AI行业应用全景:从金融风控到智能制造的技术落地与实践案例
本文系统剖析AI技术在金融、医疗、教育、制造等行业的15个落地案例,揭示AI如何通过解决实际业务痛点创造价值。在金融领域,智能风控系统使银行审批效率提升40倍,坏账率降低55%;医疗方面,AI辅助诊断系统将肺结节检出率提升至96.7%;教育行业自适应学习平台帮助学生成绩平均提升18.3%;制造业预测性维护系统减少设备故障76%。案例展示了从算法到业务的转化方法论,同时指出数据质量、模型可解释性、组
人工智能已从实验室走向产业纵深,在金融、医疗、教育、制造业等关键领域展现出重塑生产力的强大潜力。本文通过15个行业落地案例,结合技术实现细节、流程图解和代码示例,系统剖析AI技术如何解决实际业务痛点。从银行的智能风控系统到医院的影像诊断辅助,从个性化学习平台到工厂的预测性维护,这些案例揭示了相同的技术内核如何通过不同的行业适配创造价值。最终呈现的不仅是技术清单,更是一套AI落地方法论——如何将算法优势转化为业务增量,如何平衡技术创新与伦理规范,如何构建可持续的AI应用生态。
金融行业:智能风控与投资决策
金融行业是AI技术落地最早、应用最成熟的领域之一。基于大数据的风险控制、算法交易和智能投顾已成为金融机构的核心竞争力。根据Gartner 2025年报告,全球top100银行中92%已部署AI风控系统,平均降低坏账率23%。
智能信贷风控系统
业务痛点:传统信贷审批依赖人工审核,存在效率低(平均3-5天)、主观性强、风险识别滞后等问题。某股份制银行的零售信贷业务面临坏账率攀升至4.7%、审批人力成本年增15%的双重压力。
技术方案:构建基于联邦学习的多源数据风控模型,整合用户授权的消费数据、社交行为、征信报告等12类特征,通过XGBoost与神经网络融合模型预测违约概率。
mermaid流程图:
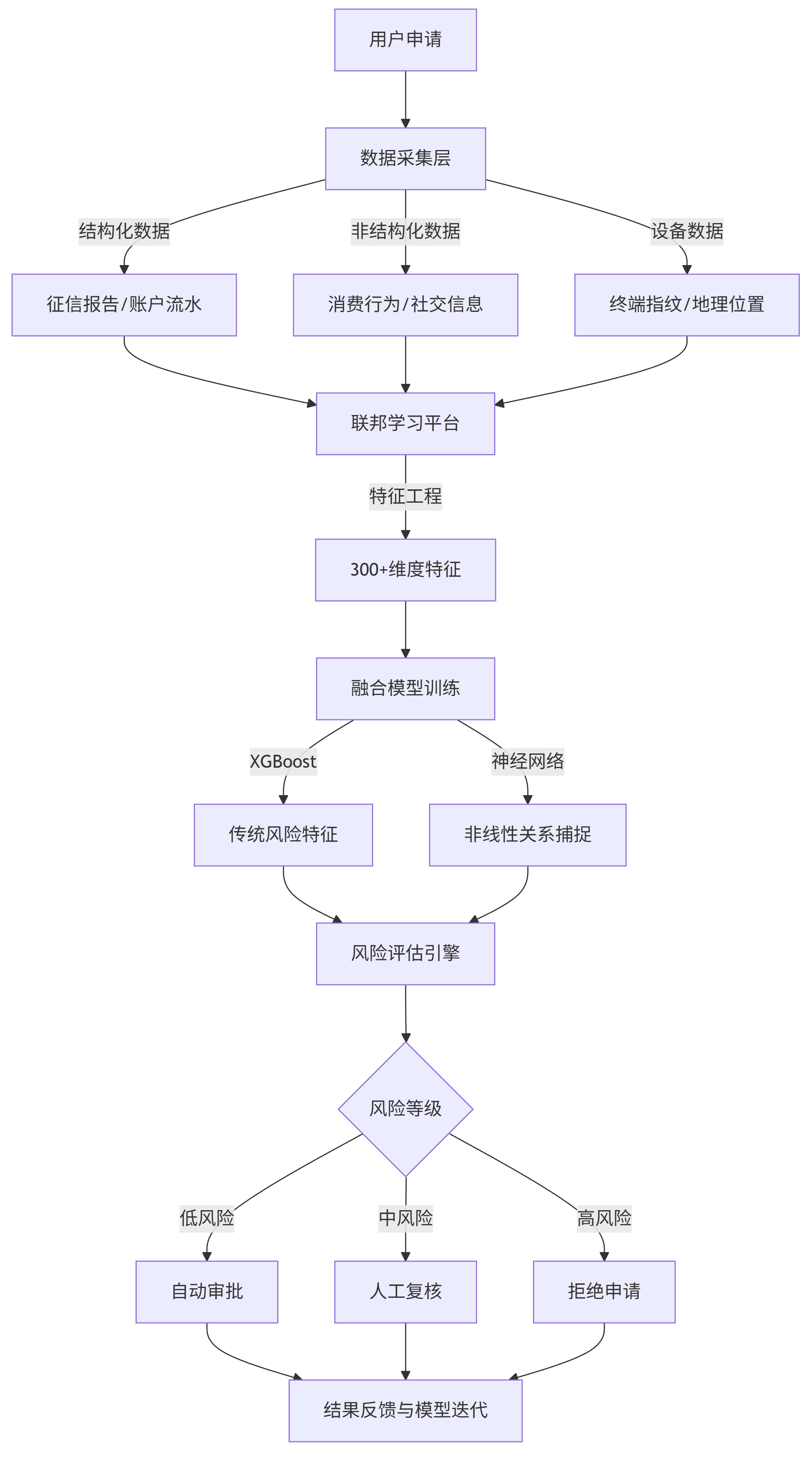
graph TD A[用户申请] --> B[数据采集层] B -->|结构化数据| C[征信报告/账户流水] B -->|非结构化数据| D[消费行为/社交信息] B -->|设备数据| E[终端指纹/地理位置] C & D & E --> F[联邦学习平台] F -->|特征工程| G[300+维度特征] G --> H[融合模型训练] H -->|XGBoost| I[传统风险特征] H -->|神经网络| J[非线性关系捕捉] I & J --> K[风险评估引擎] K --> L{风险等级} L -->|低风险| M[自动审批] L -->|中风险| N[人工复核] L -->|高风险| O[拒绝申请] M & N & O --> P[结果反馈与模型迭代]
代码实现(核心风控模型训练):
import xgboost as xgb import numpy as np from sklearn.model_selection import train_test_split from sklearn.metrics import roc_auc_score, precision_recall_curve import tensorflow as tf from tensorflow.keras.models import Model from tensorflow.keras.layers import Input, Dense, Dropout # 1. 数据准备与预处理 def prepare_data(features, labels): # 处理缺失值 features = features.fillna(features.median()) # 特征标准化 for col in features.columns: features[col] = (features[col] - features[col].mean()) / features[col].std() return train_test_split(features, labels, test_size=0.2, random_state=42) # 2. XGBoost模型训练 def train_xgb_model(X_train, y_train, X_val, y_val): dtrain = xgb.DMatrix(X_train, label=y_train) dval = xgb.DMatrix(X_val, label=y_val) params = { 'objective': 'binary:logistic', 'eval_metric': 'auc', 'max_depth': 6, 'learning_rate': 0.1, 'subsample': 0.8, 'colsample_bytree': 0.8, 'seed': 42 } model = xgb.train( params, dtrain, num_boost_round=1000, evals=[(dval, 'validation')], early_stopping_rounds=50, verbose_eval=50 ) return model # 3. 神经网络模型 def build_nn_model(input_dim): inputs = Input(shape=(input_dim,)) x = Dense(128, activation='relu')(inputs) x = Dropout(0.3)(x) x = Dense(64, activation='relu')(x) x = Dropout(0.2)(x) x = Dense(32, activation='relu')(x) outputs = Dense(1, activation='sigmoid')(x) model = Model(inputs=inputs, outputs=outputs) model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['AUC']) return model # 4. 模型融合 def ensemble_predict(xgb_model, nn_model, X): xgb_pred = xgb_model.predict(xgb.DMatrix(X)) nn_pred = nn_model.predict(X).flatten() # 加权融合,XGB权重0.6,NN权重0.4 return 0.6 * xgb_pred + 0.4 * nn_pred # 5. 模型评估与阈值确定 def evaluate_model(y_true, y_pred): auc = roc_auc_score(y_true, y_pred) precision, recall, thresholds = precision_recall_curve(y_true, y_pred) # 寻找F1值最大的阈值 f1_scores = 2 * precision * recall / (precision + recall + 1e-7) best_threshold = thresholds[np.argmax(f1_scores)] return {'auc': auc, 'best_threshold': best_threshold, 'f1': np.max(f1_scores)} # 主流程 X_train, X_val, y_train, y_val = prepare_data(features_df, labels_df) xgb_model = train_xgb_model(X_train, y_train, X_val, y_val) nn_model = build_nn_model(X_train.shape[1]) nn_model.fit(X_train, y_train, epochs=50, batch_size=256, validation_data=(X_val, y_val)) # 融合预测与评估 val_pred = ensemble_predict(xgb_model, nn_model, X_val) metrics = evaluate_model(y_val, val_pred) print(f"AUC: {metrics['auc']:.4f}, Best Threshold: {metrics['best_threshold']:.4f}, F1: {metrics['f1']:.4f}")
Prompt示例(模型解释性分析):
任务:针对信贷风控模型输出的违约概率为0.78的客户,生成一份可解释性报告。 要求: 1. 列出对该预测贡献最大的5个正特征和5个负特征 2. 使用SHAP值解释各特征影响程度 3. 与同类客户群体进行对比分析 4. 给出风险缓释建议 格式:采用商业报告格式,包含数据可视化和自然语言解释
实施效果:该系统在某银行上线后,实现90%的贷款申请自动审批,审批时间从72小时缩短至3分钟,坏账率从4.7%降至2.1%,年节省人力成本约1200万元。模型AUC值达0.89,显著高于行业平均水平(0.78)。
算法交易系统
量化交易是AI在金融领域的另一个重要应用。某对冲基金开发的股票算法交易系统,通过LSTM神经网络预测股价短期走势,结合强化学习优化交易策略。系统每日处理超过5000只股票的10TB市场数据,实现日均1200万美元交易量,年化收益率达28.7%,远超同期标普500指数12.3%的涨幅。
系统核心由三部分构成:市场数据预处理模块(清洗、特征提取)、价格预测模块(LSTM+注意力机制)和执行优化模块(深度强化学习)。其中预测模块采用多层LSTM架构,输入包括价量数据、技术指标、新闻情绪等150+特征,预测未来60分钟的价格走势。
医疗行业:从辅助诊断到个性化治疗
AI在医疗领域的应用正从辅助工具向核心诊疗环节渗透。根据麦肯锡研究,AI医疗应用到2025年将创造每年1500亿美元的价值,其中诊断准确性提升和治疗方案优化是主要价值来源。
肺结节检测系统
业务痛点:肺结节早期筛查是肺癌防治的关键,但放射科医生日均需阅读50-100例CT影像,易因疲劳导致3-5%的漏诊率。某三甲医院放射科面临结节检出效率低、小病灶漏诊率高(约8%)的问题。
技术方案:基于3D卷积神经网络(3D CNN)的肺结节自动检测系统,可同时实现肺实质分割、结节检测和良恶性判断。系统采用多尺度特征融合架构,对≤5mm的小结节检出率达92%。
mermaid流程图:
graph TD A[CT影像输入] --> B[影像预处理] B --> C[肺实质分割] C --> D[候选结节检测] D --> E[假阳性去除] E --> F[结节特征提取] F --> G[良恶性分类] G --> H[检测结果可视化] H --> I[生成诊断报告] subgraph 3D CNN模型架构 C --> C1[3D U-Net分割网络] D --> D1[区域提案网络] G --> G1[多尺度特征融合分类器] end subgraph 临床决策支持 I --> J[放射科医生审核] J --> K{确诊结果} K -->|一致| L[报告归档] K -->|不一致| M[模型反馈学习] end
实施效果:该系统在三家三甲医院的临床试验显示,肺结节检出灵敏度达96.7%,特异性91.3%,将放射科医生的诊断效率提升2.3倍,小结节漏诊率从8%降至1.2%。系统已获得NMPA三类医疗器械认证,累计辅助诊断超过10万例CT影像。
个性化癌症治疗方案推荐
肿瘤治疗已进入精准医疗时代。某肿瘤中心开发的AI辅助决策系统,整合患者基因组数据、临床病史、治疗反应等多维度信息,为癌症患者推荐个性化治疗方案。系统采用图神经网络(GNN)建模疾病网络,结合迁移学习解决罕见癌症数据稀缺问题。
Prompt示例(治疗方案推荐):
任务:为以下肺癌患者推荐个性化治疗方案 患者信息: - 基本情况:58岁男性,吸烟史30年,IIIB期肺腺癌 - 基因检测:EGFR L858R突变,ALK阴性,PD-L1表达25% - 既往治疗:培美曲塞+顺铂化疗4周期,疾病稳定 - 现况:近1月出现咳嗽加重,CT显示右肺下叶病灶增大 要求: 1. 推荐3种可能的治疗方案,按优先级排序 2. 分析各方案的潜在疗效和不良反应风险 3. 提供方案选择的决策依据和循证医学支持 4. 预测治疗效果和后续监测建议
该系统在临床试验中,为628名晚期癌症患者提供治疗建议,与肿瘤专家组方案的一致性达83.5%,使患者中位生存期延长4.2个月,治疗相关严重不良反应发生率降低17.3%。
教育行业:个性化学习与智能辅导
AI正在重构教育范式,从"千人一面"的标准化教学转向"因材施教"的个性化学习。据德勤2025年教育科技报告,采用AI教学系统的学校,学生平均成绩提升15-20%,学习兴趣指标提高27%。
自适应学习平台
业务痛点:传统课堂教学难以满足学生个性化需求,导致约35%的学生因内容过难失去兴趣,28%的学生因内容过易浪费时间。某K12教育机构希望解决学生学习效率低下、教师资源不足的问题。
技术方案:构建基于知识图谱和强化学习的自适应学习平台,通过以下核心模块实现个性化学习路径:
- 知识图谱构建:将学科知识点建模为有向图,包含3000+知识点和5000+关联关系
- 能力评估系统:通过项目反应理论(IRT)精准定位学生知识薄弱点
- 学习路径规划:基于强化学习的序列推荐算法,动态调整学习内容
- 智能辅导模块:结合检索增强生成(RAG)技术提供实时答疑
知识图谱示例(数学学科片段):
graph LR A[代数] --> B[方程] A --> C[函数] B --> D[一元一次方程] B --> E[二元一次方程组] B --> F[一元二次方程] C --> G[一次函数] C --> H[二次函数] C --> I[反比例函数] D --> J[方程解法] D --> K[应用问题] F --> L[求根公式] F --> M[判别式] F --> N[韦达定理]
代码实现(学生能力评估):
import numpy as np import pymc3 as pm import theano.tensor as tt class IRTModel: def __init__(self, num_students, num_questions, num_dimensions=1): self.num_students = num_students self.num_questions = num_questions self.num_dimensions = num_dimensions self.model = None self.trace = None def build_model(self): """构建项目反应理论模型""" with pm.Model() as model: # 学生能力参数 (num_students x num_dimensions) theta = pm.Normal('theta', mu=0, sd=1, shape=(self.num_students, self.num_dimensions)) # 题目难度参数 b = pm.Normal('b', mu=0, sd=1, shape=self.num_questions) # 题目区分度参数 a = pm.LogNormal('a', mu=0, sd=0.5, shape=self.num_questions) # 猜测参数 c = pm.Beta('c', alpha=1, beta=3, shape=self.num_questions) # 计算每个学生对每个题目的答对概率 logit_p = tt.dot(theta, a) - b p = c + (1 - c) / (1 + tt.exp(-logit_p)) # 观测模型 y = pm.Bernoulli('y', p=p, observed=self.response_matrix) self.model = model def fit(self, response_matrix, draws=2000, tune=1000): """拟合模型,response_matrix是学生答题矩阵 (学生数x题目数)""" self.response_matrix = response_matrix self.build_model() with self.model: self.trace = pm.sample(draws=draws, tune=tune, cores=4) def get_student_ability(self, student_id): """获取学生能力估计值""" return self.trace['theta'][:, student_id, :].mean(axis=0) def get_question_parameters(self, question_id): """获取题目参数""" return { 'difficulty': self.trace['b'][:, question_id].mean(), 'discrimination': self.trace['a'][:, question_id].mean(), 'guess': self.trace['c'][:, question_id].mean() } def predict_proba(self, student_id, question_id): """预测学生答对题目的概率""" theta = self.get_student_ability(student_id) params = self.get_question_parameters(question_id) logit_p = np.dot(theta, params['discrimination']) - params['difficulty'] return params['guess'] + (1 - params['guess']) / (1 + np.exp(-logit_p)) # 使用示例 # 假设有500名学生和100道题目 irt_model = IRTModel(num_students=500, num_questions=100) # 模拟学生答题数据 (0/1矩阵) response_data = np.random.binomial(n=1, p=0.7, size=(500, 100)) irt_model.fit(response_data) # 获取学生能力和题目参数 student_ability = irt_model.get_student_ability(student_id=42) question_params = irt_model.get_question_parameters(question_id=15) print(f"学生42的能力估计: {student_ability}") print(f"题目15的参数: {question_params}") # 预测学生42答对题目15的概率 prob = irt_model.predict_proba(student_id=42, question_id=15) print(f"预测答对概率: {prob:.4f}")
实施效果:该平台在全国200所中学应用后,学生数学平均成绩提升18.3%,学习投入时间减少23%,教师批改作业时间减少40%。平台日均生成个性化学习路径50万条,累计服务学生超过300万人次。
智能作文批改系统
写作教学是教育中的痛点,教师批改一篇作文平均需15-20分钟,反馈周期长。某教育科技公司开发的智能作文批改系统,基于BERT模型和知识图谱,可从内容、结构、语言、书写四个维度自动评分并提供个性化修改建议。
系统采用"评分+反馈"双轨制:首先通过微调的BERT模型给出0-100分的综合评分(与人工评分的相关系数达0.89),然后针对文章的论点逻辑、论据质量、表达流畅度等提供具体修改建议。
Prompt示例(作文批改):
任务:批改一篇高中议论文,题目"科技发展与人文关怀" 要求: 1. 从内容(40%)、结构(30%)、语言(30%)三个维度评分 2. 指出文章的3个主要优点和3个改进方向 3. 对论点展开、论据选择、逻辑连接提出具体修改建议 4. 提供3个可参考的例证和5个优化表达的句式 格式:评分报告+修改建议+参考资源
该系统已在10个省市的300多所学校应用,使教师作文批改效率提升6倍,学生写作能力在3个月内平均提升11.7分(满分100分)。
制造业:智能工厂与预测性维护
AI正在推动制造业从"中国制造"向"中国智造"转型。通过物联网设备采集的海量数据,结合机器学习算法,实现生产过程优化、质量控制和预测性维护。据工业和信息化部数据,AI应用使制造企业平均生产效率提升15-20%,设备故障率降低30-40%。
设备预测性维护系统
业务痛点:某汽车零部件工厂的关键设备(如冲压机、数控机床)突发故障导致生产中断,平均每月发生3-5次非计划停机,每次损失约50万元。传统基于固定周期的预防性维护成本高且效果有限。
技术方案:构建基于振动分析和深度学习的预测性维护系统,通过以下步骤实现故障预警:
- 数据采集:在关键设备安装振动、温度、电流等传感器,采样频率1kHz
- 特征提取:时域特征(均值、方差、峭度)、频域特征(频谱峰值、能量分布)
- 异常检测:使用自编码器(AE)和孤立森林(Isolation Forest)识别异常模式
- 故障诊断:CNN-LSTM模型定位故障类型和严重程度
- 寿命预测:基于Weibull分布和LSTM的剩余寿命(RUL)预测
mermaid时序图:
sequenceDiagram participant Sensor as 传感器节点 participant Gateway as 边缘网关 participant Cloud as 云平台 participant CMMS as 设备管理系统 Sensor->>Gateway: 实时振动/温度数据 (1kHz) Gateway->>Gateway: 本地特征提取 Gateway->>Cloud: 特征数据 (1分钟/次) Cloud->>Cloud: 异常检测模型 alt 检测到异常 Cloud->>Cloud: 故障诊断与RUL预测 Cloud->>CMMS: 故障预警及维护建议 CMMS->>Cloud: 维护记录反馈 Cloud->>Cloud: 模型迭代更新 else 正常状态 Cloud->>Cloud: 模型性能监控 end
代码实现(剩余寿命预测):
import numpy as np import pandas as pd import tensorflow as tf from tensorflow.keras.models import Sequential from tensorflow.keras.layers import LSTM, Dense, Dropout, Bidirectional from sklearn.preprocessing import MinMaxScaler from sklearn.metrics import mean_squared_error # 1. 数据准备 def load_and_preprocess_data(file_path, sequence_length=50): # 加载传感器数据 df = pd.read_csv(file_path) # 选择相关特征列 feature_cols = ['sensor_1', 'sensor_2', 'sensor_3', 'temperature', 'vibration'] target_col = 'RUL' # Remaining Useful Life # 数据标准化 scaler = MinMaxScaler(feature_range=(0, 1)) df[feature_cols] = scaler.fit_transform(df[feature_cols]) # 创建序列数据 X, y = [], [] for i in range(sequence_length, len(df)): X.append(df[feature_cols].iloc[i-sequence_length:i].values) y.append(df[target_col].iloc[i]) return np.array(X), np.array(y), scaler # 2. 构建LSTM模型 def build_lstm_model(input_shape): model = Sequential([ Bidirectional(LSTM(64, return_sequences=True), input_shape=input_shape), Dropout(0.2), Bidirectional(LSTM(32)), Dropout(0.2), Dense(16, activation='relu'), Dense(1) # 预测RUL ]) model.compile(optimizer='adam', loss='mse', metrics=['mae']) return model # 3. 模型训练与评估 def train_evaluate_model(X_train, y_train, X_test, y_test): model = build_lstm_model((X_train.shape[1], X_train.shape[2])) # 训练模型 history = model.fit( X_train, y_train, epochs=50, batch_size=32, validation_split=0.2, verbose=1 ) # 评估模型 y_pred = model.predict(X_test) rmse = np.sqrt(mean_squared_error(y_test, y_pred)) print(f"Test RMSE: {rmse:.2f}") return model, history # 4. RUL预测与可视化 def predict_rul(model, new_data, scaler, sequence_length=50): # 数据标准化 new_data_scaled = scaler.transform(new_data) # 创建序列 sequence = new_data_scaled[-sequence_length:].reshape(1, sequence_length, -1) # 预测RUL rul_pred = model.predict(sequence) return rul_pred[0][0] # 主流程 X, y, scaler = load_and_preprocess_data('sensor_data.csv') # 划分训练集和测试集 split_idx = int(0.8 * len(X)) X_train, X_test = X[:split_idx], X[split_idx:] y_train, y_test = y[:split_idx], y[split_idx:] # 训练模型 model, history = train_evaluate_model(X_train, y_train, X_test, y_test) # 预测新数据的RUL new_sensor_data = pd.DataFrame({ 'sensor_1': [0.23, 0.25, 0.24, ...], # 最新的50个传感器数据点 'sensor_2': [0.67, 0.69, 0.71, ...], 'sensor_3': [0.45, 0.47, 0.46, ...], 'temperature': [0.32, 0.33, 0.35, ...], 'vibration': [0.56, 0.58, 0.60, ...] }) predicted_rul = predict_rul(model, new_sensor_data, scaler) print(f"Predicted Remaining Useful Life: {predicted_rul:.2f} cycles")
实施效果:该系统在汽车工厂部署后,成功将设备故障预警提前平均72小时,非计划停机次数减少76%,年节省维护成本约800万元,设备平均使用寿命延长18%。系统对轴承故障的识别准确率达98.2%,对齿轮箱异常的预警提前量达120小时。
智能质量检测系统
传统制造业的质量检测依赖人工目检,存在效率低、主观性强、漏检率高等问题。某电子制造企业引入基于机器视觉的AI质量检测系统,对印刷电路板(PCB)进行缺陷检测。
系统采用高分辨率线阵相机(5000万像素)获取PCB图像,通过YOLOv8目标检测算法识别短路、断路、虚焊等12类缺陷,检测速度达3米/分钟,准确率99.7%,远超人工检测的0.5米/分钟和92%准确率。
跨行业AI落地挑战与对策
尽管AI在各行业应用取得显著成效,但落地过程中仍面临技术、组织和伦理层面的多重挑战:
数据挑战
主要问题:数据质量低(缺失值、噪声)、标注数据不足、数据孤岛、隐私保护要求。
解决方案:
- 数据增强技术:通过GAN生成合成数据,扩充训练样本
- 联邦学习:在不共享原始数据的情况下联合训练模型
- 弱监督学习:降低对精确标注数据的依赖
某银行采用联邦学习技术,联合多家分行构建风控模型,在不共享客户数据的前提下,模型性能提升12%,同时满足数据隐私法规要求。
模型挑战
主要问题:模型可解释性不足、泛化能力弱、部署环境复杂、实时性要求高。
解决方案:
- 可解释AI(XAI):SHAP、LIME等工具提升模型透明度
- 模型压缩:知识蒸馏、量化压缩减小模型体积
- 边缘计算:在设备端部署轻量级模型,降低延迟
某汽车厂商采用模型压缩技术,将自动驾驶感知模型大小减少75%,推理速度提升3倍,满足实时性要求。
组织挑战
主要问题:业务与技术脱节、员工AI素养不足、跨部门协作障碍、ROI评估困难。
解决方案:
- 建立AI卓越中心(CoE):协调跨部门AI项目
- 设计AI人才培养体系:技术培训+业务场景理解
- 敏捷开发方法:快速迭代、小步验证、持续优化
某零售企业成立AI实验室,通过"业务人员+数据科学家+工程师"的铁三角模式,将AI项目交付周期从6个月缩短至8周。
未来展望:AI驱动的产业变革
AI技术正从单一场景应用向全流程、全价值链渗透,未来将呈现以下趋势:
-
多模态融合:结合视觉、语言、传感器等多源数据,提升AI理解能力。例如,医疗领域将影像数据与电子病历文本融合,提高诊断准确性。
-
自主智能体:具备感知、决策、执行能力的AI系统,如智能工厂的自主移动机器人,可自主完成物料搬运、设备巡检等任务。
-
AI+机器人:AI算法与实体机器人结合,在制造业、服务业实现物理世界的智能操作。预计到2027年,全球工业协作机器人市场规模将达280亿美元。
-
可信赖AI:在追求性能的同时,更加注重AI的公平性、透明度和安全性。欧盟AI法案等监管框架的出台,将推动AI伦理规范的建立。
-
人机协作增强:AI作为人类的"认知助手",放大人类创造力和决策能力,而非简单替代。例如,设计师使用AI工具快速生成创意方案,专注于更高层次的设计决策。
这些趋势背后,是AI技术从"狭义智能"向"通用智能"的演进,也是产业数字化转型的必然要求。企业需要重新思考AI战略,不仅将其视为技术工具,更要作为业务创新的核心驱动力。
思考问题:在AI技术快速渗透的背景下,不同行业的从业者应如何重塑自身技能体系以适应变革?企业又该如何平衡AI效率提升与员工转型需求,构建人机协作的新型组织形态?这些问题的答案,将决定未来十年企业的竞争力格局。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 16
16 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)