第七篇:LangChain 1.0 多模态实战:Content Blocks 与批处理完全指南
本文详细讲解了 标准化内容块 Content Blocks 和批处理流程,包括多模态数据处理、批量调用、异步并发等核心概念。通过本文的学习,你将掌握如何高效处理图片、音频等多模态数据,以及如何批量处理大量请求。
📌 所属章节:第三阶段 - Content Blocks 与批处理
← 上一篇:Messages 与 Prompt 提示词模板 | 📚 系列目录 | 下一篇:流式传输与结构化输出 →
📋 摘要
本文详细讲解了 标准化内容块 Content Blocks 和批处理流程,包括多模态数据处理、批量调用、异步并发等核心概念。通过本文的学习,你将掌握如何高效处理图片、音频等多模态数据,以及如何批量处理大量请求。
适合人群:
- 需要处理多模态数据的 AI 应用开发者
- 需要批量处理请求的工程师
- 想深入理解 LangChain 数据处理机制的开发者
3.4 标准化内容块Content Blocks
统一所有模型厂商的输出格式,解决"换模型就要重写解析代码"的痛点:
LangChain 1.0 引入了 provider-agnostic与厂商无关 的 standard content blocks标准化内容块,使得消息中的多模态数据(图片、音频、PDF、视频等)能以统一、类型化的方式被构造与阅读。通过 content blocks 属性实现多模态统一处理,封装 TextBlock、ToolCallBlock、ImageBlock 等结构,扩展 LLM 应用至图片理解、语音交互等场景。其核心优势在于标准化内容流转与跨平台兼容性,可通过 langchain-openai 等厂商包直接初始化多模态模型,支持图片输入生成描述、语音转文本问答等功能,依赖 Model I/O 模块完成格式化与解析
支持类型:text 、 tool_call 、 image 、 audio 、 video
| 场景 | 内容块作用 |
|---|---|
| 📄 文档解析(PDF / 图片 / 表格) | 用 imageblock 把 Document OCR 图像传给模型 |
| 🔊 语音问答(ASR) | 用 audioblock 发送语音样本 |
| 🎞 多模态 RAG | 将检索到的图片、图表、视频帧作为 input blocks 传给模型 |
| 🤖 多工具 Agent | 工具返回的媒体统一包装成 block 再传回模型 |
| 🧪 模型评估(LangSmith / LangChain Playground) | 进行 multimodal prompt 测试与 A/B,对 content blocks 标注与评估。 |
输出提取content_blocks
# 1. 定义带速率限制的load_chat_model函数
from langchain.chat_models import init_chat_model
from langchain_core.rate_limiters import InMemoryRateLimiter
# 2. 配置速率限制器
rate_limiter = InMemoryRateLimiter(
requests_per_second=5, # 每秒最多5个请求
check_every_n_seconds=1.0 # 每1秒检查一次是否超过速率限制
)
# 3. 对模型调用进行封装,后续直接调用传参数就行
def load_chat_model(
model: str,
provider: str,
temperature: float = 0.7,
max_tokens: int | None = None,
base_url: str | None = None,
):
return init_chat_model(
model=model, # 模型名称
model_provider=provider, # 模型供应商
temperature=temperature, # 温度参数,用于控制模型的随机性,值越小则随机性越小
max_tokens=max_tokens, # 最大生成token数
base_url=base_url, # 专用于自定义 API Server 或代理
rate_limiter=rate_limiter # 自动限速
)
# 加载 DeepSeek 提供的推理模型 deepseek-reasoner
deepseek_model = load_chat_model(
model="deepseek-reasoner", # 指定模型名称
provider="deepseek", # 指定模型提供商
)
# 调用模型
res = deepseek_model.invoke("请介绍一下你自己")
# 输出模型返回的结果
res
# 从模型返回的结果中提取内容块
res.content_blocks
多模态输入content_blocks
# 如果需要把本地文件以 base64 形式发送,建议安装 pillow/ffmpeg 等按需工具
#!pip install pillow
base64 形式触及了网络传输与数据序列化的底层原理。
简单来说,将图片或音频转换为 Base64,主要是为了解决 “在纯文本协议(HTTP/JSON)中传输二进制数据(Binary Data)” 的兼容性问题。
绝大多数大模型 API(OpenAI, Anthropic, Google Gemini 等)都是基于 RESTful API,数据载荷(Payload)格式通常是 JSON。
-
JSON 的本质:JSON 是一种纯文本格式。它只能理解字符串(String)、数字、布尔值等文本数据。
-
图片/音频的本质:它们是二进制数据(Binary Bytes)。如果你直接用文本编辑器打开一张 JPG 图片,你会看到乱码,其中包含了大量的不可见字符、控制字符(如换行符、空字符 \0 等)。
-
冲突点:如果你直接把这些二进制乱码塞进 JSON 的字符串字段里(例如 {“image”: “ÿØÿà…”}),这些特殊字符会破坏 JSON 的语法结构,导致服务端无法解析,或者被 HTTP 协议拦截。
-
解决方案:Base64 编码可以将任意二进制数据,映射为 64 个标准的、可打印的 ASCII 字符(A-Z, a-z, 0-9, +, /)。这样,原本的二进制图片就变成了普通的字符串,可以完美地嵌入到 JSON 中。
content_blocks 是 LangChain v1 的标准化多模态消息单元,你可以用 dict 结构把图片与音频纳入消息里,框架会把它们转换为各 provider 可识别的格式;在实际使用时务必确认目标模型/provider 对 multimodal 的支持和所需的 mime_type / metadata 字段。
from langchain_core.messages import HumanMessage, SystemMessage
# 创建系统提示
system_msg = SystemMessage("你是一个专业的问答专家。")
# 构造用户消息:文本+图像
human_msg = HumanMessage(content=[
{"type": "text", "text": "请描述图像:"},
{"type": "image_url",
"image_url": {"url": "https://i-blog.csdnimg.cn/img_convert/4c7d96f7c9c9762f34d1befc7250fe72.png",
"mime_type": "image/jpeg",
"metadata": "RAG基础流程图"}
},
])
# 形成消息列表
messages = [system_msg, human_msg]
# 框架会懒解析 content -> content_blocks
for cb in human_msg.content_blocks:
print(cb) # content block 对象视图
输出结果:
{'type': 'text', 'text': '请描述图像:'}
{'type': 'image', 'id': 'lc_ee96e0ce-c5a9-4dec-9f82-29180fa7f85f', 'url': 'https://i-blog.csdnimg.cn/img_convert/4c7d96f7c9c9762f34d1befc7250fe72.png', 'extras': {'image_url_mime_type': 'image/jpeg', 'image_url_metadata': 'RAG基础流程图'}}
import os
from openai import OpenAI
client = OpenAI(
# 若没有配置环境变量,请用阿里云百炼API Key将下行替换为:api_key = "********************",
# 各地域的API Key不同。获取API Key:https://help.aliyun.com/zh/model-studio/get-api-key
api_key = "********************",
# 以下为北京地域的 base_url,若使用弗吉尼亚地域模型,需要将base_url换成https://dashscope-us.aliyuncs.com/compatible-mode/v1
# 若使用新加坡地域的模型,需将base_url替换为:https://dashscope-intl.aliyuncs.com/compatible-mode/v1
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
)
completion = client.chat.completions.create(
model="qwen3-vl-plus", # 此处以qwen3-vl-plus为例,可按需更换模型名称。模型列表:https://help.aliyun.com/zh/model-studio/models
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://help-static-aliyun-doc.aliyuncs.com/file-manage-files/zh-CN/20241022/emyrja/dog_and_girl.jpeg"
},
},
{"type": "text", "text": "图中描绘的是什么景象?"},
],
},
],
)
print(completion.choices[0].message.content)
输出结果:
图中描绘的是一幅温馨宁静的海边黄昏景象:一位年轻女子与一只金毛寻回犬(或拉布拉多)坐在柔软的沙滩上,正愉快地互动——狗狗抬起前爪与女子击掌(“high-five”),女子面带灿烂笑容,眼神温柔地注视着它。
背景是平静的海面与柔和的落日余晖,阳光从右侧低角度洒下,为人物和狗镀上一层温暖的金色光晕,营造出浪漫、治愈的氛围。女子身穿格子衬衫和深色裤子,赤脚坐在沙中;狗狗佩戴着彩色图案的胸背带和牵引绳,姿态温顺而活泼。
整幅画面传递出人与宠物之间深厚的信任、陪伴与快乐,象征着自由、纯真与生活中的小确幸,是一幅充满情感温度的自然人文写照。
import requests
import json
# 请求配置
url = "https://perception-openai-japan.openai.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2024-02-01"
headers = {
"Content-Type": "application/json",
"api-key": "********************"
}
# 请求体
payload = {
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "讲个笑话"}
],
"temperature": 0.7,
"max_tokens": 800
}
# 发送请求
response = requests.post(url, headers=headers, json=payload)
result = response.json()
# 获取回复内容
print(result["choices"][0]["message"]["content"])
输出结果:
当然!这是一个简单的笑话:
有一天,一只鸭子走进一家超市,问店员:“你们有葡萄吗?”
店员回答:“没有,我们不卖葡萄。”
第二天,鸭子又来了,问:“你们有葡萄吗?”
店员有点生气:“我不是告诉过你了吗?我们没有葡萄!”
第三天,鸭子又来了,问:“你们有葡萄吗?”
店员怒了:“我警告你!再问一次,我就用锤子把你的嘴钉住!”
第四天,鸭子来了,问:“你们有锤子吗?”
店员说:“没有。”
鸭子笑了:“那你们有葡萄吗?”
😄
from langchain_openai import AzureChatOpenAI
model = AzureChatOpenAI(
azure_endpoint="https://perception-openai-japan.openai.azure.com", # 注意:azure_endpoint,不是 base_url
api_key = "********************",
azure_deployment="gpt-4o", # 部署名称
api_version="2024-02-01",
temperature=0.7,
)
# 使用方式相同
res = model.invoke([{"role": "user", "content": "讲个笑话"}])
print(res.content)
输出结果:
好的!这儿有一个:
有一天,老师问小明:“如果地球是个正方形,会怎么样?”
小明想了想,说:“那就得改叫地方了!”
# # 使用具有多模态能力的模型
# model = load_chat_model(
# model="gpt-4o-mini",
# provider="openai",
# )
# res = model.invoke(messages)
# print(res.content)
# # 使用具有多模态能力的模型
# model = load_chat_model(
# model="gpt-4o-mini",
# provider="openai",
# )
# res = model.invoke(messages)
# print(res.content)
from langchain_openai import AzureChatOpenAI
model = AzureChatOpenAI(
azure_endpoint="https://perception-openai-japan.openai.azure.com", # 注意:azure_endpoint,不是 base_url
api_key = "********************",
azure_deployment="gpt-4o", # 部署名称
api_version="2024-02-01",
temperature=0.7,
)
# from langchain_openai import ChatOpenAI
# model = ChatOpenAI(
# model="qwen3-vl-plus",
# base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
# api_key = "********************"
# )
res = model.invoke(messages)
print(res.content)
输出结果:
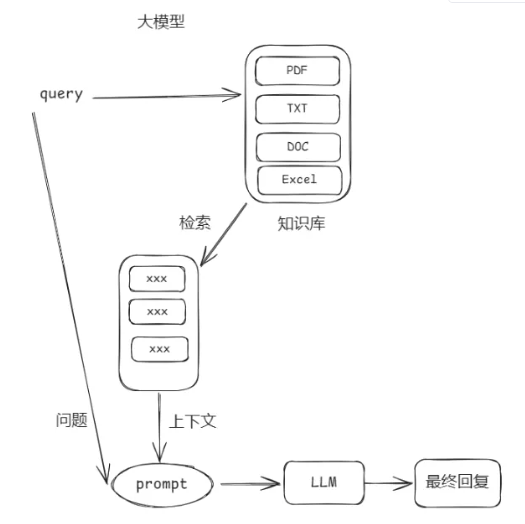
这幅图展示了一个基于大语言模型(LLM)的问答流程,主要包括以下步骤:
1. **query(查询)**:用户输入问题或查询。
2. **知识库**:系统从知识库中检索相关信息,知识库包含不同类型的文件(如PDF、TXT、DOC、Excel等)。
3. **检索结果**:从知识库中返回与查询相关的信息(标注为“xxx”),作为上下文内容。
4. **上下文与问题组合**:将检索到的上下文信息与用户的问题结合,生成一个新的“prompt”(提示)。
5. **LLM处理**:将生成的提示输入到大语言模型(LLM)中进行处理。
6. **最终回复**:LLM根据提示内容生成最终的回答并返回给用户。
图中用箭头清晰地表示了各个步骤之间的流程关系。
内容块创建标准格式
comparison = """
┌─────────────┬──────────────────────────────────────────────────────┐
│ 内容块类型 │ 标准格式(LangChain 1.0) │
├─────────────┼──────────────────────────────────────────────────────┤
│ 文本 │ {"type": "text", "text": "..."} │
│ 图像 │ {"type": "image", "url": "...", "mime_type": "..."} │
│ 音频 │ {"type": "audio", "url": "...", "mime_type": "..."} │
│ 视频 │ {"type": "video", "url": "...", "mime_type": "..."} │
│ 文件 │ {"type": "file", "url": "...", "mime_type": "..."} │
│ Base64 图像 │ {"type": "image", "base64": "...", "mime_type": "..."} │
│ Base64 音频 │ {"type": "audio", "base64": "...", "mime_type": "..."} │
│ OpenAI 图像 │ {"type": "image_url", "image_url": {"url": "..."}} │
└─────────────┴──────────────────────────────────────────────────────┘
"""
#OpenAI 内容块支持对比表:
support_table = """
┌─────────────┬──────────┬─────────────────────────────────────┐
│ 内容块类型 │ 支持情况 │ 说明 │
├─────────────┼──────────┼─────────────────────────────────────┤
│ text │ ✅ 支持 │ 纯文本内容 │
│ image_url │ ✅ 支持 │ 图像 URL(支持 jpg, png, gif, webp)│
│ audio │ ❌ 不支持│ 需要先用 Whisper 转录为文本 │
│ video │ ❌ 不支持│ 需要提取关键帧或转录音频 │
│ file │ ❌ 不支持│ 需要提取文本内容 │
└─────────────┴──────────┴─────────────────────────────────────┘
"""
3.5 批处理流程
在使用大模型时,如果需要同时处理多条独立请求(例如多个问题或多段文本),则可以使用 批量调用(Batch) 方法一次性提交这些请求。LangChain 中的 batch() 方法允许你同时发送一组请求,模型会在后台并行处理,然后返回所有结果:
import time
from datetime import datetime
# 记录开始时间
start_time = time.time()
print(f"⏱️ 开始时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
# 批量提问
responses = model.batch([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
])
# 记录结束时间
end_time = time.time()
total_duration = end_time - start_time
print(f"⏱️ 结束时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
print(f"📊 总耗时: {total_duration:.2f}s")
for response in responses:
print(response)
| 特性 | 说明 |
|---|---|
| 执行位置 | batch() 在客户端(Client-side)并行调用模型,而非调用模型提供商的批量API(如OpenAI或Anthropic自带的batch API)。 |
| 返回结果 | 默认会在所有任务完成后,统一返回完整结果列表。 |
| 并行优势 | 多条独立请求可同时执行,无需等待彼此完成。 |
| 适用场景 | 文档摘要、批量问答、数据预处理、多样本分类等。 |
当然,我们也可以进行流式批处理,也就是每个任务完成后就立即获取结果(而不是等待全部完成),可以使用 batch_as_completed() 方法。
# 使用 model.batch_as_completed 批量提交多个问题,并逐个获取回答
for response in model.batch_as_completed([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
]):
print(response)
异步并发处理RunnableConfig
而为了更好的控制并发,我们还可以在config参数中设置批处理的并发数,例如
from langchain_openai import ChatOpenAI
model = ChatOpenAI(
model="qwen-plus",
base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",
api_key = "********************"
)
import time
from datetime import datetime
#import asyncio
from langchain_core.runnables import RunnableConfig
#设置并发数为3
config = RunnableConfig(max_concurrency=3)
# 记录开始时间
start_time = time.time()
print(f"⏱️ 开始时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
# 并发调用模型,批量处理三个问题
# Jupyter 已经支持顶级 await,无需 asyncio.run()
responses = await model.abatch([
"请介绍下你自己。",
"请问什么是机器学习?",
"你知道机器学习和深度学习区别么?"
],config=config)
# 记录结束时间
end_time = time.time()
total_duration = end_time - start_time
print(f"⏱️ 结束时间: {datetime.now().strftime('%H:%M:%S.%f')[:-3]}")
print(f"📊 总耗时: {total_duration:.2f}s")
# for response in responses:
# print(response)
输出结果:
⏱️ 开始时间: 08:33:36.469
⏱️ 结束时间: 08:33:53.540
📊 总耗时: 17.07s
特别注意
-
RunnableConfig(max_concurrency=N) 只是告诉 LangChain 在执行 abatch/batch 时最多并发 N 个子任务。
-
是否能提速,取决于整个 pipeline 是否为 I/O-bound(等待网络/模型服务)或 CPU/GPU-bound(单次推理占满资源)。
-
如果单次推理把 GPU/CPU 占满(例如单卡的 vLLM 同步推理),增加并发不会变快,甚至更慢(资源竞争)。
-
如果调用的是远端云 API(有网络延迟)或能并行处理多请求的模型服务,且客户端/服务端都允许并发,则会明显提速。
-
框架内部可能会在某些组件对并发做序列化(例如某些 LLM 客户端在后端使用同步 HTTP 会阻塞),这也会导致看起来并发无效。
-
确认你使用的是 abatch(异步)而不是 batch(同步)
from langchain_core.runnables import RunnableConfig
# 配置:最多 2 个并发任务
config = RunnableConfig(
max_concurrency=2, # 最大并发数:限制同时运行的任务数量,防止资源耗尽
abstimeout=8.0, # 单个任务超时时间(秒):超过此时间未完成的任务将被强制终止
metadata={"request_id": "abc123", "task": "query"}, # 元数据:记录请求ID和任务类型,便于追踪和日志分析
)
# 创建一个带有{product}占位符变量的模板
prompt_template = [PromptTemplate](06_messages_prompt.md).from_template(
"为生产{product}的公司起一个好名字?"
)
# 准备一个输入列表
inputs = ["彩色袜子", "环保咖啡杯", "智能水杯"]
formatted_prompts = [prompt_template.format(product=product) for product in inputs]
# Jupyter 已经支持顶级 await,无需 asyncio.run()
results = await model.abatch(formatted_prompts, config=config)
for i, r in enumerate(results):
print(f"=== Query {i+1} ===")
print(r.content)
print(r.model_config)
# 可能输出: ['Fun Socks Co.', 'Green Cup Co.', 'HydraSmart']
更多config参数解释如下:
| 属性名 | 类型 | 说明 |
|---|---|---|
max_concurrency |
int |
最大并行执行数 |
timeout |
float |
每个请求的最大超时时间(秒) |
callbacks |
list |
触发事件回调,用于日志或监控 |
metadata |
dict |
额外的上下文信息,可用于追踪 |
🎯 总结
本文详细介绍了 Content Blocks 与批处理 的核心概念和实战技巧。希望这些内容能帮助你更好地理解和使用 LangChain 1.0!
如果你有任何问题或建议,欢迎在评论区留言交流!💬
🏷️ 标签:LangChain 多模态 ContentBlocks
💝 感谢阅读!如果觉得有帮助,记得点赞收藏关注哦!
本文为原创内容,版权归作者所有,转载需注明出处。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐



 10
10 0
0- 0



 已为社区贡献36条内容
已为社区贡献36条内容

所有评论(0)