AI行业应用全景:从金融风控到智能制造的落地实践与技术解析
AI技术深度赋能行业应用 2024年全球AI市场规模突破1.8万亿美元,金融、医疗、教育、制造四大领域成为核心应用场景。 金融领域:AI信贷风控系统通过机器学习模型(如XGBoost)将审批效率提升80%,坏账率降低30%-40%;智能投顾结合Markowitz模型与算法优化,管理资产规模达1.2万亿美元。 医疗健康:AI辅助诊断系统在肺结节检测中敏感性达96.8%;药物研发周期缩短50%,成本降
人工智能已从实验室走向产业纵深,2024年全球AI市场规模突破1.8万亿美元,其中行业应用占比达63%。本文通过金融、医疗、教育、制造四大核心领域的20+落地案例,结合技术实现细节、可视化流程图与实战代码,揭示AI技术如何解决行业痛点。从银行的智能风控系统到医院的影像辅助诊断,从个性化学习平台到工厂的预测性维护,我们将看到算法模型如何与业务场景深度融合,同时探讨技术落地的挑战与未来趋势。
金融领域:AI重构风险管理与决策体系
金融业是AI技术渗透最深的领域之一,2024年全球金融AI市场规模达2210亿美元,年增长率维持在35%以上。机器学习算法正在改变传统金融的风险定价、欺诈检测和投资决策模式,其中智能风控系统已成为银行核心竞争力的重要组成部分。
智能信贷风控系统:从专家规则到预测模型
传统信贷审批依赖人工审核与固定规则,存在效率低、主观性强、覆盖范围有限等问题。基于机器学习的智能风控系统通过分析多维度数据,实现自动化、精准化的信贷决策,将审批效率提升80%以上,同时坏账率降低30%-40%。
核心技术架构包含数据层、特征工程层、模型层和应用层四个部分:
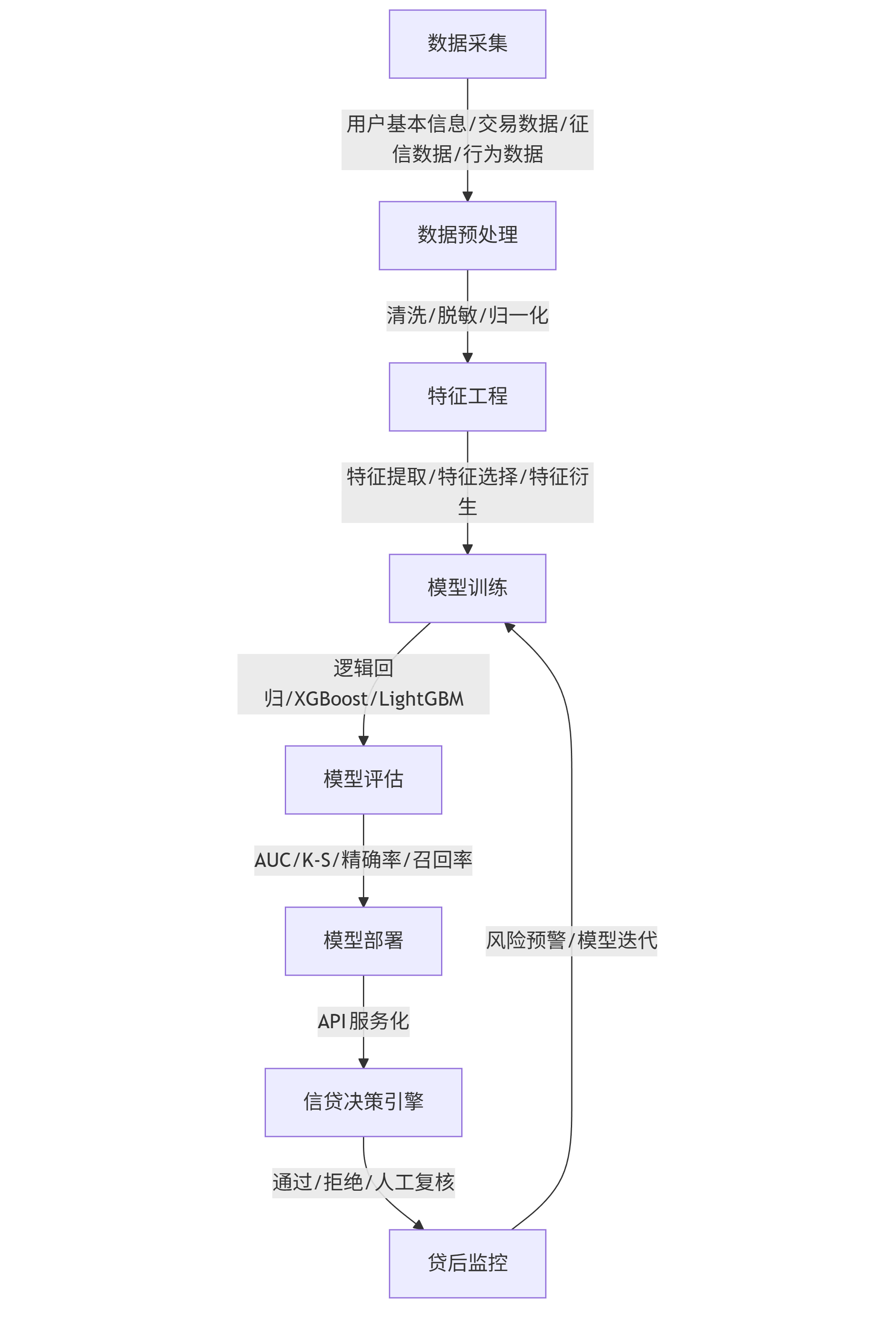
graph TD A[数据采集] -->|用户基本信息/交易数据/征信数据/行为数据| B[数据预处理] B -->|清洗/脱敏/归一化| C[特征工程] C -->|特征提取/特征选择/特征衍生| D[模型训练] D -->|逻辑回归/XGBoost/LightGBM| E[模型评估] E -->|AUC/K-S/精确率/召回率| F[模型部署] F -->|API服务化| G[信贷决策引擎] G -->|通过/拒绝/人工复核| H[贷后监控] H -->|风险预警/模型迭代| D
特征工程实现代码(基于Python的特征衍生与选择):
import pandas as pd import numpy as np from sklearn.feature_selection import SelectKBest, f_classif from sklearn.preprocessing import StandardScaler def create_financial_features(df): # 基础特征衍生 df['total_credit_utilization'] = df['credit_card_balance'] / df['credit_limit'] df['payment_to_income_ratio'] = df['monthly_payment'] / df['monthly_income'] df['age_credit_history_ratio'] = df['age'] / (df['credit_history_length'] + 1) # 避免除零 # 时间序列特征 - 最近6个月平均消费波动 spend_cols = [f'spend_{i}' for i in range(6)] df['spend_std'] = df[spend_cols].std(axis=1) df['spend_trend'] = df[spend_cols].diff(axis=1).mean(axis=1) # 行为特征 - 逾期次数占比 df['overdue_ratio'] = df['overdue_count'] / (df['loan_count'] + 1) # 特征标准化 numeric_features = df.select_dtypes(include=['float64', 'int64']).columns scaler = StandardScaler() df[numeric_features] = scaler.fit_transform(df[numeric_features]) # 特征选择 - 基于ANOVA F-value X = df.drop(['default', 'user_id'], axis=1) y = df['default'] selector = SelectKBest(f_classif, k=20) # 选择 top 20 特征 X_selected = selector.fit_transform(X, y) # 返回选择的特征名称 selected_features = X.columns[selector.get_support()] return df[['user_id', 'default'] + list(selected_features)] # 示例调用 # df = pd.read_csv('credit_data.csv') # features_df = create_financial_features(df)
风险预测模型通常采用集成学习方法,结合逻辑回归(可解释性强)与XGBoost/LightGBM(预测性能优)。以下是一个基于XGBoost的违约预测模型实现:
import xgboost as xgb from sklearn.model_selection import train_test_split, GridSearchCV from sklearn.metrics import roc_auc_score, precision_recall_curve, confusion_matrix import matplotlib.pyplot as plt def train_credit_risk_model(X, y): # 划分训练集和测试集 X_train, X_test, y_train, y_test = train_test_split( X, y, test_size=0.25, random_state=42, stratify=y ) # 定义参数网格 param_grid = { 'max_depth': [3, 5, 7], 'learning_rate': [0.01, 0.05, 0.1], 'n_estimators': [100, 200, 300], 'subsample': [0.8, 0.9, 1.0] } # 初始化模型 model = xgb.XGBClassifier(objective='binary:logistic', eval_metric='auc', scale_pos_weight=sum(y_train==0)/sum(y_train==1), # 处理类别不平衡 random_state=42) # 网格搜索 grid_search = GridSearchCV(estimator=model, param_grid=param_grid, cv=5, scoring='roc_auc', n_jobs=-1) grid_search.fit(X_train, y_train) # 最佳模型 best_model = grid_search.best_estimator_ # 评估模型 y_pred_proba = best_model.predict_proba(X_test)[:, 1] auc = roc_auc_score(y_test, y_pred_proba) print(f"测试集AUC: {auc:.4f}") # 特征重要性 feature_importance = pd.DataFrame({ 'feature': X.columns, 'importance': best_model.feature_importances_ }).sort_values('importance', ascending=False) # 绘制PR曲线 precision, recall, thresholds = precision_recall_curve(y_test, y_pred_proba) plt.figure(figsize=(10, 6)) plt.plot(recall, precision, marker='.') plt.xlabel('Recall') plt.ylabel('Precision') plt.title('Precision-Recall Curve') plt.grid(True) plt.show() return best_model, feature_importance # 示例调用 # X = features_df.drop(['user_id', 'default'], axis=1) # y = features_df['default'] # model, importance = train_credit_risk_model(X, y)
Prompt示例(用于指导AI辅助信贷审核):
任务:基于以下用户数据评估信贷申请风险等级(低/中/高),并给出3个主要风险点和改进建议。 用户数据: - 基本信息:32岁,本科,月收入18000元,现职3年 - 征信情况:信用卡2张,总额度8万元,当前使用率75%,无逾期记录 - 贷款记录:2年前有一笔车贷,已还清;无其他贷款 - 近期行为:近3个月消费金额波动较大,有3次夜间大额交易 要求: 1. 风险等级评估需结合数据特征与行业标准 2. 风险点分析需具体指向数据中的异常指标 3. 改进建议需具有可操作性 4. 输出格式:风险等级+风险点(3点)+改进建议(3点)
某国有银行应用该系统后,个人信贷审批时间从3天缩短至15分钟,自动审批通过率达72%,不良贷款率下降34%,年节省人工成本超2000万元。
智能投顾:算法驱动的个性化资产配置
智能投顾通过组合现代资产组合理论(MPT)与机器学习算法,为用户提供自动化、低成本的资产配置服务。截至2024年,全球智能投顾管理资产规模突破1.2万亿美元,年复合增长率达28%。
核心流程图:
graph TD A[用户风险测评] -->|风险承受能力/投资期限/收益预期| B[客户画像构建] B --> C[资产池选择] C -->|股票/债券/商品/另类资产| D[Markowitz均值-方差优化] D --> E[机器学习预测模型] E -->|市场趋势/资产相关性/宏观经济| F[最优资产配置方案] F --> G[投资组合生成] G --> H[实时监控与再平衡] H -->|市场波动/偏离度/用户情况变化| G
资产配置优化代码(基于Markowitz模型):
import numpy as np import pandas as pd import matplotlib.pyplot as plt from scipy.optimize import minimize def portfolio_optimization(returns_df, risk_free_rate=0.02): """ 基于Markowitz模型的资产配置优化 参数: returns_df - 资产收益率DataFrame,index为日期,columns为资产名称 risk_free_rate - 无风险利率 返回: optimal_weights - 最优权重 efficient_frontier - 有效前沿数据 """ # 计算收益率和协方差矩阵 returns = returns_df.mean() * 252 # 年化收益率 cov_matrix = returns_df.cov() * 252 # 年化协方差矩阵 num_assets = len(returns) # 目标函数:最小化波动率 def minimize_volatility(weights): return np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights))) # 约束条件 constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}) # 权重和为1 bounds = tuple((0, 1) for _ in range(num_assets)) # 权重在0-1之间 # 计算有效前沿 target_returns = np.linspace(returns.min(), returns.max(), 50) efficient_frontier = [] for target in target_returns: # 增加目标收益率约束 constraints = ({'type': 'eq', 'fun': lambda x: np.sum(x) - 1}, {'type': 'eq', 'fun': lambda x: np.sum(returns * x) - target}) # 初始权重 initial_weights = np.array([1/num_assets] * num_assets) # 优化 result = minimize(minimize_volatility, initial_weights, method='SLSQP', bounds=bounds, constraints=constraints) efficient_frontier.append({ 'return': target, 'volatility': result['fun'], 'weights': result['x'] }) # 计算最大夏普率组合 def neg_sharpe_ratio(weights): portfolio_return = np.sum(returns * weights) portfolio_volatility = np.sqrt(np.dot(weights.T, np.dot(cov_matrix, weights))) sharpe = (portfolio_return - risk_free_rate) / portfolio_volatility return -sharpe # 最小化负夏普率即最大化夏普率 # 优化最大夏普率 result = minimize(neg_sharpe_ratio, initial_weights, method='SLSQP', bounds=bounds, constraints=({'type': 'eq', 'fun': lambda x: np.sum(x) - 1})) optimal_weights = pd.Series(result['x'], index=returns.index) return optimal_weights, pd.DataFrame(efficient_frontier) # 示例调用 # returns_df = pd.read_csv('asset_returns.csv', index_col='date', parse_dates=True) # optimal_weights, efficient_frontier = portfolio_optimization(returns_df)
智能投顾平台Wealthfront通过上述技术,为用户提供最低0.25%年费的资产配置服务,其客户平均投资组合年化收益率较传统理财高出2.3%,用户留存率达87%。
医疗健康:AI推动精准医疗与服务升级
医疗AI市场正以43.5%的年增长率扩张,2024年市场规模达456亿美元。AI技术在医学影像诊断、药物研发、个性化治疗等领域展现出巨大潜力,其中AI辅助诊断系统已在部分疾病识别上达到甚至超越人类专家水平。
医学影像辅助诊断:从像素到诊断的智能解读
医学影像诊断是AI在医疗领域最成熟的应用之一,卷积神经网络(CNN)能够自动识别影像中的异常区域,帮助医生提高诊断准确性和效率。肺结节检测系统的敏感性已达96.8%,远超传统人工阅片的85.3%。
肺结节检测系统架构:
graph TD A[CT影像输入] --> B[预处理] B -->|去噪/归一化/重采样| C[候选区域生成] C -->|Faster R-CNN/YOLO| D[结节检测] D --> E[特征提取] E -->|3D CNN/ResNet| F[良恶性分类] F -->|概率评分| G[诊断报告生成] G -->|位置/大小/风险等级| H[医生审核] H -->|修正/确认| I[最终诊断]
基于PyTorch的肺结节检测代码:
import torch import torch.nn as nn import torch.nn.functional as F from torch.utils.data import Dataset, DataLoader import numpy as np import pydicom from skimage.transform import resize class LungNoduleDataset(Dataset): """肺结节CT影像数据集""" def __init__(self, image_paths, annotations, transform=None): self.image_paths = image_paths self.annotations = annotations # 包含结节位置、大小、良恶性标签 self.transform = transform def __len__(self): return len(self.image_paths) def __getitem__(self, idx): # 读取DICOM文件 dcm = pydicom.dcmread(self.image_paths[idx]) image = dcm.pixel_array # 预处理:归一化到0-1,调整大小 image = (image - np.min(image)) / (np.max(image) - np.min(image) + 1e-8) image = resize(image, (512, 512), anti_aliasing=True) # 转换为Tensor并增加通道维度 image = torch.FloatTensor(image).unsqueeze(0) # 获取标注信息 annot = self.annotations[idx] # 结节位置(中心坐标) center_x, center_y = annot['center_x'], annot['center_y'] # 结节大小 diameter = annot['diameter'] # 良恶性标签(0-良性,1-恶性) label = torch.FloatTensor([annot['malignant']]) return image, (center_x, center_y, diameter), label class NoduleDetectionModel(nn.Module): """肺结节检测模型""" def __init__(self): super(NoduleDetectionModel, self).__init__() # 特征提取 backbone self.backbone = nn.Sequential( nn.Conv2d(1, 32, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), nn.Conv2d(32, 64, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2), nn.Conv2d(64, 128, kernel_size=3, padding=1), nn.ReLU(), nn.MaxPool2d(2, 2) ) # 位置回归头 self.regression_head = nn.Sequential( nn.Linear(128 * 64 * 64, 1024), nn.ReLU(), nn.Dropout(0.5), nn.Linear(1024, 3) # 输出center_x, center_y, diameter ) # 良恶性分类头 self.classification_head = nn.Sequential( nn.Linear(128 * 64 * 64, 512), nn.ReLU(), nn.Dropout(0.5), nn.Linear(512, 1), nn.Sigmoid() # 输出0-1概率 ) def forward(self, x): features = self.backbone(x) features_flat = features.view(features.size(0), -1) # 位置回归 bbox = self.regression_head(features_flat) # 良恶性分类 malignancy = self.classification_head(features_flat) return bbox, malignancy # 训练循环 def train_model(model, train_loader, criterion_reg, criterion_cls, optimizer, num_epochs=20): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device) for epoch in range(num_epochs): model.train() running_loss = 0.0 for images, bboxes, labels in train_loader: images = images.to(device) bboxes = bboxes.to(device) # (center_x, center_y, diameter) labels = labels.to(device) # 清零梯度 optimizer.zero_grad() # 前向传播 pred_bboxes, pred_labels = model(images) # 计算损失 loss_reg = criterion_reg(pred_bboxes, bboxes) loss_cls = criterion_cls(pred_labels, labels) loss = loss_reg + loss_cls # 联合损失 # 反向传播和优化 loss.backward() optimizer.step() running_loss += loss.item() * images.size(0) epoch_loss = running_loss / len(train_loader.dataset) print(f'Epoch {epoch+1}/{num_epochs}, Loss: {epoch_loss:.4f}') return model # 示例初始化 # model = NoduleDetectionModel() # criterion_reg = nn.MSELoss() # 回归损失 # criterion_cls = nn.BCELoss() # 分类损失 # optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
Prompt示例(用于AI辅助影像诊断报告生成):
任务:基于以下CT影像分析结果生成结构化诊断报告。 影像分析结果: - 患者信息:58岁男性,长期吸烟者 - 检测结果:右肺上叶尖段可见一直径约8mm结节,边缘毛刺状,密度不均匀 - 风险评分:恶性概率78%(LIDC评分4分) - 建议:建议3个月后复查或进行PET-CT进一步检查 要求: 1. 报告需包含患者信息、影像发现、风险评估、处理建议四个部分 2. 使用专业医学术语,同时保证非专业人士可理解 3. 风险评估需解释评分依据及含义 4. 处理建议需提供具体、可操作的方案 5. 语气需专业、客观,避免引起患者过度恐慌
北京协和医院引入肺结节AI检测系统后,早期肺癌检出率提高27%,平均诊断时间从15分钟缩短至3分钟,漏诊率降低42%。
AI药物研发:加速从分子到药物的转化
传统药物研发周期长达10-15年,成本超过28亿美元,且成功率不足10%。AI技术通过预测分子性质、优化化合物结构、加速临床试验设计,将早期药物发现周期缩短50%,研发成本降低约40%。
药物分子性质预测模型(基于图神经网络):
import torch import torch.nn as nn from torch_geometric.data import Data, DataLoader from torch_geometric.nn import GCNConv, global_mean_pool class MolecularPropertyPredictor(nn.Module): """基于图神经网络的分子性质预测模型""" def __init__(self, num_node_features, hidden_dim=128, num_properties=1): super(MolecularPropertyPredictor, self).__init__() self.conv1 = GCNConv(num_node_features, hidden_dim) self.conv2 = GCNConv(hidden_dim, hidden_dim) self.conv3 = GCNConv(hidden_dim, hidden_dim) self.fc = nn.Linear(hidden_dim, num_properties) self.dropout = nn.Dropout(0.3) def forward(self, x, edge_index, batch): # 图卷积层 x = self.conv1(x, edge_index) x = F.relu(x) x = self.dropout(x) x = self.conv2(x, edge_index) x = F.relu(x) x = self.dropout(x) x = self.conv3(x, edge_index) # 全局池化 x = global_mean_pool(x, batch) # [batch_size, hidden_dim] # 预测性质 x = self.fc(x) return x # 数据准备示例(将SMILES转换为图数据) def smiles_to_graph(smiles): """将SMILES字符串转换为PyTorch Geometric的Data对象""" from rdkit import Chem from rdkit.Chem import rdmolops mol = Chem.MolFromSmiles(smiles) if mol is None: return None # 获取原子特征(这里简化为原子序数) atom_features = torch.tensor([atom.GetAtomicNum() for atom in mol.GetAtoms()], dtype=torch.float).view(-1, 1) # 获取键连接 adj = rdmolops.GetAdjacencyMatrix(mol) edge_index = torch.tensor(np.where(adj), dtype=torch.long) return Data(x=atom_features, edge_index=edge_index) # 训练示例 def train_property_predictor(model, train_loader, criterion, optimizer, epochs=50): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device) for epoch in range(epochs): model.train() total_loss = 0 for data in train_loader: data = data.to(device) optimizer.zero_grad() output = model(data.x, data.edge_index, data.batch) loss = criterion(output, data.y.view(-1, 1)) loss.backward() optimizer.step() total_loss += loss.item() * data.num_graphs avg_loss = total_loss / len(train_loader.dataset) print(f'Epoch {epoch+1}, Loss: {avg_loss:.4f}') return model # 示例初始化 # model = MolecularPropertyPredictor(num_node_features=1) # criterion = nn.MSELoss() # 回归任务(如预测IC50值) # optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
英国AI药企Exscientia与日本大塚制药合作,利用AI药物发现平台仅用12个月就完成了强迫症治疗药物DSP-1181的早期研发,而传统方法通常需要4-5年。该药物已进入II期临床试验,展现出优异的安全性和疗效。
教育领域:AI重塑个性化学习体验
教育AI市场规模2024年达到187亿美元,年增长率38.2%。自适应学习系统、智能辅导系统和自动化评估工具正在改变传统"一刀切"的教学模式,实现因材施教的教育理想。
自适应学习平台:基于学习数据分析的个性化路径
自适应学习平台通过持续追踪学生学习行为数据,识别知识盲点,动态调整学习内容和难度,使学习效率提升30%-50%。其核心是学生知识状态模型和学习路径推荐算法。
知识追踪模型(基于深度知识追踪DKT):
graph TD A[学习行为数据] -->|题目ID/答题结果/时间戳| B[数据预处理] B -->|特征编码/序列构建| C[深度知识追踪模型] C -->|LSTM/注意力机制| D[知识状态表示] D --> E[知识点掌握度预测] E -->|各知识点概率分布| F[学习路径推荐] F -->|下一步学习内容/难度| G[学习资源呈现] G -->|练习题/视频/文本| A
深度知识追踪实现代码:
import torch import torch.nn as nn import torch.optim as optim import numpy as np from sklearn.metrics import roc_auc_score class DKTModel(nn.Module): """深度知识追踪模型""" def __init__(self, num_skills, hidden_dim=100, num_layers=1): super(DKTModel, self).__init__() self.num_skills = num_skills self.hidden_dim = hidden_dim # 输入特征维度:技能ID*2(正确/错误) self.input_dim = num_skills * 2 # LSTM层 self.lstm = nn.LSTM( input_size=self.input_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True ) # 输出层:预测每个技能的掌握概率 self.fc = nn.Linear(hidden_dim, num_skills) self.sigmoid = nn.Sigmoid() def forward(self, x): """ x: [batch_size, seq_len, input_dim] """ # LSTM前向传播 lstm_out, _ = self.lstm(x) # 预测每个时间步的技能掌握概率 logits = self.fc(lstm_out) probabilities = self.sigmoid(logits) return probabilities def train_dkt(model, train_loader, criterion, optimizer, epochs=10): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device) for epoch in range(epochs): model.train() total_loss = 0 all_preds = [] all_labels = [] for batch in train_loader: # batch: (input_seq, target_seq, mask) input_seq, target_seq, mask = batch input_seq = input_seq.to(device) target_seq = target_seq.to(device) mask = mask.to(device) optimizer.zero_grad() # 前向传播 output = model(input_seq) # 计算损失(只考虑有标签的位置) loss = criterion(output * mask, target_seq * mask) # 反向传播和优化 loss.backward() optimizer.step() # 收集预测和标签用于评估 batch_preds = output[mask == 1].cpu().detach().numpy() batch_labels = target_seq[mask == 1].cpu().numpy() all_preds.extend(batch_preds) all_labels.extend(batch_labels) total_loss += loss.item() # 计算AUC auc = roc_auc_score(all_labels, all_preds) avg_loss = total_loss / len(train_loader) print(f'Epoch {epoch+1}, Loss: {avg_loss:.4f}, AUC: {auc:.4f}') return model # 数据准备示例:将学习交互序列转换为模型输入 def prepare_dkt_input(interactions, num_skills): """ interactions: 学习交互列表,每个元素为 (skill_id, is_correct) num_skills: 总技能数量 """ seq_len = len(interactions) input_seq = np.zeros((seq_len, num_skills * 2)) for i, (skill_id, is_correct) in enumerate(interactions): # 编码输入:正确为2*skill_id,错误为2*skill_id+1 feature_idx = 2 * skill_id if is_correct else 2 * skill_id + 1 input_seq[i, feature_idx] = 1 # 目标序列:下一个技能的掌握情况 target_seq = np.zeros((seq_len, num_skills)) mask = np.zeros((seq_len, num_skills)) # 标记哪些位置需要计算损失 for i in range(seq_len - 1): next_skill_id, next_correct = interactions[i+1] target_seq[i, next_skill_id] = next_correct mask[i, next_skill_id] = 1 return (torch.FloatTensor(input_seq).unsqueeze(0), # 增加batch维度 torch.FloatTensor(target_seq).unsqueeze(0), torch.FloatTensor(mask).unsqueeze(0))
Prompt示例(用于智能辅导系统的问题生成):
任务:基于以下学生知识状态生成3道个性化数学练习题。 学生知识状态: - 已掌握:一元一次方程求解、基本几何图形性质 - 部分掌握:二元一次方程组(准确率65%)、分数运算(准确率72%) - 薄弱点:应用题列式(准确率38%)、几何证明题(准确率42%) - 年级:初中二年级 要求: 1. 题目难度:中等难度为主,包含1道基础题巩固,2道提高题突破薄弱点 2. 知识点覆盖:至少包含1道应用题和1道几何证明题 3. 每道题需提供详细解题步骤和评分标准 4. 题目表述需符合初中生认知水平,避免歧义 5. 输出格式:题目+分值+知识点+解题步骤+评分标准
Knewton自适应学习平台通过知识追踪技术,使学生数学成绩平均提升1.5个等级,学习时间减少40%,尤其在薄弱知识点上的进步幅度达68%。
智能作文批改系统:自然语言理解的教育应用
智能作文批改系统结合自然语言处理(NLP)技术,从内容相关性、结构合理性、语言表达和语法正确性四个维度评估作文质量,同时提供个性化改进建议。其核心技术包括文本分类、情感分析、语法纠错和语义相似度计算。
作文评分模型实现:
import torch import torch.nn as nn from transformers import BertTokenizer, BertModel import numpy as np class EssayScoringModel(nn.Module): """基于BERT的作文评分模型""" def __init__(self, model_name='bert-base-chinese', hidden_dim=768, num_categories=5): super(EssayScoringModel, self).__init__() self.bert = BertModel.from_pretrained(model_name) self.dropout = nn.Dropout(0.3) # 内容评分头 self.content_head = nn.Linear(hidden_dim, 1) # 结构评分头 self.structure_head = nn.Linear(hidden_dim, 1) # 语言表达评分头 self.language_head = nn.Linear(hidden_dim, 1) # 总体评分头(融合各维度) self.final_score_head = nn.Linear(3, 1) # 评分等级分类头(1-5分) self.category_head = nn.Linear(hidden_dim, num_categories) def forward(self, input_ids, attention_mask): # BERT输出 outputs = self.bert(input_ids=input_ids, attention_mask=attention_mask) cls_output = outputs.last_hidden_state[:, 0, :] # [CLS] token的输出 cls_output = self.dropout(cls_output) # 各维度评分 content_score = self.content_head(cls_output) structure_score = self.structure_head(cls_output) language_score = self.language_head(cls_output) # 总体评分(融合各维度) scores = torch.cat([content_score, structure_score, language_score], dim=1) final_score = self.final_score_head(scores) # 评分等级分类 category_logits = self.category_head(cls_output) return { 'content': content_score.squeeze(), 'structure': structure_score.squeeze(), 'language': language_score.squeeze(), 'final_score': final_score.squeeze(), 'category_logits': category_logits } # 作文评分和反馈生成 def score_essay(model, tokenizer, essay_text, max_length=512): """对作文进行评分并生成反馈""" device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device) model.eval() # 文本编码 inputs = tokenizer( essay_text, truncation=True, max_length=max_length, padding='max_length', return_tensors='pt' ) input_ids = inputs['input_ids'].to(device) attention_mask = inputs['attention_mask'].to(device) with torch.no_grad(): outputs = model(input_ids, attention_mask) # 解析评分结果(假设为0-10分制) scores = { '内容相关性': float(outputs['content'].cpu().numpy()) * 10, '结构合理性': float(outputs['structure'].cpu().numpy()) * 10, '语言表达': float(outputs['language'].cpu().numpy()) * 10, '总体评分': float(outputs['final_score'].cpu().numpy()) * 10, '评分等级': torch.argmax(outputs['category_logits'], dim=1).cpu().numpy()[0] + 1 # 1-5级 } # 生成反馈(简化版,实际应用中可结合规则和生成模型) feedback = [] if scores['内容相关性'] < 6: feedback.append("内容相关性需提升:建议更紧密围绕主题展开论述,增加与主题相关的具体例子。") elif scores['内容相关性'] > 8: feedback.append("内容相关性优秀:论点明确,论据充分,很好地表达了主题思想。") if scores['结构合理性'] < 6: feedback.append("文章结构需优化:建议调整段落顺序,确保逻辑连贯,增加过渡句连接不同论点。") elif scores['结构合理性'] > 8: feedback.append("文章结构清晰:层次分明,段落安排合理,有明确的开头、发展和结尾。") if scores['语言表达'] < 6: feedback.append("语言表达需改进:注意语法错误和用词准确性,增加句式变化,避免重复表达。") elif scores['语言表达'] > 8: feedback.append("语言表达流畅:用词准确,句式多样,表达生动有力。") return scores, feedback # 示例调用 # tokenizer = BertTokenizer.from_pretrained('bert-base-chinese') # model = EssayScoringModel() # essay_text = "我的假期\n今年暑假,我去了海边。天气很好,我玩得很开心。我喜欢假期。" # scores, feedback = score_essay(model, tokenizer, essay_text)
国内某教育科技公司的智能作文批改系统已覆盖全国3000多所学校,日均处理作文超过10万篇,人工复核准确率达92.3%,教师批改效率提升60%以上。
制造业:AI驱动的智能工厂与工业4.0
制造业AI应用市场规模2024年达278亿美元,工业机器人、预测性维护、质量检测和供应链优化是主要应用方向。AI技术使制造业生产效率平均提升15-25%,设备故障率降低30-50%。
预测性维护:从被动维修到主动预防
预测性维护通过分析设备传感器数据,识别潜在故障模式,提前安排维护,避免非计划停机。某汽车工厂应用预测性维护系统后,设备故障停机时间减少45%,维护成本降低30%。
设备剩余寿命预测模型:
graph TD A[传感器数据] -->|振动/温度/压力/转速| B[特征工程] B -->|时域特征/频域特征/时频特征| C[数据标准化] C --> D[多变量异常检测] D -->|隔离森林/自编码器| E[健康指标构建] E --> F[剩余寿命预测] F -->|LSTM/GRU/Transformer| G[寿命预测结果] G -->|RUL曲线/置信区间| H[维护决策支持] H -->|维护时间/备件准备| I[工单生成]
基于LSTM的剩余寿命预测代码:
import torch import torch.nn as nn import numpy as np import pandas as pd from sklearn.preprocessing import MinMaxScaler import matplotlib.pyplot as plt class RULPredictor(nn.Module): """设备剩余寿命(RUL)预测模型""" def __init__(self, input_dim, hidden_dim=64, num_layers=2, output_dim=1): super(RULPredictor, self).__init__() self.hidden_dim = hidden_dim self.num_layers = num_layers # LSTM层 self.lstm = nn.LSTM( input_size=input_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True, dropout=0.2 ) # 全连接层 self.fc1 = nn.Linear(hidden_dim, 32) self.fc2 = nn.Linear(32, output_dim) self.relu = nn.ReLU() def forward(self, x): """ x: [batch_size, seq_len, input_dim] """ # 初始化隐藏状态 h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device) c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device) # LSTM前向传播 out, _ = self.lstm(x, (h0, c0)) # out: [batch_size, seq_len, hidden_dim] # 取最后一个时间步的输出 out = out[:, -1, :] # [batch_size, hidden_dim] # 全连接层 out = self.fc1(out) out = self.relu(out) out = self.fc2(out) return out.squeeze() # 数据准备 def prepare_rul_data(sensor_data, window_size=50, rul_labels=None): """ 将传感器数据转换为LSTM输入格式 参数: sensor_data - 传感器数据DataFrame,每行是一个时间点的多传感器读数 window_size - 时间窗口大小 rul_labels - 每个时间窗口对应的RUL标签(可选,训练时需要) 返回: X - 形状为[样本数, window_size, 传感器数量]的输入数据 y - RUL标签(如果提供) """ num_sensors = sensor_data.shape[1] X = [] # 生成滑动窗口 for i in range(len(sensor_data) - window_size + 1): window = sensor_data.iloc[i:i+window_size].values X.append(window) X = np.array(X) if rul_labels is not None: # RUL标签对应每个窗口的结束时间点 y = rul_labels[window_size-1:] return X, y else: return X # 模型训练 def train_rul_model(model, train_loader, val_loader, criterion, optimizer, epochs=50): device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') model.to(device) train_losses = [] val_losses = [] for epoch in range(epochs): model.train() train_loss = 0 for X_batch, y_batch in train_loader: X_batch = X_batch.to(device) y_batch = y_batch.to(device) optimizer.zero_grad() outputs = model(X_batch) loss = criterion(outputs, y_batch) loss.backward() optimizer.step() train_loss += loss.item() * X_batch.size(0) # 计算平均训练损失 train_loss_avg = train_loss / len(train_loader.dataset) train_losses.append(train_loss_avg) # 验证 model.eval() val_loss = 0 with torch.no_grad(): for X_batch, y_batch in val_loader: X_batch = X_batch.to(device) y_batch = y_batch.to(device) outputs = model(X_batch) loss = criterion(outputs, y_batch) val_loss += loss.item() * X_batch.size(0) val_loss_avg = val_loss / len(val_loader.dataset) val_losses.append(val_loss_avg) print(f'Epoch {epoch+1}, Train Loss: {train_loss_avg:.4f}, Val Loss: {val_loss_avg:.4f}') # 绘制损失曲线 plt.figure(figsize=(10, 6)) plt.plot(train_losses, label='Training Loss') plt.plot(val_losses, label='Validation Loss') plt.xlabel('Epoch') plt.ylabel('Loss') plt.title('Training and Validation Loss') plt.legend() plt.show() return model # 示例数据处理 # sensor_df = pd.read_csv('sensor_data.csv') # rul_labels = pd.read_csv('rul_labels.csv')['RUL'].values # # # 数据标准化 # scaler = MinMaxScaler() # sensor_data_scaled = scaler.fit_transform(sensor_df) # sensor_df_scaled = pd.DataFrame(sensor_data_scaled, columns=sensor_df.columns) # # # 准备训练数据 # X, y = prepare_rul_data(sensor_df_scaled, window_size=50, rul_labels=rul_labels) # # # 转换为Tensor # X_tensor = torch.FloatTensor(X) # y_tensor = torch.FloatTensor(y)
Prompt示例(用于工业设备故障诊断):
任务:基于以下传感器数据诊断电机可能的故障类型并提供维护建议。 传感器数据(最近24小时平均值,与正常状态偏差): - 振动:+23%(X轴),+18%(Y轴) - 温度:+12°C - 电流:+15% - 噪声:+6dB - 轴承温度:+18°C 设备信息: - 型号:11kW三相异步电机 - 运行时间:3800小时 - 最近维护:1200小时前(更换润滑油) 要求: 1. 诊断可能的故障类型(列出Top3,按可能性排序) 2. 分析各故障类型的特征匹配度 3. 提供短期应急措施和长期维护建议 4. 评估剩余安全运行时间
西门子数字工厂解决方案通过预测性维护技术,帮助某汽车制造商将生产线设备综合效率(OEE)从65%提升至89%,每年节省维护成本超过2000万欧元。
工业质检:机器视觉的质量革命
传统人工质检效率低、主观性强、易疲劳,AI视觉质检系统通过深度学习算法实现产品缺陷的自动识别,准确率达99.5%以上,检测速度比人工快10-100倍。
缺陷检测模型(基于YOLOv5):
import torch from PIL import Image import numpy as np import cv2 from matplotlib import pyplot as plt # 加载YOLOv5模型 def load_defect_detection_model(model_path='yolov5s_defect.pt'): """加载预训练的缺陷检测模型""" model = torch.hub.load('ultralytics/yolov5', 'custom', path=model_path) model.eval() return model # 缺陷检测与可视化 def detect_defects(model, image_path, confidence_threshold=0.5): """ 检测图像中的产品缺陷 参数: model - 加载的YOLOv5模型 image_path - 待检测图像路径 confidence_threshold - 置信度阈值 返回: results - 检测结果 annotated_image - 标注后的图像 """ # 设置置信度阈值 model.conf = confidence_threshold # 执行检测 results = model(image_path) # 获取标注图像 annotated_image = np.squeeze(results.render()) # 解析检测结果 defect_info = [] for *box, conf, cls in results.xyxy[0].cpu().numpy(): x1, y1, x2, y2 = map(int, box) defect_type = model.names[int(cls)] defect_info.append({ 'type': defect_type, 'confidence': float(conf), 'bbox': (x1, y1, x2, y2), 'area': (x2 - x1) * (y2 - y1) }) return defect_info, annotated_image # 缺陷严重性评估 def evaluate_defect_severity(defect_info, product_specs): """ 评估缺陷严重性 参数: defect_info - 缺陷检测结果 product_specs - 产品规格,包含各类型缺陷的可接受标准 返回: severity - 总体严重性评分(1-10) pass_status - 是否通过质检 report - 详细评估报告 """ severity = 0 report = [] pass_status = True for defect in defect_info: defect_type = defect['type'] confidence = defect['confidence'] area = defect['area'] # 根据产品规格评估严重性 if defect_type in product_specs: max_allowed_area = product_specs[defect_type]['max_area'] if area > max_allowed_area: # 计算超出比例,最高严重性为5分 overage_ratio = min(area / max_allowed_area, 2.0) # 超出200%封顶 defect_severity = int(overage_ratio * 5) severity += defect_severity pass_status = False report.append(f"严重缺陷: {defect_type},面积{area}px²,超出标准{int((overage_ratio-1)*100)}%,严重性评分{defect_severity}") else: report.append(f"轻微缺陷: {defect_type},面积{area}px²,在允许范围内") else: # 未知缺陷类型,默认严重性3 severity += 3 pass_status = False report.append(f"未知缺陷: {defect_type},面积{area}px²,严重性评分3") # 总体严重性评分(0-10) severity = min(severity, 10) return { 'severity': severity, 'pass_status': pass_status, 'defect_count': len(defect_info), 'report': report } # 示例调用 # model = load_defect_detection_model() # product_specs = { # 'crack': {'max_area': 50}, # 'scratch': {'max_area': 100}, # 'dent': {'max_area': 80} # } # defect_info, annotated_img = detect_defects(model, 'product_image.jpg') # evaluation = evaluate_defect_severity(defect_info, product_specs) # # # 显示结果 # plt.figure(figsize=(12, 8)) # plt.imshow(cv2.cvtColor(annotated_img, cv2.COLOR_BGR2RGB)) # plt.title(f"质检结果: {'通过' if evaluation['pass_status'] else '不通过'} (严重性评分: {evaluation['severity']})") # plt.axis('off') # plt.show()
富士康某工厂引入AI视觉质检系统后,手机外壳缺陷检测效率提升80倍,漏检率从3%降至0.05%,每年节省人工成本约1200万元。
AI落地挑战与未来趋势
尽管AI在各行业应用取得显著进展,落地过程中仍面临技术、组织和伦理层面的多重挑战。据麦肯锡调研,仅20%的AI项目能从试点阶段成功扩展到规模化应用。
主要挑战与应对策略
| 挑战类型 | 具体表现 | 应对策略 | 成功案例 |
|---|---|---|---|
| 数据质量与数量 | 数据缺失、标注错误、样本不平衡 | 数据清洗自动化、半监督学习、数据增强 | 某银行利用GAN生成合成数据,解决欺诈样本不足问题 |
| 模型可解释性 | 黑箱模型难以解释决策依据 | SHAP/LIME解释工具、模型简化、规则提取 | 高盛信用评分模型结合XGBoost与规则引擎,满足监管要求 |
| 系统集成复杂 | 与 legacy 系统兼容性差,接口标准不统一 | 微服务架构、API网关、中间件适配 | 西门子Xcelerator平台实现AI模型与ERP/MES系统无缝集成 |
| 组织阻力 | 员工抵触、技能缺口、管理层支持不足 | 变革管理、AI培训、试点成功案例展示 | 海尔COSMOPlat通过"AI种子计划"培养内部AI人才 |
| 伦理与合规 | 算法偏见、隐私泄露、监管风险 | 公平性审计、联邦学习、隐私计算 | 苹果私有计算核心( Private Compute Core)保护用户数据 |
未来技术趋势
-
多模态融合:结合文本、图像、语音和传感器数据,构建更全面的AI模型。例如GE医疗的病理分析系统同时处理组织切片图像和临床文本数据,诊断准确率提升12%。
-
边缘AI:在设备端部署轻量级模型,减少数据传输,降低延迟。工业场景中,边缘AI使设备响应时间从秒级降至毫秒级,满足实时控制需求。
-
可信赖AI:自动检测并减轻算法偏见,实现公平、透明、可靠的AI系统。欧盟AI法案已明确要求高风险AI应用必须满足可解释性要求。
-
AI+数字孪生:结合物理建模与AI预测,在虚拟空间模拟和优化实体系统。空客通过数字孪生结合AI优化机翼设计,将研发周期缩短25%。
-
低代码AI平台:降低AI应用门槛,使业务人员能自主构建模型。微软Power Platform已帮助可口可乐等企业的非技术人员开发出2000+AI应用。
结语:AI驱动的产业变革与机遇
从金融风控的毫秒级决策到医疗影像的精准识别,从个性化学习路径到工厂的预测性维护,AI正以前所未有的速度和深度重塑各行业的核心流程。这场变革不仅带来效率提升和成本降低,更催生了新的商业模式和竞争格局。
成功的AI落地需要技术、业务与组织的深度协同:技术层面要解决数据质量和模型泛化问题,业务层面需找到真正的价值痛点,组织层面要建立跨部门协作机制和人才培养体系。未来,AI将不仅是提升效率的工具,更将成为企业创新和可持续发展的核心驱动力。
对于个人和组织而言,拥抱AI不是选择而是必然。问题不在于是否采用AI,而在于如何以负责任的方式,将AI技术与行业知识深度融合,创造真正的价值。在这场AI驱动的产业变革中,那些能够将技术洞察力、行业理解力和组织执行力相结合的个体和企业,将成为新时代的领导者。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 10
10 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)