人工智能 - 2026年人工智能发展的三大核心风口
当AI从屏幕后的工具跃变为渗透现实的“参与者”,2026年将成为人工智能发展的关键分水岭。2026年人工智能发展的三大核心风口被广泛认为是:AI原生应用,物理AI,多模态大模型当AI从屏幕后的工具跃变为渗透现实的“参与者”,2026年将成为人工智能发展的关键分水岭。综合2025年底至2026年初多家权威科技媒体和行业分析的共识,2026年人工智能发展的三大核心风口被广泛认为是:AI原生应用,物理A
当AI从屏幕后的工具跃变为渗透现实的“参与者”,2026年将成为人工智能发展的关键分水岭。2026年人工智能发展的三大核心风口被广泛认为是:AI原生应用,物理AI,多模态大模型
当AI从屏幕后的工具跃变为渗透现实的“参与者”,2026年将成为人工智能发展的关键分水岭。综合2025年底至2026年初多家权威科技媒体和行业分析的共识,2026年人工智能发展的三大核心风口被广泛认为是:AI原生应用,物理AI,多模态大模型。
- AI原生应用(AI-Native Applications):AI不再作为附加功能,而是成为系统设计的底层逻辑。应用将具备自然语言交互、自主学习与适应、以及端到端自主完成任务的能力,彻底重构人机交互方式,尤其在办公、设计等知识工作者场景中潜力巨大。
- 物理AI(Physical AI):AI从数字世界走向物理现实,通过“世界模型+物理仿真引擎+具身智能控制器”三大技术组件,使机器人、自动驾驶等智能体能在真实环境中进行感知、推理与行动,实现从“理解世界”到“改变世界”的跨越。
- 多模态大模型(Multimodal Large Models):AI模型将深度融合文本、图像、音频、视频、3D等多种数据模态,实现跨模态的理解与生成,成为支撑AI在复杂现实场景中应用的基础能力,是推动AI从单一任务向综合智能演进的关键。
01 AI原生
AI原生开发平台已形成明确趋势,低代码/无代码工具让普通人无需编程即可打造专属AI工具。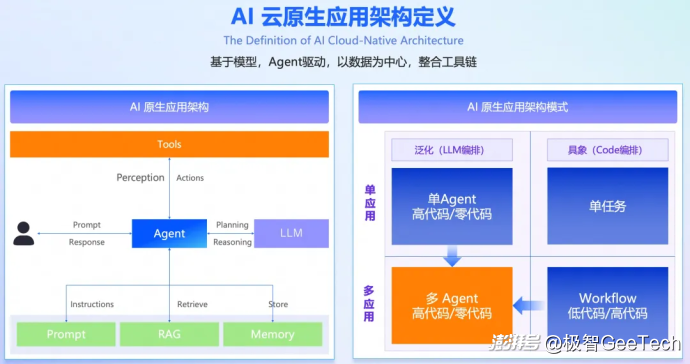
一个真正的AI原生系统或应用,通常具备以下三个显著特征:
-
以自然语言交互为基础: 用户通过语言交互界面与后端交互,无需或者少量通过图形界面与后端交互,最终呈现GUI(图形用户界面)和LUI(语言用户界面)混合的交互形式,以实现用户从有限的输入跃迁到无限的输入,既提供高频、固定的功能,也具备对低频、定制化需求的理解与处理能力。
-
具备自主学习和适应能力: 在人机交互过程中,能够集成理解、记忆、适应多模态数据,并进行自我学习,能根据上下文、任务环境、交互对象的变化,对输出结果进行更准确、更个性化的调整。
-
具备自主完成任务的能力:有能力基于大语言模型和知识库执行精确任务,实现端到端闭环,集获取任务到完成任务全流程于一体。
02 物理AI
物理AI(Physical AI)时代,AI不仅能够理解世界,还能够像人一样进行推理、计划和行动。
物理AI的技术基础建立在三个关键组件之上:世界模型、物理仿真引擎和具身智能控制器。
世界模型是物理AI的认知核心,它不同于传统的语言模型或图像模型,需要构建对三维空间的完整理解,包括物体的几何形状、材质属性、运动状态和相互关系。这通常通过神经辐射场(NeRF)、3D高斯溅射(3D Gaussian Splatting)或体素网格(Voxel Grid)等方法来实现空间表征,模型需要学习物理定律的隐式表示,比如重力加速度、摩擦系数、弹性模量等参数,并能够根据当前状态预测未来的物理演化。
物理仿真引擎则负责实时计算物理交互,这不是简单的预设规则,而是基于偏微分方程求解器的动态计算系统,需要处理刚体动力学、流体力学、软体变形等复杂物理现象,系统需要在毫秒级时间内完成复杂的物理计算,同时保证足够的精度来支持准确的决策。
具身智能控制器是连接虚拟推理和物理执行的桥梁,它接收来自世界模型的预测结果和物理仿真的计算输出,生成具体的控制指令。技术上,通常基于模型预测控制(MPC)或深度强化学习(DRL)算法,控制器需要处理高维的状态空间和动作空间,同时考虑执行器的物理限制、延迟和噪声。
多模态大模型
多模态大模型的能力体系主要围绕“跨模态理解”与“跨模态生成”两大核心构建。
在跨模态理解方面,其核心能力体现在三个层面:
第一,出色的语义匹配能力,可判断文本与图片、音频与文字记录等不同模态信息是否语义一致,在内容检索和信息校验中作用重大。
第二,文档智能场景下的结构化解析能力,不仅能识别字符,更能在复杂场景中准确解析表格、版面、图文混排等内容,理解文档的深层结构与语义。
第三,多模态内容的深层解读能力,例如分析带文字说明的图表、关联视频动作与同期声、解读图文社交媒体内容的情感倾向等。
跨模态生成则更为引人注目,基于一种模态生成另一种模态内容已成为现实。除常见的图像转文本外,还包括文本生成图像、音频转文本、文本生成音频、视频生成文字梗概等,极大拓展了内容创作的边界。
世界模型
世界模型并没有一个标准的定义,这一概念源于认知科学和机器人学,它强调AI系统需要具备对物理世界的直观理解,而不仅仅是处理离散的符号或数据。
世界模型的价值在于“泛化能力”——能够将已知场景的认知迁移到未知场景,例如在未见过的乡村道路上,基于对物理规律的理解,依然能安全行驶。
特斯拉与谷歌等企业正积极研发世界模型,通过输入图像序列与提示词,生成符合物理规律的虚拟场景,用于模型训练与仿真测试,形成“数据-模型-仿真”的无限闭环。
行业普遍认为,世界模型是一种能够对现实世界环境进行仿真,并基于文本、图像、视频和运动等输入数据来生成视频、预测未来状态的生成式Al模型。它整合了多种语义信息,如视觉、听觉、语言等,通过机器学习、深度学习和其他数学模型来理解和预测现实世界中的现象、行为和因果关系。
简单来说,世界模型就像是A1系统对现实世界的“内在理解”和“心理模拟”。它不仅能够处理输入的数据,还能估计未直接感知的状态,并预测未来状态的变化。
这个模型的核心目标是让AI系统能够像人类一样,在内部构建一个对外部物理环境的模拟和理解。通过这种方式,AI可以在“脑海”中模拟和预测不同行为可能导致的后果,从而进行有效的规划和决策。
例如,一个具备世界模型的自动驾驶系统,可以在遇到湿滑路面时,预判到如果车速过快可能会导致刹车距离延长,从而提前减速,避免危险。这种能力源于AI内部对物理规律(如摩擦力、惯性)的模拟,而不是简单地记忆“湿滑路面要减速”这条规则。
世界模型具有三大核心特点:
其一,内在表征与预测。世界模型可以将高维的原始观测数据(如图像、声音、文本等)编码为低维的潜在状态,形成对世界的简洁而有效的表征。在此基础上,它能够预测在给定当前状态和动作的情况下,下一个时刻的状态分布,从而实现对未来事件的前瞻性预测。
其二,物理认知与因果关系。世界模型具备基本的物理认知能力,能够理解和模拟物理世界的规律,如重力、摩擦力、运动轨迹等。这使得它在处理与物理世界相关的问题时,能够提供更准确、更符合现实的预测和决策支持。
其三,反事实推理能力。世界模型不仅能够基于已有的数据进行预测,还能够进行假设性思考,即反事实推理。例如,它可以回答“如果环境条件改变,结果会怎样”这类问题,从而为复杂问题的解决提供更多的可能性和思路。
技术层面,世界模型关键技术包括因果推理、场景重建时空一致性、多模数据物理规则描述、执行与实时反馈。全球主流模型如谷歌Genie3、英伟达COSMOS等,国内华为盘古、蔚来NWM等模型在不同应用场景展现优势。
应用领域,在自动驾驶中,世界模型可生成高动态、高不确定性场景,解决长尾问题,通过构建闭环反馈机制赋能自动驾驶系统,降低成本、提升效率,未来将向多模态融合、通用化等方向发展。比如蘑菇车联MogoMind通过将物理世界实时动态数据纳入训练体系,突破了传统大模型仅依赖互联网静态数据的局限,实现从全局感知、深度认知到实时推理决策的闭环,可以为多类型智能体提供实时数字孪生与深度理解服务。
在具身智能中,世界模型提供大规模高质量合成数据,解决数据缺口问题,还重塑开发范式,未来将构建“物理+心智”双轨建模架构,提升人机交互与多智能体协作能力。
参考资料:
https://www.thepaper.cn/newsDetail_forward_32088718

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐


 14
14 0
0- 0



 已为社区贡献21条内容
已为社区贡献21条内容

所有评论(0)