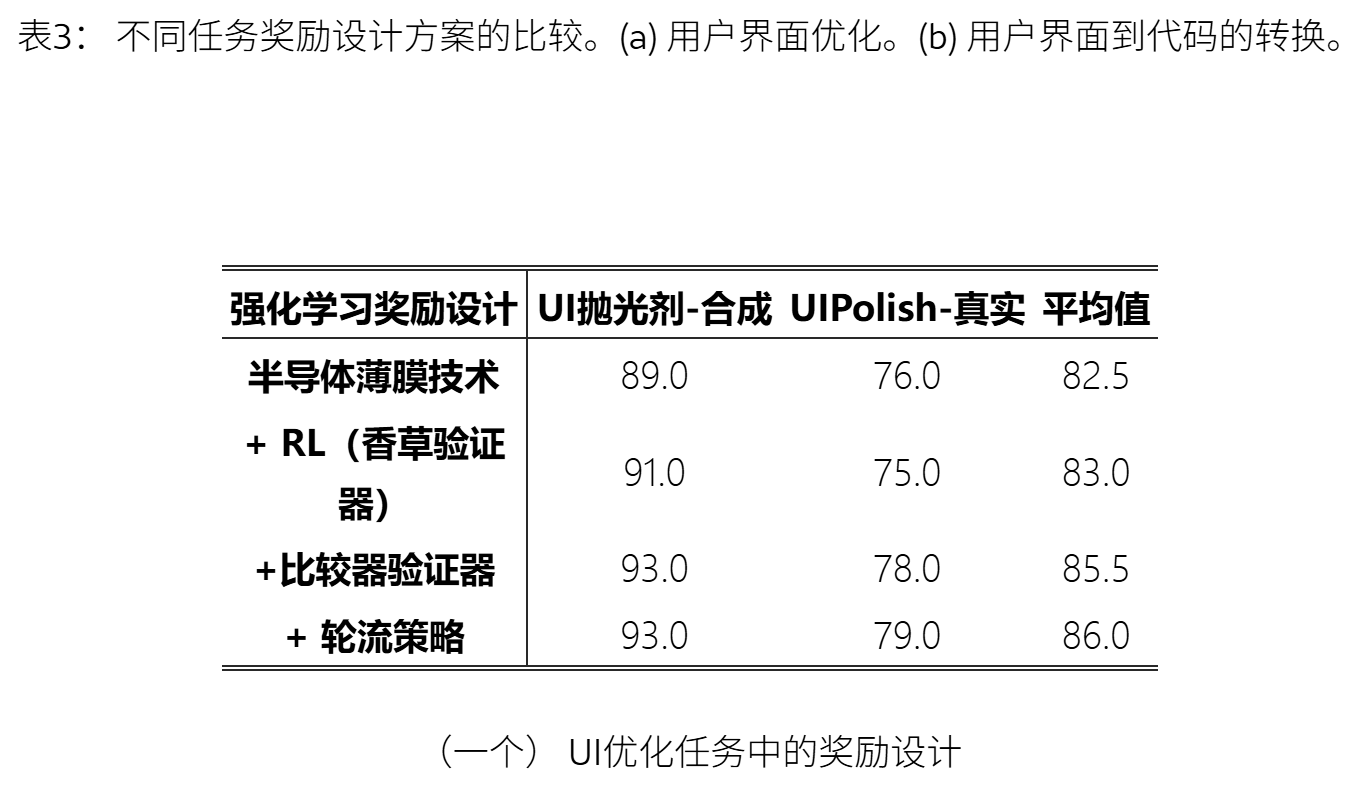
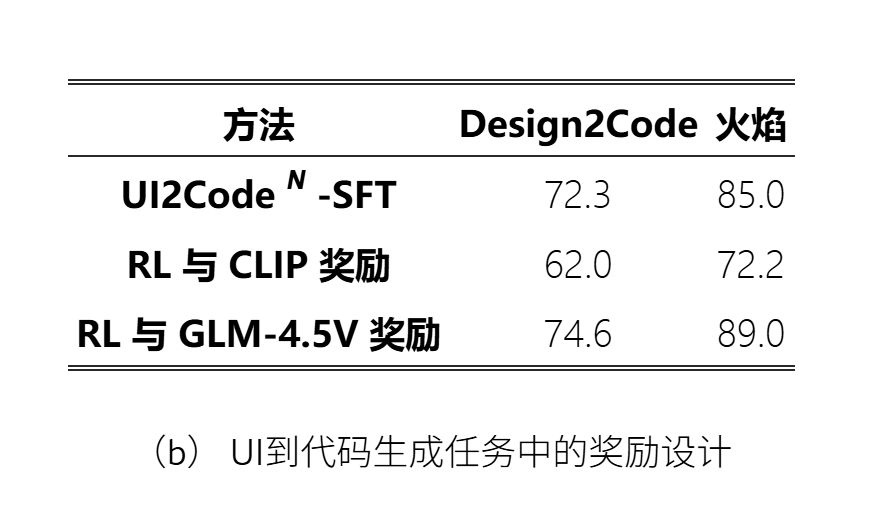
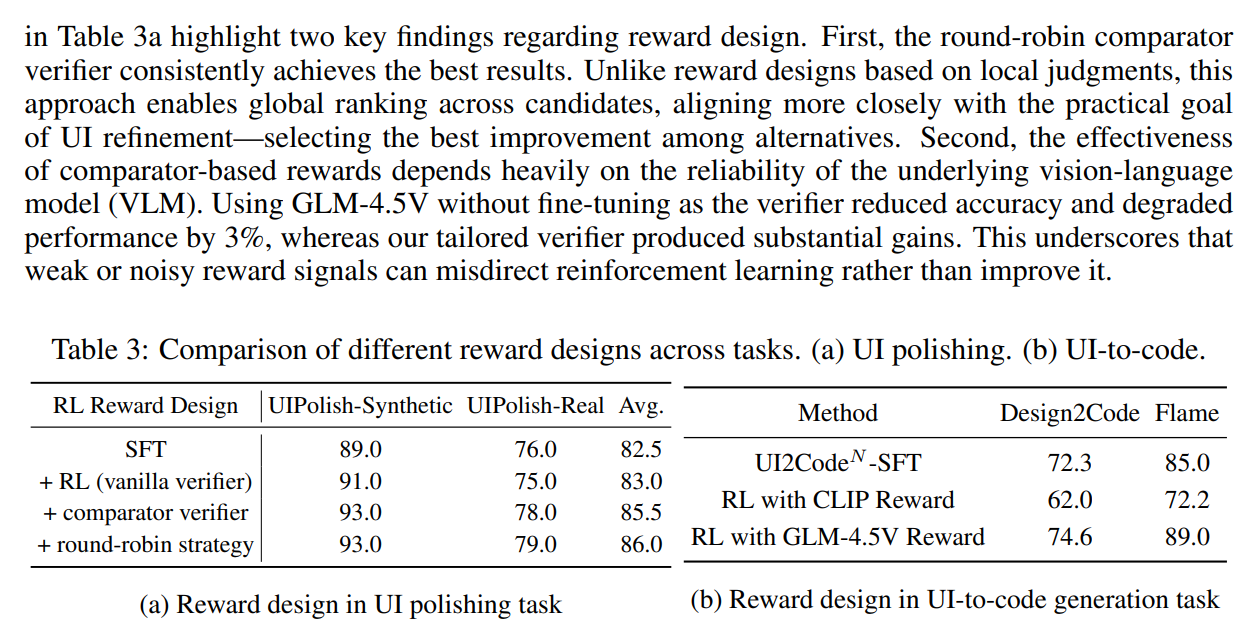
① 奖励设计的影响
奖励的设计:




②真实网页在RL的影响:

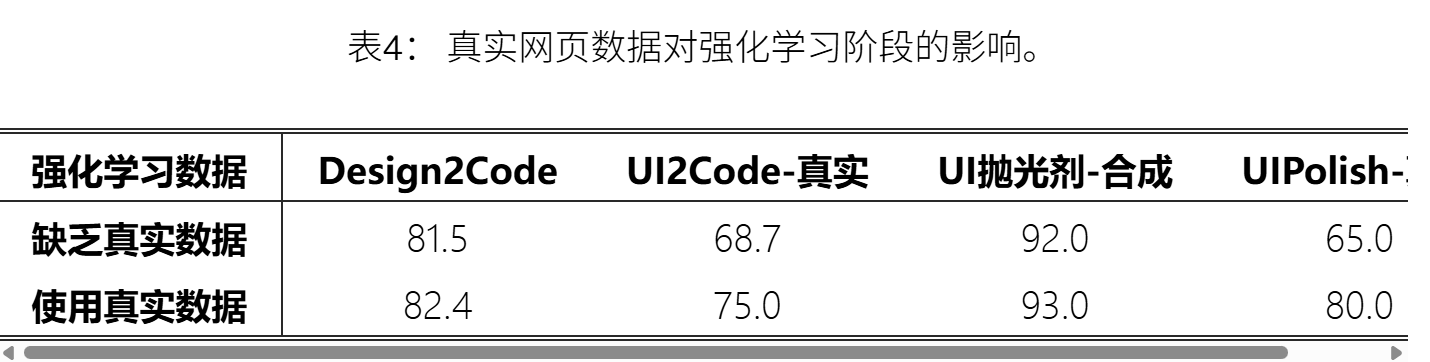
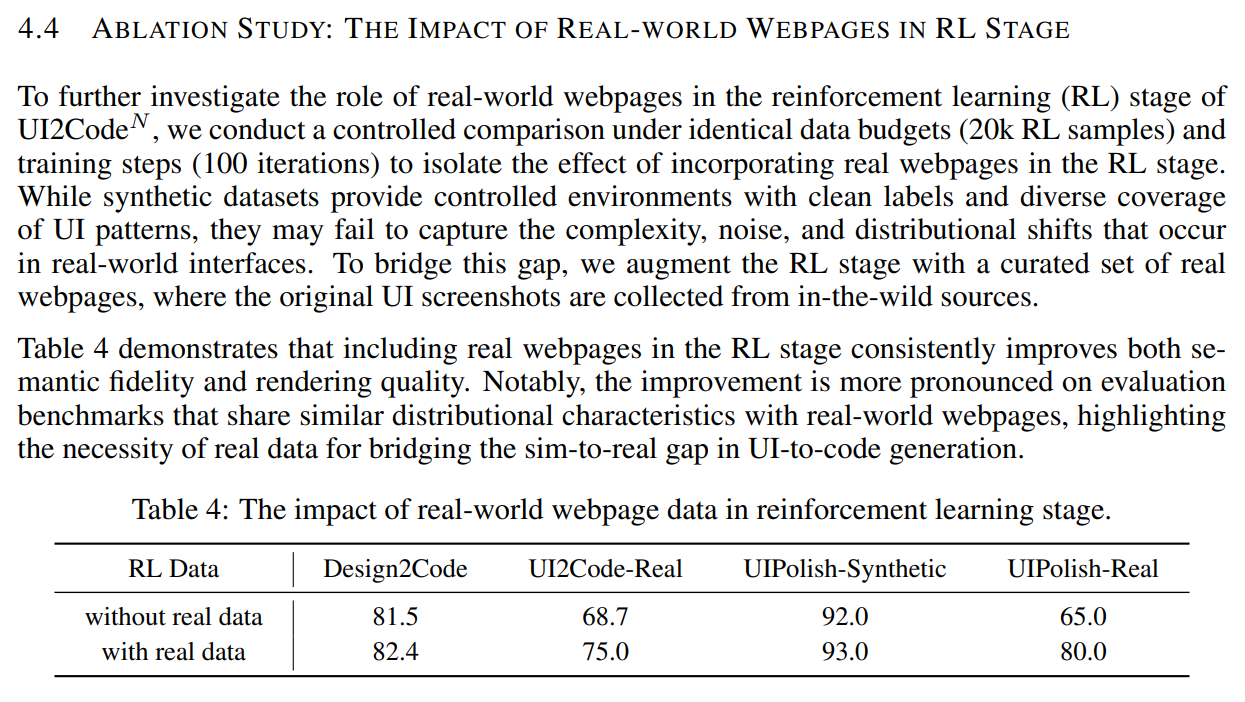
补充/附录:
奖励的设计:三个算法(验证者评分、比较器评分、循环比较器)
奖励的实施
提示 promt:
验证视觉评分,用于 UI 优化 RL 训练
评估指标规范:
基准详情:现有的基准、我们提出的基准
演示案例

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 12
12 0
0- 0



 已为社区贡献6条内容
已为社区贡献6条内容

所有评论(0)