李飞飞团队新作:无需修改架构,重组数据即显著提升AI对视频理解能力
斯坦福大学、微软研究院和威斯康辛大学团队,提出了VideoWeave数据中心化方法。一种简单得令人惊讶的方法,只需将现有的短视频素材重组,就能在不增加计算成本的前提下显著提升AI对长视频的理解能力。斯坦福大学、微软研究院和威斯康辛大学团队,提出了VideoWeave数据中心化方法。不需要发明新的复杂架构,也不需要耗资巨大的新标注,仅仅通过改变喂给模型的数据组织形式,就能让AI变得更聪明。训练视频语
斯坦福大学、微软研究院和威斯康辛大学团队,提出了VideoWeave数据中心化方法。
一种简单得令人惊讶的方法,只需将现有的短视频素材重组,就能在不增加计算成本的前提下显著提升AI对长视频的理解能力。

斯坦福大学、微软研究院和威斯康辛大学团队,提出了VideoWeave数据中心化方法。
不需要发明新的复杂架构,也不需要耗资巨大的新标注,仅仅通过改变喂给模型的数据组织形式,就能让AI变得更聪明。
训练视频语言模型一直是个烧钱的苦差事。
相比于静态图像,视频多了一个时间维度,处理一秒钟的视频往往需要分析数十帧画面,计算量成倍增加。
更让人头疼的是高质量数据的匮乏,现有的视频数据集大多是只有几秒到一分钟的短片段,配上一句简单的描述。
而在真实应用场景中,我们希望AI能看懂半小时甚至一小时的长电影,理解其中复杂的剧情走向。
用短跑的训练方式去跑马拉松,效果自然不尽如人意。
拼接短视频构建合成长上下文
视频理解的核心难点在于长上下文的处理。
当人类观看一段长视频时,大脑需要不断记忆之前的片段,并将当前的画面与记忆关联起来。
现有的模型训练受限于显存和计算资源,通常只能在一个批次中采样少量帧数,且这些帧数往往来自同一个短视频。
模型很快学会了偷懒,它发现相邻的帧长得差不多,只需要看几眼就能猜出大概,根本不需要建立长期的时空依赖关系。
VideoWeave打破了这种舒适区。
它的逻辑非常直观,既然缺乏带标注的长视频,那就用现有的短视频人工合成。
研究者从WebVid-10M这样的海量短视频库中取材,将多个毫无关联的短视频剪辑拼接在一起,形成一个更长的“合成视频”。
与此同时,这些视频原本的文本描述也被串联起来,作为新的训练目标。
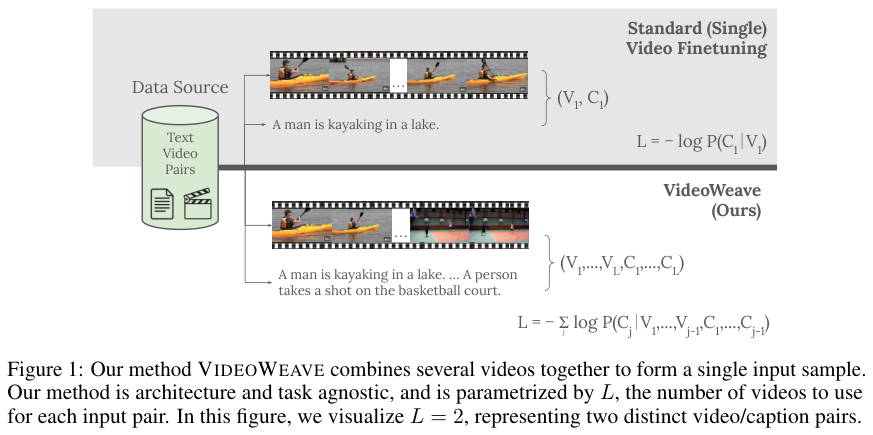
图中展示了VideoWeave的基本原理。
它并没有改变模型的内部构造,而是改变了输入端。如果设定的计算预算是处理16帧画面,传统方法会从一个视频里抽取16帧。
VideoWeave则可能从4个不同的视频里各抽取4帧,或者从16个视频里各抽取1帧,将它们按顺序拼成一个序列。
这种做法巧妙地模拟了长视频中可能出现的场景切换和内容跳跃。
模型被迫去适应画面内容的剧烈变化,它必须时刻保持警惕,因为下一秒的画面可能从“湖上泛舟”瞬间变成“篮球比赛”。
为了回答准确,模型必须真正理解每一帧的内容,而不是依靠惯性去猜测。
这种训练方式在保持计算量不变的情况下,极大地丰富了模型在一次更新中接触到的视觉语义信息。
随机拼接竟然战胜了精心聚类
在确定了拼接策略后,一个自然的问题浮出水面:应该把什么样的视频拼在一起。
直觉告诉我们,如果把内容相似的视频拼在一起,比如都是户外运动或者都是烹饪教学,模型可能更容易理解,形成的合成视频也更像一个连贯的故事。
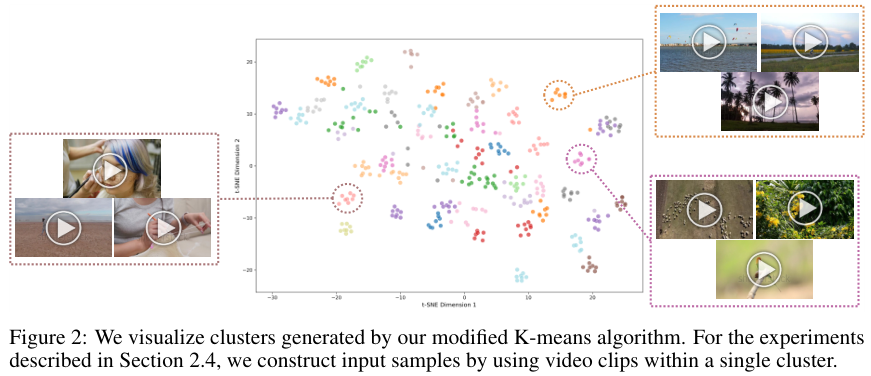
为了验证这一点,研究团队尝试了基于视觉相似度的聚类拼接。
他们提取了视频的特征,利用改进的 K-均值算法将相似的视频归为一类,然后只从同一个类别中选取视频进行拼接。
下图展示了这种聚类算法产生的视觉群组。
除了视觉上的连贯,研究者还尝试了文本上的连贯。
他们利用GPT-4o-mini将原本独立的短句描述改写成一段流畅通顺的叙事文本,希望这能帮助模型更好地建立语言与视觉的联系。

实验结果却给了所有人一记响亮的耳光。精心设计的视觉聚类和文本润色,表现竟然不如最简单的随机拼接。

表1展示了不同方法在VideoMME基准测试上的得分。随机拼接的VideoWeave方法(Multi-Video FT)不仅击败了仅使用图像训练的基准,也显著优于传统的单视频微调(Single-Video FT)。
进一步的分析揭示了原因。
当视频在视觉上过于相似时,模型又开始偷懒了,它发现根据前几帧的内容就能很容易地推断出后面的内容,从而忽略了细微的差别。
而随机拼接带来的强烈反差,强迫模型必须关注每一个片段的独特特征。
至于文本润色,GPT-4虽然把句子写得漂亮了,但也丢失了原始数据中的具体细节,甚至产生了一些幻觉,导致模型学到了错误的信息。
最原始的、用空格隔开的简单字幕拼接,反而提供了最精准的监督信号。
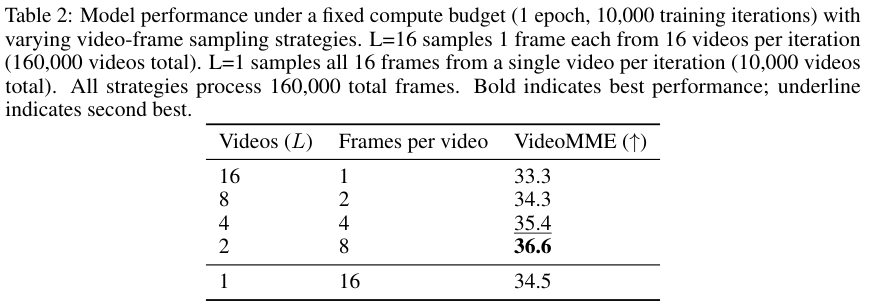
表2详细列出了不同的拼接数量对性能的影响。

表3则对比了随机选择与聚类选择的效果。
数据表明,在总帧数固定的情况下,将两个不同的视频拼接在一起,即每个视频贡献8帧,达到了最佳的平衡点。
这既保证了每个片段有足够的内部连贯性供模型理解动作,又提供了足够的上下文切换来锻炼模型的适应能力。
数据重组比修改架构更具性价比
VideoWeave证明:数据的使用方式往往比模型架构的微调更关键。
通过简单的数据重组,我们可以在不增加任何硬件投入的情况下,挖掘出模型更大的潜力。
这种方法实际上是在模拟一种更高效的学习过程,就像学生在复习时,不再是死记硬背某一章,而是将不同章节的知识点穿插在一起复习,从而锻炼出融会贯通的能力。
这种能力的提升在定性分析中表现得尤为明显。

图4展示了一个VideoMME中的多项选择题案例。
在这个例子中,模型需要回答厄尔尼诺现象的主要原因。
VideoWeave训练出的模型能够准确捕捉到“信风减弱”这一关键信息,而标准微调的模型则给出了错误的答案。
这说明经过多样化拼接数据训练的模型,在处理复杂信息和排除干扰项方面具有更强的鲁棒性。
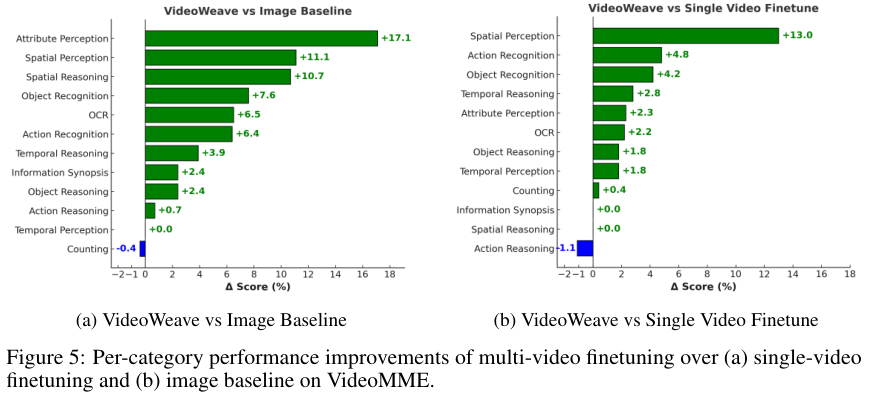
图5进一步展示了不同类别下的性能提升情况。
可以看到,在属性感知、空间感知和时序推理等多个维度,VideoWeave都取得了显著的进步。
这并非是因为模型本身变得更大了,而是它看视频的方式发生了质的改变。
它不再盯着单一的画面发呆,而是学会了在不断变化的视觉流中寻找关键线索。
这种训练策略不仅适用于学术研究,对于工业界在大规模视频数据上进行高效预训练也具有极高的参考价值。

有“AI”的1024 = 2048,欢迎大家加入2048 AI社区
更多推荐

 23
23 0
0- 0



 已为社区贡献208条内容
已为社区贡献208条内容

所有评论(0)