ICLR 2026|QVLA:仅需30%显存,精度几乎无损!开始加速你的所有VLA吧~
QVLA 是 VLA 模型低比特量化的第一次系统性尝试。它证明了在具身智能领域,“以动作为中心”才是模型压缩的正确打开方式。这项工作不仅为在资源受限的机器人硬件上部署大模型铺平了道路,也将加速具身智能从实验室走向现实世界的进程。另外,本文提出的量化技术可以与pruning,diffusion cache等技术无缝接入,系统性的提升模型inference速度。
- Paper: https://arxiv.org/abs/2602.03782
- GitHub: https://github.com/AutoLab-SAI-SJTU/QVLA
随着 OpenVLA、RT-2 等视觉-语言-动作(VLA)模型的爆发,具身智能(Embodied AI)正迎来它的“ChatGPT时刻”。然而,这些庞大的模型往往动辄 7B 甚至更大,对于算力和显存受限的机器人终端来说,不仅跑不动,更是跑不快 。
虽然量化(Quantization)在大语言模型(LLM)中已经是“基操”,但直接搬运到具身VLA上的分析和研究却比较空白。
LLM 的量化方法在机器人VLA上表现怎么样?
如何让大模型塞进机器人小算力芯片的同时,还能手稳活细?
在刚刚公布的 ICLR 2026 中,来自上海交通大学 AutoLab、无界动力,中科院自动化所,蚂蚁等机构的研究团队给出了答案。他们提出了首个面向具身控制的通道级动作感知量化框架QVLA 。
🛑痛点:机器人动作的误差累积
在 LLM 领域,量化算法(如 SmoothQuant, AWQ)通常是为了保住“文本困惑度”或“视觉特征” 。但在机器人领域,评价标准完全不同。
研究团队发现,如果直接套用 LLM 的均匀量化,哪怕产生极其微小的动作误差,经过物理环境的放大和长序列任务的累积,也会导致“一步错,步步错”,最终引发抓取失败或轨迹偏离等灾难性后果 。
🛑核心洞察:Not All Channels Are Equal
QVLA 的核心思想非常直观:在 VLA 模型中,并非所有的通道(Channel)都是同样重要的 。
研究团队进行了细致的敏感度分析,发现:
- 模块差异大: 视觉编码器耐压缩;但投影层(Projector)和动作头(Action Head)对量化极其敏感,稍微压缩就会导致性能崩塌 。
- 通道差异大: 即使在同一层内,不同通道对最终动作输出的影响也天差地别 。
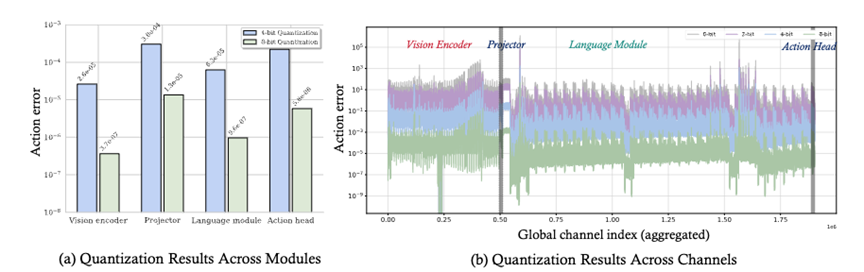
基于此,QVLA 抛弃了粗暴的“一刀切”均匀量化,提出了一种以“动作敏感度”为核心的混合精度策略。
🛑论文方法:让每一比特都花在刀刃上
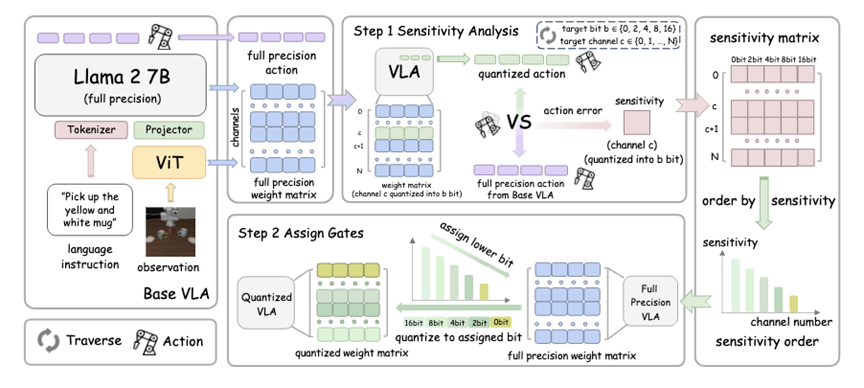
QVLA 的工作流程可以概括为两步走 :
- 动作敏感度计算(Step 1): 不同于传统方法看重特征重构误差,QVLA 直接测量量化某个通道会对最终动作空间产生多大误差 。为了计算高效,团队还推导了一套基于泰勒展开的快速代理指标 。
- 贪心比特分配(Step 2): 根据敏感度排名,算法会自动给每个通道分配不同位宽 。
- 关键通道: 保留高精度(16-bit/8-bit),确保手稳。
- 冗余通道: 疯狂压缩甚至直接剪枝(0-bit),节省资源 。
🛑性能优异:SOTA 级的压缩效果
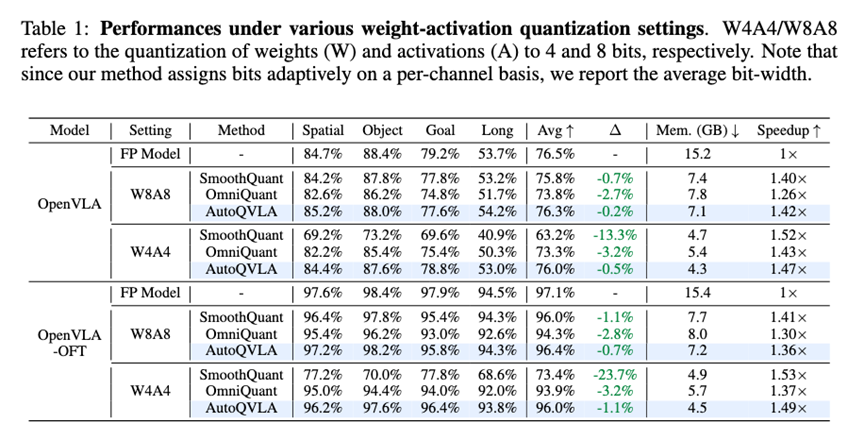
在 LIBERO 机器人操作基准测试中,QVLA 展现了优异的效果:
- 极致压缩: 在 OpenVLA-OFT 模型上,QVLA 仅需 29.2% 的显存(约 4.5GB),推理速度提升 1.49倍 。
- 性能无损: 在大幅压缩下,仍保持了 98.9% 的原始性能,甚至在部分任务上因去噪效应超过了全精度模型 。
- 吊打基线: 相比于 LLM 领域的明星方法 SmoothQuant(性能下降 23.7%),QVLA 的性能损失微乎其微(仅 1.1%) 。
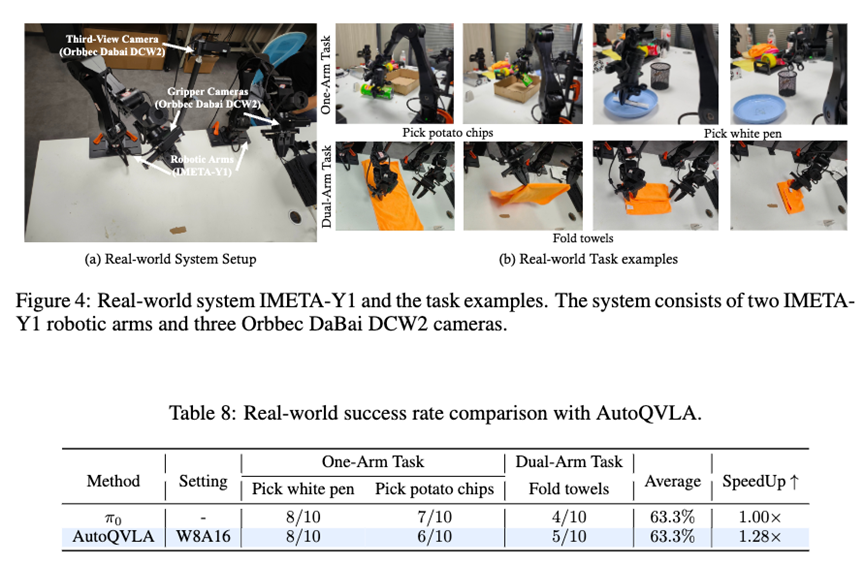
🛑真机实战
除了仿真环境,QVLA 还在真实的 IMETA-Y1 双臂机器人上进行了验证 。
在 NVIDIA 4070 显卡上,量化后的模型在“拿薯片”、“折叠毛巾”等灵巧操作任务中,表现与全精度模型几乎一致。
总结
QVLA 是 VLA 模型低比特量化的第一次系统性尝试。它证明了在具身智能领域,“以动作为中心”才是模型压缩的正确打开方式。这项工作不仅为在资源受限的机器人硬件上部署大模型铺平了道路,也将加速具身智能从实验室走向现实世界的进程 。
另外,本文提出的量化技术可以与pruning,diffusion cache等技术无缝接入,系统性的提升模型inference速度。
如我们将AutoPrune[NeurIPS’25],SmoothCache[CVPRW’24]和我们的量化方法用到pi0.5,可以实际inference速度加速1.8倍且性能几乎不掉,后续会一起更新到代码仓库。此外,我们后续也准备将算法集成到tensorRT中,这样便可以同时享受tensorRT极致的并行加速。
具身求职内推来啦
国内最大的具身智能全栈学习社区来啦!
推荐阅读
从零部署π0,π0.5!好用,高性价比!面向具身科研领域打造的轻量级机械臂
工业级真机教程+VLA算法实战(pi0/pi0.5/GR00T/世界模型等)
具身智能算法与落地平台来啦!国内首个面向科研及工业的全栈具身智能机械臂
VLA/VLA+触觉/VLA+RL/具身世界模型等!具身大脑+小脑算法与实战全栈路线来啦~
MuJoCo具身智能实战:从零基础到强化学习与Sim2Real
Diffusion Policy在具身智能领域是怎么应用的?为什么如此重要?
1v1 科研论文辅导来啦!

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 12
12 0
0- 0



 已为社区贡献39条内容
已为社区贡献39条内容

所有评论(0)