面壁MiniCPM-SALA模型,稀疏-线性注意力,单卡吞吐百万上下文
注意力“太昂贵了”,人的注意力如此,大模型也是!DeepSeek推出稀疏注意力DeepSeek Sparse Attention(DSA),让大模型读得快,想的深,还更省资源。智谱刚刚发布最强开源模型GLM-5,就首次集成了DSA注意力。Kimi推出的线性注意力Kimi Delta Attention(KDA),也实现了大模型卓越性能,高吞吐量,更省资源。面壁智能团队则创新性地首次将稀疏与线性注意
注意力“太昂贵了”,人的注意力如此,大模型也是!
DeepSeek推出稀疏注意力DeepSeek Sparse Attention(DSA),让大模型读得快,想的深,还更省资源。
智谱刚刚发布最强开源模型GLM-5,就首次集成了DSA注意力。
Kimi推出的线性注意力Kimi Delta Attention(KDA),也实现了大模型卓越性能,高吞吐量,更省资源。
面壁智能团队则创新性地首次将稀疏与线性注意力结合提出Sparse and Linear Attention(SALA)。

基于新的独特的稀疏与线性注意力混合架构训练的MiniCPM-SALA模型,在单张A6000显卡上实现了百万token的超长上下文推理,同时将模型训练成本降低了约75%。
在保留模型聪明才智的同时,把长文本处理的效率提升到了极致。
混合架构破解长文本算力诅咒
大语言模型正从短跑向马拉松范式转移,应用场景不再局限于简单的问答,而是转向了需要处理海量信息,比如一次性读完厚重的技术手册、分析包含数万行代码的项目库,或者在长达数天的人机协作中保持连贯的记忆。
这种全方位的上下文理解能力,要求模型必须能够轻松消化百万级的token。
传统的Transformer架构在面对这种超长上下文时显得力不从心,核心症结在于其全注意力机制(Full Attention)。
这种机制要求模型在生成每一个新字时,都要回头去“看”之前所有的字,计算量随着文本长度的增加呈平方级爆炸式增长。
这就像是一个记忆力虽好但效率极低的阅读者,每读一个新句子,都要把整本书从头到尾复习一遍。
当文本长度达到百万级别时,这种计算开销和内存占用(KV-Cache)会庞大到让即便是昂贵的计算集群也望而却步。
为了解决这个问题,业界尝试过稀疏注意力(Sparse Attention)和线性注意力(Linear Attention)。
稀疏注意力试图只关注重要的信息片段,像是在书中做折角标记;线性注意力则试图将信息压缩成固定大小的状态,如同写摘要。
两者各有千秋,稀疏注意力能保留细节但存储压力依然大,线性注意力计算极快但容易丢失信息导致变笨。
MiniCPM-SALA巧妙地将它们结合在了一起。
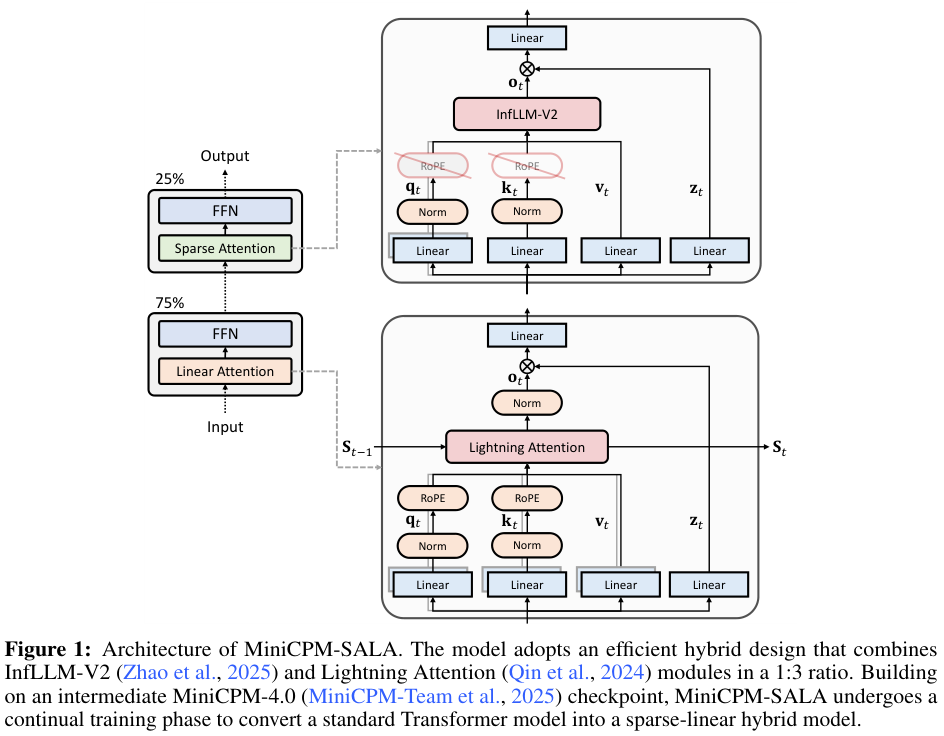
MiniCPM-SALA采用了1:3的黄金比例混合策略,即25%的层使用稀疏注意力(具体为InfLLM-V2),负责精准捕捉长距离的细节依赖;剩余75%的层使用线性注意力(具体为Lightning Attention),负责高效地处理全局信息。
这种分工协作极其高明,线性注意力层保持了处理长序列时的恒定计算和内存复杂度,为模型提供了广阔的视野和极高的吞吐量,而稀疏注意力层则像是一个个精准的定位器,确保模型在茫茫文海中不会丢失关键细节。
为了让这两位性格迥异的“搭档”配合默契,团队引入了混合位置编码(HyPE)。
在线性注意力层,模型保留了旋转位置编码(RoPE),这有助于模型感知全局的相对位置关系,知道谁在谁的前面。而在稀疏注意力层,RoPE被特意移除。
这是一个非常敏锐的洞察,因为RoPE在长距离上往往会导致信息衰减,移除它反而让模型在超长上下文中能更精准地召回远古记忆。
除了位置编码,模型还在每个注意力块后加入了输出门控(Output Gates)。
这个小巧的机制起到了调节阀的作用,有效防止了注意力汇聚在某些无关紧要的token上,解决了常见的“注意力耗散”问题。
通过调节信息流,输出门控让模型能够更灵活地分配注意力权重,既保证了稳定性,又提升了性能。
继承权重让训练成本暴降七成
从零开始训练一个高性能的大模型,通常需要耗费巨大的算力和财力。MiniCPM-SALA团队基于已经训练好的MiniCPM-4.0模型进行了架构转换。
利用名为HALO(Hybrid Attention via Layer Optimization)的技术,将原本的全注意力模型平滑过渡到混合架构。
这相当于给一个已经博览群书的成年人进行了一次微创手术,让他学会了速读和精读的结合,而不是重新培养一个婴儿。
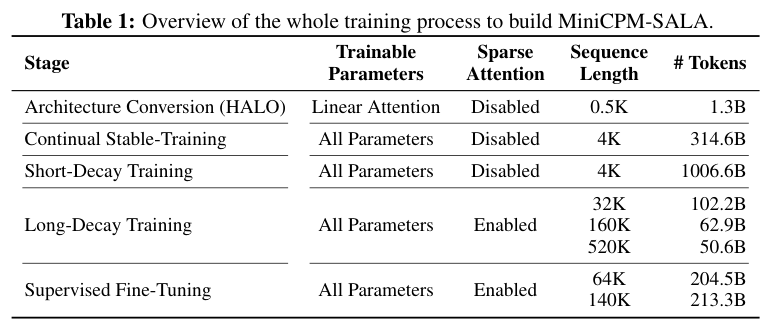
Table 1概括了构建MiniCPM-SALA的全过程。从架构转换到持续预训练,再到长文本适应和监督微调,整个过程环环相扣,高效利用了预训练权重。
整个训练流程分为五个精密的阶段。
首先是架构转换,利用HALO算法决定哪些层保留为稀疏注意力,哪些层转换为线性注意力。
为了保证稳定性,模型的首尾层保持不变。在这个阶段,只有转换后的线性注意力层参数是可训练的,其他参数冻结,仅用少量的1.3B token就完成了初步适配。
接下来是持续稳定训练阶段,目的是让新转换的线性层与模型的其他部分(如FFN层和嵌入层)磨合。
随后进入短衰减训练,引入大量高质量数据,进一步巩固模型的基础能力。
真正让模型掌握长文本能力的是长衰减训练阶段。
在这里,序列长度从4K逐步拉长到32K、160K,最终达到520K。
随着长度的增加,稀疏注意力机制被激活,模型开始学习如何在浩瀚的上下文中协同使用稀疏和线性两种注意力。
最终,通过监督微调(SFT),使用高质量的推理和长文本数据,将模型的潜力完全激发出来。
这种基于转换的持续训练策略,总共消耗了约2T的token,仅为从头训练MiniCPM-4.0所需数据量的25%。
这不仅大幅节省了计算资源,还完美继承了原模型强大的通用能力。
边缘设备也能跑通百万长文
基于新架构的MiniCPM-SALA模型不仅在传统的知识、代码和数学基准测试中保持了与全注意力模型相当的水准,更在长文本处理上展现出了压倒性的优势。
在RULER、MRCR等长文本基准测试中,MiniCPM-SALA在128K长度下的表现显著优于同量级的Qwen3-8B和Falcon-H1R-7B等模型。
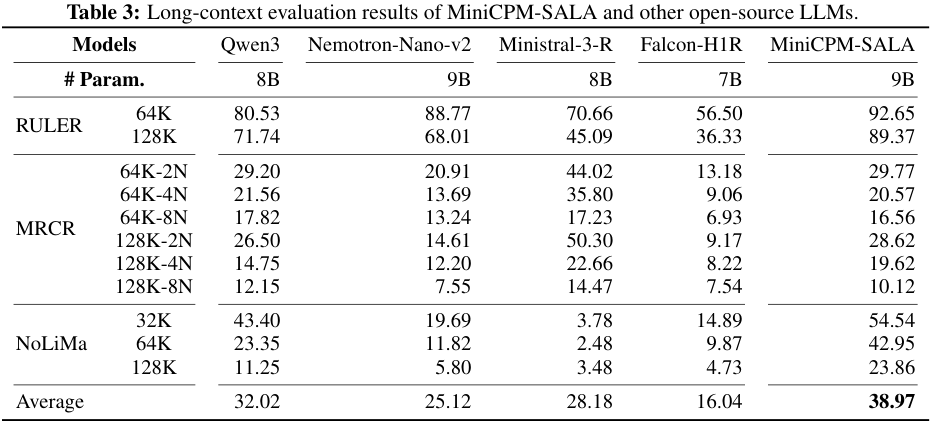
特别是在大海捞针(Needle In A Haystack)类的任务中,它展现出了极高的检索准确率。
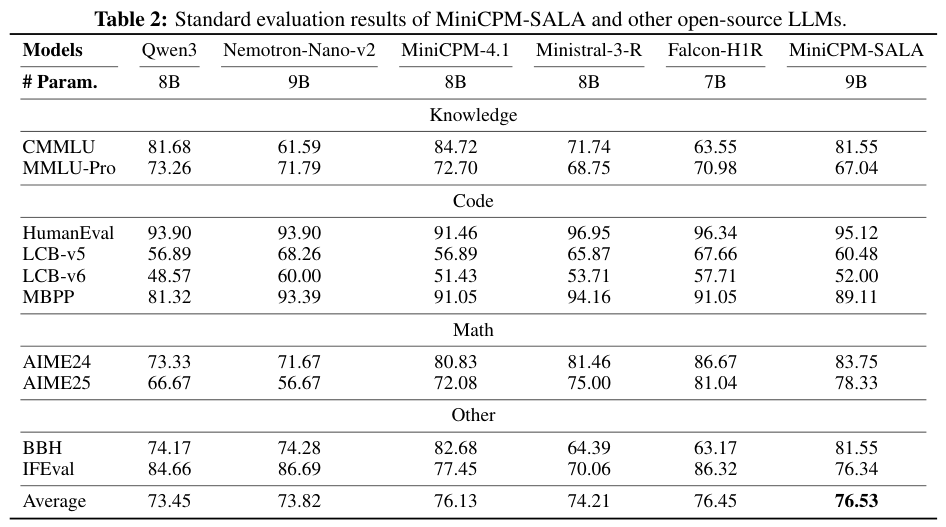
在常规短文本基准测试中,MiniCPM-SALA并没有因为引入了线性注意力而牺牲通用能力,其平均得分甚至略高于Qwen3-8B等强力基线。
更令人兴奋的是其在推理速度和内存效率上的突破。
在NVIDIA A6000D(96GB显存)上,当序列长度达到256K时,MiniCPM-SALA的推理速度是Qwen3-8B的3.5倍。
首字延迟(TTFT)从180秒缩短到了51秒,这种体验上的提升是质的飞跃。
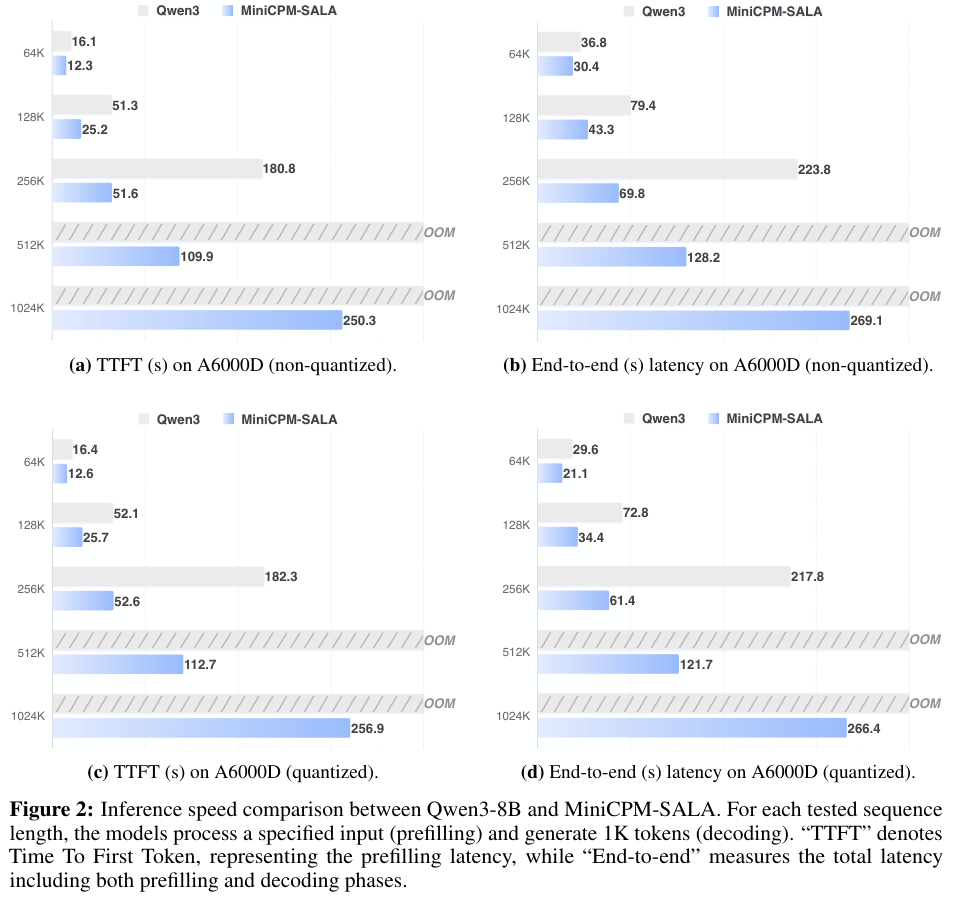
随着序列长度增加,MiniCPM-SALA在首字生成时间(TTFT)和端到端延迟上均大幅优于Qwen3-8B。Qwen3在512K长度时就因显存不足(OOM)而失败,而MiniCPM-SALA依然稳健运行。
当全注意力模型在512K和1M长度面前纷纷因显存耗尽(OOM)而倒下时,MiniCPM-SALA依然能够从容应对。
它甚至支持在RTX 5090和4090这样的消费级显卡上运行超长上下文任务。
在RTX 5090(32GB显存)上,经过4-bit量化后的MiniCPM-SALA可以处理高达256K的上下文,而同条件下的全注意力模型在128K时就已经崩溃。
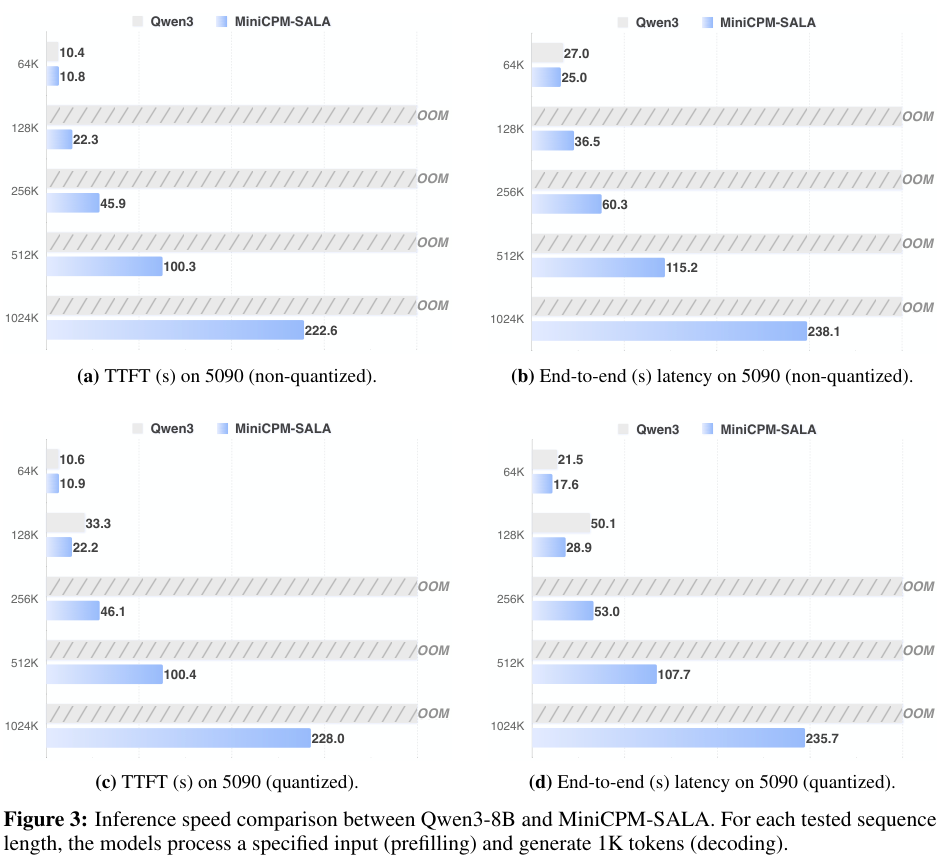
MiniCPM-SALA成功突破了显存墙,让个人用户也能在本地处理海量数据。
这种极致的效率还带来了惊人的外推能力。
尽管训练时最长只接触过520K的序列,MiniCPM-SALA却能将其能力延伸至200万token,且性能没有明显下降。
这证明了其架构并非死记硬背位置信息,而是真正掌握了处理长序列的内在逻辑。
这项技术让大模型普及迈出了一大步,百万级的长文本分析不再是拥有昂贵H100集群的巨头的专利。普通开发者也能玩转。
参考资料:
https://github.com/openbmb/minicpm
https://huggingface.co/openbmb/MiniCPM-SALA
https://www.modelscope.cn/models/OpenBMB/MiniCPM-SALA

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 15
15 0
0- 0



 已为社区贡献248条内容
已为社区贡献248条内容

所有评论(0)