AI项目问题总结大全
本文介绍了基于DeepSeek和LangChain构建知识库检索系统的两种方案。方案一使用LangChain框架,通过加载多种格式文档(txt/pdf/docx)、文本分块、向量化处理(采用HuggingFace嵌入模型)并存入Chroma向量数据库,最终搭建可查询的问答系统。方案二基于LlamaIndex实现,特点是以中文优化向量模型为核心,通过创建索引实现高效检索。两种方案均支持本地LLM(如
目录:
1、deepseek和langchain有什么关联以及使用的场景
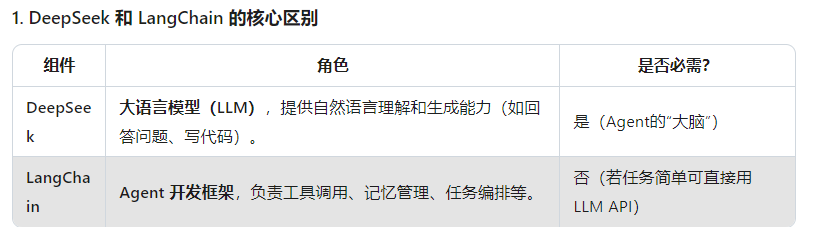
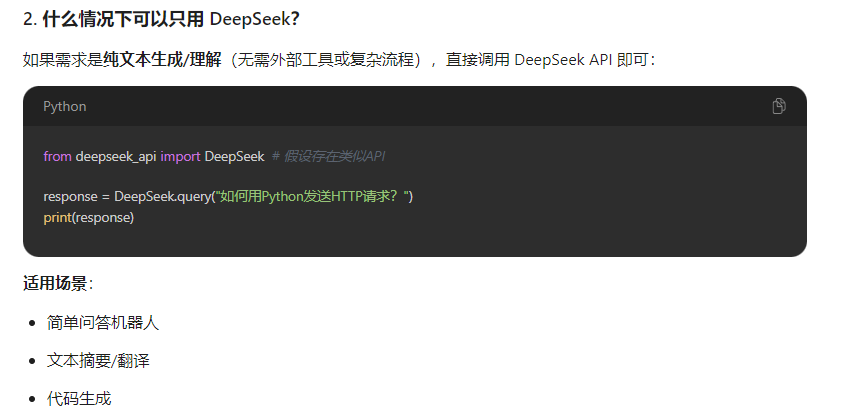
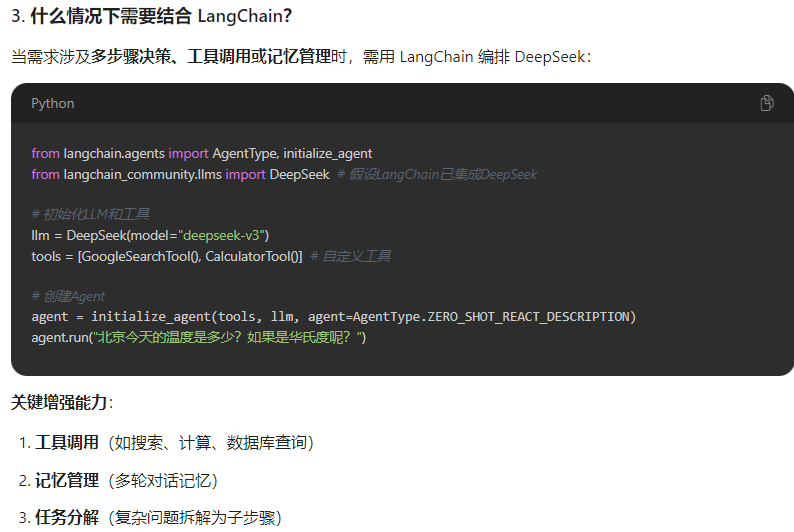
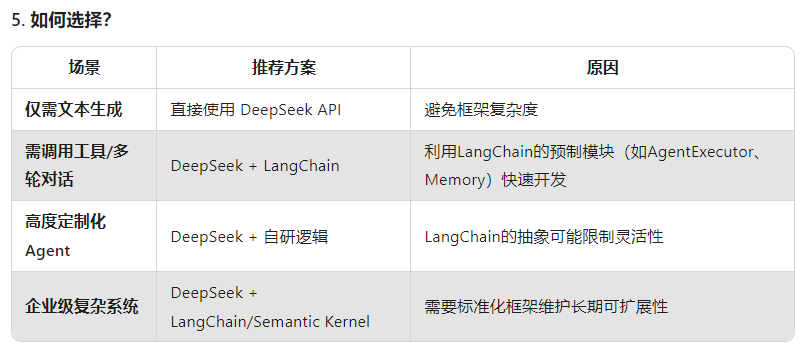
2、已有的文档目录如何实现知识库检索
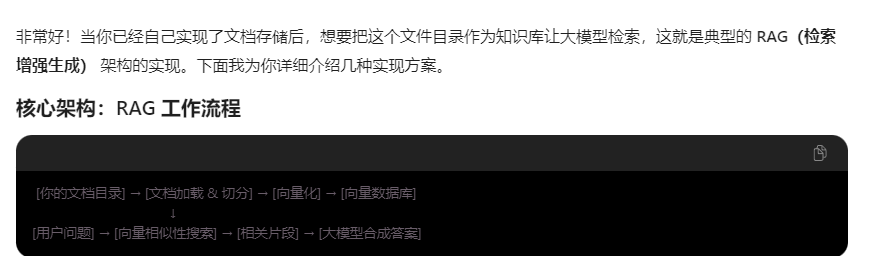
其实就是要把所有文档都加载到向量数据库 大模型才能检索到。
方案一:使用 LangChain/LlamaIndex 框架(推荐)
1. 基于 LangChain 的实现
import os
from langchain.document_loaders import DirectoryLoader, TextLoader, PyPDFLoader, UnstructuredWordDocumentLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import Chroma
from langchain.llms import Ollama # 或 OpenAI, Tongyi等
from langchain.chains import RetrievalQA
class DocumentQASystem:
def __init__(self, docs_directory):
self.docs_directory = docs_directory
self.vectorstore = None
def initialize_knowledge_base(self):
"""初始化知识库"""
# 1. 文档文档加载 - 根据不同类型使用不同的loader
loaders = {
'.txt': TextLoader,
'.pdf': PyPDFLoader,
'.docx': UnstructuredWordDocumentLoader,
}
all_docs = []
for ext, loader_class in loaders.items():
try:
loader = DirectoryLoader(
self.docs_directory,
glob=f"**/*{ext}",
loader_cls=loader_class,
show_progress=True
)
docs = loader.load()
all_docs.extend(docs)
except Exception as e:
print(f"加载 {ext} 文件时出错: {e}")
print(f"共加载 {len(all_docs)} 个文档")
# 2. 文本切分
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=1000, # 每个片段的字符数
chunk_overlap=200, # 重叠字符数,保持上下文连贯
length_function=len,
)
splits = text_splitter.split_documents(all_docs)
print(f"切分为 {len(splits)} 个文本片段")
# 3. 向量 向量化模型(本地)
embeddings = HuggingFaceEmbeddings(
model_name="sentence-transformers/all-MiniLM-L6-v2" # 轻量且效果好
)
# 4. 创建向量数据库
self.vectorstore = Chroma.from_documents(
documents=splits,
embedding=embeddings,
persist_directory="./chroma_db" # 向量数据库持久化目录
)
return self
def query(self, question):
"""查询知识库"""
if not self.vectorstore:
raise ValueError("请先初始化知识库")
# 5. 创建检索链
qa_chain = RetrievalQA.from_chain_type(
llm=Ollama(model="qwen:7b"), # 本地LLM,或使用Coze API
chain_type="stuff", # 还有其他方式:map_reduce, refine等
retriever=self.vectorstore.as_retriever(
search_type="similarity", # 相似度搜索
search_kwargs={"k": 4} # 返回最相关的4个片段
),
return_source_documents=True
)
result = qa_chain({"query": question})
return result
# 使用示例
if __name__ == "__main__":
# 初始化
qa_system_system = DocumentQASystem("/path/to/your/documents")
qa_system.initialize_knowledge_base()
# 查询
answer = qa_system.query("你们公司的产品有什么特色?")
print(answer["result"])
# 查看来源文档
for doc in answer["source_documents"]:
print(f"来源: {doc.metadata['source']}, 页码: {doc.metadata.get('page', 'N/A')}")
2. 基于 LlamaIndex 的实现
from llama_index import VectorStoreIndex, SimpleDirectoryReader, ServiceContext
from llama_index.embeddings import HuggingFaceEmbedding
from llama_index.llms import Ollama
def setup_llamaindex_knowledgebase(doc_path):
"""使用LlamaIndex设置知识库"""
# 1. 加载文档
documents = SimpleDirectoryReader(doc_path).load_data()
# 2. 配置服务和LLM
embed_model = HuggingFaceEmbedding(
model_name="BAAI/bge-small-zh-v1.5" # 中文优化的向量模型
)
llm = Ollama(model="qwen:7b")
service_context = ServiceContext.from_defaults(
llm=llm,
embed_model=embed_model,
chunk_size=1024
)
# 3. 创建索引
index = VectorStoreIndex.from_documents(
documents,
service_context=service_context
)
# 4. 创建查询引擎
query_engine = index.as_query_engine(
similarity_top_k=5,
response_mode="compact"
)
return query_engine
# 使用
query_engine = setup_llamaindex_knowledgebase("/path/to/your/documents")
response = query_engine.query("介绍一下产品的主要功能")
print(response)
3、AI agent的实现原理
AI Agent = LLM + 推理能力 + 工具使用 + 记忆机制
与传统聊天机器人不同,Agent 具有自主性、目标导向和环境交互能力。
总结:
AI Agent的核心原理是将大语言模型从一个单纯的文本生成器升级为具备自主感知、规划、行动、反思能力的智能体。关键在于:
- 推理链路的明确化 - 让思考过程可见可控
- 工具的扩展性 - 突破纯文本的限制
- 记忆的持久化 - 积累经验和知识
- 决策的层次化 - 从战略规划到战术执行
这种架构使得AI能够处理远超单次对话范围的复杂任务,真正成为人类的智能伙伴。
4、LangChain、LlamaIndex 和 LangGraph使用场景
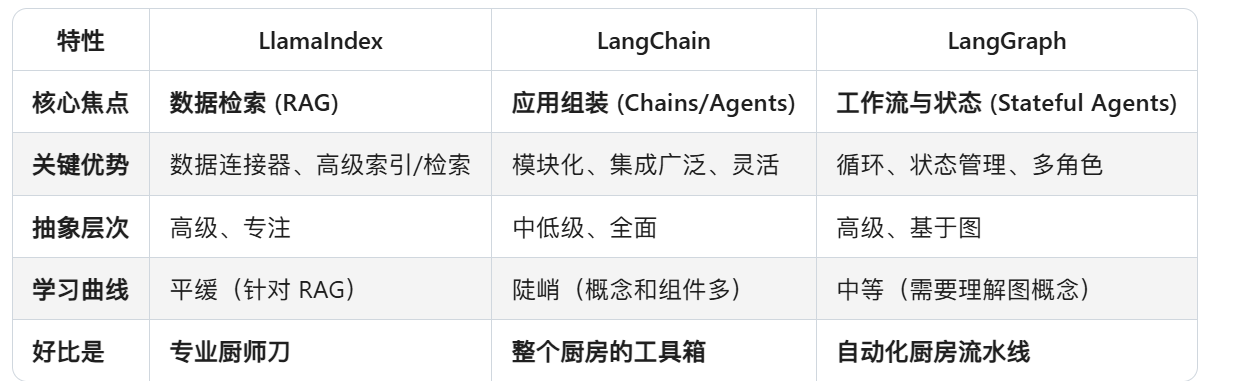
如何选择?
- 做 RAG? -> 从 LlamaIndex 开始,它为你省去了很多底层细节(纯知识库检索项目)。
- 快速原型,需要调用各种工具和API? -> 用 LangChain,它的生态系统无人能及。
- 构建有复杂推理和循环的智能代理? -> LangGraph 是你的不二之选,它通常与 LangChain 组件一起使用(LangChain+ LangGraph 是强大组合)。
现代趋势是结合使用它们:
例如,使用 LlamaIndex 作为 LangChain 或 LangGraph 中的一个检索工具,发挥各自长处,构建最强大的应用。
5、SpringAI项目demo示例开源项目
项目地址:
https://github.com/liuyueyi/spring-ai-demo/tree/master
6、机器学习(ML)和深度学习(DL)的区别和特点
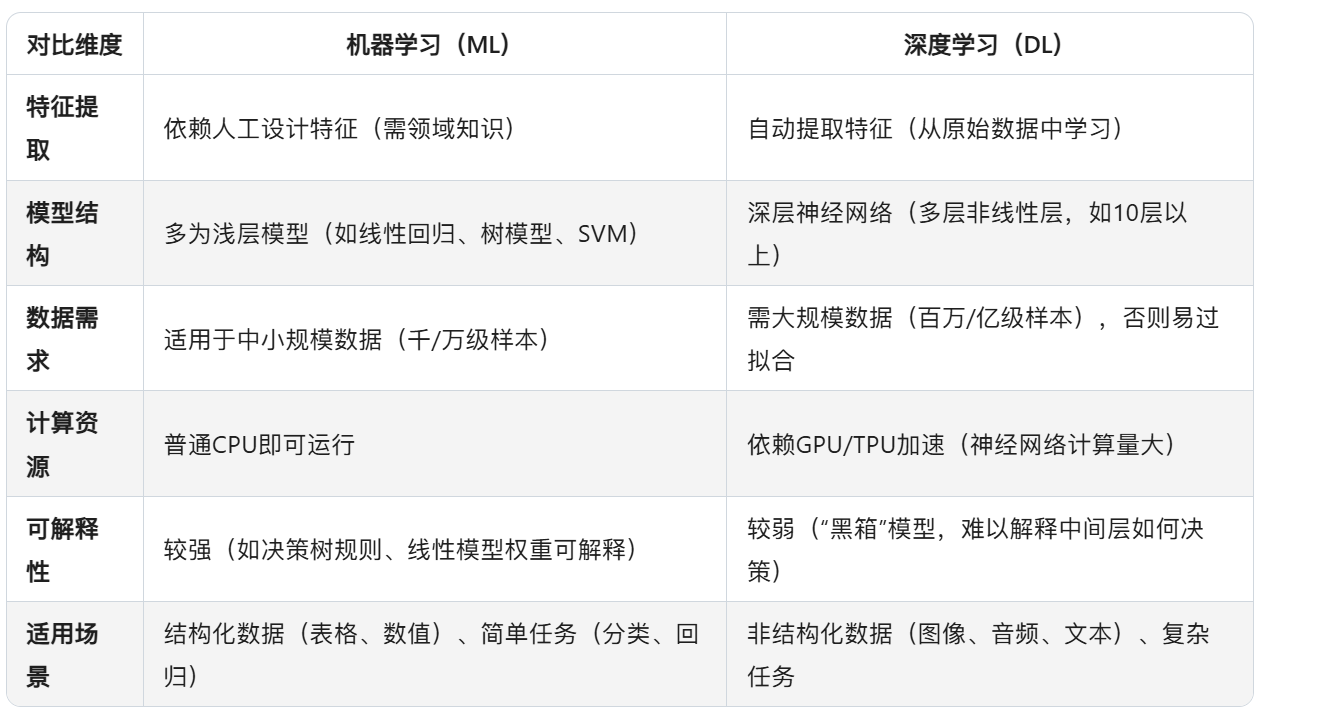
- 深度学习是机器学习的一个子集,是包含的关系。
- 深度学习的4个核心特点可概括为:自动特征提取、深层非线性结构、数据与计算密集、强拟合与黑箱性。
- 深度学习的四大应用场景覆盖了 视觉(cv)、语言(NLP)、语音、决策 领域。
7、AI项目架构分析
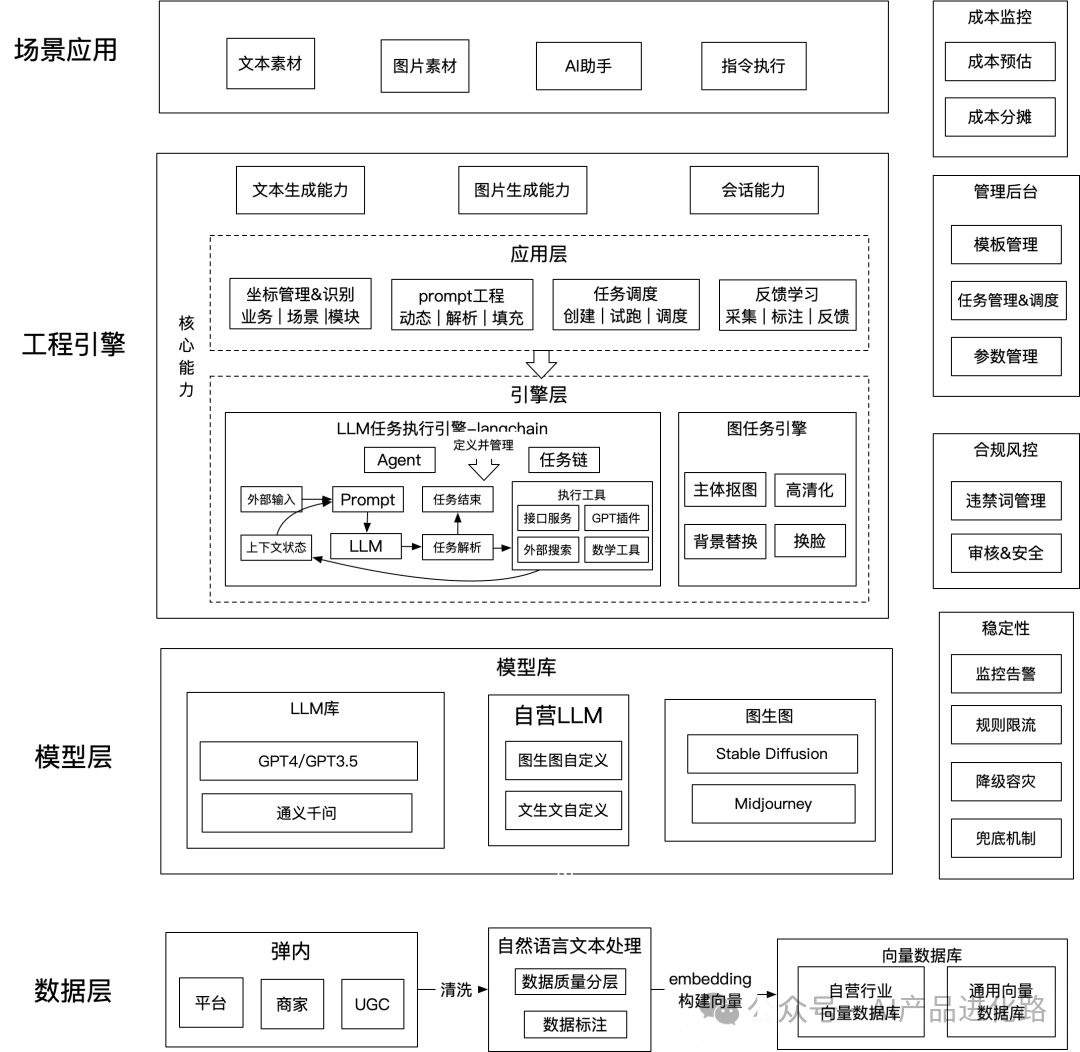
7.1、数据层:数据准备与向量化
功能:从原始数据到结构化向量,为模型提供输入。
核心流程:
-
数据采集:从平台、商家、UGC(用户生成内容)收集文本/图片素材。
-
数据清洗与标注:过滤噪声、标准化格式,标注高质量数据。
-
Embedding向量化:将文本转换为向量,存储到向量数据库(用于检索增强)。
代码示例(数据向量化与存储):
from sentence_transformers import SentenceTransformer
import chromadb # 向量数据库
# 1. 原始数据(如商家文本素材)
raw_data = [
"这是一款新品运动鞋,主打轻量化设计",
"夏季连衣裙促销,折扣力度50%",
# ...更多数据
]
# 2. 数据清洗(简化示例)
cleaned_data = [text.strip() for text in raw_data if len(text) > 5]
# 3. Embedding向量化(使用开源模型)
model = SentenceTransformer("all-MiniLM-L6-v2")
embeddings = model.encode(cleaned_data) # 转换为768维向量
# 4. 存储到向量数据库
client = chromadb.Client()
collection = client.create_collection("text_materials")
collection.add(
documents=cleaned_data,
embeddings=embeddings.tolist(),
ids=[f"doc_{i}" for i in range(len(cleaned_data))]
)
7.2、模型层:调用LLM与AIGC模型
功能:集成各类基础模型(LLM、图生图),作为能力底座。
核心流程:
- 模型选型:根据场景选择开源/闭源模型(如GPT-4、Stable Diffusion)。
- 模型封装:统一调用接口,支持多模型切换。
代码示例(模型调用封装):
import openai
from diffusers import StableDiffusionPipeline # 开源图生图模型
class ModelLibrary:
def __init__(self):
# 1. LLM模型(闭源API)
self.llm_openai = openai.OpenAI(api_key="your_key")
# 2. 图生图模型(开源本地部署)
self.sd_pipeline = StableDiffusionPipeline.from_pretrained("runwayml/stable-diffusion-v1-5")
# 3. 自定义模型(如微调的文生文模型)
self.custom_llm = ... # 加载本地微调模型
def text_generation(self, prompt, model_type="openai"):
"""文本生成统一接口"""
if model_type == "openai":
response = self.llm_openai.chat.completions.create(
model="gpt-3.5-turbo",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
elif model_type == "custom":
return self.custom_llm.generate(prompt) # 调用自定义模型
def image_generation(self, prompt, model_type="sd"):
"""图片生成统一接口"""
if model_type == "sd":
image = self.sd_pipeline(prompt).images[0]
return image # 返回PIL Image对象
7.3、引擎层:任务调度与执行(核心层)
功能:解析用户指令,调度模型和工具,完成复杂任务(对应图中“LLM任务执行引擎”“图任务引擎”)。
核心流程:
-
Prompt工程:动态解析用户输入,结合上下文生成模型输入。
-
任务链(Agent+工具):通过LangChain定义任务流程,调用外部工具(如数据库检索、数学计算)。
-
多模态任务处理:文本/图片任务分流到不同引擎。
代码示例(基于LangChain的任务调度):
from langchain.agents import initialize_agent, Tool
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 1. 初始化工具(向量数据库检索工具)
def vector_db_search(query):
"""从向量数据库检索相关文档"""
results = collection.query(query_texts=[query], n_results=3)
return "\n".join(results["documents"][0])
tools = [
Tool(
name="VectorDB",
func=vector_db_search,
description="用于检索产品素材、促销信息等文档"
)
]
# 2. 初始化LLM Agent(任务执行引擎)
model_lib = ModelLibrary()
llm_chain = LLMChain(
llm=model_lib.llm_openai, # 使用OpenAI LLM
prompt=PromptTemplate(
input_variables=["query", "context"],
template="根据上下文回答问题:{context}\n问题:{query}"
)
)
agent = initialize_agent(
tools=tools,
llm=model_lib.llm_openai,
agent="zero-shot-react-description",
verbose=True # 打印任务执行过程
)
# 3. 执行用户任务(例如:生成促销文案)
user_query = "帮我写一个夏季运动鞋的促销文案,结合轻量化特点"
result = agent.run(user_query)
print("文案生成结果:", result)
7.4、应用层:核心能力封装
功能:将引擎层的能力封装为“文本生成”“图片生成”“会话能力”等标准化接口,供上层调用。
核心流程:
- 能力抽象:将复杂引擎逻辑封装为简单API。
- 反馈学习:收集用户反馈,优化模型输出。
代码示例(能力封装为API):
from fastapi import FastAPI
app = FastAPI()
class AppLayer:
def __init__(self):
self.model_lib = ModelLibrary()
self.engine = agent # 复用引擎层的Agent
def generate_text(self, prompt, use_context=True):
"""文本生成能力接口"""
if use_context:
# 调用引擎层的Agent(带工具检索)
return self.engine.run(prompt)
else:
# 直接调用LLM(无上下文检索)
return self.model_lib.text_generation(prompt)
def generate_image(self, prompt, style="realistic"):
"""图片生成能力接口"""
if style == "cartoon":
prompt = f"卡通风格: {prompt}"
return self.model_lib.image_generation(prompt)
# 实例化应用层
app_layer = AppLayer()
# 4. 暴露API接口(供场景应用调用)
@app.post("/api/generate/text")
def api_generate_text(prompt: str):
return {"result": app_layer.generate_text(prompt)}
@app.post("/api/generate/image")
def api_generate_image(prompt: str):
image = app_layer.generate_image(prompt)
return {"image_url": save_image_to_storage(image)} # 保存图片并返回URL
7.5、场景应用层:用户交互与功能落地
功能:面向最终用户,提供文本素材生成、图片素材生成、AI助手等场景化功能。
核心流程:
- 用户输入:接收文本/指令(如“生成促销文案”)。
- 调用应用层API:将用户需求转换为应用层接口调用。
- 结果返回:展示生成的文本/图片,支持用户反馈。
代码示例(简化的Web交互):
# 前端(简化示例,实际为Vue/React页面)
def user_interface():
user_input = input("请输入需求(如“生成夏季运动鞋促销文案”):")
# 调用应用层API
response = requests.post(
"http://localhost:8000/api/generate/text",
json={"prompt": user_input}
)
print("生成结果:", response.json()["result"])
# 运行用户交互
if __name__ == "__main__":
user_interface()
真实的场景会使用大模型来分析用户意图:
import openai
def analyze_intent_with_llm(user_input: str) -> str:
"""用GPT-4分析用户意图"""
response = openai.chat.completions.create(
model="gpt-4",
messages=[
{"role": "system", "content": "判断用户想生成文本还是图片,只返回text或image"},
{"role": "user", "content": user_input}
],
max_tokens=10
)
return response.choices[0].message.content.lower()
# 测试示例
print(analyze_intent_with_llm("需要一张风景图作为封面")) # 输出: image
print(analyze_intent_with_llm("润色这段文字")) # 输出: text
推荐混合使用:
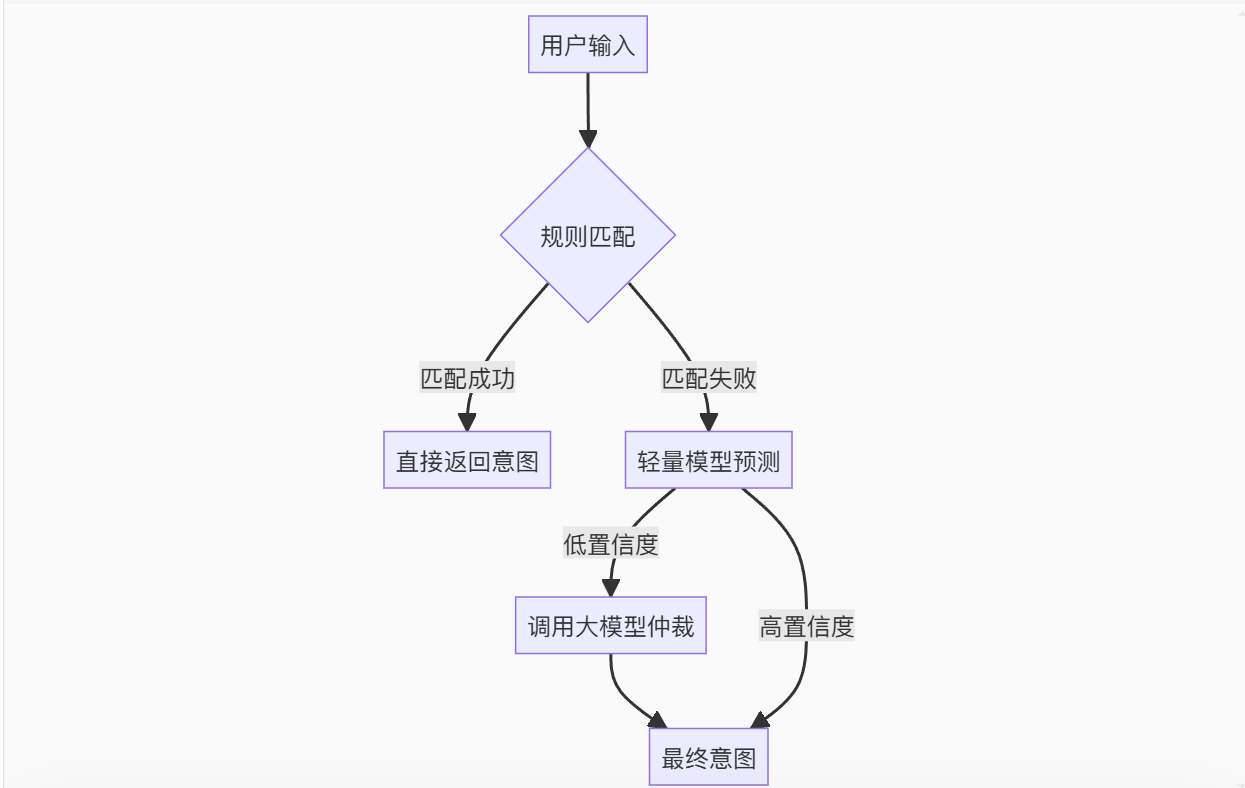
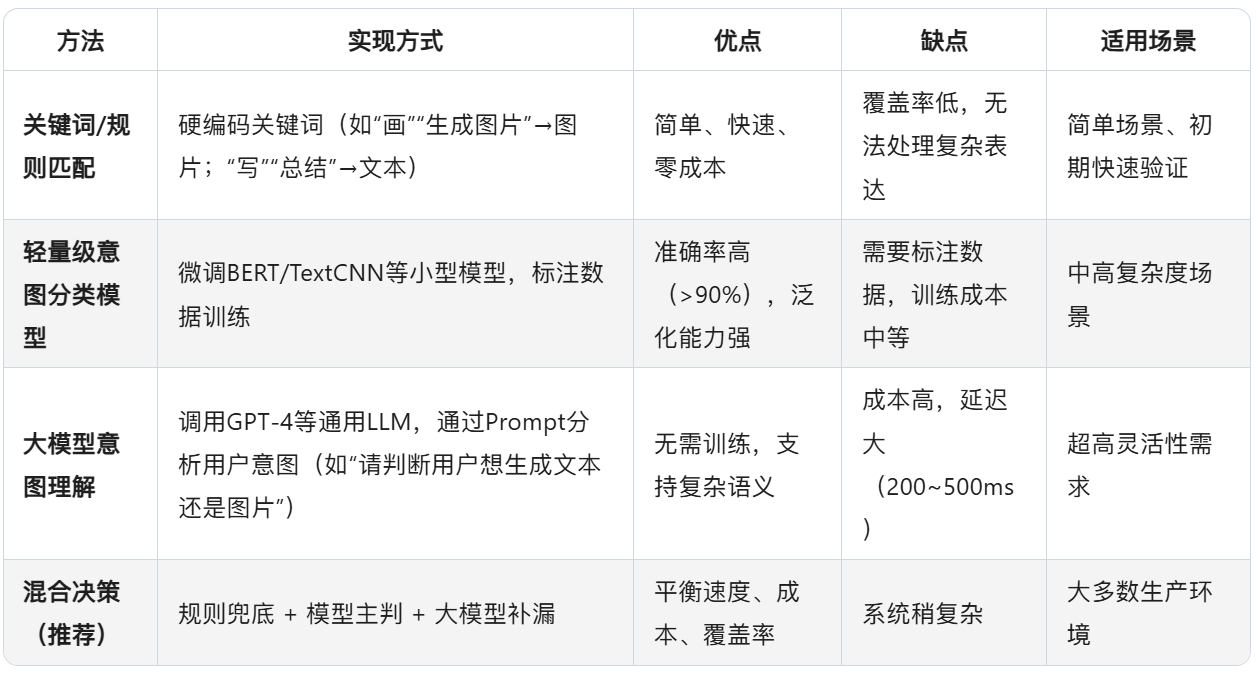
8、RAG知识库文档如何更新
8.1、更新场景
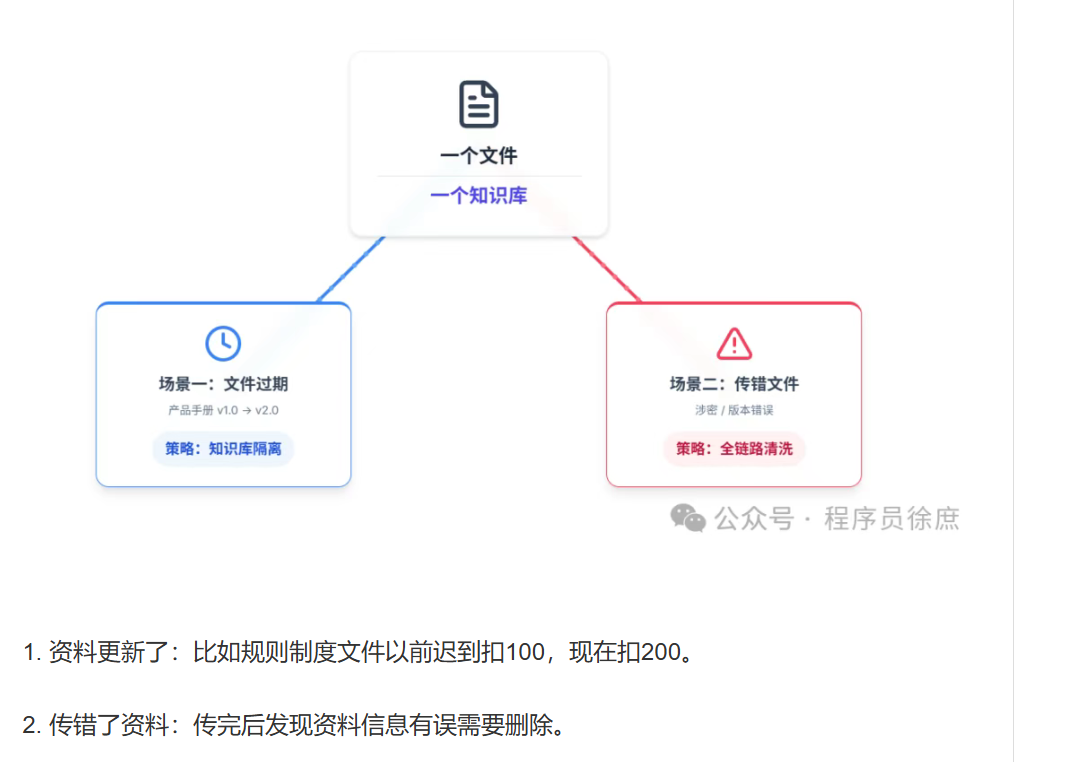
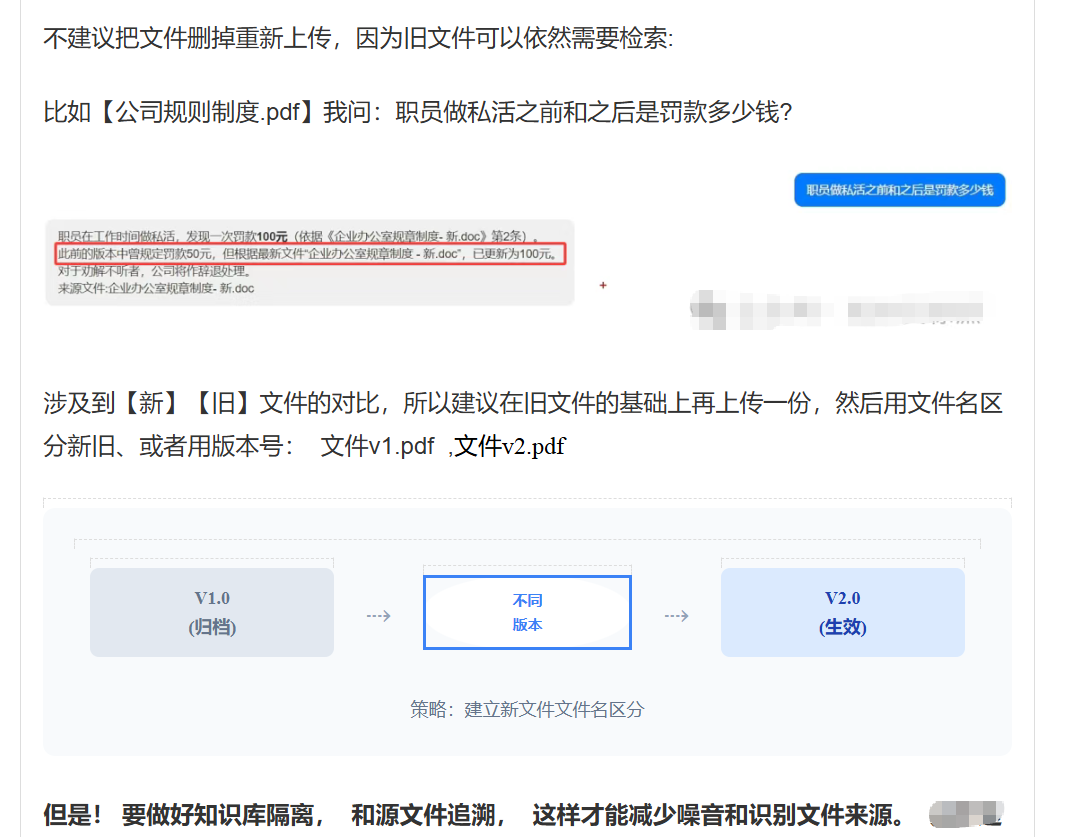
8.2、场景一:资料更新了
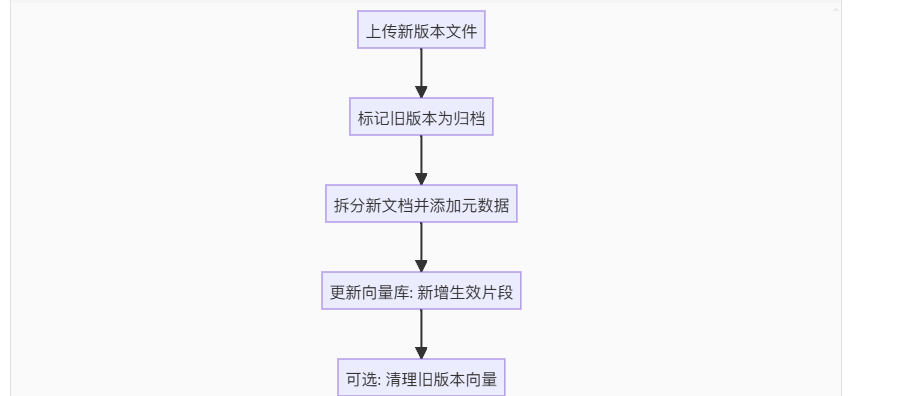
8.3、场景二:资料上传错了
当遇到“传错文件”时(比如误传了薪资表),只在业务表里删除记录是不够的。如果向量库里还有残留的切片,用户依然能通过语义搜索“钓”出敏感数据。
我们需要一种“全链路清洗”机制,像狙击手一样精准清除。



有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 3
3 0
0- 0



 已为社区贡献18条内容
已为社区贡献18条内容

所有评论(0)