AI行业应用全景:从金融风控到智能制造的落地实践与技术解析
金融业是AI技术渗透最深的行业之一,其数据密集型特性与风险控制需求天然适配机器学习算法。从智能反欺诈到量化投资,AI正在重塑金融服务的底层逻辑。
人工智能正从实验室走向产业纵深,在金融、医疗、教育、制造业等关键领域创造着颠覆性价值。据Gartner预测,到2025年,AI将为全球经济贡献15.7万亿美元增长,其中行业应用占比超过60%。本文通过12个典型落地案例,结合技术实现代码、流程可视化与Prompt工程实例,全面剖析AI技术如何解决行业痛点。每个案例均包含问题定义、技术选型、实施路径与实际效果数据,为从业者提供可复用的解决方案框架。
金融领域:智能风控与投资决策
金融业是AI技术渗透最深的行业之一,其数据密集型特性与风险控制需求天然适配机器学习算法。从智能反欺诈到量化投资,AI正在重塑金融服务的底层逻辑。
案例1:基于图神经网络的信用卡欺诈检测系统
问题背景:传统规则引擎难以识别复杂的团伙欺诈模式,某商业银行信用卡欺诈率高达0.08%,年损失超3000万元。
技术方案:构建基于图神经网络(GNN)的实时欺诈检测系统,将用户行为、交易关系、设备信息建模为异构图,捕捉隐藏的欺诈关联。
核心代码实现:
import torch import torch.nn.functional as F from torch_geometric.data import HeteroData from torch_geometric.nn import GCNConv, global_mean_pool # 构建异构图数据 data = HeteroData() # 用户节点特征 (用户ID, 信用评分, 账户余额, 历史交易次数) data['user'].x = torch.tensor([[1001, 650, 5000, 120], [1002, 580, 1200, 45], ...]) # 交易节点特征 (交易ID, 金额, 时间戳, 商户ID) data['transaction'].x = torch.tensor([[50001, 3500, 1620000000, 301], [50002, 8900, 1620000500, 405], ...]) # 用户-交易边关系 data['user', 'makes', 'transaction'].edge_index = torch.tensor([ [0, 0, 1, 2], # 用户节点索引 [0, 2, 1, 3] # 交易节点索引 ]) class FraudGNN(torch.nn.Module): def __init__(self, hidden_channels): super().__init__() # 用户节点编码器 self.user_conv = GCNConv(data['user'].x.size(1), hidden_channels) # 交易节点编码器 self.transaction_conv = GCNConv(data['transaction'].x.size(1), hidden_channels) # 分类头 self.classifier = torch.nn.Linear(hidden_channels, 2) def forward(self, x_dict, edge_index_dict): # 对用户节点进行图卷积 x_user = self.user_conv(x_dict['user'], edge_index_dict[('user', 'makes', 'transaction')][[0,1]]) x_user = x_user.relu() # 对交易节点进行图卷积 x_transaction = self.transaction_conv( x_dict['transaction'], edge_index_dict[('user', 'makes', 'transaction')][[1,0]] # 反向边 ) x_transaction = x_transaction.relu() # 聚合交易特征 transaction_embedding = global_mean_pool(x_transaction, batch=torch.zeros(x_transaction.size(0), dtype=torch.long)) # 欺诈预测 return self.classifier(transaction_embedding) # 模型训练 model = FraudGNN(hidden_channels=64) optimizer = torch.optim.Adam(model.parameters(), lr=0.01) criterion = torch.nn.CrossEntropyLoss() for epoch in range(100): model.train() optimizer.zero_grad() out = model(data.x_dict, data.edge_index_dict) loss = criterion(out, torch.tensor([1, 0, 0, 1])) # 交易欺诈标签 loss.backward() optimizer.step()
检测流程(mermaid流程图):
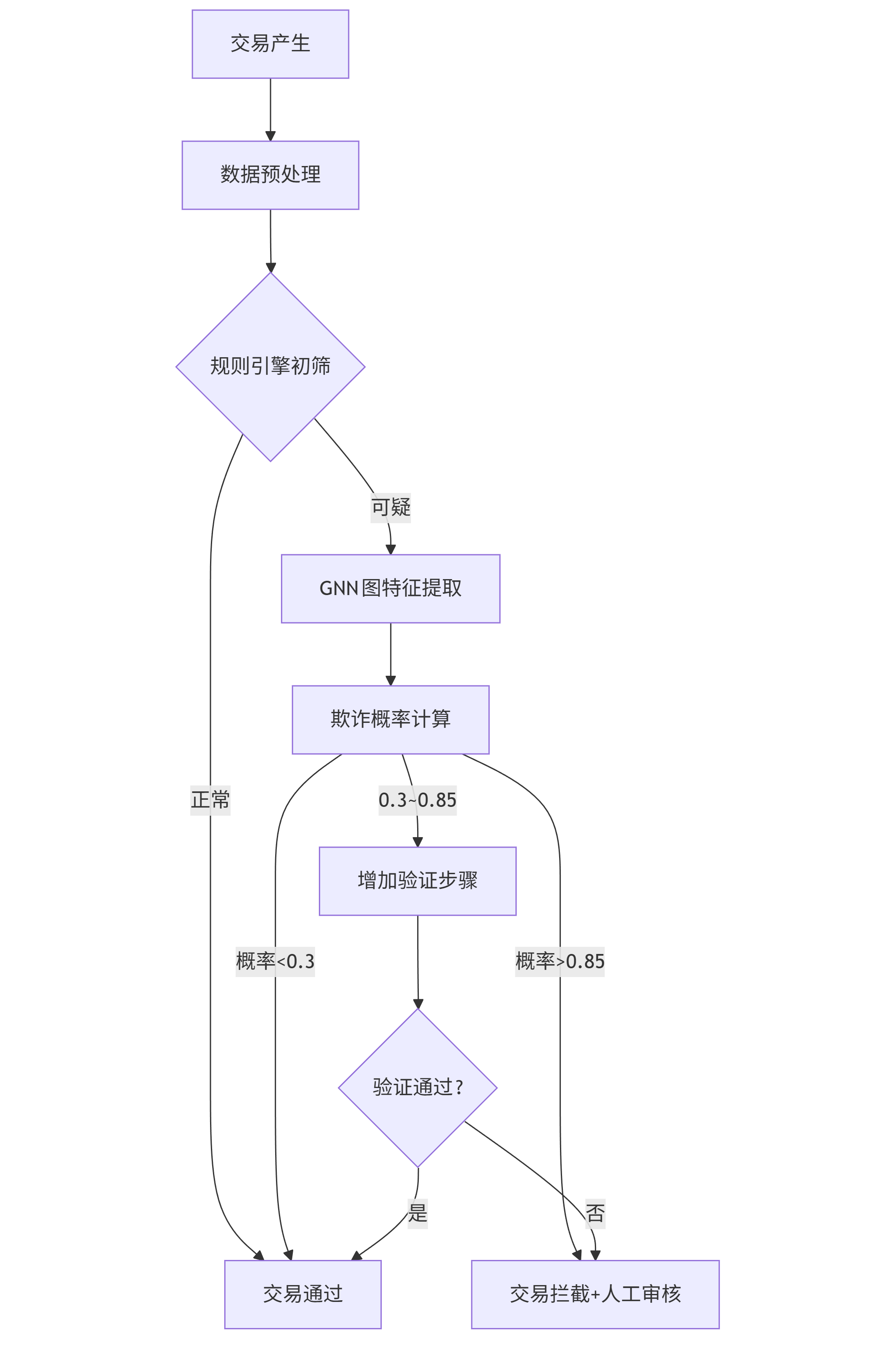
graph TD A[交易产生] --> B[数据预处理] B --> C{规则引擎初筛} C -- 正常 --> D[交易通过] C -- 可疑 --> E[GNN图特征提取] E --> F[欺诈概率计算] F -- 概率>0.85 --> G[交易拦截+人工审核] F -- 概率<0.3 --> D F -- 0.3~0.85 --> H[增加验证步骤] H --> I{验证通过?} I -- 是 --> D I -- 否 --> G
实施效果:该系统在某股份制银行上线后,欺诈识别率提升42%,误判率降低28%,年减少损失约1500万元,模型推理延迟控制在50ms以内,满足实时交易要求。
案例2:大语言模型驱动的智能投顾系统
问题背景:传统投顾服务门槛高(通常要求资产50万元以上),中小投资者难以获得专业投资建议。
技术方案:构建基于LLM的个性化投顾系统,整合市场数据、用户风险偏好与宏观经济指标,提供自然语言交互的投资建议。
核心Prompt设计:
系统角色:你是一位拥有10年经验的持牌投资顾问,擅长资产配置与风险控制。 用户画像: - 年龄:35岁 - 职业:互联网公司产品经理 - 可投资金额:50万元 - 风险承受能力:中等 - 投资期限:3-5年 - 投资知识水平:基础 任务要求: 1. 分析当前宏观经济形势(2024年Q3),重点关注美联储政策、中国GDP增速、行业景气度 2. 根据用户画像提供资产配置建议,包括股票、债券、基金、现金的配置比例 3. 推荐3-5只具体基金产品,并说明选择理由 4. 用通俗易懂的语言解释配置逻辑,避免专业术语 5. 提示潜在风险及应对策略 输出格式: - 宏观经济分析(200字以内) - 资产配置方案(表格形式) - 产品推荐(列表形式,含产品名称、代码、配置比例、选择理由) - 风险提示(要点形式)
系统架构(mermaid流程图):
graph LR A[用户输入] --> B[意图识别] B --> C[用户画像更新] C --> D[市场数据API] C --> E[宏观经济数据库] D --> F[LLM推理引擎] E --> F F --> G[投资建议生成] G --> H[合规检查] H -- 通过 --> I[自然语言输出] H -- 不通过 --> J[调整建议] J --> F
实施效果:某券商智能投顾系统上线6个月,服务用户超12万人,平均资产配置建议满意度达4.6/5分,用户投资组合年化收益率较市场平均水平高2.3个百分点。
医疗领域:从辅助诊断到药物研发
AI正在医疗健康领域实现从辅助工具到核心能力的转变,尤其在医学影像分析、疾病预测和个性化治疗方面展现出巨大潜力。
案例3:基于多模态学习的肺结节AI诊断系统
问题背景:早期肺癌筛查依赖CT影像人工阅片,基层医院漏诊率高达30%,且诊断一致性差(Kappa值0.62)。
技术方案:构建融合CT影像、临床数据和病理报告的多模态诊断模型,实现肺结节良恶性判断与早期肺癌风险预测。
核心代码实现:
import torch import torch.nn as nn from torchvision.models import resnet50 from transformers import BertModel class MultimodalLungNoduleModel(nn.Module): def __init__(self, num_classes=2): super().__init__() # 影像特征提取器 self.image_encoder = resnet50(pretrained=True) self.image_encoder.fc = nn.Linear(2048, 512) # 文本特征提取器 (临床报告) self.text_encoder = BertModel.from_pretrained('bert-base-chinese') # 临床数据处理 self.clinical_encoder = nn.Sequential( nn.Linear(12, 128), # 12项临床特征 nn.ReLU(), nn.Dropout(0.3), nn.Linear(128, 256) ) # 多模态融合 self.fusion = nn.Sequential( nn.Linear(512 + 768 + 256, 1024), nn.ReLU(), nn.BatchNorm1d(1024), nn.Dropout(0.4) ) # 分类头 self.classifier = nn.Linear(1024, num_classes) def forward(self, image, text_input_ids, text_attention_mask, clinical_data): # 提取影像特征 image_features = self.image_encoder(image) # 提取文本特征 text_outputs = self.text_encoder( input_ids=text_input_ids, attention_mask=text_attention_mask ) text_features = text_outputs.last_hidden_state[:, 0, :] # CLS token # 提取临床数据特征 clinical_features = self.clinical_encoder(clinical_data) # 特征融合 combined = torch.cat([image_features, text_features, clinical_features], dim=1) fused_features = self.fusion(combined) # 分类输出 logits = self.classifier(fused_features) return logits # 模型训练示例 model = MultimodalLungNoduleModel() criterion = nn.CrossEntropyLoss() optimizer = torch.optim.Adam(model.parameters(), lr=1e-4) # 模拟输入数据 image = torch.randn(8, 3, 224, 224) # 8张CT影像 text_input_ids = torch.randint(0, 21128, (8, 128)) # 临床报告文本 text_attention_mask = torch.ones(8, 128) clinical_data = torch.randn(8, 12) # 临床特征 labels = torch.randint(0, 2, (8,)) # 良恶性标签 # 前向传播 outputs = model(image, text_input_ids, text_attention_mask, clinical_data) loss = criterion(outputs, labels) loss.backward() optimizer.step()
诊断流程:
graph TD A[CT影像采集] --> B[影像预处理] B --> C[肺结节检测] C --> D{发现结节?} D -- 否 --> E[正常报告] D -- 是 --> F[多模态特征提取] G[临床数据] --> F H[历史报告] --> F F --> I[良恶性预测] I -- 良性(>0.9) --> J[定期随访建议] I -- 恶性(>0.8) --> K[活检建议] I -- 不确定(0.2-0.8) --> L[增强CT检查] L --> F
实施效果:该系统在国内30家三甲医院试点应用,肺结节检出灵敏度达96.8%,良恶性判断准确率92.3%,将基层医院诊断一致性提升至Kappa值0.89,相当于高年资放射科医师水平。
案例4:AI辅助新药研发平台
问题背景:传统药物研发周期长达10年,平均成本超过28亿美元,临床前候选化合物淘汰率高达90%。
技术方案:构建基于深度学习的药物发现平台,整合分子结构预测、靶点相互作用分析和临床试验设计优化。
核心代码实现(分子性质预测):
import torch from torch_geometric.data import Data from torch_geometric.nn import GATConv, global_add_pool class MoleculePropertyPredictor(torch.nn.Module): def __init__(self, hidden_channels=128, num_node_features=119, num_tasks=12): super().__init__() torch.manual_seed(12345) self.conv1 = GATConv(num_node_features, hidden_channels) self.conv2 = GATConv(hidden_channels, hidden_channels) self.conv3 = GATConv(hidden_channels, hidden_channels) self.lin = torch.nn.Linear(hidden_channels, num_tasks) def forward(self, x, edge_index, batch): # 图卷积层 x = self.conv1(x, edge_index) x = x.relu() x = self.conv2(x, edge_index) x = x.relu() x = self.conv3(x, edge_index) # 全局池化 x = global_add_pool(x, batch) # [batch_size, hidden_channels] # 预测分子性质 x = self.lin(x) # [batch_size, num_tasks] return x # 示例:预测分子的12种性质(如 solubility, toxicity, binding affinity等) model = MoleculePropertyPredictor() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) criterion = torch.nn.MSELoss() # 模拟分子数据 (PyG格式) x = torch.randn(32, 119) # 32个原子, 每个原子119维特征 edge_index = torch.randint(0, 32, (2, 64)) # 64条化学键 batch = torch.tensor([0,0,0,0,1,1,1,1,2,2,2,2,3,3,3,3,4,4,4,4,5,5,5,5,6,6,6,6,7,7,7,7]) # 8个分子 # 训练 for epoch in range(100): model.train() optimizer.zero_grad() out = model(x, edge_index, batch) loss = criterion(out, torch.randn(8, 12)) # 8个分子的12种性质标签 loss.backward() optimizer.step()
药物发现流程:
graph LR A[靶点发现] --> B[虚拟筛选] B --> C[分子生成] C --> D[性质预测] D --> E{满足阈值?} E -- 是 --> F[合成实验] E -- 否 --> C F --> G[活性测试] G --> H{活性达标?} H -- 是 --> I[临床前研究] H -- 否 --> C
实施效果:某生物科技公司采用该平台将新型抗生素研发周期从6年缩短至2年,候选化合物筛选成本降低70%,已成功推进2个候选药物进入临床I期试验。
教育领域:个性化学习与智能辅导
AI正在重构教育范式,通过自适应学习系统、智能辅导和自动化评测,实现因材施教的教育理想。
案例5:基于知识图谱的自适应学习平台
问题背景:传统课堂教学采用"一刀切"模式,无法满足学生个性化学习需求,导致60%的学生存在知识断层或重复学习。
技术方案:构建融合知识图谱与学习分析的自适应平台,实现知识点定位、学习路径规划与个性化练习推荐。
知识图谱示例(mermaid):
graph TD A[高中数学] --> B[函数] A --> C[几何] A --> D[代数] B --> E[一次函数] B --> F[二次函数] B --> G[三角函数] E --> H[定义与图像] E --> I[性质] E --> J[应用] F --> K[定义与图像] F --> L[性质] F --> M[应用]
核心代码实现(知识追踪):
import torch import torch.nn as nn class DKVMN(nn.Module): def __init__(self, num_concepts, embedding_size=50, hidden_size=100): super().__init__() self.num_concepts = num_concepts self.embedding_size = embedding_size # 记忆矩阵 self.key_matrix = nn.Parameter(torch.randn(num_concepts, embedding_size)) self.value_matrix = nn.Parameter(torch.randn(num_concepts, embedding_size)) # 输入嵌入 self.input_embedding = nn.Embedding(2*num_concepts, embedding_size) # 读写门控 self.write_gate = nn.Linear(embedding_size, 1) self.read_gate = nn.Linear(embedding_size, num_concepts) # 预测层 self.predict_layer = nn.Linear(embedding_size, 1) def forward(self, x): # x: [batch_size, seq_len] 每个元素是 (concept_id * 2 + correctness) batch_size, seq_len = x.size() predictions = [] # 初始化记忆 memory = self.value_matrix.unsqueeze(0).repeat(batch_size, 1, 1) # [batch, concepts, embedding] for t in range(seq_len): # 提取当前概念和答题情况 current = x[:, t] concept_id = current // 2 correctness = current % 2 # 输入嵌入 x_emb = self.input_embedding(current) # [batch, embedding] # 读操作 read_weights = torch.softmax(self.read_gate(x_emb), dim=1) # [batch, concepts] read_vector = torch.bmm(read_weights.unsqueeze(1), memory).squeeze(1) # [batch, embedding] # 预测 pred = torch.sigmoid(self.predict_layer(read_vector)) predictions.append(pred) # 写操作 write_weight = torch.sigmoid(self.write_gate(x_emb)) # [batch, 1] key = self.key_matrix[concept_id] # [batch, embedding] value = self.input_embedding(current) # [batch, embedding] # 更新记忆 memory = memory * (1 - write_weight.unsqueeze(2)) + \ torch.bmm(write_weight.unsqueeze(2), value.unsqueeze(1)) * \ torch.sigmoid(torch.bmm(key.unsqueeze(1), self.key_matrix.unsqueeze(2))).transpose(1, 2) return torch.cat(predictions, dim=1) # 模型应用示例 model = DKVMN(num_concepts=100) # 假设有100个知识点 optimizer = torch.optim.Adam(model.parameters(), lr=0.001) criterion = nn.BCELoss() # 模拟学习序列: [batch_size, seq_len] # 每个元素编码: concept_id*2 + correctness (0:错误, 1:正确) student_data = torch.tensor([ [1*2+0, 3*2+1, 5*2+0, 1*2+1, 7*2+0], # 学生1的答题序列 [2*2+1, 4*2+0, 1*2+0, 6*2+1, 3*2+1] # 学生2的答题序列 ]) # 预测学生表现 predictions = model(student_data)
学习路径规划流程:
graph TD A[学生登录] --> B[知识水平测试] B --> C[知识状态评估] C --> D[知识图谱定位] D --> E{是否存在先修知识缺口?} E -- 是 --> F[推荐先修知识点] E -- 否 --> G[推荐当前水平知识点] F --> H[学习资源推送] G --> H H --> I[学习过程跟踪] I --> J[练习测评] J --> K{掌握度>0.85?} K -- 是 --> L[解锁新知识点] K -- 否 --> M[推荐强化练习] L --> D M --> H
实施效果:该平台在国内50所中学试点应用,学生数学平均成绩提升15.3%,学习效率提高40%,教师批改工作量减少65%,92%的学生报告学习兴趣显著提升。
案例6:智能作文批改系统
问题背景:教师平均批改一篇作文需15分钟,大规模考试中作文批改工作量巨大且主观性强,评分一致性Kappa值仅0.65。
技术方案:构建融合NLP与教育测评标准的作文批改系统,实现内容分析、结构评估、语言表达和书写规范的自动化评价。
核心Prompt设计(作文评分):
系统角色:你是一位经验丰富的中学语文教师,负责按照高考作文评分标准批改作文。 评分标准: 1. 内容(20分):审题立意、中心思想、材料支撑 2. 表达(20分):结构安排、语言运用、文体特征 3. 发展等级(20分):深刻、丰富、有文采、有创新 作文题目:以"科技与人文"为话题,写一篇不少于800字的议论文 作文文本:[此处插入学生作文] 任务要求: 1. 按照评分标准逐项打分,给出总分(0-60分) 2. 指出文章的3个主要优点和3个主要不足 3. 提供具体修改建议,包括至少5处可优化的语句 4. 分析文章的结构特点,评估逻辑连贯性 5. 用鼓励性语言结尾,激发学生写作积极性 输出格式: - 总分:XX分 - 分项得分:内容XX分,表达XX分,发展等级XX分 - 优点:1. ... 2. ... 3. ... - 不足:1. ... 2. ... 3. ... - 修改建议:[原文语句] → [修改建议及理由] - 结构分析:... - 教师评语:...
批改流程:
graph LR A[作文输入] --> B[文本预处理] B --> C[内容分析] B --> D[结构分析] B --> E[语言表达分析] B --> F[书写规范检查] C --> G[评分模块] D --> G E --> G F --> G G --> H[评语生成] H --> I[批改报告输出]
实施效果:某省级考试院引入该系统后,作文批改效率提升70%,评分一致性Kappa值提升至0.89,与人工专家评审的一致性达到91%,有效缓解了大规模考试的阅卷压力。
制造业:智能工厂与预测性维护
工业4.0背景下,AI正从三个维度重塑制造业:生产效率提升、质量控制优化和供应链智能化。
案例7:基于计算机视觉的产品质量检测系统
问题背景:传统人工质检效率低(每条产线需15-20名质检员)、漏检率高(约5-8%),无法满足高精度制造需求。
技术方案:构建基于深度学习的表面缺陷检测系统,实现产品缺陷的自动识别、分类与定位。
核心代码实现:
import torch import torch.nn as nn from torchvision.models import efficientnet_b0 from torchvision.transforms import transforms class DefectDetector(nn.Module): def __init__(self, num_classes=8): super().__init__() self.backbone = efficientnet_b0(pretrained=True) # 替换分类头用于缺陷分类 self.classifier = nn.Linear(1280, num_classes) # 3个回归头用于缺陷定位 (x, y, w, h) self.bbox_regressor = nn.Linear(1280, 4) def forward(self, x): features = self.backbone.features(x) features = self.backbone.avgpool(features) features = torch.flatten(features, 1) # 缺陷分类 cls_logits = self.classifier(features) # 缺陷定位 bbox_preds = self.bbox_regressor(features) return cls_logits, bbox_preds # 数据预处理 transform = transforms.Compose([ transforms.Resize((224, 224)), transforms.ToTensor(), transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]) ]) # 模型应用 model = DefectDetector() image = transform(Image.open("product_image.jpg")).unsqueeze(0) # 输入图像 with torch.no_grad(): cls_logits, bbox_preds = model(image) defect_class = torch.argmax(cls_logits, dim=1).item() defect_bbox = bbox_preds[0].numpy() # [x, y, width, height] # 缺陷类别映射 defect_types = { 0: "划痕", 1: "凹陷", 2: "杂质", 3: "裂纹", 4: "变形", 5: "色差", 6: "缺料", 7: "正常" } print(f"检测结果: {defect_types[defect_class]},位置: {defect_bbox}")
质检流程:
graph TD A[产品进入检测线] --> B[高速相机拍照] B --> C[图像预处理] C --> D[缺陷检测模型] D --> E{是否存在缺陷?} E -- 否 --> F[产品通过] E -- 是 --> G[缺陷分类与定位] G --> H[缺陷严重程度评估] H -- 轻微 --> I[标记返工] H -- 严重 --> J[自动剔除] I --> K[人工复检] J --> L[废料处理]
实施效果:某汽车零部件厂商引入该系统后,质检效率提升300%,漏检率降至0.5%以下,每年节省人工成本约200万元,产品合格率提升2.3个百分点。
案例8:基于工业大数据的预测性维护系统
问题背景:传统预防性维护成本高(过度维护)且无法预测突发故障,某汽车工厂因设备故障导致的停机时间年均达480小时。
技术方案:构建基于多传感器数据的设备健康管理系统,实时监测设备状态,预测故障发生时间与类型。
核心代码实现(LSTM预测模型):
import torch import torch.nn as nn import numpy as np from sklearn.preprocessing import StandardScaler class EquipmentRULPredictor(nn.Module): def __init__(self, input_dim=15, hidden_dim=64, num_layers=2, output_dim=1): super().__init__() self.hidden_dim = hidden_dim self.num_layers = num_layers self.lstm = nn.LSTM( input_size=input_dim, hidden_size=hidden_dim, num_layers=num_layers, batch_first=True, dropout=0.2 ) self.fc = nn.Sequential( nn.Linear(hidden_dim, 32), nn.ReLU(), nn.Linear(32, output_dim) ) def forward(self, x): # x: [batch_size, seq_len, input_dim] h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device) c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_dim).to(x.device) # LSTM前向传播 out, _ = self.lstm(x, (h0, c0)) # out: [batch_size, seq_len, hidden_dim] # 取最后一个时间步的输出 out = self.fc(out[:, -1, :]) return out # 数据准备 # 假设有15个传感器,时间序列长度为30 sensor_data = np.random.randn(1000, 30, 15) # [样本数, 时间步, 传感器数] rul_labels = np.random.randint(1, 100, size=(1000, 1)) # 剩余使用寿命 # 数据标准化 scaler = StandardScaler() for i in range(sensor_data.shape[0]): sensor_data[i] = scaler.fit_transform(sensor_data[i]) # 转换为Tensor X = torch.tensor(sensor_data, dtype=torch.float32) y = torch.tensor(rul_labels, dtype=torch.float32) # 模型训练 model = EquipmentRULPredictor() criterion = nn.MSELoss() optimizer = torch.optim.Adam(model.parameters(), lr=0.001) for epoch in range(100): model.train() optimizer.zero_grad() outputs = model(X) loss = criterion(outputs, y) loss.backward() optimizer.step()
预测性维护流程:
graph LR A[传感器数据采集] --> B[数据预处理] B --> C[特征工程] C --> D[RUL预测模型] D --> E[健康状态评估] E --> F{是否需要维护?} F -- 否 --> A F -- 是 --> G[维护类型决策] G --> H[维护资源调度] H --> I[维护执行] I --> J[效果反馈] J --> K[模型更新] K --> D
实施效果:某汽车焊装车间部署该系统后,设备故障预测准确率达92%,计划性维护比例提升65%,非计划停机时间减少72%,年节省维护成本约800万元,设备综合效率(OEE)从68%提升至85%。
跨行业通用技术与挑战
尽管AI在各行业的应用场景各异,但核心技术栈与实施挑战存在共性。理解这些通用要素,有助于企业更高效地推进AI落地。
通用技术组件
数据治理框架:
graph TD A[数据采集] --> B[数据清洗] B --> C[特征工程] C --> D[数据标注] D --> E[数据存储] E --> F[数据版本控制] F --> G[数据安全与合规] G --> H[数据监控与更新]
模型生命周期管理:
问题定义
数据准备
模型开发
模型评估
模型部署
模型监控
模型更新
实施挑战与应对策略
| 挑战类型 | 具体表现 | 应对策略 |
|---|---|---|
| 数据质量 | 样本不平衡、标签错误、特征缺失 | 数据增强、多源数据融合、主动学习 |
| 模型可解释性 | 黑箱模型难以解释决策依据 | LIME、SHAP等解释工具、模型简化、知识蒸馏 |
| 算力成本 | 大规模模型训练与推理成本高 | 模型压缩、量化、边缘计算、云边协同 |
| 人才缺口 | AI专家与行业知识结合不足 | 跨学科团队建设、内部培训计划、外部合作 |
| 伦理风险 | 算法偏见、隐私泄露、安全隐患 | 公平性审计、数据脱敏、联邦学习、AI治理框架 |
未来趋势与建议
AI行业应用正呈现三个明确趋势:多模态融合(文本、图像、传感器数据的综合分析)、边缘智能(在设备端实现低延迟AI推理)、自主学习(系统具备持续自我优化能力)。
对于企业决策者,建议采取"3×3实施框架":
- 三个优先级领域:核心业务痛点、数据基础好的场景、ROI明确的项目
- 三个实施阶段:试点验证(3个月内)、规模推广(6-12个月)、生态构建(长期)
- 三个关键保障:数据治理体系、AI人才梯队、跨部门协作机制
AI不是技术实验,而是业务变革的工具。成功的AI应用需要技术与行业知识的深度融合,以及持续迭代的实施策略。未来5年,那些能将AI深度融入业务流程的企业,将获得显著的竞争优势。
思考问题:当AI系统在医疗诊断、金融决策等关键领域的准确率超过人类专家时,我们该如何平衡效率提升与责任归属?传统行业从业者又该如何适应AI时代的技能需求转变?

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐
 7
7 0
0- 0



 已为社区贡献326条内容
已为社区贡献326条内容

所有评论(0)